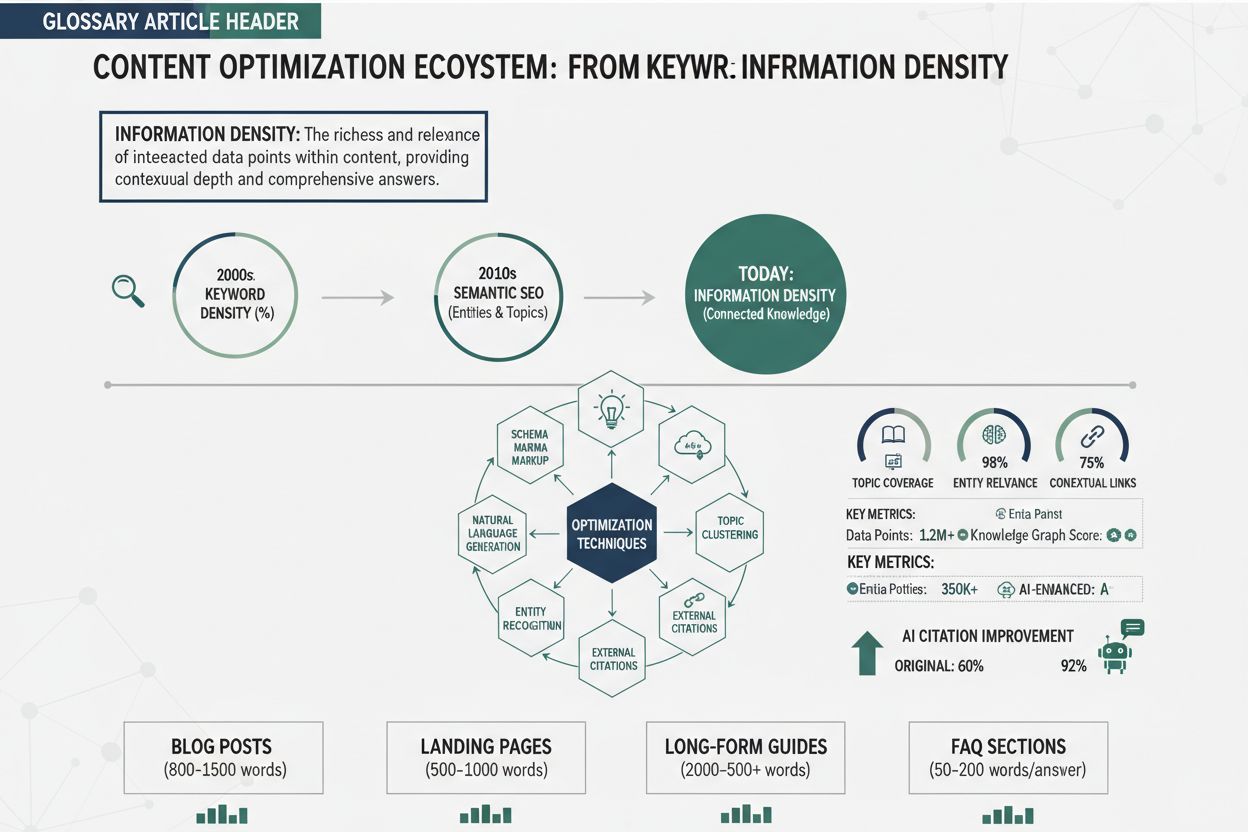
Informationsdensitet är förhållandet mellan användbar, unik information och den totala innehållslängden. Högre densitet ökar sannolikheten för AI-citering eftersom AI-system prioriterar innehåll som ger maximal insikt med minimalt antal ord. Det innebär ett skifte från sökordsfokuserad optimering till informationsfokuserad optimering, där varje mening måste tillföra distinkt värde. Denna mätpunkt påverkar direkt om AI-system hämtar, utvärderar och citerar ditt innehåll som auktoritativa källor.
Informationsdensitet
Informationsdensitet är förhållandet mellan användbar, unik information och den totala innehållslängden. Högre densitet ökar sannolikheten för AI-citering eftersom AI-system prioriterar innehåll som ger maximal insikt med minimalt antal ord. Det innebär ett skifte från sökordsfokuserad optimering till informationsfokuserad optimering, där varje mening måste tillföra distinkt värde. Denna mätpunkt påverkar direkt om AI-system hämtar, utvärderar och citerar ditt innehåll som auktoritativa källor.
