
Entity Recognition
Entity Recognition är en AI NLP-förmåga som identifierar och kategoriserar namngivna entiteter i text. Lär dig hur det fungerar, dess tillämpningar inom AI-över...
9 min läsning

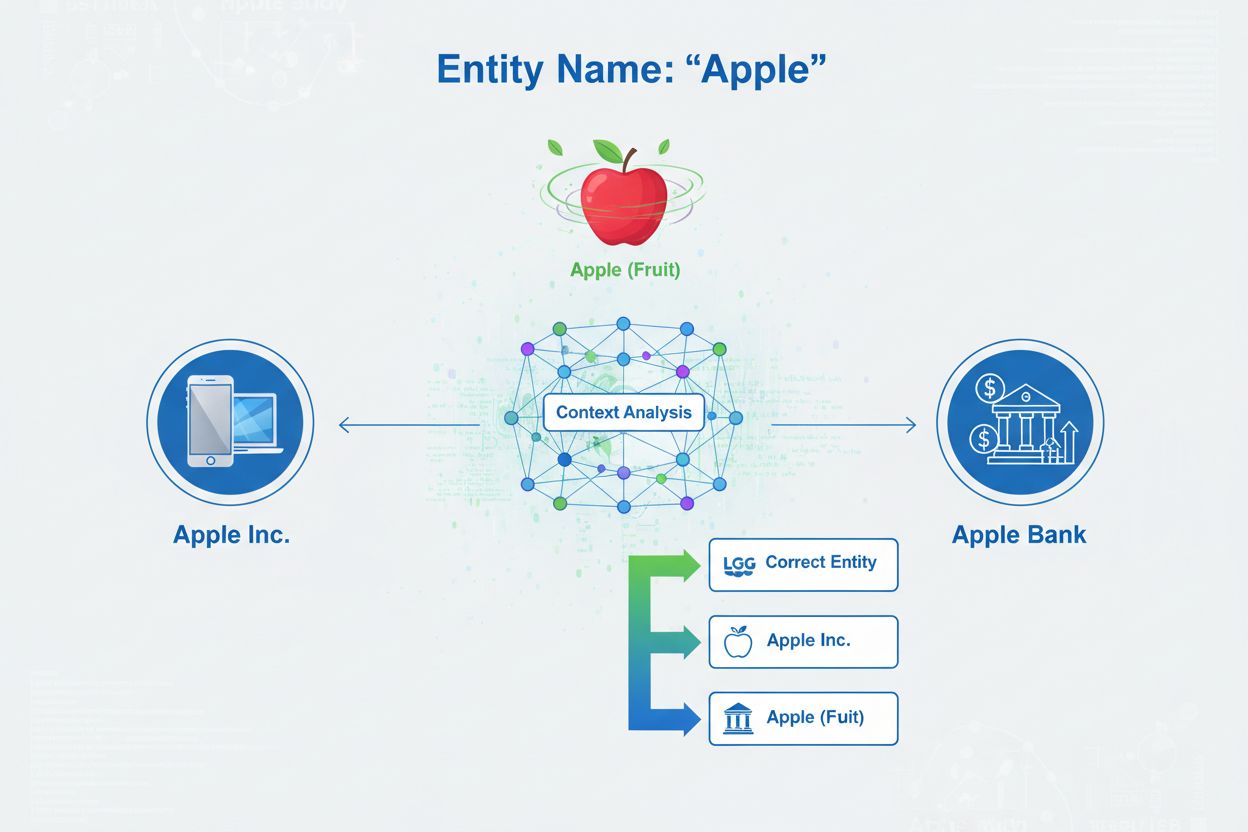
Entitetsdisambiguering är processen att avgöra vilken specifik entitet en viss nämning syftar på när flera entiteter delar samma namn. Det hjälper AI-system att korrekt förstå och citera innehåll genom att lösa tvetydigheter i namngivna entitetsreferenser, vilket säkerställer att nämningar av ‘Apple’ korrekt identifierar om referensen gäller Apple Inc., frukten eller någon annan entitet med samma namn.
