
A/B-testning för AI-synlighet: Metodik och bästa praxis
Bemästra A/B-testning för AI-synlighet med vår omfattande guide. Lär dig GEO-experiment, metodik, bästa praxis och verkliga fallstudier för bättre AI-övervaknin...
10 min läsning

Isolerade sandlådemiljöer utformade för att validera, utvärdera och felsöka artificiella intelligensmodeller och applikationer innan produktionsdriftsättning. Dessa kontrollerade utrymmen möjliggör testning av AI-innehållets prestanda över olika plattformar, mätning av nyckeltal samt säkerställande av tillförlitlighet utan att påverka produktionssystem eller exponera känslig data.
Isolerade sandlådemiljöer utformade för att validera, utvärdera och felsöka artificiella intelligensmodeller och applikationer innan produktionsdriftsättning. Dessa kontrollerade utrymmen möjliggör testning av AI-innehållets prestanda över olika plattformar, mätning av nyckeltal samt säkerställande av tillförlitlighet utan att påverka produktionssystem eller exponera känslig data.
En AI-testmiljö är ett kontrollerat, isolerat beräkningsutrymme utformat för att validera, utvärdera och felsöka artificiella intelligensmodeller och applikationer innan de driftsätts i produktionssystem. Det fungerar som en sandlåda där utvecklare, data scientists och QA-team säkert kan köra AI-modeller, testa olika konfigurationer och mäta prestanda mot fördefinierade nyckeltal utan att påverka produktionssystem eller exponera känslig data. Dessa miljöer återskapar produktionsförhållanden men med fullständig isolering, vilket möjliggör identifiering av problem, optimering av modellbeteende och säkerställande av tillförlitlighet i olika scenarier. Testmiljön fungerar som en kritisk kvalitetsgrind i AI-utvecklingslivscykeln och överbryggar gapet mellan experimentell prototyp och driftsättning i företagsskala.

En omfattande AI-testmiljö består av flera sammankopplade tekniska lager som samverkar för att tillhandahålla fullständiga testmöjligheter. Modellkörningslagret hanterar själva inferensen och beräkningen, med stöd för flera ramverk (PyTorch, TensorFlow, ONNX) och modelltyper (LLM, computer vision, tidsserier). Databehandlingslagret hanterar testdatamängder, fixtures och syntetisk datagenerering samtidigt som dataseparation och efterlevnad upprätthålls. Utvärderingsramverket inkluderar nyckeltalsmotorer, assertionsbibliotek och poängsystem som mäter modellutdata mot förväntade resultat. Övervaknings- och loggningslagret fångar exekveringsspår, prestandanyckeltal, latenstider och felloggar för analys efter test. Orkestreringslagret hanterar testarbetsflöden, parallell körning, resursallokering och miljöetablering. Nedan följer en jämförelse av viktiga arkitekturkomponenter mellan olika typer av testmiljöer:
| Komponent | LLM-testning | Computer Vision | Tidsserier | Multimodal |
|---|---|---|---|---|
| Modellkörning | Transformer-inferens | GPU-accelererad inferens | Sekventiell bearbetning | Hybridkörning |
| Dataformat | Text/token | Bild/tensor | Numeriska sekvenser | Blandmedia |
| Utvärderingsmått | Semantisk likhet, hallucination | Noggrannhet, IoU, F1-score | RMSE, MAE, MAPE | Korsmodalsjustering |
| Latenskrav | 100-500ms typiskt | 50-200ms typiskt | <100ms typiskt | 200-1000ms typiskt |
| Isoleringsmetod | Container/VM | Container/VM | Container/VM | Firecracker microVM |
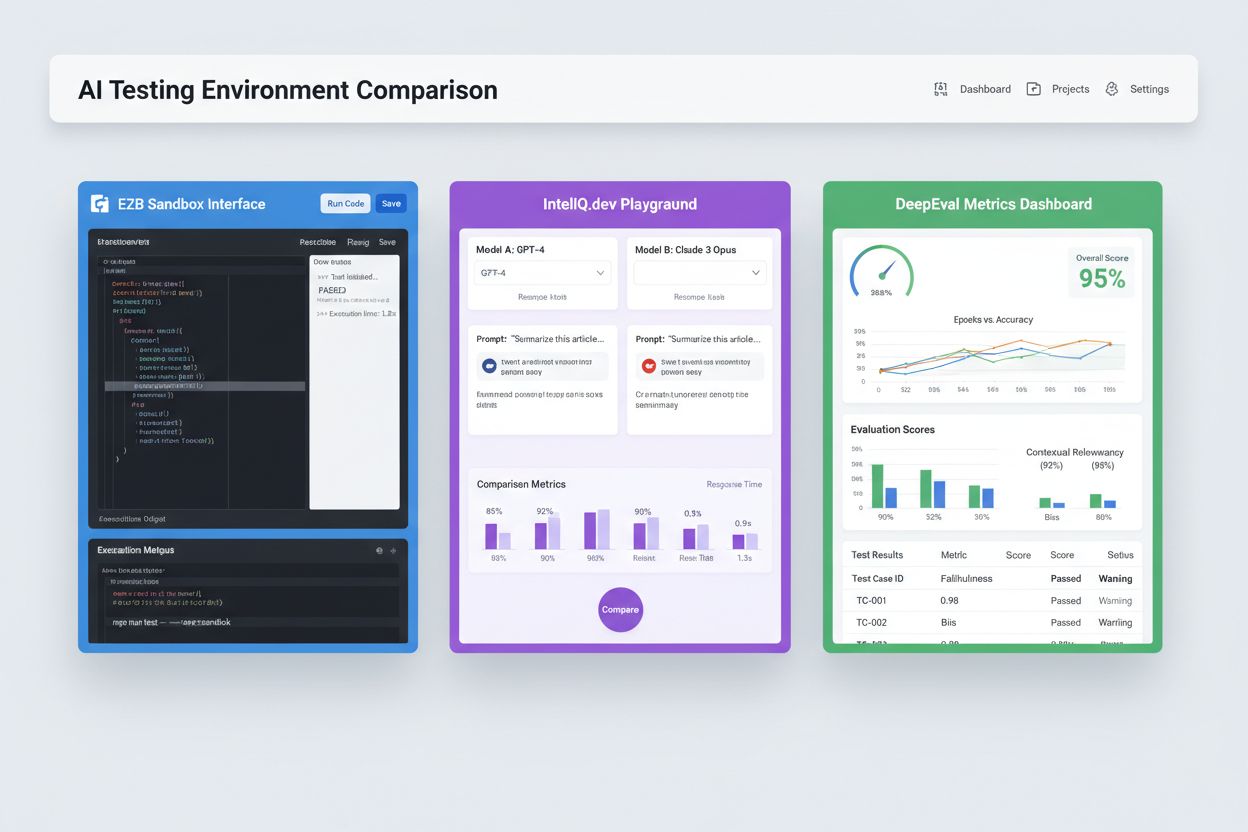