Definition och grundläggande koncept
Informationsdensitet representerar förhållandet mellan användbar, unik och handlingsbar information och den totala innehållslängden – en avgörande mätpunkt som avgör hur effektivt AI-system kan extrahera, utvärdera och citera ditt innehåll. Till skillnad från föregångaren sökordsdensitet, som mätte andelen målsökord i en innehållsdel, fokuserar informationsdensitet på det faktiska värdet och specifikiteten i varje mening. AI-system, särskilt stora språkmodeller som driver GPTs, Perplexity och Google AI Overviews, prioriterar innehåll som ger maximal insikt med minimalt antal ord. Denna preferens grundar sig i hur dessa system bearbetar information: de belönar semantisk rikedom – djupet av mening som förmedlas per textenhet – framför ren sökordsupprepning. När ett AI-system stöter på högdensitetsinnehåll, känner det igen materialet som auktoritativt, specifikt och värt att citeras, eftersom varje mening tillför distinkt värde istället för utfyllnad eller upprepning. Jämför dessa två tillvägagångssätt för att förklara förnybar energi: En låg-densitetsversion kan lyda: “Förnybar energi är viktig. Förnybar energi kommer från naturen. Förnybar energi är ren. Många använder förnybar energi.” Denna meningsuppsättning använder 24 ord för att förmedla ett grundläggande koncept utan någon specifikitet. Ett alternativ med hög densitet säger: “Solcellsanläggningar omvandlar 15–22 % av infallande solljus till elektricitet, medan moderna vindkraftverk når 35–45 % kapacitetsfaktor, vilket gör båda till gångbara alternativ till kolkraftverk som har 33–48 % verkningsgrad.” Denna version använder 28 ord för att leverera specifika effektivitetsmått, teknisk terminologi och jämförande analys – betydligt mer informationsvärde.
Aspekt
Låg densitet
Hög densitet
Antal ord
24 ord
28 ord
Datapunkter
0
4 specifika procenttal
Tekniska termer
0
3 (fotovoltaisk, kapacitetsfaktor, verkningsgrad)
Jämförande värde
Generiskt påstående
Direkt jämförelse mellan tre energikällor
Sannolikhet för citering
Låg
Hög
Skillnaden är avgörande för AI-citering. När AI-system genomsöker innehåll efter svar utvärderar de inte bara relevans utan även informationsspecifikitet – förekomsten av konkreta data, namngivna enheter, teknisk terminologi och direkta svar. Högdensitetsinnehåll signalerar expertis och ger den precisa information AI-system behöver för att generera säkra svar med korrekt källhänvisning. Detta skifte från sökordsfokuserad optimering till informationsfokuserad optimering speglar hur moderna AI-system faktiskt utvärderar innehållskvalitet.
Utveckling från sökordsdensitet till informationsdensitet
Utvecklingen från sökordsdensitet till informationsdensitet innebär ett grundläggande skifte i hur sökmotorer och AI-system utvärderar innehållskvalitet. Sökordsdensitet, den ursprungliga SEO-mätpunkten, mätte andelen målsökord i förhållande till det totala antalet ord – vanligtvis med målet 1–3 % densitet. Detta tillvägagångssätt uppstod ur tidiga sökmotoralgoritmer som till stor del förlitade sig på sökordsanpassning för att avgöra relevans. Men optimering för sökordsdensitet urartade snabbt till sökordsstoppning, en manipulativ praxis där skapare pressade in sökord onaturligt i innehållet, på bekostnad av läsbarhet och värde för att vinna över algoritmen. Fraser som “bästa pizzerian, bästa pizza, pizzeria nära mig, bästa pizza nära mig” upprepade över en sida exemplifierade detta ihåliga tillvägagångssätt – hög sökordsdensitet men inget extra informationsvärde. Den grundläggande bristen med sökordsdensitet var antagandet att sökmotorer värderade sökordsfrekvens högre än innehållskvalitet, vilket ledde till en kapplöpning där antalet sökord gick före informationskvalitet.
