
Hur du bestrider och rättar felaktig information i AI-svar
Lär dig hur du bestrider felaktig AI-information, rapporterar fel till ChatGPT och Perplexity, samt implementerar strategier för att säkerställa att ditt varumä...
9 min läsning
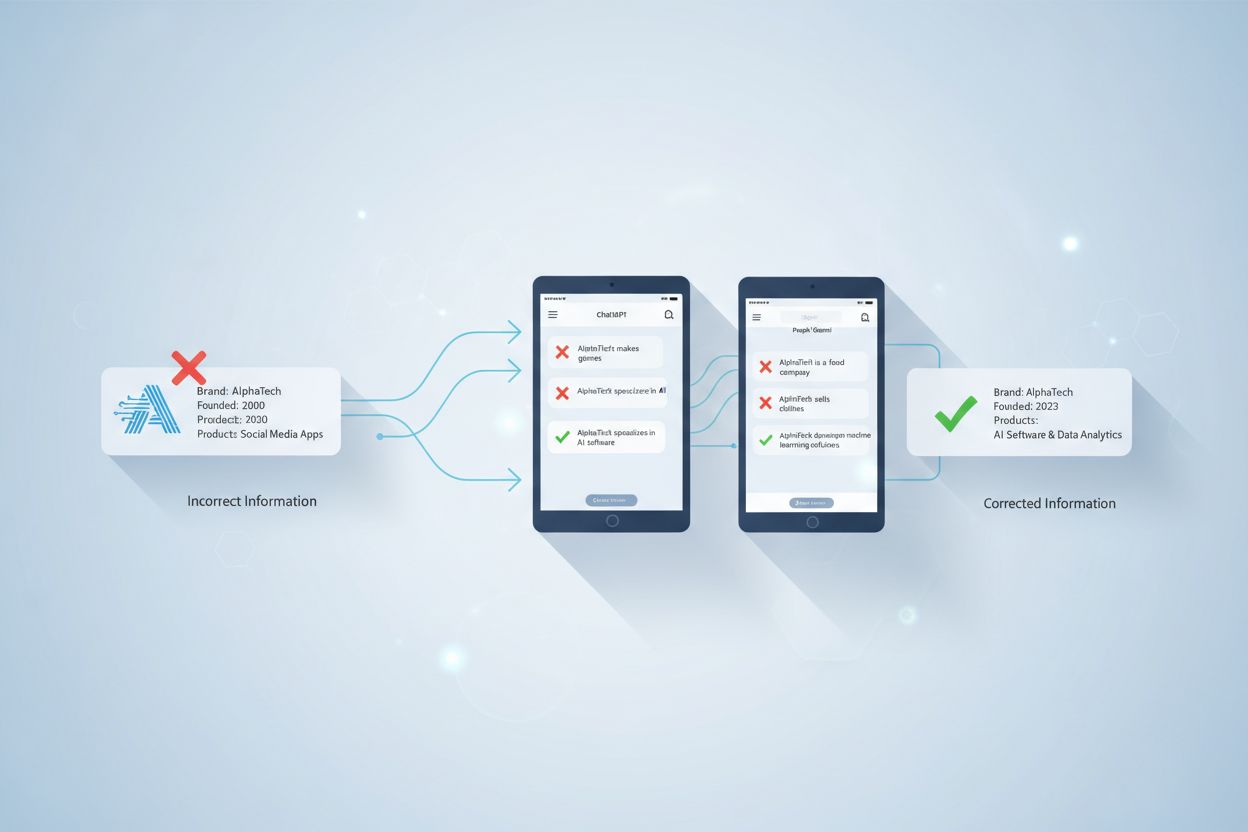
AI-missinformationskorrigering avser strategier och verktyg för att identifiera och åtgärda felaktig varumärkesinformation som förekommer i AI-genererade svar från system som ChatGPT, Gemini och Perplexity. Det innebär övervakning av hur AI-system representerar varumärken och att genomföra korrigeringar på källnivå för att säkerställa att korrekt information distribueras över betrodda plattformar. Till skillnad från traditionell faktakontroll fokuserar det på att korrigera de källor som AI-systemen litar på snarare än AI-utgångarna själva. Detta är avgörande för att upprätthålla varumärkets rykte och noggrannhet i en AI-driven sökmiljö.
