Upptäckten att endast 7 % av webbadresserna som rankas i traditionell Google-sökning också förekommer i AI-citat. Denna mätning avslöjar en betydande skillnad mellan vilka källor Googles algoritm rankar högst och vilka källor AI-språkmodeller citerar i sina svar, vilket indikerar att AI-system och sökmotorer utvärderar källors trovärdighet och relevans på olika sätt.
7%-överlapningsproblemet
Upptäckten att endast 7 % av webbadresserna som rankas i traditionell Google-sökning också förekommer i AI-citat. Denna mätning avslöjar en betydande skillnad mellan vilka källor Googles algoritm rankar högst och vilka källor AI-språkmodeller citerar i sina svar, vilket indikerar att AI-system och sökmotorer utvärderar källors trovärdighet och relevans på olika sätt.
Förstå 7%-överlapningsproblemet
7%-överlapningsproblemet syftar på en avgörande upptäckt inom AI-citatorsforskning: när AI-språkmodeller citerar källor förekommer endast cirka 7 % av de exakta webbadresser de refererar till i Googles topp 10-sökresultat för samma fråga. Detta fenomen dokumenterades först genom omfattande studier som analyserade hur stora AI-plattformar som ChatGPT, Perplexity och Google AI Overviews hämtar sin information jämfört med traditionella sökmotorrankningar. Upptäckten utmanar antagandet att AI-system prioriterar samma auktoritativa källor som Googles algoritm rankar högst, och avslöjar en betydande skillnad i hur olika informationsåtervinningssystem utvärderar källors trovärdighet och relevans. Denna skillnad har djupgående konsekvenser för SEO-proffs, innehållsskapare och organisationer som vill förstå AI:s roll i modern informationsupptäckt.
Domänöverlappning vs URL-överlappning
Att förstå skillnaden mellan domänöverlappning och URL-överlappning är avgörande för att tolka 7%-överlapningsproblemet. Domänöverlappning mäter andelen unika domäner som citeras av AI och som också förekommer i Googles topp 10-resultat, medan URL-överlappning spårar andelen exakta, specifika webbadresser som återfinns i båda källorna. Dessa mätvärden skiljer sig markant eftersom AI-system kan citera flera sidor från samma domän, eller referera till andra sidor än dem Google rankar högst för identiska sökfrågor. Skillnaden visar att även om AI och Google kan vara överens om vilka webbplatser som är auktoritativa (domännivå), är de ofta oense om vilka specifika sidor som är mest relevanta (URL-nivå). Denna distinktion är viktig eftersom den påverkar hur innehållsskapare bör optimera sina strategier – fokus på domänauktoritet respektive enskild sidoptimering kräver olika tillvägagångssätt.
Mätvärde
Definition
Typiskt intervall
Betydelse
Domänöverlappning
% av domäner som citeras av AI och förekommer i Googles topp 10
10–91 %
Visar ämnesmässig överensstämmelse
URL-överlappning