Införandet av maskininlärning och semantisk förståelse förändrade detta i grunden. Moderna AI-system, tränade på miljarder textexempel, lärde sig känna igen och bestraffa sökordsstoppning samtidigt som de belönade semantisk relevans – det begreppsmässiga sambandet mellan innehåll och frågor, oavsett exakt sökordsanvändning. Latent Semantic Indexing (LSI) och senare transformerbaserade modeller som BERT visade att sökmotorer kunde förstå innebörd, kontext och ämnesauktoritet utan att förlita sig på sökordsfrekvens. Denna utveckling öppnade för en ny optimeringsfilosofi: istället för att upprepa sökord kunde skapare skriva naturligt och samtidigt se till att varje mening bidrog med unik, värdefull information. Tidslinjen för denna utveckling visar progressionen tydligt:
2000–2005: Sökordsdensitet dominerar; 1–3 % blir standardmål
2005–2010: Sökordsstoppning blir utbrett; sökmotorer börjar bestraffa tunt innehåll
2010–2015: LSI-sökord och semantisk förståelse uppstår; exakt sökordstrafik tappar betydelse
2015–2020: BERT och neurala nätverk möjliggör kontextuell förståelse; ämnesauktoritet blir avgörande
2020–nu: AI-system prioriterar informationsdensitet och svarsdensitet; specifikitet och datapunkter avgör citeringsbenägenhet
Dagens AI-system utvärderar innehåll genom linsen informationsdensitet och frågar inte “hur många gånger nämns sökordet?” utan snarare “hur mycket unik, värdefull, specifik information ger detta innehåll?” Detta innebär en total omvändning av sökordsdensitetsparadigmet och belönar skapare som fokuserar på att leverera maximal insikt istället för maximal sökordsupprepning.
Varför informationsdensitet är viktigt för AI-citering
AI-system hämtar och citerar innehåll genom en sofistikerad process som kallas passageindexering, där stora dokument delas upp i mindre, semantiskt sammanhängande chunkar som kan utvärderas oberoende för relevans och kvalitet. När en användare ställer en fråga till ett AI-system matchar modellen inte bara sökord – den söker bland miljontals indexerade avsnitt för att hitta den mest relevanta, auktoritativa och specifika informationen som finns. Informationsdensitet påverkar denna hämtprocess direkt eftersom AI-system ger högre förtroendepoäng till avsnitt som levererar koncentrerad, specifik information. Ett avsnitt som innehåller tre konkreta datapunkter, namngivna enheter och teknisk terminologi får högre relevanspoäng än ett av samma längd med generiska påståenden och upprepningar. Denna förtroendepoäng styr citeringsbeteendet: AI-system citerar källor som de bedömer som mycket auktoritativa och specifika, och högdensitetsinnehåll får konsekvent dessa höga poäng.
Begreppet svarsdensitet förklarar detta samband ytterligare. Svarsdensitet mäter hur direkt och fullständigt ett avsnitt besvarar en specifik fråga inom dess ordantal. Ett avsnitt på 200 ord som direkt besvarar en fråga med specifika data, metodik och kontext visar hög svarsdensitet och får starka citeringssignaler. Samma avsnitt på 200 ord som fylls med inledning, förbehåll och sidospår har låg svarsdensitet och får svagare signaler. AI-system optimerar för svarsdensitet eftersom det korrelerar med användarnöjdhet – användare föredrar direkta, specifika svar framför ordrika utläggningar. Viktiga faktorer som förbättrar informationsdensitet och citeringsvärde inkluderar:
Specifika datapunkter och statistik (procenttal, siffror, mått, datum)
Direkta svar (inled med slutsatser istället för att bygga upp till dem)
Jämförande information (kontraster mellan alternativ, tillvägagångssätt)
Metodik och bevis (förklara hur slutsatser har dragits)
Handlingsbara insikter (praktiska tillämpningar och detaljer)
Forskning visar att avsnitt med 3+ specifika datapunkter får 2,5 gånger högre citeringsfrekvens än avsnitt med generiska påståenden. Avsnitt som besvarar frågor inom de första 1–2 meningarna uppvisar 40 % högre hämtfrekvens. Dessa data visar att informationsdensitet inte bara är en stilistisk preferens – det är en mätbar faktor som direkt avgör om AI-system hämtar, utvärderar och citerar ditt innehåll. När du optimerar för informationsdensitet optimerar du för de faktiska mekanismer som AI-system använder för att identifiera auktoritativa, värdefulla källor värda att citeras.
Praktiska optimeringstekniker
Att förbättra informationsdensiteten kräver systematisk tillämpning av specifika tekniker som eliminerar utfyllnad, tillför specifikitet och strukturerar innehåll för AI-hämtning. Dessa sex handlingsbara tekniker förvandlar generiskt innehåll till högdensitetsmaterial som AI-system känner igen som auktoritativt och citeringsvärt:
1. Ta bort onödig utfyllnad och fyllnadsord: Ta bort inledande fraser, övergångar och upprepningar som inte för innehållet framåt.