Entitetsdisambiguering är processen att avgöra vilken specifik entitet en viss nämning syftar på när flera entiteter delar samma namn. Det hjälper AI-system att korrekt förstå och citera innehåll genom att lösa tvetydigheter i namngivna entitetsreferenser, vilket säkerställer att nämningar av 'Apple' korrekt identifierar om referensen gäller Apple Inc., frukten eller någon annan entitet med samma namn.
Entitetsdisambiguering är processen att avgöra vilken specifik entitet en viss nämning syftar på när flera entiteter delar samma namn eller liknande referenser. Inom artificiell intelligens och naturlig språkbehandling (NLP) säkerställer entitetsdisambiguering att när ett AI-system stöter på en namngiven entitet i text, identifierar det korrekt vilket verkligt objekt, person, organisation eller plats som avses. Detta skiljer sig grundläggande från namngiven entitetsigenkänning (NER), som bara identifierar att en entitet existerar och klassificerar den i en kategori som “person”, “organisation” eller “plats”. Medan NER svarar på frågan “Finns det en entitet här?”, svarar entitetsdisambiguering på “Vilken specifik entitet är detta?” Till exempel, när man behandlar meningen “Apple var Steve Jobs hjärtebarn”, identifierar NER “Apple” som en organisation, men entitetsdisambiguering avgör om detta syftar på Apple Inc., teknikföretaget, eller möjligtvis en annan entitet med samma namn. Denna åtskillnad är avgörande för AI-system som behöver förstå och citera innehåll korrekt, vilket är anledningen till att AmICited.com övervakar hur AI-system som ChatGPT, Perplexity och Google AI Overviews hanterar entitetsdisambiguering när de genererar svar om varumärken och organisationer.
Det grundläggande problem som entitetsdisambiguering löser är tvetydighet—det faktum att många entitetsnamn kan syfta på flera olika verkliga objekt. Denna tvetydighet skapar stora utmaningar för AI-system som försöker förstå och generera korrekt innehåll. Enligt Stanford AI Index 2024 innehåller över 18 % av LLM-svar som rör varumärkesentiteter antingen hallucinationer eller felaktiga entitetstilldelningar, vilket betyder att AI-system ofta förväxlar en entitet med en annan eller genererar felaktig information om entiteter. Denna felfrekvens har allvarliga konsekvenser för varumärkesrepresentation och innehållsnoggrannhet. När ett AI-system felidentifierar en entitet kan det ge felaktig information, tillskriva uttalanden till fel organisation eller missa att citera rätt källa.
| Entitetsnamn | Möjliga betydelser | AI-förväxlingsfrekvens |
|---|---|---|
| Apple | Teknikföretag / Frukt / Bank | Hög |
| Delta | Flygbolag / Blandarföretag / Grekisk bokstav | Hög |
| Jaguar | Biltillverkare / Djurart | Medel |
| Amazon | E-handelsföretag / Regnskog / Flod | Hög |
| Orange | Färg / Frukt / Telekomföretag | Medel |
Konsekvenserna av bristfällig entitetsdisambiguering går längre än enkla faktafel. För innehållsskapare och varumärken kan felidentifiering i AI-genererade svar leda till förlorad synlighet, felaktig tillskrivning och skada på varumärkets rykte. När en användare frågar ett AI-system om “Delta” kanske de söker information om Delta Airlines, men om systemet förväxlar det med Delta Blandarföretag får användaren irrelevant information. Det är därför AmICited.com övervakar hur AI-system disambiguera entiteter—för att hjälpa varumärken att förstå om de identifieras och citeras korrekt i AI-genererat innehåll över flera plattformar.
Entitetsdisambiguering sker genom en systematisk process som kombinerar flera NLP-tekniker för att lösa tvetydighet och korrekt identifiera entiteter. Att förstå denna process förklarar varför vissa AI-system presterar bättre än andra när det gäller citeringsnoggrannhet.