AI-missinformationskorrigering avser strategier och verktyg för att identifiera och åtgärda felaktig varumärkesinformation som förekommer i AI-genererade svar från system som ChatGPT, Gemini och Perplexity. Det innebär övervakning av hur AI-system representerar varumärken och att genomföra korrigeringar på källnivå för att säkerställa att korrekt information distribueras över betrodda plattformar. Till skillnad från traditionell faktakontroll fokuserar det på att korrigera de källor som AI-systemen litar på snarare än AI-utgångarna själva. Detta är avgörande för att upprätthålla varumärkets rykte och noggrannhet i en AI-driven sökmiljö.
AI-missinformationskorrigering avser de strategier, processer och verktyg som används för att identifiera och åtgärda felaktig, föråldrad eller vilseledande information om varumärken som förekommer i AI-genererade svar från system som ChatGPT, Gemini och Perplexity. Färsk forskning visar att ungefär 45 % av AI-förfrågningar ger felaktiga svar, vilket gör varumärkesnoggrannhet i AI-system till en avgörande fråga för företag. Till skillnad från traditionella sökresultat där varumärken kan kontrollera sina egna listningar, sammanställer AI-system information från flera källor på webben, vilket skapar ett komplext landskap där missinformation kan fortsätta utan att upptäckas. Utmaningen handlar inte bara om att rätta enskilda AI-svar – det gäller att förstå varför AI-system får varumärkesinformation fel från början och att genomföra systematiska korrigeringar på källnivå.
AI-system hittar inte på varumärkesinformation från grunden; de sammanställer den från det som redan finns på internet. Denna process skapar dock flera förutsägbara felkällor som leder till felaktig varumärkesrepresentation:
| Grundorsak | Hur det sker | Affärspåverkan |
|---|---|---|
| Källinkonsekvens | Varumärket beskrivs olika på olika webbplatser, kataloger och artiklar | AI drar fel slutsatser från motstridig information |
| Föråldrade auktoritativa källor | Gamla Wikipedia-artiklar, kataloglistningar eller jämförelsesidor innehåller felaktiga data | Nyare rättelser ignoreras eftersom äldre källor har högre auktoritetssignaler |
| Entitetsförväxling | Liknande varumärkesnamn eller överlappande kategorier förvirrar AI-system | Konkurrenter tillskrivs dina egenskaper eller varumärket utelämnas helt |
| Saknade primära signaler | Avsaknad av strukturerad data, tydliga Om oss-sidor eller konsekvent terminologi | AI tvingas gissa information, vilket leder till vaga eller felaktiga beskrivningar |
När ett varumärke beskrivs olika över flera plattformar har AI-system svårt att avgöra vilken version som är auktoritativ. Istället för att be om förtydligande drar de slutsatser utifrån frekvens och upplevd auktoritet – även när den konsensusen är fel. Små skillnader i varumärkesnamn, beskrivningar eller positionering dupliceras ofta över plattformar, och när de har upprepats tillräckligt blir dessa fragment signaler som AI-modeller tolkar som tillförlitliga. Problemet förvärras när föråldrade men auktoritativa sidor innehåller felaktig information; AI-systemen väljer ofta dessa äldre källor framför nyare rättelser, särskilt om rättelserna inte spridits brett över betrodda plattformar.
Att rätta felaktig varumärkesinformation i AI-system kräver ett fundamentalt annorlunda tillvägagångssätt än traditionell SEO-sanering. I traditionell SEO uppdaterar varumärken sina egna listningar, korrigerar NAP-data (namn, adress, telefon) och optimerar innehåll på egna sidor. AI-varumärkeskorrigering fokuserar på att ändra vad betrodda källor säger om ditt varumärke, inte på att kontrollera din egen synlighet. Du korrigerar inte AI direkt – du korrigerar det som AI litar på. Att försöka “fixa” AI-svar genom att upprepa felaktiga påståenden (även för att förneka dem) kan slå tillbaka genom att förstärka kopplingen du vill ta bort. AI-system känner igen mönster, inte avsikt. Det innebär att varje korrigering måste börja på källnivå, baklänges från där AI-systemen faktiskt lär sig information.
Innan du kan rätta felaktig varumärkesinformation behöver du insyn i hur AI-system för närvarande beskriver ditt varumärke. Effektiv övervakning fokuserar på:
Manuella kontroller är opålitliga eftersom AI-svar varierar beroende på prompt, kontext och uppdateringscykel. Strukturerade övervakningsverktyg ger den insyn som behövs för att upptäcka fel tidigt, innan de fastnar i AI-systemen. Många varumärken inser inte att de representeras fel i AI förrän en kund nämner det eller en kris uppstår. Proaktiv övervakning förhindrar detta genom att fånga inkonsekvenser innan de sprids.