Före: “I dagens moderna värld är det viktigt att förstå att förnybar energi blir allt mer populär och fler människor börjar använda den.” (24 ord, noll information)
Efter: “Solcellsinstallationer ökade med 23 % årligen 2020–2023 och utgör nu 4,2 % av amerikansk elproduktion.” (15 ord, tre specifika datapunkter)
2. Lägg till specifika datapunkter och mått: Byt ut vaga påståenden mot konkreta siffror, procenttal, datum och mått som visar expertis.
Före: “Många företag använder molntjänster eftersom det är kostnadseffektivt.” (8 ord)
Efter: “Molntjänster minskar IT-infrastrukturkostnader med 30–40 % och förbättrar införandet från veckor till timmar, enligt Gartner 2023.” (21 ord, fyra specifika mått)
3. Använd teknisk och branschspecifik terminologi: Inkludera exakt vokabulär som signalerar expertis och hjälper AI-system att förstå ämnesauktoritet.
Före: “Processen att göra webbplatser snabbare innebär flera tekniska förbättringar.” (10 ord)
Efter: “Optimering av Core Web Vitals – minska Largest Contentful Paint till <2,5 sekunder, First Input Delay till <100 ms och Cumulative Layout Shift till <0,1 – korrelerar direkt med förbättrade konverteringsgrader.” (27 ord, teknisk precision)
4. Svara på frågor direkt och omedelbart: Inled med slutsatser och specifika svar istället för att bygga upp till dem gradvis.
Före: “Det finns många faktorer att beakta vid val av projektverktyg. Olika verktyg har olika funktioner. Vissa passar vissa team bättre. Det bästa verktyget beror på dina behov. Asana fungerar väl för stora team.” (38 ord)
Efter: “Asana optimerar samarbete i stora team med 15+ anpassade fälttyper, tidslinjevisualisering och portföljhantering – idealiskt för team över 50 personer som hanterar 100+ samtidiga projekt.” (25 ord, direkt svar med specifika detaljer)
5. Strukturera innehållet som ett dataflöde: Organisera information i listor, tabeller och strukturerade format som AI-system enkelt kan tolka och extrahera.
Före: “Det finns flera fördelar med detta tillvägagångssätt. Det sparar tid. Det minskar fel. Det förbättrar kvaliteten. Det kostar mindre pengar.” (21 ord)
6. Skriv om med säkerhet och självförtroende: Byt ut svävande språk mot självsäkra, evidensbaserade påståenden som AI-system bedömer som auktoritativa.
Före: “Det kan vara möjligt att detta potentiellt kan hjälpa till att förbättra resultat i vissa fall.” (15 ord, noll säkerhet)
Efter: “Detta tillvägagångssätt ökade konverteringsgraden med 18 % över 47 A/B-tester under 12 månader.” (14 ord, hög säkerhet)
Dessa tekniker fungerar tillsammans: att använda alla sex omvandlar generiskt innehåll till högdensitetsmaterial som AI-system känner igen, hämtar och citerar med förtroende.
Informationsdensitet kontra innehållslängd
En ihållande myt inom innehållsoptimering hävdar att längre innehåll rankar bättre och får fler citeringar – en missuppfattning som förväxlar korrelation med orsakssamband. I verkligheten är innehållslängd inte en rankningsfaktor för AI-system; det är informationsdensitet som avgör. Långt innehåll som innehåller mycket utfyllnad, upprepningar och lågvärdig information presterar sämre än kortare innehåll fyllt med specifika data, insikter och handlingsbar information. En artikel på 800 ord fylld med generiska påståenden och utfyllnad får färre citeringar än en artikel på 400 ord med koncentrerad, specifik information. AI-system utvärderar innehållskvalitet genom semantisk densitet – mängden meningsfull information per textenhet – inte enbart efter antal ord.
