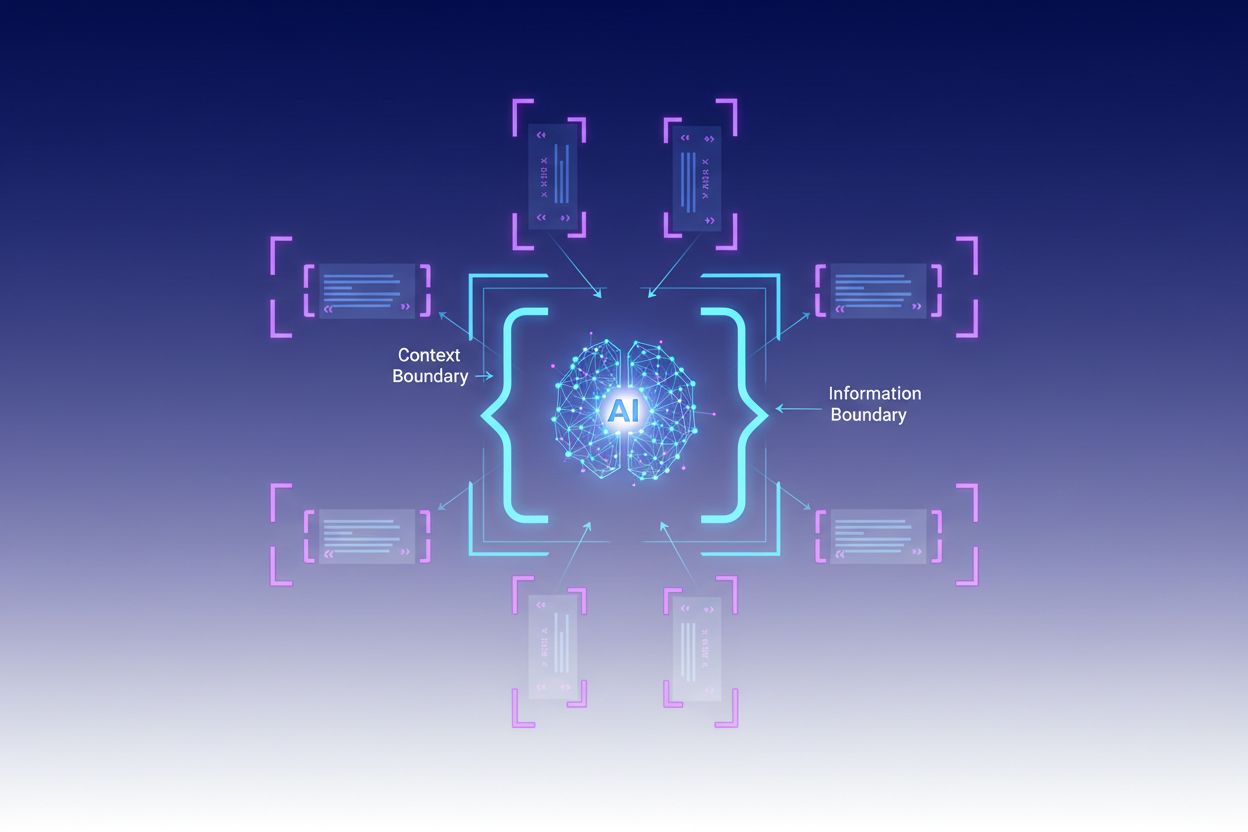
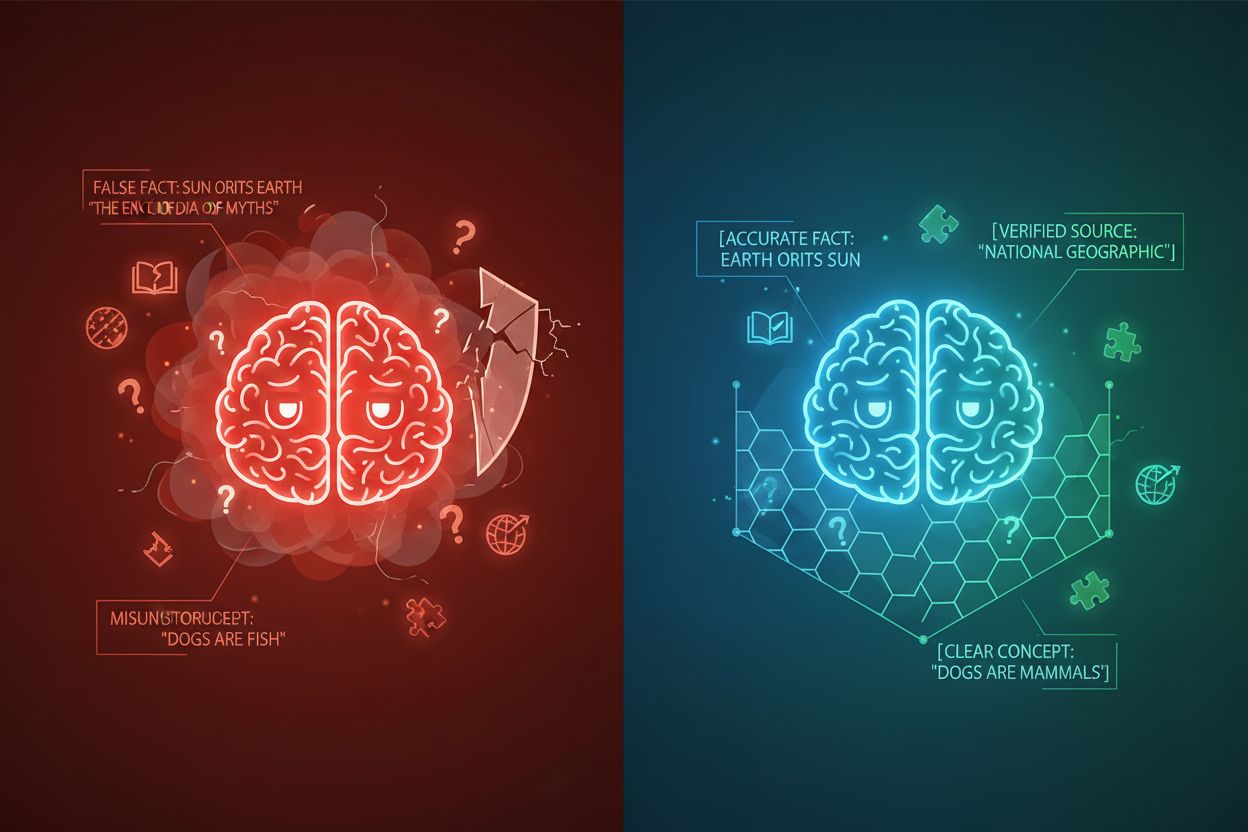
Kontextuell avgränsning är en teknik för innehållsoptimering som etablerar tydliga gränser kring information för att förhindra AI-missförstånd och hallucinationer. Den använder explicita avgränsare och kontextmarkörer för att säkerställa att AI-modeller förstår exakt var relevant information börjar och slutar, vilket förhindrar att svar genereras på antaganden eller påhittade detaljer.
Kontextuell avgränsning
Kontextuell avgränsning är en teknik för innehållsoptimering som etablerar tydliga gränser kring information för att förhindra AI-missförstånd och hallucinationer. Den använder explicita avgränsare och kontextmarkörer för att säkerställa att AI-modeller förstår exakt var relevant information börjar och slutar, vilket förhindrar att svar genereras på antaganden eller påhittade detaljer.
Vad är kontextuell avgränsning?
Kontextuell avgränsning är en teknik för innehållsoptimering som etablerar tydliga gränser kring information för att förhindra att AI misstolkar och hallucinerar. Denna metod innebär att man använder explicita avgränsare—såsom XML-taggar, markdown-rubriker eller specialtecken—för att markera början och slutet av specifika informationsblock, vilket skapar det som experter kallar en “kontextgräns”. Genom att strukturera prompter och data med dessa tydliga markörer säkerställer utvecklare att AI-modeller förstår exakt var relevant information börjar och slutar, vilket förhindrar att modellen genererar svar baserat på antaganden eller påhittade detaljer. Kontextuell avgränsning representerar en utveckling av traditionell prompt engineering och sträcker sig in i den bredare disciplinen kontextengineering, som fokuserar på att optimera all information som ges till en LLM för att uppnå önskade resultat. Tekniken är särskilt värdefull i produktionsmiljöer där noggrannhet och konsekvens är avgörande, eftersom den utgör matematiska och strukturella skyddsräcken som styr AI-beteende utan att kräva komplexa villkorslogiker.