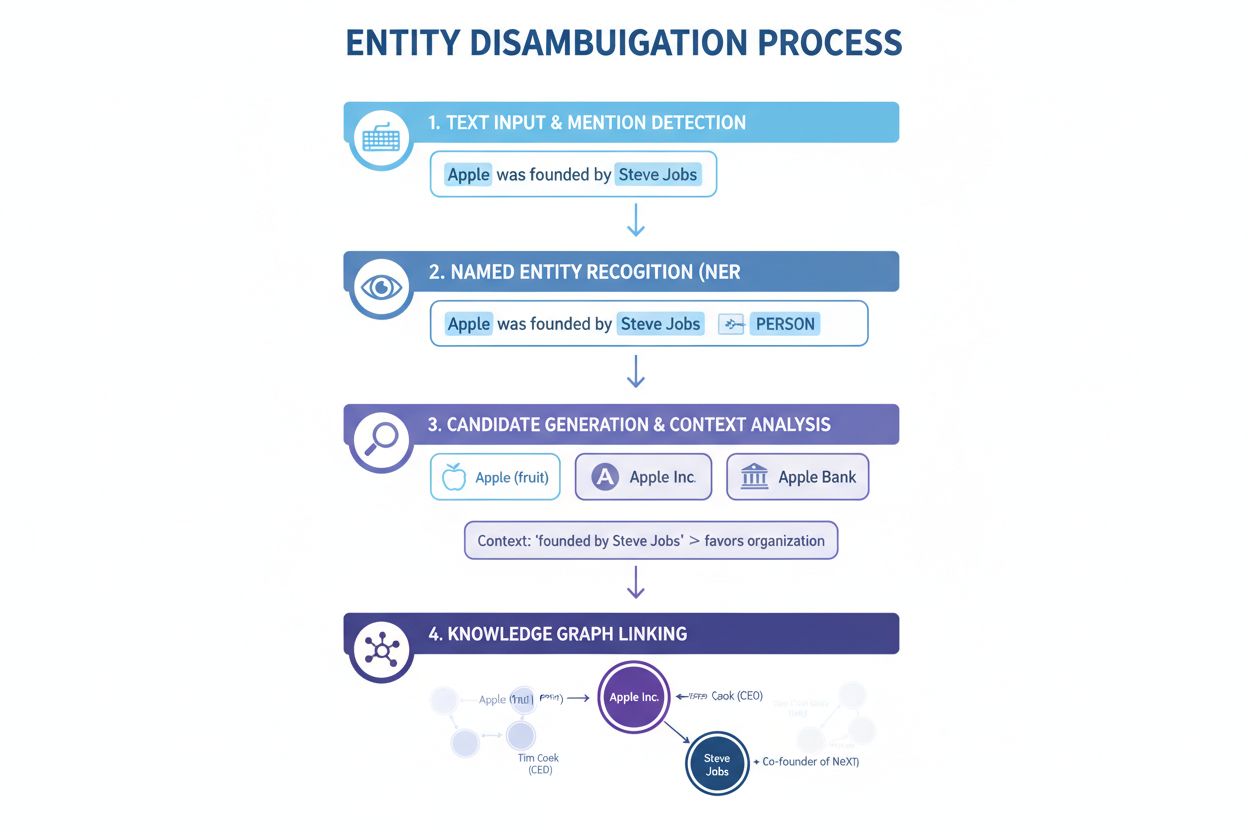
Namngiven entitetsigenkänning (NER): Första steget är att identifiera och klassificera namngivna entiteter i text. NER-system skannar textdata och hittar entitetsnämningar, och tilldelar dem fördefinierade kategorier som person, organisation, plats, produkt eller datum. Till exempel, i meningen “Apple var Steve Jobs hjärtebarn”, identifierar NER både “Apple” och “Steve Jobs” som entiteter och klassificerar dem som organisation respektive person. Detta grundläggande steg är nödvändigt eftersom disambiguering inte kan ske utan att först identifiera vilka entiteter som finns i texten.