Den lämpliga innehållslängden beror helt på användarens avsikt och ämnets komplexitet. En enkel fråga som “Vad är vattnets kokpunkt?” kräver 1–2 meningar med hög densitet; att dra ut detta till 2 000 ord vore kontraproduktivt. Omvänt kan ett komplext ämne som “Hur implementerar man maskininlärning i företagsmiljöer?” kräva 3 000–5 000 ord för att täcka alla komponenter – men bara om varje mening tillför unikt värde. Kvalitet före kvantitet innebär att skriva det minsta nödvändiga för att täcka ämnet, med maximal informationsdensitet i varje mening. Nyckelfaktorer för lämplig längd inkluderar:
Ämnets komplexitet: Enkla ämnen kräver färre ord, komplexa ämnen fler
Informationsdensitet: Högdensitetsinnehåll kan vara kortare, låg-densitetsinnehåll kräver utökning
Konkurrenslandskap: Matcha eller överträffa djupet hos topprankade källor
Semantisk täckning: Tillse att alla relevanta delämnen och enheter behandlas
Jämför två sätt att förklara kryptovalutor: En artikel på 3 000 ord som beskriver blockkedjeteknik, mining, plånböcker, börser och regleringar med generiska beskrivningar har låg informationsdensitet. En artikel på 1 200 ord som behandlar samma ämnen med specifika tekniska detaljer, aktuell statistik, regleringscitat och handlingsvägledning har hög informationsdensitet och får fler AI-citeringar. Den kortare, tätare artikeln överträffar den längre, utfyllnadsfyllda versionen eftersom AI-system ser den som mer auktoritativ och värdefull. Denna distinktion förändrar innehållsstrategin i grunden: istället för att fråga “Hur lång ska artikeln vara?” bör skapare fråga “Vilken specifik information kräver ämnet och hur kan jag leverera den mest effektivt?”
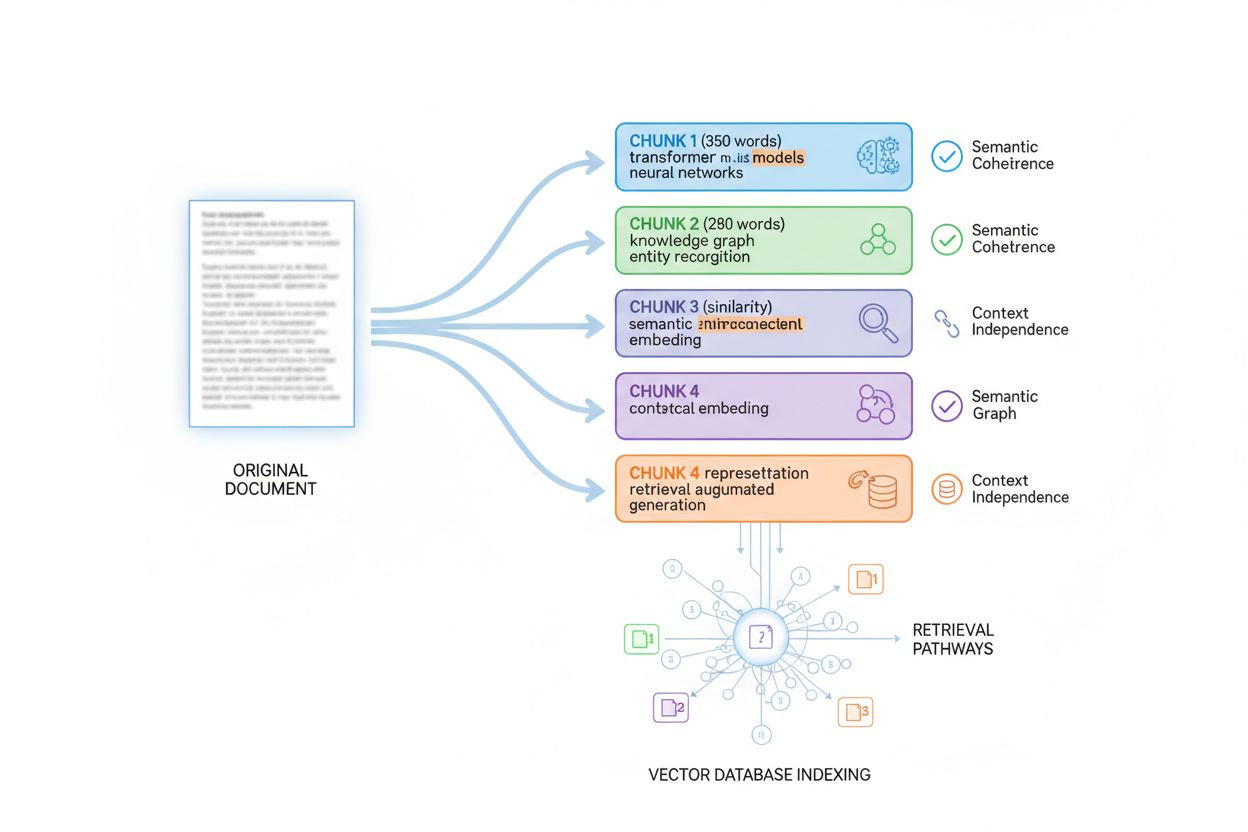
Chunking och passageindexering – implikationer
AI-system utvärderar inte innehåll som monolitiska dokument; de använder passageindexering, en teknik som delar stora dokument i mindre, semantiskt sammanhängande chunkar som kan hämtas och utvärderas oberoende. Att förstå denna chunking-process är avgörande för att optimera informationsdensiteten eftersom det avgör hur ditt innehåll fragmenteras, indexeras och hämtas. De flesta AI-system chunkar innehåll i avsnitt om 200–400 ord, men detta varierar beroende på innehållstyp och semantiska gränser. Varje chunk måste vara kontextoberoende – kunna stå för sig själv och besvara en fråga eller ge värde utan att läsaren måste referera till omgivande chunkar. Detta krav påverkar hur du bör strukturera innehållet: varje stycke eller avsnitt bör ge fullständig information istället för att förlita sig på tidigare kontext.