Hallucinationsproblemet
AI-hallucination uppstår när språkmodeller genererar svar som inte är förankrade i faktisk information eller det specifika sammanhang som tillhandahållits, vilket resulterar i felaktiga fakta, vilseledande påståenden eller referenser till icke-existerande källor. Forskning visar att chatbottar hittar på fakta cirka 27 % av tiden, med 46 % av deras texter innehållande faktamissar, medan ChatGPT:s journalistiska citat var felaktiga 76 % av gångerna. Dessa hallucinationer härrör från flera källor: modeller kan lära sig mönster från partisk eller ofullständig träningsdata, missförstå relationen mellan tokens, eller sakna tillräckliga begränsningar som begränsar möjliga utdata. Konsekvenserna är allvarliga inom olika branscher—inom sjukvården kan hallucinationer leda till fel diagnoser och onödiga medicinska ingrepp; i juridiska sammanhang kan de resultera i påhittade rättsfall (som i fallet Mata v. Avianca där en advokat fick sanktioner för att ha använt ChatGPT:s falska juridiska citat); i affärslivet slösas resurser bort genom felaktiga analyser och prognoser. Det grundläggande problemet är att utan tydliga kontextgränser verkar AI-modeller i ett informationsvakuum där de är mer benägna att “fylla i luckorna” med trovärdigt klingande men felaktig information, och behandlar hallucinationer mer som en funktion än en bugg.
Hallucinationstyp
Frekvens
Påverkan
Exempel
Faktamissar
27-46%
Spridning av felinformation
Falska produktegenskaper
Källpåhitt
76% (citat)
Förtroendeförlust
Icke-existerande källhänvisningar
Missförstådda begrepp
Varierande
Felaktig analys
Fel rättspraxis
Partiska mönster
Löpande
Diskriminerande utdata
Stereotypa svar
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Effektiviteten hos kontextuell avgränsning vilar på fem grundläggande principer:
Användning av avgränsare: Använd konsekventa, otvetydiga markörer (XML-taggar som <context>, markdown-rubriker eller specialtecken) för att tydligt avgränsa informationsblock och förhindra att modellen blandar ihop gränser mellan olika datakällor eller instruktionstyper.
Kontextfönsterhantering: Fördela tokens strategiskt mellan systeminstruktioner, användarinmatning och hämtad kunskap, så att den mest relevanta informationen får modellens begränsade uppmärksamhetsbudget medan mindre viktiga detaljer filtreras bort eller hämtas vid behov.
Informationshierarki: Etablera tydliga prioriteringsnivåer för olika informationstyper och signalera för modellen vilken data som ska behandlas som auktoritativa källor kontra kompletterande kontext, vilket förhindrar lika viktning av primär och sekundär information.
Gränsdefinition: Ange uttryckligen vilken information modellen ska ta hänsyn till och vad den ska ignorera, och skapa tydliga stopp som förhindrar att modellen extrapolerar utanför angivna data eller gör antaganden om outtalad information.
Omfångsmarkörer: Använd strukturella element för att ange omfånget för instruktioner, exempel och data, så att det är tydligt om vägledningen gäller globalt, för specifika sektioner eller bara för särskilda frågetyper.
