
AI-crawlerhantering
Lär dig hur du hanterar AI-crawlers åtkomst till ditt webbplatsinnehåll. Förstå skillnaden mellan tränings- och sökcrawlers, implementera robots.txt-kontroller ...
6 min läsning
Strategier för att säkerställa att AI-system har tillgång till aktuellt innehåll istället för inaktuella cachade versioner. Cachehantering balanserar prestandafördelarna med caching mot risken att leverera föråldrad information, genom att använda invalidationsstrategier och övervakning för att bibehålla dataaktualitet samtidigt som latens och kostnader minskas.
Strategier för att säkerställa att AI-system har tillgång till aktuellt innehåll istället för inaktuella cachade versioner. Cachehantering balanserar prestandafördelarna med caching mot risken att leverera föråldrad information, genom att använda invalidationsstrategier och övervakning för att bibehålla dataaktualitet samtidigt som latens och kostnader minskas.
AI-cachehantering avser det systematiska tillvägagångssättet för att lagra och hämta tidigare beräknade resultat, modellutdata eller API-svar för att undvika onödig bearbetning och minska latens i artificiella intelligenssystem. Den huvudsakliga utmaningen ligger i att balansera prestandafördelarna med cachad data mot risken att leverera föråldrad eller inaktuell information som inte längre återspeglar systemets aktuella tillstånd eller användarens krav. Detta blir särskilt kritiskt i stora språkmodeller (LLM:er) och AI-applikationer där inferenskostnaderna är betydande och svarstiden direkt påverkar användarupplevelsen. Cachehanteringssystem måste intelligent avgöra när cachade resultat fortfarande är giltiga och när färsk beräkning är nödvändig, vilket gör det till en grundläggande arkitekturell aspekt för AI i produktion.
Effektiv cachehantering har en stor och mätbar påverkan på AI-systemets prestanda över flera dimensioner. Implementering av caching-strategier kan minska svarslatens med 80-90% för upprepade frågor samtidigt som API-kostnaderna minskar med 50-90%, beroende på cacheträffar och systemarkitektur. Utöver prestandamått påverkar cachehantering direkt noggrannhetskonsistens och systemtillförlitlighet, eftersom korrekt invaliderade cacher säkerställer att användare får aktuell information, medan dåligt hanterade cacher leder till inaktuell data. Dessa förbättringar blir allt viktigare när AI-system skalas för att hantera miljontals förfrågningar, där den samlade effekten av cacheeffektivitet direkt avgör infrastrukturkostnader och användarnöjdhet.
| Aspekt | Cachade system | Icke-cachade system |
|---|---|---|
| Svarstid | 80-90% snabbare | Basnivå |
| API-kostnader | 50-90% minskning | Full kostnad |
| Noggrannhet | Konsekvent | Variabel |
| Skalbarhet | Hög | Begränsad |
Cacheinvalidationsstrategier avgör hur och när cachad data uppdateras eller tas bort från lagring, och utgör ett av de mest kritiska besluten i cachearkitekturdesign. Olika invalidationsmetoder erbjuder tydliga kompromisser mellan dataaktualitet och systemprestanda:
Valet av invalidationsstrategi beror i grunden på applikationskrav: system som prioriterar dataexakthet kan acceptera högre latenskostnader genom aggressiv invalidering, medan prestandakritiska applikationer kan tolerera något inaktuell data för att behålla svarstider under millisekunder.
Prompt-caching i stora språkmodeller är en specialiserad tillämpning av cachehantering som lagrar mellanliggande modelltilstånd och tokensekvenser för att undvika ombearbetning av identiska eller liknande indata. LLM:er stödjer två huvudsakliga cachingmetoder: exakt caching matchar identiska prompts tecken-för-tecken, medan semantisk caching identifierar funktionellt likvärdiga prompts trots olika formulering. OpenAI implementerar automatisk prompt-caching med 50% kostnadsminskning på cachade tokens, där minst 1024 tokens krävs per prompt för att aktivera cachefördelarna. Anthropic erbjuder manuell prompt-caching med mer aggressiva 90% kostnadsminskningar men kräver att utvecklare explicit hanterar cache-nycklar och giltighetstider, med minimikrav på 1024-2048 tokens beroende på modellkonfiguration. Cachedurationen i LLM-system varierar vanligtvis från minuter till timmar, för att balansera de besparingar som återanvändning av cachade tillstånd ger mot risken att leverera föråldrade modellutdata för tidskänsliga applikationer.