När du har identifierat felaktig varumärkesinformation måste korrigeringen ske där AI-systemen faktiskt hämtar informationen – inte bara där felet förekommer. Effektiva korrigeringar på källnivå inkluderar:
Huvudprincipen är: korrigeringar fungerar bara när de görs på källnivå. Att ändra vad som visas i AI-utgångar utan att rätta de underliggande källorna är högst tillfälligt. AI-system omvärderar kontinuerligt signaler när nytt innehåll publiceras och äldre sidor dyker upp igen. En korrigering som inte adresserar den ursprungliga källan kommer så småningom att skrivas över av den ursprungliga missinformationen.
När du rättar felaktig varumärkesinformation över kataloger, marknadsplatser eller AI-matade plattformar kräver de flesta system verifiering som kopplar varumärket till legitimt ägande och användning. Vanligt efterfrågad dokumentation inkluderar:
Målet är inte volym – det är konsekvens. Plattformar granskar om dokumentation, listningar och publika varumärkesdata är samstämmiga. Att ha dessa material organiserade i förväg minskar risken för avslag och påskyndar godkännande när felaktig varumärkesinformation ska rättas i större skala. Konsekvens över källor signalerar till AI-system att din varumärkesinformation är pålitlig och auktoritativ.
Flera verktyg hjälper nu team att spåra varumärkesrepresentation över AI-sökmotorer och webben i stort. Även om funktionerna överlappar, fokuserar de oftast på synlighet, attribuering och konsekvens:
Dessa verktyg rättar inte felaktig varumärkesinformation direkt. Istället hjälper de team att upptäcka fel tidigt, identifiera datadiskrepanser innan de sprids, validera om källkorrektioner förbättrar AI-noggrannhet och övervaka långsiktiga trender i AI-attribuering och synlighet. Används tillsammans med källkorrektioner och dokumentation ger övervakningsverktyg den återkopplingsslinga som krävs för att hållbart rätta felaktig varumärkesinformation.
AI-söknoggrannhet förbättras när varumärken är tydligt definierade entiteter, inte vaga aktörer inom en kategori. För att minska felaktig varumärkesrepresentation i AI-system, fokusera på:
Målet är inte att säga mer – utan att säga samma sak överallt. När AI-systemen stöter på konsekventa varumärkesdefinitioner från auktoritativa källor slutar de gissa och börjar återge korrekt information. Detta är särskilt viktigt för varumärken som upplever felaktiga omnämnanden, felattribuering till konkurrenter eller utelämning i AI-svar. Även efter att du rättat felaktig varumärkesinformation är noggrannheten inte permanent. AI-system utvärderar kontinuerligt signaler, vilket gör löpande tydlighet avgörande.
Det finns ingen fast tidslinje för att rätta felaktig varumärkesrepresentation i AI-system. AI-modeller uppdateras utifrån signalstyrka och konsensus, inte inlämningsdatum. Vanliga mönster är:
Tidiga framsteg syns sällan som ett plötsligt “fixat” svar. Titta istället efter indirekta signaler: minskad variation i AI-svar, färre motstridiga beskrivningar, mer konsekventa citeringar över källor och gradvis inkludering av ditt varumärke där det tidigare saknades. Stagnation ser annorlunda ut – om samma felaktiga formulering består trots flera korrigeringar betyder det oftast att ursprungskällan inte har rättats eller att starkare förstärkning behövs på annat håll.
Det mest tillförlitliga sättet att rätta felaktig varumärkesinformation är att minska förutsättningarna för att den ska uppstå från början. Effektivt förebyggande omfattar:
Varumärken som behandlar AI-synlighet som ett levande system – inte ett engångsprojekt – återhämtar sig snabbare från fel och upplever färre återkommande fall av felaktig varumärkesrepresentation. Förebyggande handlar inte om att kontrollera AI-utgångar. Det handlar om att upprätthålla rena, konsekventa indata som AI-systemen tryggt kan återge. I takt med att AI-sök fortsätter att utvecklas är det de varumärken som ser missinformationskorrigering som en pågående process, med kontinuerlig övervakning, källhantering och strategisk förstärkning av korrekt information på betrodda plattformar, som lyckas.
AI-missinformationskorrigering är processen att identifiera och åtgärda felaktig, föråldrad eller vilseledande information om varumärken som förekommer i AI-genererade svar. Till skillnad från traditionell faktagranskning fokuserar det på att korrigera de källor som AI-systemen litar på (kataloger, artiklar, listningar) istället för att försöka redigera AI-utgångarna direkt. Målet är att säkerställa att när användare frågar AI-system om ditt varumärke, får de korrekt information.