% av exakta webbadresser som citeras av AI och förekommer i Googles topp 10
6–82 %
Visar direkt källmatchning
Forskningsgrund och metodik
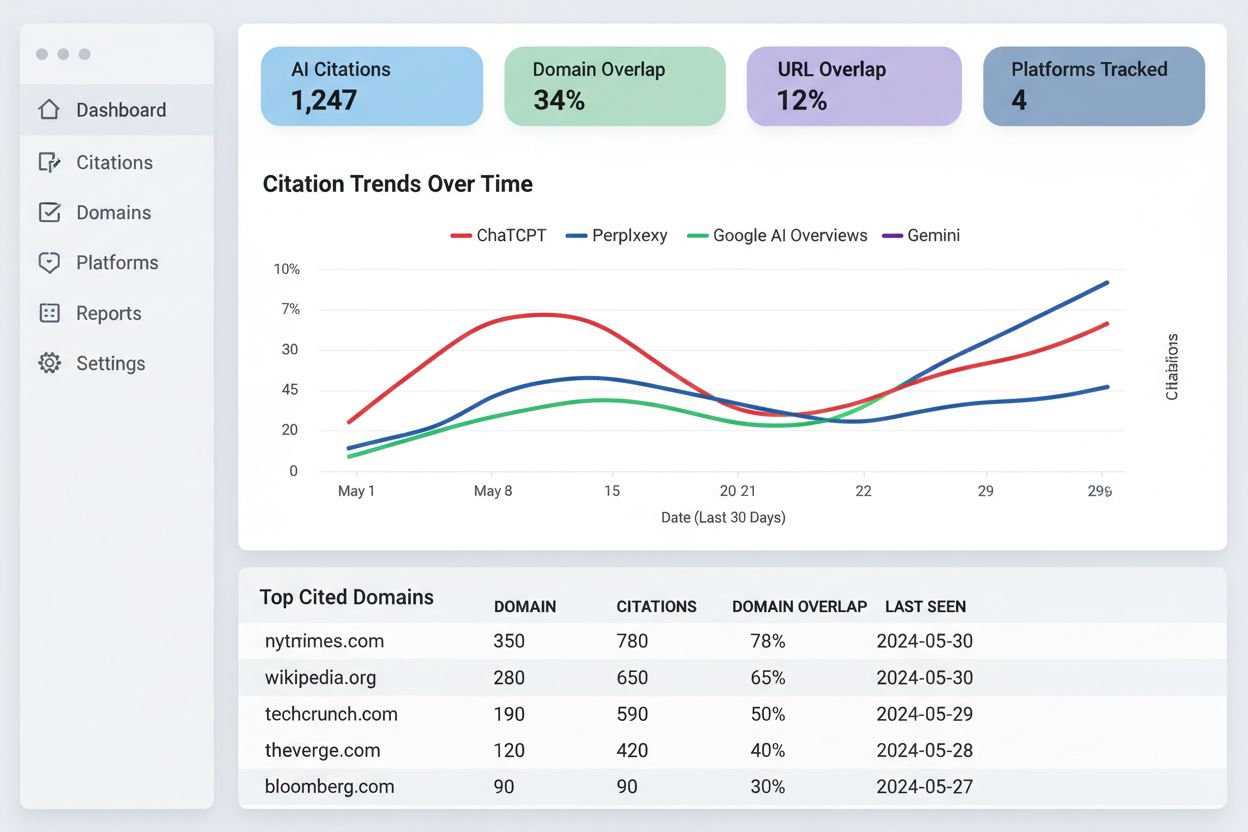
Forskningsgrunden för att förstå 7%-överlapningsproblemet kommer från flera storskaliga studier utförda av ledande SEO-plattformar. Ahrefs analyserade över 10 000 AI-genererade svar över olika frågetyper och fann domänöverlappning mellan 10–91 % beroende på frågekategori, medan URL-överlappningen låg konsekvent lågt på 6–82 %. Search Atlas genomförde liknande forskning med stickprov på över 5 000 frågor, och dokumenterade hur olika AI-modeller prioriterar källor annorlunda än traditionella sökalgoritmer. Semrush forskarteam granskade citeringsmönster över flera AI-plattformar samtidigt och visade att överlappningsvariansen är starkt beroende av frågeintention, ämnesspecifikitet och hur aktuell AI-modellens träningsdata är. Dessa studier använde rigorösa metoder som kontrollerade frågetester, källverifiering och statistisk analys för att säkerställa att resultaten var reproducerbara och tillförlitliga. Den konsekventa bilden mellan oberoende forskarlag bekräftar att 7%-överlapningsproblemet representerar en verklig strukturell skillnad i hur AI-system hämtar och rankar informationskällor.
Plattformspecifika citeringsmönster
Olika AI-plattformar uppvisar anmärkningsvärt varierande citeringsmönster, vilket visar att 7%-överlapningsproblemet tar sig olika uttryck inom AI-landskapet:
Perplexity: Uppvisar högst överlappning med 43 % domänöverlappning och 24 % URL-överlappning, vilket tyder på att denna plattform prioriterar källor mer i linje med traditionella sökrankningar
ChatGPT: Visar lägre överlappning med 21 % domänöverlappning och 7 % URL-överlappning, vilket indikerar att den förlitar sig mer på träningsdata än på sökintegration i realtid
Google AI Overviews: Uppvisar måttlig till hög överlappning med 86 % domänöverlappning och 67 % URL-överlappning, vilket är logiskt med tanke på Googles direkta tillgång till sin egen rankingdata
Gemini: Tar en selektiv ansats med 28 % domänöverlappning och 6 % URL-överlappning, vilket antyder en balans mellan träningsdata och kuraterat källval
Dessa variationer speglar grundläggande skillnader i hur varje plattform hämtar information, deras tillgång till realtidsdata och deras underliggande hämtningsmekanismer. Den dramatiska skillnaden mellan Perplexity och ChatGPT beror till exempel på att Perplexity är integrerad med webbsökning i realtid medan ChatGPT är beroende av träningsdata med avgränsning i tiden. Att förstå dessa plattformspecifika mönster hjälper organisationer att förutse vilka AI-system som kommer att citera deras innehåll och hur man optimerar för varje plattforms unika citeringspreferenser.