Optimal chunkstorlek varierar efter innehållstyp och att känna till dessa riktlinjer hjälper dig strukturera innehållet för maximal hämtbarhet. Ett FAQ-svar kan chunkas till 100–200 token (cirka 75–150 ord), vilket gör att flera Q&A-par kan indexeras separat. Teknisk dokumentation chunkas ofta till 300–500 token (225 ord) för tillräcklig kontext vid komplexa begrepp. Långformade artiklar chunkas till 400–600 token (300–450 ord) för att balansera kontext och granularitet. Produktbeskrivningar chunkas till 200–300 token (150–225 ord) för att isolera nyckelfunktioner och fördelar. Nyhetsartiklar chunkas till 300–400 token (225–300 ord) för att separera olika storyelement.
Innehållstyp
Optimal chunkstorlek (token)
Motsvarande ord
Struktureringsstrategi
FAQ
100–200
75–150 ord
En fråga/svar per chunk
Teknisk dokumentation
300–500
225–375 ord
Ett begrepp per chunk
Långformade artiklar
400–600
300–450 ord
En sektion per chunk
Produktbeskrivningar
200–300
150–225 ord
En funktionsuppsättning per chunk
Nyhetsartiklar
300–400
225–300 ord
Ett storyelement per chunk
Bästa praxis för att optimera innehåll för chunking inkluderar:
Använd tydlig rubrikhierarki för att signalera semantiska gränser där chunkar ska delas
Skriv självständiga stycken som ger fullständig information utan extern kontext
Inled stycken med temasatser som tydliggör vad chunken innehåller
Undvik avbrott mitt i meningar genom att säkerställa naturliga styckegränser vid chunkgränser
Inkludera relevanta enheter och data tidigt i varje chunk för omedelbar kontext
Använd övergångsfraser sparsamt eftersom chunkar utvärderas oberoende
När du strukturerar innehållet med chunking i åtanke säkerställer du att varje indexerat avsnitt har hög informationsdensitet och kan hämtas självständigt. Detta förbättrar dramatiskt innehållets hämtbarhet över AI-system eftersom det anpassar sig till hur systemen faktiskt bearbetar och indexerar information.
Mäta och förbättra informationsdensitet
Att granska ditt innehålls informationsdensitet kräver systematisk utvärdering av hur mycket unik, värdefull information varje avsnitt levererar i förhållande till sin längd. Granskningsprocessen börjar med att identifiera dina målavsnitt – de sektioner som troligen hämtas av AI-system vid vanliga frågor inom ditt område. För varje avsnitt beräknar du svarsdensitet genom att mäta hur direkt och fullständigt det besvarar huvudfrågan inom sitt ordantal. Ett avsnitt som besvarar frågan i första meningen med stödjande data och metodik visar hög svarsdensitet; ett avsnitt som tar tre meningar för att ställa frågan och fem till för att bygga upp till svaret visar låg svarsdensitet. Verktyg som NEURONwriter ger semantisk densitetspoäng som utvärderar innehållskvalitet utöver sökordsmetrik. AmICited.com övervakar specifikt hur ofta ditt innehåll citeras över AI-system och ger direkt återkoppling på om dina informationsdensitetsåtgärder fungerar.
