
Sanningen om LLMs.txt: Överskattad eller oumbärlig?
Kritisk analys av LLMs.txt effektivitet. Upptäck om denna AI-innehållsstandard är oumbärlig för din webbplats eller bara hype. Riktig data om användning, plattf...
9 min läsning

En föreslagen standardfil placerad i webbplatsens rotkatalog som kommunicerar med AI-crawlare och stora språkmodeller om högkvalitativt, citerbart innehåll. Liknar robots.txt men är utformad för vägledning vid inferenstid snarare än åtkomstkontroll. Hjälper AI-system att upptäcka och prioritera auktoritativt innehåll vid generering av svar. Blir alltmer adopterad av stora AI-plattformar som OpenAI, Anthropic, Perplexity och Google.
En föreslagen standardfil placerad i webbplatsens rotkatalog som kommunicerar med AI-crawlare och stora språkmodeller om högkvalitativt, citerbart innehåll. Liknar robots.txt men är utformad för vägledning vid inferenstid snarare än åtkomstkontroll. Hjälper AI-system att upptäcka och prioritera auktoritativt innehåll vid generering av svar. Blir alltmer adopterad av stora AI-plattformar som OpenAI, Anthropic, Perplexity och Google.
LLMs.txt-filen är en ren textfil i markdown som placeras i webbplatsens rotkatalog och fungerar som en kurerad guide för stora språkmodeller vid inferenstid. Till skillnad från traditionella SEO-verktyg är LLMs.txt utformad för att hjälpa AI-crawlare och språkmodeller att upptäcka och prioritera högkvalitativt innehåll på din webbplats när de genererar svar eller söker information. Denna föreslagna standard innebär en förändring i hur webbplatser kommunicerar med artificiella intelligenssystem, genom att gå bortom blockering med robots.txt till att istället erbjuda intelligent innehållskurering. Filen fungerar som en innehållsfärdplan som talar om för AI-system vilka sidor, artiklar och resurser som är mest värdefulla, auktoritativa och relevanta för deras syften. Det är viktigt att förstå att LLMs.txt inte handlar om att blockera eller tillåta AI-träning—den är specifikt för inferenstidens insamling, och hjälper AI-system att hitta rätt innehåll när de besvarar användarfrågor. Filen skrivs i markdownformat och sparas som ren text, vilket gör den enkel att skapa och underhålla. Genom att implementera LLMs.txt kan webbplatser säkerställa att när AI-system refererar till deras innehåll, hämtas det från de mest korrekta, välstrukturerade och auktoritativa källorna som finns.
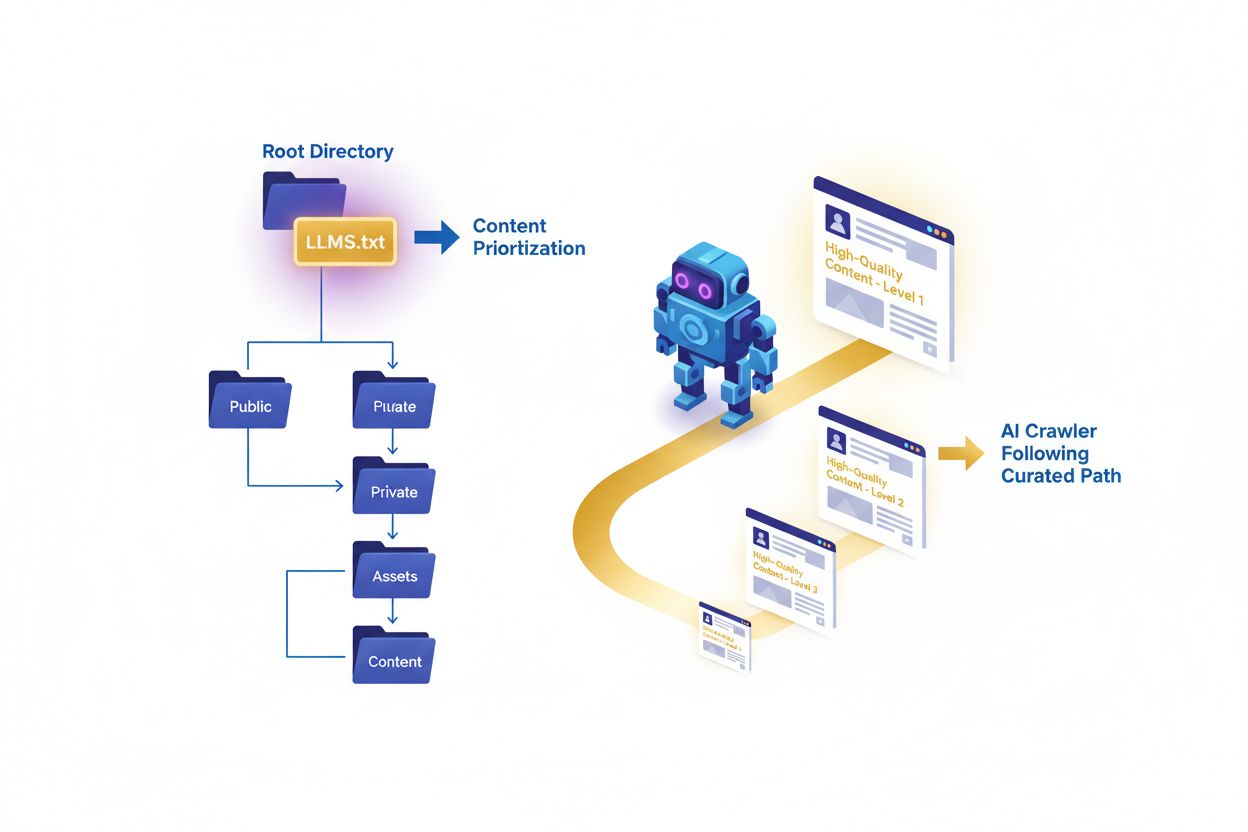