Varför gapet finns
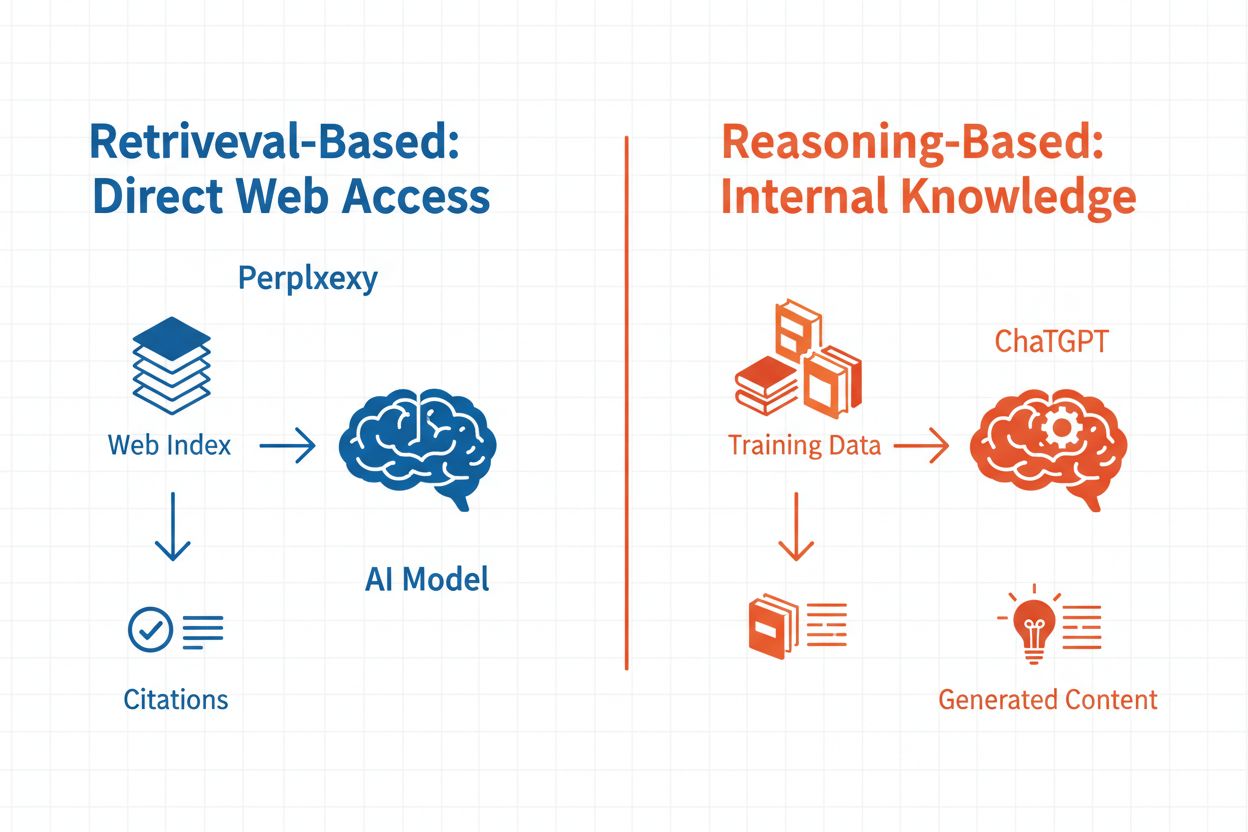
Skillnaden mellan domän- och URL-överlappning uppstår på grund av flera sammankopplade faktorer som bottnar i hur AI-system i grunden skiljer sig från sökmotorer. Resonerande återhämtning, som många AI-modeller använder, prioriterar information som hjälper till att skapa sammanhängande svar snarare än information som rankas högst i sökresultaten – detta förklarar varför ChatGPT kan citera en mindre populär men mer direkt relevant sida istället för Googles toppresultat. Skillnader i träningsdata utgör en annan avgörande faktor: AI-modeller som tränats på data från 2023 eller tidigare kan citera källor som var auktoritativa under träningen men som sedan dess ersatts av nyare, mer auktoritativa källor som Google nu rankar högre. Aktualitetsproblemet förvärrar detta, eftersom AI-system utan sökintegration i realtid inte kan komma åt de senaste innehållsuppdateringarna, algoritmändringarna eller nyligen publicerade auktoritativa källor. Dessutom kan AI-system medvetet diversifiera källor för att tillhandahålla flera perspektiv istället för att koncentrera citat till en enda mest rankad domän, vilket speglar en annan syn på vad som utgör en “bra” källa. Dessa faktorer samverkar och skapar den systematiska skillnad som observeras i 7%-överlapningsproblemet, vilket gör det till en egenskap hos AI-arkitekturen snarare än ett fel som ska åtgärdas.