Implementeringstekniker
Implementering av kontextuell avgränsning kräver noggrann uppmärksamhet på hur information struktureras och presenteras för AI-modeller. Strukturerad indataformatering med hjälp av JSON- eller XML-scheman ger explicita fältdefinitioner som vägleder modellens beteende—till exempel skapar inneslutning av användarfrågor i <user_query>-taggar och förväntade utdata i <expected_output>-taggar tydliga gränser. Systemprompter bör organiseras i distinkta sektioner med markdown-rubriker eller XML-taggar: <background_information>, <instructions>, <tool_guidance>, och <output_description> har alla särskilda syften och hjälper modellen att förstå informationens hierarki. Få-shot-exempel bör inkludera avgränsad kontext som visar exakt hur modellen ska strukturera sina svar, med tydliga avgränsare kring in- och utdata. Verktygsdefinitioner gynnas av explicita parameterbeskrivningar och användningsbegränsningar, vilket förhindrar att modellen använder verktygen utanför avsett omfång. Retrieval-Augmented Generation (RAG)-system kan implementera kontextuell avgränsning genom att innesluta hämtade dokument i källmarkörer (<source>dokument_namn</source>) och använda grundningspoäng för att verifiera att genererade svar håller sig inom gränserna för hämtad information. Till exempel fungerar CustomGPT:s kontextgränsfunktion genom att träna modeller uteslutande på uppladdade dataset, vilket säkerställer att svar aldrig sträcker sig utanför den tillhandahållna kunskapsbasen—en praktisk tillämpning av kontextuell avgränsning på arkitekturnivå.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kontextuell avgränsning jämfört med andra tillvägagångssätt
Även om kontextuell avgränsning delar likheter med relaterade tekniker, har den en distinkt position inom AI-ingenjörskapet. Grundläggande prompt engineering fokuserar främst på att skapa effektiva instruktioner och exempel men saknar det systematiska tillvägagångssättet för att hantera alla kontextelement som kontextuell avgränsning erbjuder. Kontextengineering, den bredare disciplinen, omfattar kontextuell avgränsning som en komponent bland många—den inkluderar promptoptimering, verktygsdesign, minneshantering och dynamisk kontexthämtning, vilket gör den till ett övergripande ramverk där kontextuell avgränsning är en mer fokuserad metod. Enkel instruktionsföljning förlitar sig på modellens förmåga att förstå naturliga språkinstruktioner utan explicita strukturella gränser, vilket ofta misslyckas när instruktionerna är komplexa eller när modellen stöter på tvetydiga situationer. Skyddsräcken och valideringssystem verkar på utdata-nivå och kontrollerar svaren efter generering, medan kontextuell avgränsning fungerar på indata-nivå för att förhindra hallucinationer innan de uppstår. Den avgörande skillnaden är att kontextuell avgränsning är förebyggande och strukturell—den formar det informationslandskap modellen verkar inom—snarare än korrigerande eller reaktiv, vilket gör den mer effektiv och tillförlitlig för att upprätthålla noggrannhet i produktionssystem.
Tillämpningar i verkligheten
Kontextuell avgränsning ger mätbart värde i olika tillämpningar. Kundtjänstchattbottar använder kontextgränser för att begränsa svar till företagets godkända kunskapsbaser, vilket förhindrar att agenter hittar på produktegenskaper eller ger obehöriga löften. Juridiska dokumentanalysystem avgränsar relevant rättspraxis, lagar och prejudikat, så att AI endast refererar till verifierade källor och inte hittar på juridiska citat. Medicinska AI-system implementerar strikta kontextgränser kring kliniska riktlinjer, patientdata och godkända behandlingsprotokoll, vilket förhindrar farliga hallucinationer som kan skada patienter. Innehållsgenereringsplattformar använder kontextuell avgränsning för att upprätthålla varumärkesriktlinjer, tonkrav och faktakrav, så att genererat innehåll stämmer överens med organisationens standarder. Forsknings- och analysverktyg avgränsar primärkällor, dataset och verifierad information, vilket gör att AI kan syntetisera insikter samtidigt som tydlig källhänvisning upprätthålls och påhittade statistik eller studier förhindras. AmICited.com exemplifierar denna princip genom att övervaka hur AI-system citerar och refererar till varumärken över GPTs, Perplexity och Google AI Overviews—i praktiken spåras om AI-modeller håller sig inom lämpliga kontextgränser när de diskuterar specifika företag eller produkter, vilket hjälper organisationer att förstå om AI-system hallucinerar om deras varumärke eller återger deras information korrekt.