Entitetskategorisering: När entiteterna är identifierade måste de kategoriseras mer precist. Detta innebär inte bara bred klassificering utan även att förstå den specifika typen och kontexten för varje entitet. Systemet analyserar omgivande text för att förstå om “Apple” förekommer i ett tekniksammanhang (tyder på Apple Inc.), ett matsammanhang (frukten) eller ett finansiellt sammanhang (Apple Bank). Denna kontextanalys hjälper till att smalna av alternativen före själva disambigueringen.
Disambiguering: Detta är kärnsteget där systemet avgör vilken specifik entitet som avses. Systemet utvärderar flera kandidater som matchar det identifierade namnet och använder olika signaler—inklusive kontext, entitetsbeskrivningar, semantiska relationer och kunskapsgrafinformation—för att välja den troligaste entiteten. För “Apple var Steve Jobs hjärtebarn” känner systemet igen att Steve Jobs är starkt förknippad med Apple Inc., vilket gör det till det korrekta valet.
Länkning till kunskapsbas: Slutsteget är att länka den disambiguerade entiteten till en unik identifierare i en extern kunskapsbas eller kunskapsgraf, såsom Wikidata, Wikipedia eller en proprietär databas. Denna länkning bekräftar entitetens identitet och berikar texten med semantisk information för vidare bearbetning och analys. Entiteten tilldelas en unik URI (Uniform Resource Identifier) som tjänar som definitiv referenspunkt.
Olika metoder för entitetsdisambiguering har utvecklats över tid, var och en med sina fördelar och begränsningar. Att förstå dessa metoder förklarar varför moderna AI-system varierar i disambigueringens noggrannhet.
Regelbaserade metoder: Dessa system använder fördefinierade språkliga regler och heuristiska mönster för att disambiguera entiteter. De kan tillämpa regler som “om ‘Apple’ förekommer nära ‘iPhone’ eller ‘MacBook’, syftar det på Apple Inc.” eller “om ‘Delta’ förekommer nära ‘flygbolag’ eller ‘flyg’, syftar det på Delta Airlines.” Regelbaserade system är tolkbara och kräver inte stora träningsdata, men har svårt för nya sammanhang och kan inte anpassa sig till nya betydelser utan manuella uppdateringar.
Maskininlärningsmetoder: Övervakade maskininlärningsmodeller lär sig från annoterad träningsdata att förutsäga rätt entitet baserat på kontextuella egenskaper. Dessa system extraherar egenskaper från omgivande text och använder algoritmer som Support Vector Machines eller Random Forests för att klassificera vilken entitet som är mest sannolik. Maskininlärning är mer flexibel än regelbaserade system men kräver mycket märkta träningsdata och kan ha svårt för okända entiteter.
Djupinlärning och transformerbaserade modeller: Modern entitetsdisambiguering förlitar sig alltmer på transformerarkitekturer som BERT, RoBERTa, och specialiserade modeller som GENRE och BLINK. Dessa modeller använder neurala nätverk för att förstå kontext på djupare nivå, fånga semantiska relationer och nyanserade språkmönster. Transformerbaserade modeller uppnår överlägsen prestanda på standardbenchmarks och hanterar komplexa disambigueringsscenarier bättre. Exempelvis använder Ontotexts CEEL-system (Common English Entity Linking) transformerbaserad arkitektur optimerad för CPU-effektivitet med hög noggrannhet, och når 96 % entitetsigenkänning och 76 % entitetslänkning på standardbenchmarks.
Kunskapsgrafintegration: Moderna system kombinerar i allt högre grad maskininlärning med kunskapsgrafer—strukturerade databaser som representerar entiteter och deras relationer. Kunskapsgrafer ger rik kontextuell information om entiteter, deras egenskaper och hur de relaterar till andra entiteter. Genom att fråga kunskapsgrafer under disambigueringen kan systemen få tillgång till metadata, beskrivningar och relationsinformation som hjälper till att lösa tvetydigheter mer korrekt.
Entitetsdisambiguering har blivit avgörande inom många branscher och tillämpningar, där var och en drar nytta av korrekt identifiering och citering av entiteter.