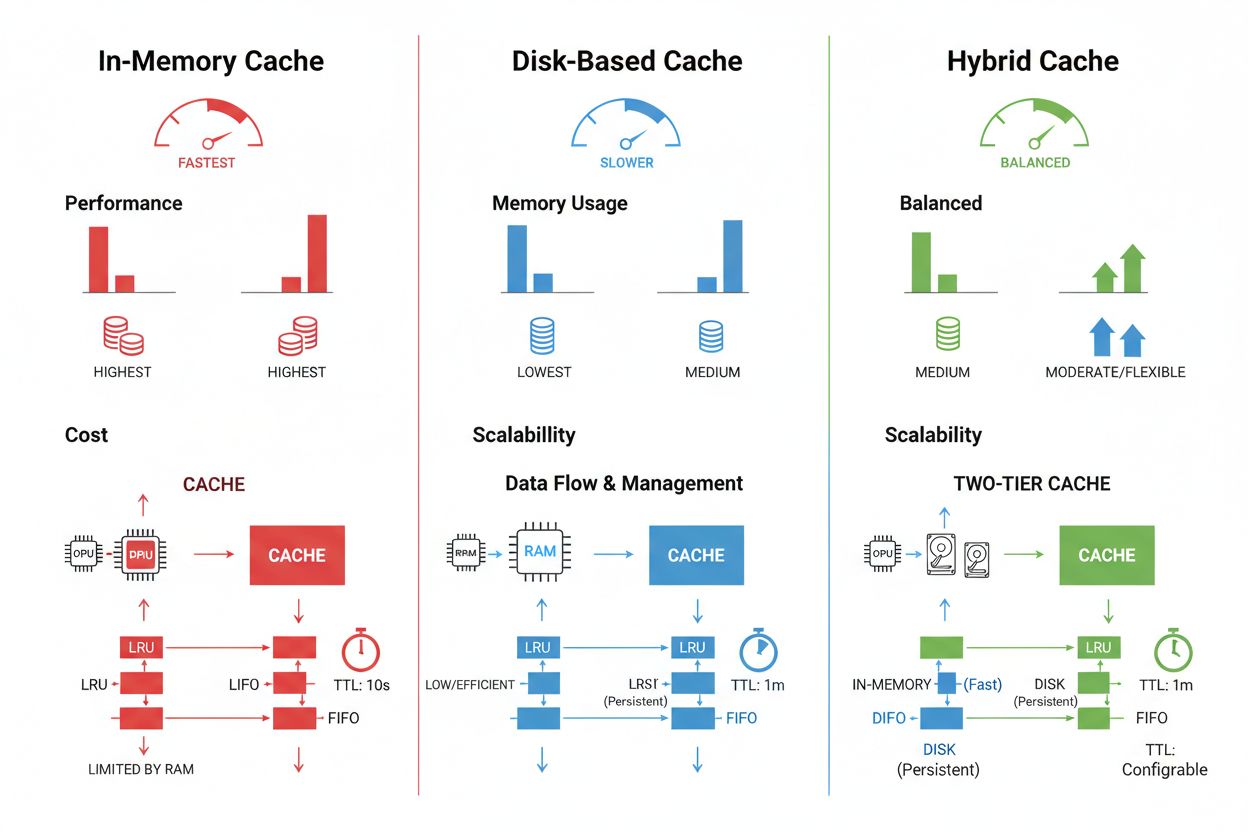
Cachestorage och hanteringstekniker varierar avsevärt beroende på prestandakrav, datavolymer och infrastrukturbegränsningar, där varje metod erbjuder särskilda för- och nackdelar. Minnesbaserade cachar som Redis ger åtkomsthastigheter på mikrosekundnivå och är idealiska för högfrekventa frågor men kräver mycket RAM och noggrann minneshantering. Diskbaserad caching rymmer större dataset och kvarstår över systemomstarter men innebär latens på millisekundnivå jämfört med minnesalternativ. Hybridmetoder kombinerar båda lagringstyperna, där ofta åtkomna data lagras i minne medan större dataset sparas på disk:
| Lagringstyp | Bäst för | Prestanda | Minnesanvändning |
|---|---|---|---|
| Minnesbaserad (Redis) | Frekventa frågor | Snabbast | Högre |
| Diskbaserad | Stora dataset | Måttlig | Lägre |
| Hybrid | Blandade arbetsbelastningar | Balanserad | Balanserad |
Effektiv cachehantering kräver korrekt konfigurerade TTL-inställningar som återspeglar datavolatiliteten—korta TTL:er (minuter) för snabbt föränderliga data, längre TTL:er (timmar/dagar) för stabilt innehåll—kombinerat med kontinuerlig övervakning av cacheträffar, eviktionsmönster och minnesanvändning för att hitta optimeringsmöjligheter.