Strategiska implikationer för innehållsskapare
För SEO-proffs och innehållsskapare kräver 7%-överlapningsproblemet ett grundläggande skifte i optimeringsstrategi. Istället för att anta att en topp 10-placering i Google garanterar AI-citat måste organisationer nu satsa på en dubbelkanalig optimeringsstrategi som riktar sig till både sökmotoralgoritmer och AI-hämtningssystem separat. Det innebär att skapa innehåll som tydligt visar expertis och relevans för specifika frågor och samtidigt säkerställa att sidor kan upptäckas via de träningsdata och realtidsintegrationer som AI-system använder. Innehållsskapare bör fokusera på ämnesauktoritet och semantisk relevans snarare än att enbart förlita sig på traditionella SEO-signaler, eftersom AI-system ofta värderar innehållskvalitet och svarens direkthet högre än länkprofiler. Implikationerna sträcker sig även till länkbyggandet: Även om bakåtlänkar fortfarande är avgörande för Googles ranking har de mindre direkt inverkan på AI-citat, vilket kräver att marknadsförare diversifierar sina auktoritetsbyggande insatser. Organisationer bör också beakta vilka AI-plattformar deras målgrupp använder mest och optimera därefter – ett B2B-företag vars målgrupp ofta använder Perplexity bör prioritera andra optimeringstaktiker än ett vars målgrupp förlitar sig på ChatGPT. Slutligen antyder den låga URL-överlappningen att flera relevanta sidor på en domän ökar sannolikheten för AI-citat, även om enskilda sidor inte rankar i Googles topp 10.
Övervaknings- och mätningslösningar
Att övervaka AI-citat kräver specialiserade verktyg som är särskilt utformade för detta ändamål, eftersom traditionella SEO-analysplattformar inte fångar hur AI-system refererar till ditt innehåll. AmICited.com utmärker sig som en dedikerad plattform för att spåra AI-citat över flera modeller, och erbjuder övervakning i realtid av vilka AI-system som citerar din domän, vilka specifika sidor som refereras samt hur ofta citaten förekommer över tid. Kompletterande verktyg som Semrush, Ahrefs och Search Atlas har integrerat AI-citeringsspårning i sina bredare SEO-sviter, och erbjuder jämförande analys mellan AI-överlappning och Googles rankingar. Dessa övervakningslösningar spårar vanligtvis citat över större plattformar som ChatGPT, Perplexity, Google AI Overviews och Gemini, vilket gör det möjligt för organisationer att förstå sin synlighet inom hela AI-landskapet. För organisationer som menar allvar med AI-drivet trafik- och varumärkesexponering är det avgörande att implementera ett övervakningssystem – du kan inte optimera för något du inte kan mäta. AmICited är särskilt starkt på att tillhandahålla detaljerad citeringsdata, historiska trender och konkurrensjämförelser som hjälper organisationer att förstå inte bara om de citeras av AI, utan hur deras citeringsmönster står sig mot konkurrenter och branschstandarder. Regelbunden övervakning möjliggör datadrivna justeringar av innehållsstrategin och hjälper organisationer att dra nytta av AI:s växande roll som upptäcktskanal vid sidan av traditionell sökning.
Vanliga frågor
Vad är egentligen 7%-överlapningsproblemet?
7%-överlapningsproblemet syftar på upptäckten att endast cirka 7 % av de exakta webbadresser som citeras av AI-språkmodeller återfinns i Googles topp 10-sökresultat för samma sökfråga. Detta avslöjar en betydande skillnad mellan vilka källor AI-system prioriterar och vilka källor Googles algoritm rankar högst, vilket indikerar fundamentalt olika sätt att utvärdera källors trovärdighet och relevans.
Varför är URL-överlappningen så mycket lägre än domänöverlappningen?