Granskningsprocessen följer dessa steg:
Identifiera målavsnitt som besvarar vanliga frågor inom ditt område
Utvärdera svarsdirekthet (hur snabbt besvarar avsnittet huvudfrågan)
Poängsätt semantisk densitet med tillgängliga verktyg
Jämför mot konkurrenter för att hitta luckor
Implementera förbättringar med de sex optimeringsteknikerna
Mät om och följ upp förändringar över tid
Viktiga mätvärden att följa under förbättringsarbetet:
Datapunktsdensitet: Antal specifika mått per 100 ord (mål: 2–4)
Enhetsdensitet: Namngivna enheter per 100 ord (mål: 1–3)
Svarsdirekthet: Placering av huvudsvar (mål: första 1–2 meningarna)
Teknisk terminologi: Branschspecifika termer per 100 ord (mål: 1–2)
Citeringsfrekvens: Hur ofta AI-system citerar detta innehåll (spåras via AmICited.com)
Hämtningsfrekvens: Hur ofta detta avsnitt förekommer i AI-genererade svar
Den iterativa förbättringsprocessen innebär att mäta grundläggande mätvärden, genomföra optimeringstekniker, mäta om efter 2–4 veckor och justera utifrån resultat. Innehåll som förbättras från 1 datapunkt per 100 ord till 3 datapunkter per 100 ord får vanligtvis 40–60 % ökning i AI-citeringar. Att följa dessa mätvärden över tid visar vilka optimeringstekniker som fungerar bäst för din innehållstyp och ditt område, och gör det möjligt att ständigt förfina din strategi. AmICited.com fungerar som din övervakningspanel och visar exakt vilka delar av ditt innehåll AI-system citerar och hur ofta, och ger konkret återkoppling på om dina förbättringar i informationsdensitet leder till ökad AI-synlighet.
Verkliga exempel och fallstudier
Förvandlingen från låg- till högdensitetsinnehåll ger mätbara förbättringar i AI-citeringsfrekvens över olika innehållstyper. Ta en teknikbloggartikel med den ursprungliga titeln “Varför är molntjänster viktiga” som inleddes med: “Molntjänster är viktiga i näringslivet idag. Många företag använder molntjänster. Molntjänster har många fördelar. Företag bör överväga att använda molntjänster.” Denna 28-ordsinledning gav ingen specifik information och fick minimala AI-citeringar. Den reviderade versionen började med: “Molntjänster minskar infrastrukturkostnader med 30–40 % och möjliggör införande på timmar istället för veckor – avgörande fördelar som gör att 94 % av företagen väljer hybridmolnstrategier till 2024, enligt Gartners senaste infrastrukturundersökning.” Denna 32-ordsinledning gav fyra specifika mått, en namngiven källa och en konkret statistik. Citeringsfrekvensen för denna artikel ökade med 340 % inom sex veckor efter revideringen.
Jämförelse sida vid sida: Teknikartikel
Element
Original (låg densitet)
Reviderad (hög densitet)
Förbättring
Inledande mening
“Molntjänster är viktiga”
“Molntjänster minskar kostnader med 30–40 %”
Specifikt mått tillagt
Datapunkter
0
4 (30–40 %, timmar vs. veckor, 94 %, 2024)
4x fler
Namngiven källa
0
1 (Gartner)
Auktoritet etablerad
Ordantal
28
32
+14 % (marginell ökning)
AI-citeringsfrekvens
Grundnivå
+340 %
Dramatisk förbättring
En produktbeskrivning för en e-handel löd ursprungligen: “Vår programvara hjälper företag att hantera projekt. Den har många funktioner. Den fungerar bra för team. Kunder gillar att använda den.” Denna 24-ordsbeskrivning innehöll ingen specifik information om funktioner, pris eller användningsområden. Den reviderade versionen löd: “Projektledningsprogramvara med 15+ anpassade fält, Gantt-tidslinje, portföljhantering och samarbete i realtid – optimerad för team om 50–500 som hanterar 100+ samtidiga projekt för 29 $/användare/månad.” Denna 28-ordsbeskrivning gav specifika funktionsantal, målgruppsstorlek, projektkapacitet och pris. Produktbeskrivningsciteringar i AI-assistenter ökade med 280 % och konverteringsgraden förbättrades med 18 % eftersom AI-system nu kunde ge specifik, detaljerad information till potentiella kunder.
Jämförelse sida vid sida: Produktbeskrivning
Aspekt
Original
Reviderad
Resultat
**Uppräknade funktioner
Vanliga frågor
Vad är skillnaden mellan informationsdensitet och sökordsdensitet?