Bästa praxis och implementeringsstrategi
För att framgångsrikt implementera kontextuell avgränsning krävs efterlevnad av beprövade bästa praxis:
Börja med minimal kontext: Starta med den minsta möjliga informationsmängd som behövs för korrekta svar och utöka endast när tester avslöjar luckor, vilket förhindrar kontextförorening och bibehåller modellens fokus.
Använd konsekventa avgränsningsmönster: Etablera och upprätthåll enhetliga avgränsningskonventioner i hela ditt system, vilket gör det enklare för modellen att känna igen gränser och minskar förvirring från inkonsekvent formatering.
Testa och validera gränser: Testa systematiskt om modellen respekterar definierade gränser genom att försöka få den att gå utanför dem, identifiera och åtgärda brister innan driftsättning.
Övervaka kontextglidning: Spåra kontinuerligt om modellens svar förblir inom avsedda gränser över tid, eftersom modellbeteendet kan förändras med olika indata eller när kunskapsbaser utvecklas.
Implementera återkopplingsslingor: Skapa mekanismer för användare eller mänskliga granskare att flagga fall där modellen överskrider sina gränser, och använd feedbacken för att förfina kontextdefinitioner och förbättra framtida prestanda.
Versionshantera kontextdefinitioner: Behandla kontextgränser som kod, med versionshistorik och dokumentation av ändringar, vilket möjliggör återställning om nya gränsdefinitioner ger sämre resultat.
Verktyg och plattformar med stöd för kontextuell avgränsning
Flera plattformar har byggt in stöd för kontextuell avgränsning i sina kärnerbjudanden. CustomGPT.ai implementerar kontextgränser genom sin “context boundary”-funktion, som fungerar som en skyddsvägg så att AI bara använder data som tillhandahålls av användaren och aldrig hämtar från allmän kunskap eller hittar på information—detta tillvägagångssätt har visat sig effektivt för organisationer som MIT som kräver absolut noggrannhet i kunskapsleverans. Anthropic’s Claude betonar kontextengineering-principer och erbjuder detaljerad dokumentation om hur man strukturerar prompter, hanterar kontextfönster och implementerar skyddsräcken som håller svar inom definierade gränser. AWS Bedrock Guardrails erbjuder automatiserade resonemangskontroller som verifierar genererat innehåll mot matematiska, logikbaserade regler, med grundningspoäng som indikerar om svaren håller sig inom källmaterialet (poäng över 0,85 krävs för finansapplikationer). Shelf.io erbjuder RAG-lösningar med kontexthanteringsfunktioner, vilket gör det möjligt för organisationer att implementera retrieval-augmented generation samtidigt som strikta gränser för vilken information modellen kan komma åt och referera till upprätthålls. AmICited.com har en kompletterande roll genom att övervaka hur AI-system citerar och refererar till ditt varumärke på flera AI-plattformar, vilket hjälper dig att förstå om AI-modeller respekterar lämpliga kontextgränser när de diskuterar din organisation eller håller sig till korrekt, verifierad information om ditt varumärke—och i praktiken ger insyn i om kontextuell avgränsning fungerar effektivt i verkligheten.
Vanliga frågor
Vad är skillnaden mellan kontextuell avgränsning och prompt engineering?
Prompt engineering fokuserar främst på att skapa effektiva instruktioner och exempel, medan kontextuell avgränsning är ett systematiskt tillvägagångssätt för att hantera alla kontextelement genom explicita avgränsare och gränser. Kontextuell avgränsning är mer strukturerad och förebyggande, och arbetar på indata-nivå för att förhindra hallucinationer innan de uppstår, medan prompt engineering är bredare och inkluderar olika optimeringstekniker.
Hur förhindrar kontextuell avgränsning AI-hallucinationer?
Kontextuell avgränsning förhindrar hallucinationer genom att etablera tydliga informationsgränser med hjälp av avgränsare som XML-taggar eller markdown-rubriker. Detta talar om för AI-modellen exakt vilken information den ska ta hänsyn till och vad den ska ignorera, vilket förhindrar att den hittar på detaljer eller gör antaganden om information som inte anges. Genom att begränsa modellens uppmärksamhet till definierade gränser minskar sannolikheten för att generera felaktiga fakta eller påhittade källor.