AI-system som ChatGPT, Gemini och Perplexity påverkar nu hur miljontals människor lär sig om varumärken. Forskning visar att 45 % av AI-förfrågningar ger fel, och felaktig varumärkesinformation kan skada ryktet, förvirra kunder och leda till förlorade affärer. Till skillnad från traditionell sökning där varumärken kontrollerar sina egna listningar, syntetiserar AI-system information från flera källor, vilket gör varumärkesnoggrannhet svårare att kontrollera men desto viktigare att hantera.
Nej, direkt korrigering fungerar inte effektivt. AI-system lagrar inte varumärkesfakta på redigerbara platser – de sammanställer svar från externa källor. Att upprepade gånger be AI 'fixa' information kan faktiskt förstärka hallucinationer genom att stärka den koppling du vill ta bort. Istället måste korrigeringar göras på källnivå: uppdatera kataloger, rätta föråldrade listningar och publicera korrekt information på betrodda plattformar.
Det finns ingen fast tidslinje eftersom AI-system uppdateras baserat på signalstyrka och konsensus, inte inlämningsdatum. Mindre faktakorrigeringar syns vanligtvis inom 2–4 veckor, förtydliganden på entitetsnivå tar 1–3 månader och konkurrensförskjutning kan ta 3–6 månader eller längre. Framsteg syns sällan som ett plötsligt 'fixat' svar – titta istället efter minskad variation i svaren och mer konsekventa citeringar över källor.
Flera verktyg spårar nu varumärkesrepresentation över AI-plattformar: Wellows övervakar omnämnanden och sentiment över ChatGPT, Gemini och Perplexity; Profound jämför synlighet över LLM:er; Otterly.ai analyserar varumärkessentiment i AI-svar; BrandBeacon ger positioneringsanalys; Ahrefs Brand Radar spårar omnämnanden på webben; och AmICited.com är specialiserad på att övervaka hur varumärken citeras och representeras i AI-system. Dessa verktyg hjälper till att upptäcka fel tidigt och validera om korrigeringar fungerar.
AI-hallucinationer är när AI-system genererar information som inte baseras på träningsdata eller är felaktigt avkodad. AI-missinformation är falsk eller vilseledande information som förekommer i AI-svar, vilket kan bero på hallucinationer men också på föråldrade källor, entitetsförväxling eller inkonsekvent data över plattformar. Missinformationskorrigering adresserar både hallucinationer och felaktigheter på källnivå som leder till felaktig varumärkesrepresentation.
Övervaka hur AI-system beskriver ditt varumärke genom att ställa frågor om ditt företag, produkter och positionering. Leta efter föråldrad information, felaktiga beskrivningar, saknade uppgifter eller att konkurrenter tillskrivs ditt innehåll. Använd övervakningsverktyg för att spåra omnämnanden i ChatGPT, Gemini och Perplexity. Kontrollera om ditt varumärke saknas i relevanta AI-svar. Jämför AI-beskrivningar med din officiella varumärkesinformation för att identifiera avvikelser.
Det är en pågående process. AI-system omvärderar kontinuerligt signaler när nytt innehåll tillkommer och äldre sidor dyker upp igen. En engångskorrigering utan löpande övervakning kommer så småningom att skrivas över av den ursprungliga missinformationen. Varumärken som lyckas behandlar AI-synlighet som ett levande system, upprätthåller konsekventa varumärkesdefinitioner över källor, granskar kataloger regelbundet och övervakar AI-omnämnanden kontinuerligt för att fånga nya fel innan de sprids.
Spåra hur AI-system som ChatGPT, Gemini och Perplexity representerar ditt varumärke. Få insikter i realtid om varumärkesomnämnanden, citeringar och synlighet över AI-plattformar med AmICited.com.
Lär dig hur du bestrider felaktig AI-information, rapporterar fel till ChatGPT och Perplexity, samt implementerar strategier för att säkerställa att ditt varumä...

Lär dig identifiera, förebygga och rätta AI-desinformation om ditt varumärke. Upptäck 7 beprövade strategier och verktyg för att skydda ditt rykte i AI-sökresul...
Diskussion i communityn om hur man bemöter felaktiga AI-nämningar och desinformation. Verkliga erfarenheter av att rätta faktamissar i ChatGPT, Perplexity och a...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.