Sökmotorer: Google, Bing och andra sökmotorer förlitar sig starkt på entitetsdisambiguering för att leverera relevanta resultat. När en användare söker efter “Apple” måste sökmotorn avgöra om det avser Apple Inc., frukten eller en annan entitet med det namnet. Sökmotorer använder frågekontext, användarhistorik och kunskapsgrafer för att disambiguera och visa de mest relevanta resultaten. Det är därför sökresultat för “Apple” oftast visar teknikföretaget först—systemet har lärt sig att det är den vanligaste avsedda entiteten.
Media och publicering: Nyhetsorganisationer och innehållsplattformar använder entitetsdisambiguering för att förbättra innehållsupptäckbarhet och länka relaterade artiklar. När en nyhetsartikel nämner “Apple” kan systemet automatiskt länka till Apple Inc:s kunskapsbaspost, vilket ger läsarna ytterligare kontext och relaterade artiklar. Detta ökar engagemanget och hjälper läsare att förstå nyheternas sammanhang.
Hälso- och sjukvård: Medicinska institutioner använder entitetsdisambiguering för att korrekt identifiera läkemedel, sjukdomar och medicinska procedurer i patientjournaler och vetenskaplig litteratur. Att disambiguera läkemedelsnamn är särskilt viktigt—“aspirin” kan avse den generiska substansen, ett specifikt varumärke eller en dosvariant. Noggrann disambiguering säkerställer att vårdpersonal får rätt information och att patientjournaler organiseras korrekt.
Finansiella tjänster: Investeringsföretag och finansanalytiker använder entitetsdisambiguering för att följa företagsnämningar i nyheter, rapporter och marknadsdata. Vid marknadsanalys behöver ett företag korrekt identifiera alla nämningar av ett specifikt bolag i olika datakällor. Entitetsdisambiguering säkerställer att “Apple”-nämningar korrekt tillskrivs Apple Inc. och inte andra entiteter, vilket möjliggör korrekt riskbedömning och portföljanalys.
E-handel: Onlineåterförsäljare använder entitetsdisambiguering för att matcha produktnämningar mot faktiska produkter i sina kataloger. När en kund söker efter “Apple laptop” måste systemet disambiguera “Apple” som företaget och matcha mot relevanta produkter. Detta förbättrar sökträffsäkerheten och hjälper kunder hitta det de söker mer effektivt.
AmICited.com tillämpar principer för entitetsdisambiguering för att övervaka hur AI-system som ChatGPT, Perplexity och Google AI Overviews hanterar varumärkesnämningar. Genom att följa om dessa system korrekt disambiguera varumärkesentiteter och citerar dem rätt, hjälper AmICited varumärken att förstå sin synlighet och representation i AI-genererat innehåll.
Kunskapsgrafer har blivit fundamentala i moderna entitetsdisambigueringssystem och tillhandahåller strukturerade representationer av entiteter och deras relationer. En kunskapsgraf är i princip en databas av entiteter (noder) och relationerna mellan dem (kanter). Varje entitetsnod innehåller metadata som namn, beskrivning, typ och egenskaper. Till exempel kan entiteten “Apple Inc.” i en kunskapsgraf ha egenskaper som “grundat 1976”, “huvudkontor i Cupertino”, “bransch: teknik” och relationer som “grundad av Steve Jobs” och “producerar iPhone”.
När ett entitetsdisambigueringssystem stöter på en tvetydig nämning kan det fråga kunskapsgrafen för att få tillgång till rik kontextuell information om kandidaterna. Denna information hjälper systemet att fatta mer välgrundade beslut. Om systemet till exempel försöker disambiguera “Apple” och finner att omgivande text nämner “Steve Jobs”, kan det fråga kunskapsgrafen och upptäcka att Steve Jobs är starkt förknippad med Apple Inc., vilket gör det till det mest sannolika valet. Kunskapsgrafer som Wikidata och Wikipedia erbjuder publikt tillgänglig entitetsinformation som många AI-system använder vid inferens. Proprietära kunskapsgrafer byggda av företag som Google och Microsoft ger ytterligare domänspecifik information. Integrationen av kunskapsgrafer med maskininlärningsmodeller har avsevärt förbättrat disambigueringens noggrannhet, eftersom systemen nu kan kombinera inlärda mönster med strukturerad faktisk information.