Moderna AI-testmiljöer måste stödja heterogena modele ekosystem, så att team kan utvärdera applikationer över olika LLM-leverantörer, ramverk och driftsättningsmål samtidigt. Multipla plattformstestning möjliggör för organisationer att jämföra modellutdata från OpenAI:s GPT-4, Anthropics Claude, Mistral och öppna alternativ som Llama inom samma testmiljö, vilket underlättar välgrundade modellval. Plattformar som E2B tillhandahåller isolerade sandlådor som kör kod genererad av valfri LLM, med stöd för Python, JavaScript, Ruby och C++ med fullständig filsystemåtkomst, terminalfunktioner och pakethantering. IntelIQ.dev möjliggör jämförelse sida vid sida av flera AI-modeller med enhetliga gränssnitt, så att team kan testa skyddade prompts och policybaserade mallar över olika leverantörer. Testmiljöer måste hantera:
AI-testmiljöer tjänar olika organisatoriska behov inom utveckling, kvalitetssäkring och efterlevnad. Utvecklingsteam använder testmiljöer för att validera modellbeteende under iterativ utveckling, testa promptvariationer, finjustera parametrar och felsöka oväntade utdata innan integration. Data science-team använder dessa miljöer för att utvärdera modellprestanda på hold-out-dataset, jämföra olika arkitekturer och mäta mått som noggrannhet, precision, återkallelse och F1-poäng. Produktionsövervakning innebär kontinuerlig testning av driftsatta modeller mot baslinjemått, upptäckt av prestandaförsämring och utlösning av omträningspipelines när kvalitetsgränser överskrids. Efterlevnads- och säkerhetsteam använder testmiljöer för att validera att modeller uppfyller regulatoriska krav, inte producerar partiska utdata och hanterar känslig data korrekt. Företagstillämpningar inkluderar:
AI-testningslandskapet omfattar specialiserade plattformar utformade för olika testscenarier och organisationsnivåer. DeepEval är ett öppet LLM-utvärderingsramverk med över 50 forskningsstödda mått, inklusive svarsnoggrannhet, semantisk likhet, hallucinationsdetektion och toxicitetsmätning, med inbyggd Pytest-integration för CI/CD-arbetsflöden. LangSmith (av LangChain) erbjuder omfattande insyn, utvärdering och driftsättningsfunktioner med inbyggd spårning, promptversionering och dataset-hantering för LLM-applikationer. E2B erbjuder säkra, isolerade sandlådor drivna av Firecracker microVMs, med stöd för kodexekvering med <200ms starttid, upp till 24 timmars sessioner och integration med stora LLM-leverantörer. IntelIQ.dev fokuserar på privacy-first-testning med end-to-end-kryptering, rollbaserade behörigheter och stöd för flera AI-modeller inklusive GPT-4, Claude och open source-alternativ. Följande tabell jämför viktiga funktioner:
| Verktyg | Primärt fokus | Mått | CI/CD-integration | Flermodellsstöd | Prismodell |
|---|---|---|---|---|---|
| DeepEval | LLM-utvärdering | 50+ mått | Inbyggd Pytest | Begränsat | Öppen källkod + moln |
| LangSmith | Observabilitet & utvärdering | Anpassade mått | API-baserad | LangChain-ekosystem | Freemium + företag |
| E2B | Kodexekvering | Prestandamått | GitHub Actions | Alla LLM | Betala per användning + företag |
| IntelIQ.dev | Privacy-first-testning | Anpassade mått | Arbetsflödesbyggare | GPT-4, Claude, Mistral | Prenumerationsbaserad |