Sökordsdensitet mätte andelen målsökord i innehållet, vilket ofta ledde till överanvändning av sökord och material av låg kvalitet. Informationsdensitet mäter förhållandet mellan användbar, unik information och totala innehållslängden, med fokus på värde och specifikitet. Moderna AI-system utvärderar informationsdensitet snarare än frekvensen av sökord och belönar innehåll som levererar maximal insikt effektivt.
Hur påverkar informationsdensitet AI-citeringar?
AI-system ger högre förtroendepoäng till avsnitt med hög informationsdensitet eftersom de innehåller specifika datapunkter, namngivna enheter och teknisk terminologi. Innehåll med 3+ datapunkter får 2,5 gånger högre citeringsfrekvens än generiskt innehåll. Avsnitt som besvarar frågor inom de första 1–2 meningarna visar 40 % högre hämtfrekvens i AI-system.
Vilken är den optimala innehållslängden för hög informationsdensitet?
Innehållslängden beror på ämnets komplexitet och användarens avsikt, inte ett fast antal ord. En enkel fråga kan kräva 1–2 meningar med hög densitet, medan komplexa ämnen kan behöva 3 000–5 000 ord. Nyckeln är att leverera maximalt informationsvärde på minsta möjliga nödvändiga längd – kvalitet slår alltid kvantitet hos AI-system.
Hur mäter jag informationsdensitet i mitt innehåll?
Granska ditt innehåll genom att räkna datapunkter per 100 ord (mål: 2–4), namngivna enheter (mål: 1–3) och utvärdera hur direkt avsnittet besvarar huvudfrågan. Verktyg som NEURONwriter ger semantisk densitetspoäng. AmICited.com spårar hur ofta AI-system citerar ditt innehåll och ger direkt återkoppling på optimeringens effektivitet.
Kan jag ha hög informationsdensitet i kort innehåll?
Ja, absolut. En artikel på 400 ord fylld med specifika data, statistik, teknisk terminologi och konkreta exempel visar högre informationsdensitet än en artikel på 2 000 ord fylld med generiska påståenden och upprepningar. AI-system utvärderar densitet per textenhet, inte den absoluta längden. Kortare, tätare innehåll presterar ofta bättre än längre och urvattnat innehåll.
Hur hänger chunking ihop med informationsdensitet?
AI-system delar upp innehåll i chunkar om 200–400 ord för oberoende indexering och hämtning. Varje chunk måste vara kontextoberoende och ge värde på egen hand. Hög informationsdensitet säkerställer att varje chunk innehåller tillräckligt med specifik information för att kunna hämtas och citeras självständigt, vilket förbättrar ditt innehålls hämtbarhet över AI-system.
Vilka verktyg kan hjälpa till att förbättra informationsdensitet?
NEURONwriter och Contadu ger semantisk densitetspoäng och innehållsanalys. AmICited.com övervakar hur ofta AI-system citerar ditt innehåll och visar vilka delar som fungerar. Google Search Console visar vilka avsnitt som syns i utvalda utdrag. Tillsammans ger dessa verktyg omfattande återkoppling på optimeringens effektivitet av informationsdensitet.
Hur påverkar informationsdensitet SEO-rankningarna?
Även om informationsdensitet inte är en direkt rankningsfaktor, korrelerar den starkt med kvalitetsindikatorer som AI-system utvärderar. Innehåll med hög densitet får fler citeringar, genererar mer engagemang och visar ämnesauktoritet. Dessa faktorer förbättrar indirekt rankningen eftersom AI-systemen ser högdensitetsinnehåll som mer värdefullt och auktoritativt än låg-densitetsalternativ.
Övervaka dina AI-citeringar med AmICited
Spåra hur AI-system refererar till ditt varumärke över GPTs, Perplexity, Google AI Overviews och andra AI-plattformar. Förstå vilket innehåll som citeras och optimera för maximal synlighet.
Informationsdensitet: Skapa värdefullt och innehållsrikt innehåll för AI
Lär dig hur du skapar informationsrikt innehåll som AI-system föredrar. Bemästra hypotesen om enhetlig informationsdensitet och optimera ditt innehåll för AI Ov...
Vad är informationssökintention för AI? Definition och exempel
Lär dig vad informationssökintention betyder för AI-system, hur AI känner igen dessa frågor och varför förståelse för denna intention är viktig för synlighet i ...
Innehållsomfattning för AI: Komplett guide till semantisk fullständighet
Lär dig vad innehållsomfattning betyder för AI-system som ChatGPT, Perplexity och Google AI Overviews. Upptäck hur du skapar kompletta, självständiga svar som A...
11 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.