Vilka är de vanligaste avgränsarna som används i kontextuell avgränsning?
Vanliga avgränsare inkluderar XML-taggar (som och ), markdown-rubriker (# Avsnittsnamn), specialtecken (---, ===) och strukturerade format som JSON eller YAML. Det viktigaste är konsekvens – att använda samma avgränsningsmönster genom hela systemet hjälper modellen att pålitligt känna igen gränser och minskar förvirring från inkonsekvent formatering.
Kan kontextuell avgränsning användas med alla AI-modeller?
Principerna för kontextuell avgränsning kan tillämpas på de flesta moderna språkmodeller, även om effektiviteten varierar. Modeller som är tränade för bättre instruktionsefterföljelse (som Claude, GPT-4 och Gemini) tenderar att respektera gränser mer pålitligt. Tekniken fungerar bäst tillsammans med modeller som stöder strukturerade utdata och är tränade på varierad, välformaterad data.
Hur implementerar jag kontextuell avgränsning i mina AI-applikationer?
Börja med att organisera dina systemprompter i tydliga sektioner med hjälp av tydliga avgränsare. Strukturera in- och utdata med JSON- eller XML-scheman. Använd konsekventa avgränsningsmönster överallt. Implementera få-shot-exempel som visar modellen exakt hur den ska respektera gränser. Testa omfattande för att säkerställa att modellen respekterar definierade gränser och övervaka prestanda över tid för att upptäcka kontextglidning.
Vilka är prestandaeffekterna av att använda kontextuell avgränsning?
Kontextuell avgränsning kan öka tokenanvändningen något på grund av extra avgränsare och strukturella markörer, men detta uppvägs vanligtvis av förbättrad noggrannhet och färre hallucinationer. Tekniken förbättrar faktiskt effektiviteten genom att hindra modellen från att slösa tokens på påhittad information. I produktionssystem väger noggrannhetsvinsterna vida upp den minimala tokenkostnaden.
Hur relaterar kontextuell avgränsning till Retrieval-Augmented Generation (RAG)?
Kontextuell avgränsning och RAG är kompletterande tekniker. RAG hämtar relevant information från externa källor, medan kontextuell avgränsning säkerställer att modellen håller sig inom gränserna för den hämtade informationen. Tillsammans skapar de ett kraftfullt system där modellen kan komma åt extern kunskap samtidigt som den är begränsad till att endast referera till verifierade, hämtade källor.
Vilka verktyg stöder kontextuell avgränsning direkt?
Flera plattformar har inbyggt stöd: CustomGPT.ai erbjuder funktioner för kontextgränser, Anthropic's Claude tillhandahåller dokumentation om kontextengineering och stöd för strukturerad utdata, AWS Bedrock Guardrails inkluderar automatiserade resonemangskontroller, och Shelf.io erbjuder RAG med kontexthantering. AmICited.com övervakar hur AI-system citerar ditt varumärke och hjälper dig verifiera att kontextuell avgränsning fungerar effektivt.
Övervaka hur AI refererar till ditt varumärke
Kontextuell avgränsning säkerställer att AI-system ger korrekt information om ditt varumärke. Använd AmICited för att spåra hur AI-modeller citerar och refererar till ditt innehåll över GPTs, Perplexity och Google AI Overviews.
Vad är ett kontextfönster och varför ska innehållsmarknadsförare bry sig om det?
Diskussion i communityn om AI:s kontextfönster och dess implikationer för innehållsmarknadsföring. Förstå hur kontextgränser påverkar AI:s bearbetning av ditt i...
Kontextfönster förklarat: det maximala antalet tokens en LLM kan bearbeta åt gången. Lär dig hur kontextfönster påverkar AI-noggrannhet, hallucinationer och var...
Lär dig vad kontextfönster är i AI-språkmodeller, hur de fungerar, deras påverkan på modellprestanda och varför de är viktiga för AI-drivna applikationer och öv...
8 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.