Företagsklassade AI-testmiljöer måste implementera strikta säkerhetskontroller för att skydda känslig data, upprätthålla regulatorisk efterlevnad och förhindra obehörig åtkomst. Dataseparation kräver att testdata aldrig läcker till externa API:er eller tredjepartstjänster; plattformar som E2B använder Firecracker microVMs för att ge fullständig processisolering utan delad kärnåtkomst. Krypteringsstandarder bör inkludera end-to-end-kryptering för data i vila och under överföring, med stöd för HIPAA, SOC 2 Type 2 och GDPR-krav. Behörighetskontroller måste upprätthålla rollbaserade rättigheter, granskningsloggning och godkännandeflöden för känsliga testsituationer. Bästa praxis inkluderar: att använda separata testdatamängder utan produktionsdata, implementera datamaskering för personuppgifter (PII), använda syntetisk datagenerering för realistiska tester utan integritetsrisk, genomföra regelbundna säkerhetsgranskningar av testinfrastruktur och dokumentera alla testresultat för efterlevnad. Organisationer bör även implementera biasdetektion för att identifiera diskriminerande modellbeteende, använda tolkningsverktyg som SHAP eller LIME för förståelse av modellbeslut och etablera beslutsloggning för att spåra hur modeller kommer fram till specifika utdata för regulatoriskt ansvar.
AI-testmiljöer måste smidigt integreras i befintliga pipelines för kontinuerlig integration och driftsättning för att möjliggöra automatiska kvalitetsgrindar och snabba iterationer. Inbyggd CI/CD-integration gör att tester kan köras automatiskt vid kodändringar, pull requests eller schemalagda tider med plattformar som GitHub Actions, GitLab CI eller Jenkins. DeepEvals Pytest-integration gör att utvecklare kan skriva testfall som vanliga Python-tester som körs i existerande CI-arbetsflöden, med resultat rapporterade tillsammans med traditionella unittester. Automatiserad utvärdering kan mäta modellprestanda, jämföra utdata mot baslinjeversioner och blockera driftsättning om kvalitetskraven inte uppnås. Artefakthantering innebär lagring av testdataset, modellcheckpoints och utvärderingsresultat i versionskontroll eller artefaktregister för reproducerbarhet och granskningsspår. Integrationsmönster inkluderar:
Landskapet för AI-testmiljöer utvecklas snabbt för att hantera nya utmaningar inom modellkomplexitet, skala och heterogenitet. Agentisk testning blir allt viktigare i takt med att AI-system går bortom enskild modellinferens till flerstegsarbetsflöden där agenter använder verktyg, fattar beslut och interagerar med externa system—vilket kräver nya utvärderingsramverk som mäter uppgiftslösning, säkerhet och tillförlitlighet. Distribuerad utvärdering möjliggör testning i stor skala genom tusentals samtidiga testinstanser i molninfrastruktur, avgörande för reinforcement learning och storskalig modellträning. Realtidsövervakning skiftar från batchutvärdering till kontinuerlig, produktionsklassad testning som upptäcker försämrad prestanda, datadrift och framväxande bias i livesystem. Observabilitetsplattformar som AmICited blir viktiga verktyg för heltäckande AI-övervakning och synlighet, med centraliserade dashboards som spårar modellprestanda, användningsmönster och kvalitetsmått över hela AI-portföljen. Framtida testmiljöer kommer i allt högre grad att inkludera automatiserad åtgärdshantering, där system inte bara upptäcker problem utan automatiskt startar omträningspipelines eller modelluppdateringar, samt korsmodalsutvärdering, med stöd för samtidiga tester av text-, bild-, ljud- och videomodeller inom enhetliga ramverk.