Domänöverlappning mäter om AI-system citerar samma webbplatser som Google (vanligtvis 10–91 %), medan URL-överlappning mäter om de citerar exakt samma sidor (vanligtvis 6–82 %). Skillnaden finns eftersom AI-system kan citera olika sidor från samma betrodda domän, eller hänvisa till sidor som Google rankar lägre men som bättre besvarar den specifika frågan. Detta visar att AI och Google är överens om auktoritativa domäner men inte om vilka specifika sidor som är mest relevanta.
Vilken AI-plattform har högst överlappning med Google-sök?
Perplexity uppvisar högst överlappning med Google-sök, med 43 % domänöverlappning och 24 % URL-överlappning. Detta beror på att Perplexity integrerar sökning på webben i realtid i sina svar, vilket gör att den kan komma åt och citera samma aktuella källor som Google rankar. Till skillnad från detta visar ChatGPT endast 21 % domänöverlappning och 7 % URL-överlappning eftersom den är beroende av träningsdata istället för integrerad sökning i realtid.
Hur påverkar 7%-överlapningsproblemet min SEO-strategi?
7%-överlapningsproblemet innebär att du inte kan anta att en topp 10-placering i Google garanterar AI-citat. Du behöver en tvåkanalig optimeringsstrategi som adresserar både sökmotoralgoritmer och AI-hämtningssystem separat. Detta inkluderar fokus på ämnesauktoritet, semantisk relevans, innehållskvalitet och att säkerställa att din domän har flera relevanta sidor som kan upptäckas både genom AI:s träningsdata och sök i realtid.
Kan jag fortfarande ranka bra i Google och få AI-citat?
Ja, men det kräver olika optimeringsstrategier. Starka Google-placeringar hjälper visserligen till med AI-synlighet (korrelationen på domännivå är stark), men de garanterar inte att specifika sidor citeras. Du bör fokusera på att skapa heltäckande, högkvalitativt innehåll som direkt besvarar användarfrågor, uppvisar expertis och kan upptäckas via flera kanaler. Domänauktoritet är fortsatt viktig både för Google och AI-synlighet.
Hur ofta ändras överlappningsprocenten?
Överlappningsprocenterna varierar beroende på algoritmuppdateringar, förändringar i AI-modellernas träningsdata och skiften i hur plattformar prioriterar källor. Forskning visar att överlappningen kan förändras avsevärt inom några månader när AI-plattformar uppdaterar sina hämtningsmekanismer och träningsdata. Därför är kontinuerlig övervakning av dina AI-citat viktigare än att förlita sig på statiska mätvärden.
Vilka verktyg kan jag använda för att övervaka AI-citat?
AmICited.com är en dedikerad plattform som är särskilt utformad för att övervaka AI-citat över flera modeller, inklusive ChatGPT, Perplexity, Google AI Overviews och Gemini. Andra verktyg som Semrush, Ahrefs och Search Atlas har integrerat spårning av AI-citat i sina bredare SEO-plattformar. AmICited utmärker sig genom att erbjuda detaljerad citeringsdata, historiska trender och konkurrensjämförelser specifikt för AI-synlighet.
Blir 7%-överlapningsproblemet bättre eller sämre?
Överlappningsproblemet utvecklas snarare än att det bara blir bättre eller sämre. När AI-plattformar mognar och integrerar mer realtidsökning (som Perplexity) ökar överlappningen med Google. Men när AI-systemen utvecklar mer sofistikerad resonerande förmåga kan de avsiktligt avvika från Googles rankingar för att erbjuda mer varierade eller kontextuellt relevanta källor. Trenden tyder på en stabilisering kring plattformsspecifika överlappningsmönster snarare än en konvergens mot Googles rankingar.
Övervaka din AI-synlighet på alla plattformar
Spåra hur ditt varumärke syns i ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar. Förstå dina AI-citeringsmönster och optimera din innehållsstrategi därefter.
7%-överlappningsproblemet: Varför synlighet på Google inte innebär AI-synlighet
Endast 7% av URL:er som citeras av AI-sökmotorer matchar Googles toppresultat. Upptäck varför en hög placering på Google inte garanterar AI-synlighet och hur du...
Reverse-engineering av konkurrenters AI-citat: Vilket innehåll blir omnämnt
Lär dig hur du reverse-engineerar konkurrenters AI-citat och upptäcker vilket innehåll AI-modeller föredrar att citera. Strategisk guide till konkurrensfördel i...
Lär dig vad konkurrenters citeringskällor är och hur du analyserar vilka innehållstillgångar som driver konkurrenters AI-synlighet i ChatGPT, Perplexity och Goo...
11 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.