Medan robots.txt och sitemap.xml har tjänat webbplatser väl för traditionella sökmotorer, adresserar LLMs.txt ett fundamentalt annorlunda behov i artificiell intelligens ålder. Den avgörande skillnaden ligger i deras primära funktioner och timing: robots.txt styr crawlerbeteende och vad sökmotorer får komma åt, sitemap.xml hjälper sökmotorer att upptäcka och indexera sidor, medan LLMs.txt vägleder AI-system under inferenstid när de aktivt genererar svar. Det är avgörande att förstå att LLMs.txt inte blockerar eller tillåter AI-träning—den kurerar bara vilket innehåll AI-system ska prioritera vid besvarande av frågor eller informationssökning. De tre filerna har kompletterande syften och kan absolut samexistera på samma domän utan konflikt. Där robots.txt handlar om åtkomstkontroll och sitemap.xml om upptäckbarhet, handlar LLMs.txt om innehållets kvalitet och relevans. Tänk så här: robots.txt säger “vad du får crawla”, sitemap.xml säger “detta finns”, och LLMs.txt säger “detta är mest betydelsefullt”. Denna åtskillnad är särskilt viktig då AI-system behöver andra signaler än traditionella sökmotorer—de måste förstå vilket innehåll som är auktoritativt, välstrukturerat och lämpligt för citering.
| Fil | Primär funktion | Huvudsyfte | Användningsfall |
|---|---|---|---|
| robots.txt | Åtkomstkontroll | Förhindra/tillåta crawleråtkomst | Blockera känsliga sidor från sökmotorer |
| sitemap.xml | Upptäckbarhet | Hjälpa sökmotorer hitta sidor | Förbättra indexering av nytt eller djupt innehåll |
| LLMs.txt | Innehållskurering | Vägleda AI:s inferenstidsinhämtning | Styra AI-system till auktoritativa källor |
LLMs.txt-filen följer en markdown-baserad struktur som är både läsbar för människor och maskiner, vilket gör den tillgänglig för både innehållsskapare och AI-system. Filen börjar vanligtvis med en H1-titel (med #) som identifierar webbplatsen och dess syfte, följt av ett inledande blockcitat som ger kontext om webbplatsens uppdrag eller fokus. Kärnstrukturen inkluderar organiserade sektioner med H2-rubriker (##) som kategoriserar olika typer av innehåll—som “Kärnresurser”, “Guider”, “Dokumentation” eller “Bästa praxis”—där varje sektion innehåller en kurerad lista av URL:er med korta beskrivningar. En “Valfritt”-sektion i slutet gör det möjligt för webbplatser att inkludera ytterligare resurser som kan vara värdefulla men inte ingår i huvudkureringen. Filen använder ren text i UTF-8-kodning för att säkerställa kompatibilitet över alla system och AI-plattformar. Varje URL-post innehåller vanligtvis fullständig sökväg och en kort beskrivning som förklarar varför det innehållet är värdefullt eller vad det handlar om. Rekommenderad filstorlek hålls generellt under 100KB för att säkerställa effektiv bearbetning av AI-system, även om det inte finns någon hård gräns. Markdownformatet möjliggör flexibel organisering samtidigt som tydligheten bibehålls, och strukturen bör spegla din webbplats verkliga innehållshierarki och betydelse.
# Exempelwebbplats - LLMs.txt
> Detta är Exempelwebbplats, en omfattande resurs för att lära sig om [ditt ämne].
> Vi tillhandahåller auktoritativa guider, handledningar och dokumentation för [ditt område].