En AI-testmiljö är en isolerad sandlåda där du säkert kan testa modeller, prompts och konfigurationer utan att påverka produktionssystem eller användare. Produktionsdriftsättning är den miljö där modeller betjänar riktiga användare. Testmiljöer låter dig upptäcka problem, optimera prestanda och validera ändringar innan de når produktion, vilket minskar risk och säkerställer kvalitet.
Ja, moderna AI-testmiljöer stöder testning av flera modeller samtidigt. Plattformar som E2B, IntelIQ.dev och DeepEval låter dig testa samma prompt eller indata över olika LLM-leverantörer (OpenAI, Anthropic, Mistral, etc.) samtidigt, vilket möjliggör direkt jämförelse av utdata och prestandanyckeltal.
Företagsklassade AI-testmiljöer implementerar flera säkerhetslager inklusive dataseparation (containerisering eller microVMs), end-to-end-kryptering, rollbaserade behörigheter, granskningsloggar och efterlevnadscertifieringar (SOC 2, GDPR, HIPAA). Data lämnar aldrig den isolerade miljön om den inte explicit exporteras, vilket skyddar känslig information.
Testmiljöer möjliggör efterlevnad genom att tillhandahålla granskningsspår av alla modelevalueringar, stöd för datamaskering och syntetisk datagenerering, tillämpning av behörighetskontroller och total separation av testdata från produktionssystem. Denna dokumentation och kontroll hjälper organisationer att uppfylla regulatoriska krav som GDPR, HIPAA och SOC 2.
Viktiga nyckeltal beror på användningsfall: för LLM, följ noggrannhet, semantisk likhet, hallucinationsgrad och latens; för RAG-system, mät kontextprecision/återkallelse och sanningshalt; för klassificeringsmodeller, övervaka precision, återkallelse och F1-poäng; för alla modeller, följ degradering av prestanda över tid och biasindikatorer.
Kostnaden varierar beroende på plattform: DeepEval är öppen källkod och gratis; LangSmith erbjuder ett gratisnivå med betalda planer från 39 USD/månad; E2B använder betalning per användning baserat på sandlådans körtid; IntelIQ.dev erbjuder prenumerationsbaserad prissättning. Många plattformar har även företagspriser för storskalig användning.
Ja, de flesta moderna testmiljöer stöder CI/CD-integration. DeepEval integreras nativt med Pytest, E2B fungerar med GitHub Actions och GitLab CI, och LangSmith erbjuder API-baserad integration. Detta möjliggör automatiserad testning vid varje kodändring och införandekontroller vid driftsättning.
End-to-end-testning behandlar hela din AI-applikation som en svart låda och testar slutresultatet mot förväntad output. Komponentnivåtestning utvärderar de enskilda delarna (LLM-anrop, retrievers, verktygsanvändning) separat med hjälp av spårning och instrumentering. Komponentnivåtestning ger djupare insikt om var problem uppstår, medan end-to-end-testning validerar hela systemets beteende.
AmICited spårar hur AI-system refererar till ditt varumärke och innehåll på ChatGPT, Claude, Perplexity och Google AI. Få realtidsinsyn i din AI-närvaro med heltäckande övervakning och analys.
Bemästra A/B-testning för AI-synlighet med vår omfattande guide. Lär dig GEO-experiment, metodik, bästa praxis och verkliga fallstudier för bättre AI-övervaknin...

Upptäck hur AI-certifieringar etablerar förtroende genom standardiserade ramverk, krav på transparens och tredjepartsgranskning. Lär dig om CSA STAR, ISO 42001 ...

Lär dig vad ambient AI-assistenter är, hur de fungerar i smarta hem, deras inverkan på köpbeslut och framtiden för intelligenta boendemiljöer. Omfattande guide ...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.