Trots stora framsteg står entitetsdisambigueringssystem inför flera bestående utmaningar som begränsar deras noggrannhet och tillämpbarhet.
Polysemi och tvetydighet: Många entitetsnamn har flera legitima betydelser, och kontexten räcker ibland inte för att disambiguera dem. “Bank” kan syfta på en finansiell institution eller en flodbank. “Trana” kan betyda en fågel eller en byggkran. Vissa entitetsnamn är så tvetydiga att även människor har svårt att avgöra avsedd betydelse utan mer kontext. AI-system måste lära sig att känna igen när kontexten är otillräcklig och hantera sådana fall på ett smidigt sätt.
Nya och framväxande entiteter: Kunskapsbaser och träningsdata blir föråldrade när nya entiteter tillkommer. När ett nytt företag startas eller en ny produkt lanseras har systemen kanske inte information om detta i sina kunskapsbaser. Zero-shot entity linking—förmågan att disambiguera entiteter som inte setts under träning—är fortfarande en utmaning. System måste kunna känna igen att en entitet är ny och hantera det korrekt istället för att felaktigt matcha mot en befintlig med liknande namn.
Namnvarianter och stavfel: Entiteter har ofta flera namn, förkortningar och varianter. “United States”, “USA”, “U.S.” och “America” syftar alla på samma entitet. Stavfel och felskrivningar komplicerar ytterligare. System måste känna igen dessa varianter och korrekt mappa dem till den kanoniska entiteten. Detta är särskilt utmanande i användargenererat innehåll där stavfel är vanliga.
Ofullständig eller föråldrad data: Kunskapsbaser kan innehålla ofullständig information om entiteter, eller så kan informationen bli föråldrad när entiteter förändras. Ett företags huvudkontor kan flytta, ledningen kan bytas ut eller företaget kan köpas upp. Om kunskapsbasen inte uppdateras snabbt kan systemet använda föråldrad information för beslut.
Skalbarhet och prestanda: Att bearbeta stora mängder text med hög noggrannhet i entitetsdisambiguering kräver betydande beräkningsresurser. Realtidsdisambiguering för webbskala är kostsamt. System måste balansera noggrannhet med hastighet och kostnad, vilket ofta kräver kompromisser som kan sänka kvaliteten.
För varumärken och innehållsskapare är förståelse för entitetsdisambiguering avgörande för att säkerställa korrekt representation i AI-genererat innehåll. I takt med att AI-system blir allt mer inflytelserika i hur information upptäcks och konsumeras, måste varumärken ta proaktiva steg för att säkerställa att de disambiguerares och citeras korrekt.
Strategier för disambiguering i förväg: Varumärken kan genomföra strategier för att göra sina entiteter enklare för AI-system att disambiguera korrekt. Det innebär att skapa tydliga, distinkta digitala signaler som gör att AI-system kan identifiera varumärket otvetydigt. En nyckelstrategi är att implementera strukturerad data med Schema.org-markering och JSON-LD-format på varumärkets webbplats. Denna strukturerade data informerar AI-system om varumärkets identitet, inklusive det officiella namnet, beskrivning, logotyp, huvudkontor och andra utmärkande egenskaper. När AI-system stöter på varumärkesnamnet kan de referera till den strukturerade datan för att bekräfta rätt entitet.
Optimering i kunskapsgrafer: Varumärken bör säkerställa närvaro i stora kunskapsgrafer som Wikidata och Wikipedia. Detta innebär att skapa eller upprätthålla korrekta Wikipedia-artiklar, säkerställa att Wikidata-poster är kompletta och aktuella, samt bygga relationer mellan varumärkesentiteten och relaterade entiteter. Ju mer omfattande och korrekt varumärkets kunskapsgraf är, desto mer information har AI-system tillgängligt för disambiguering.