Verkliga AI-applikationer visar både den transformativa potentialen och de operativa utmaningarna med cachehantering över olika användningsområden. Kundtjänstchatbots utnyttjar caching för att leverera konsekventa svar på vanliga frågor och minska inferenskostnaderna med 60-70%, vilket möjliggör kostnadseffektiv skala till tusentals samtidiga användare. Kodassistenter cachar vanliga kodmönster och dokumentationsfragment, vilket gör att utvecklare får autokompletteringsförslag med under 100 ms latens även vid hög belastning. Dokumentbehandlingssystem cachar inbäddningar och semantiska representationer av ofta analyserade dokument, vilket dramatiskt snabbar upp likhetsökningar och klassificeringsuppgifter. Produktion av cachehantering medför dock betydande utmaningar: invalidationskomplexiteten ökar exponentiellt i distribuerade system där cachekonsistens måste upprätthållas över flera servrar, resursbegränsningar tvingar svåra avvägningar mellan cachestorlek och täckning, säkerhetsrisker uppstår när cachad data innehåller känslig information som kräver kryptering och åtkomstkontroller, och koordinering av cacheuppdateringar över mikrotjänster introducerar potentiella race conditions och datainkonsistenser. Omfattande övervakningslösningar som spårar cacheaktualitet, träffar och invalidationstillfällen blir avgörande för att upprätthålla systemtillförlitlighet och identifiera när cachestrategier behöver justeras utifrån förändrade dataprofiler och användarbeteenden.
Cacheinvalidering tar bort eller uppdaterar inaktuell data när förändringar sker, vilket ger omedelbar färskhet men kräver händelsedrivna triggers. Cacheutgång sätter en tidsgräns (TTL) för hur länge data stannar i cachen, vilket är enklare att implementera men kan innebära att inaktuell data levereras om TTL är för lång. Många system kombinerar båda metoderna för optimal prestanda.
Effektiv cachehantering kan minska API-kostnader med 50-90% beroende på cacheträffar och systemarkitektur. OpenAI:s prompt-caching ger 50% kostnadsminskning på cachade tokens, medan Anthropic erbjuder upp till 90% minskning. De faktiska besparingarna beror på frågemönster och hur mycket data som effektivt kan cachas.
Prompt-caching lagrar mellanliggande modelltilstånd och tokensekvenser för att undvika ombearbetning av identiska eller liknande indata i stora språkmodeller. Det stöder exakt caching (tecken-för-tecken-matchning) och semantisk caching (funktionellt likvärdiga prompts med olika formulering). Detta minskar latensen med 80% och kostnaderna med 50-90% för upprepade frågor.
De huvudsakliga strategierna är: Tidsbaserad utgång (TTL) för automatisk borttagning efter en angiven tid, Händelsebaserad invalidering för omedelbara uppdateringar vid databasändringar, Semantisk invalidering för liknande frågor baserat på mening, samt Hybridmetoder som kombinerar flera strategier. Valet beror på datavolatilitet och krav på färskhet.
Minnesbaserad caching (som Redis) ger åtkomsthastigheter på mikrosekundnivå och är idealisk för frekventa frågor men förbrukar mycket RAM. Diskbaserad caching hanterar större dataset och kvarstår över omstarter, men innebär latens på millisekundnivå. Hybridmetoder kombinerar båda, där ofta åtkomna data lagras i minnet medan större dataset ligger på disk.
TTL är en nedräkningstimer som avgör hur länge cachad data förblir giltig innan utgång. Korta TTL:er (minuter) passar snabbt föränderliga data, medan längre TTL:er (timmar/dagar) fungerar för stabilt innehåll. Korrekt TTL-konfiguration balanserar dataaktualitet mot onödiga cacheuppdateringar och serverbelastning.
Effektiv cachehantering gör det möjligt för AI-system att hantera betydligt fler förfrågningar utan proportionerlig infrastrukturökning. Genom att minska beräkningsbelastningen per förfrågan kan systemen betjäna miljontals användare mer kostnadseffektivt. Cacheträffar avgör direkt infrastrukturkostnader och användarnöjdhet i produktionsdrift.
Cachad känslig data innebär säkerhetshot om den inte krypteras och åtkomstkontrolleras korrekt. Risker inkluderar obehörig åtkomst till cachad information, dataexponering vid cacheinvalidering, och oavsiktlig caching av konfidentiellt innehåll. Omfattande kryptering, åtkomstkontroller och övervakning är avgörande för att skydda känslig cachad data.
AmICited spårar hur AI-system refererar till ditt varumärke och säkerställer att ditt innehåll förblir aktuellt i AI-cacher. Få insyn i AI-cachehantering och innehållsaktualitet över GPT:er, Perplexity och Google AI Overviews.
Lär dig hur du hanterar AI-crawlers åtkomst till ditt webbplatsinnehåll. Förstå skillnaden mellan tränings- och sökcrawlers, implementera robots.txt-kontroller ...

Lär dig vad ryktehantering för AI-sökning innebär, varför det är viktigt för ditt varumärke och hur du övervakar din närvaro över ChatGPT, Perplexity, Claude oc...

Lär dig om AI-innehållsstyrning – de policyer, processer och ramverk som organisationer använder för att hantera innehållsstrategi över AI-plattformar, samtidig...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.