Kontextuell innehållsstrategi: Varumärken kan skapa innehåll som tydligt ger kontext om deras identitet och särskiljer dem från andra entiteter med liknande namn. Innehåll som explicit nämner bransch, produkter, grundare och unika värden hjälper AI-system att förstå varumärkets särdrag. Denna kontext blir en del av träningsdata och kontext som AI-system använder för disambiguering.
Citeringsövervakning: Verktyg som AmICited.com gör det möjligt för varumärken att övervaka hur AI-system disambiguera och citerar deras varumärke på olika plattformar. Genom att följa om ChatGPT, Perplexity, Google AI Overviews och andra system korrekt identifierar och citerar varumärket kan man upptäcka disambigueringsfel och vidta åtgärder. Denna övervakning är avgörande för att förstå varumärkets synlighet i den generativa AI-eran.
Generative Engine Optimization (GEO): I takt med att entitetsdisambiguering blir viktigare för AI-synlighet bör varumärken införliva entitetsoptimering i sin bredare Generative Engine Optimization-strategi. Det innebär att säkerställa att varumärkesentiteten är tydligt definierad, väldokumenterad och lätt att särskilja från konkurrerande entiteter. GEO omfattar inte bara traditionell SEO utan även optimering för hur AI-system förstår och representerar varumärken.
Entitetsdisambiguering fortsätter att utvecklas i takt med att AI-teknologin avancerar och nya utmaningar uppstår. Flera trender formar framtiden för denna kritiska kapacitet.
Flerspråkig entitetsdisambiguering: I takt med att AI-system blir mer globala blir förmågan att disambiguera entiteter över flera språk allt viktigare. Ett namn kan stavas olika på olika språk, och samma entitet kan kallas olika i olika språkkontexter. Avancerade flerspråkiga modeller utvecklas för att hantera entitetsdisambiguering över språkgränser, vilket möjliggör verkligt globala AI-system.
Realtidsdisambiguering i stora språkmodeller: Moderna stora språkmodeller som GPT-4 och Claude inkorporerar i allt högre grad realtidsdisambiguering under textgenerering. Istället för att enbart förlita sig på träningsdata kan dessa modeller fråga kunskapsgrafer och externa databaser vid inferens för att verifiera entitetsinformation och säkerställa korrekt disambiguering. Denna kapacitet förbättrar citeringsnoggrannhet och minskar hallucinationer.
Förbättrad zero-shot learning: Framtida system för entitetsdisambiguering kommer sannolikt att prestera bättre på entiteter som inte setts under träning. Framsteg inom fåskotts- och zero-shot-inlärning gör att systemen bättre kan disambiguera nya entiteter, vilket minskar behovet av frekvent omskolning och gör systemen mer anpassningsbara.
Integration med Retrieval-Augmented Generation (RAG): Retrieval-augmented generation-system som kombinerar språkmodeller med informationshämtning blir allt populärare. Dessa system kan hämta relevant entitetsinformation från kunskapsbaser under textgenerering, vilket förbättrar disambigueringens noggrannhet och citeringskvalitet. Denna integration är ett stort steg framåt för säker AI-citering.
Standardisering och interoperabilitet: I takt med att entitetsdisambiguering blir allt viktigare för AI-system är det troligt att branschstandarder för entitetsrepresentation och disambiguering utvecklas. Dessa standarder möjliggör bättre interoperabilitet mellan olika system och kunskapsbaser, vilket gör det enklare för AI att använda entitetsinformation konsekvent över plattformar.
Entitetsdisambiguering har utvecklats från en nischuppgift inom NLP till en kritisk funktion för att AI-system ska förstå och representera information korrekt. I takt med att AI blir allt mer inflytelserikt för hur information upptäcks och konsumeras kommer vikten av noggrann entitetsdisambiguering bara att öka. För varumärken, innehållsskapare och organisationer är förståelse och optimering för entitetsdisambiguering avgörande för att upprätthålla synlighet och säkerställa korrekt representation i den generativa AI-eran.
Namngiven entitetsigenkänning identifierar att en entitet finns i texten och klassificerar den i kategorier som person, organisation eller plats. Entitetsdisambiguering går längre genom att avgöra vilken specifik entitet som refereras när flera entiteter delar samma namn. Till exempel identifierar NER 'Apple' som en organisation, medan entitetsdisambiguering avgör om det gäller Apple Inc., Apple Bank eller en annan entitet.
Entitetsdisambiguering säkerställer att AI-system korrekt förstår vilken entitet som diskuteras och citerar den korrekt. Enligt Stanford AI Index 2024 innehåller över 18 % av LLM-svar som handlar om varumärkesentiteter hallucinationer eller felaktiga tilldelningar. Noggrann entitetsdisambiguering förhindrar att AI-system förväxlar en entitet med en annan, vilket är avgörande för att upprätthålla varumärkesrykte och citeringsnoggrannhet.
Kunskapsgrafer tillhandahåller strukturerad information om entiteter och deras relationer. När ett AI-system stöter på en tvetydig entitetsnämning kan det fråga kunskapsgrafen för att få tillgång till metadata, beskrivningar och relationsinformation om kandidaterna. Denna kontextuella information hjälper systemet att fatta mer välgrundade beslut och välja rätt entitet.
Ja, genom zero-shot entity linking-angreppssätt. Moderna system kan känna igen när en entitet är ny och hantera det korrekt istället för att felaktigt matcha den mot en befintlig entitet. Dock är detta fortfarande en utmaning, och systemen presterar bättre när nya entiteter har tydliga kontextsignaler som särskiljer dem från befintliga entiteter.
Noggrann entitetsdisambiguering säkerställer att ditt varumärke identifieras och citeras korrekt i AI-genererade svar. När AI-system disambiguera ditt varumärke korrekt får användarna korrekt information om din organisation, vilket förbättrar synlighet och rykte. Dålig disambiguering kan leda till att ditt varumärke förväxlas med konkurrenter eller andra entiteter, vilket minskar synligheten och potentiellt skadar ryktet.
Viktiga utmaningar inkluderar polysemi (flera betydelser för samma namn), nya entiteter som inte finns i träningsdata, namnvarianter och stavfel, ofullständiga eller föråldrade kunskapsbaser samt skalbarhetsproblem. Dessutom är vissa entitetsnamn i sig tvetydiga och kontexten räcker ibland inte för att avgöra rätt entitet.
Varumärken kan implementera strukturerad data med Schema.org-markering, upprätthålla korrekta Wikipedia- och Wikidata-poster, skapa kontextuellt innehåll som tydligt särskiljer deras varumärke samt övervaka hur AI-system disambiguera deras varumärke med verktyg som AmICited. Dessa strategier hjälper AI-system att korrekt identifiera och citera ditt varumärke.
Kontext är avgörande för entitetsdisambiguering. Den omgivande texten, relaterade entiteter och semantiska relationer ger signaler som hjälper AI-system att avgöra vilken entitet som refereras. Om 'Apple' till exempel förekommer nära 'Steve Jobs' och 'teknik', kan systemet använda denna kontext för att korrekt disambiguera det som Apple Inc. istället för frukten.
Följ upp entitetsdisambigueringens noggrannhet i AI-plattformar och säkerställ att ditt varumärke identifieras och citeras korrekt i AI-genererade svar.
Entity Recognition är en AI NLP-förmåga som identifierar och kategoriserar namngivna entiteter i text. Lär dig hur det fungerar, dess tillämpningar inom AI-över...

Lär dig hur entityoptimering hjälper ditt varumärke att bli igenkänt av LLM:er. Bemästra kunskapsgrafsoptimering, schema-markering och entity-strategier för AI-...

Lär dig hur du bygger entity-synlighet i AI-sök. Bemästra optimering av kunskapsgrafer, schema markup och entity SEO-strategier för att öka varumärkets närvaro ...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.