## Kärnresurser
- https://example.com/about - Översikt av vårt uppdrag och expertis
- https://example.com/getting-started - Viktig startpunkt för nya användare
## Omfattande guider
- https://example.com/guide/advanced-techniques - Djupgående utforskning av avancerade metoder
- https://example.com/guide/best-practices - Branschstandarder och rekommendationer
## Dokumentation
- https://example.com/docs/api-reference - Komplett API-dokumentation
- https://example.com/docs/installation - Installations- och uppsättningsinstruktioner
## Valfritt
- https://example.com/blog/latest-trends - Senaste branschinsikterna
- https://example.com/case-studies - Exempel på verkliga implementeringar
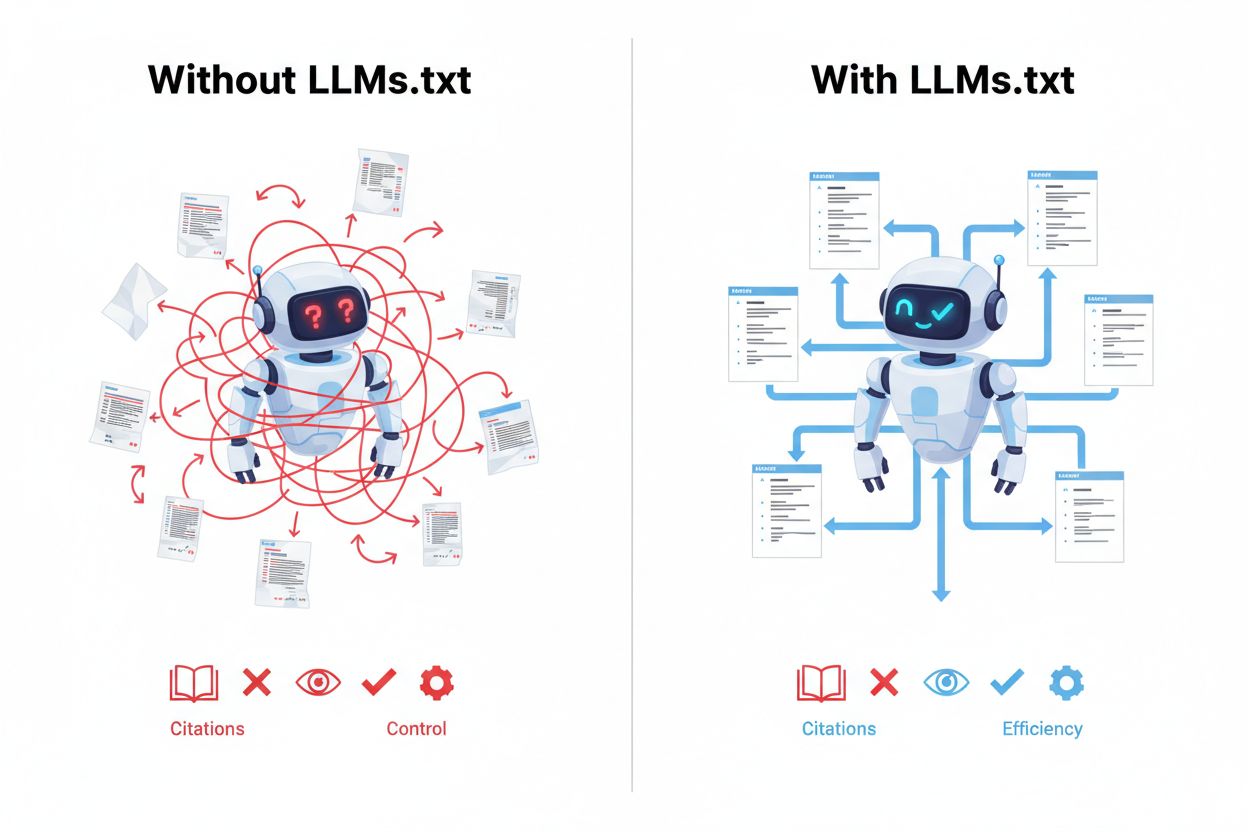
Implementering av LLMs.txt ger stora fördelar i det framväxande landskapet av AI-drivna sökningar och innehållsupptäckt. Den främsta fördelen är inferenstidsinsamling, vilket innebär att ditt kurerade innehåll prioriteras när AI-system aktivt svarar på användarfrågor snarare än under träningsfaser. Detta leder till bättre AI-förståelse för ditt innehålls kontext, auktoritet och relevans, vilket resulterar i mer korrekta citeringar och referenser när AI-system nämner ditt arbete. Genom att implementera LLMs.txt får du direkt kontroll över upptäckt, så att AI-system hittar ditt bästa innehåll först istället för potentiellt innehåll av lägre kvalitet. Filen ökar din synlighet i AI-sökresultat och AI-drivna applikationer, vilket skapar en ny kanal för trafik och attribution som kompletterar traditionell SEO. Organisationer som tidigt adopterar LLMs.txt får ett konkurrensfördel genom att etablera sig som auktoritativa källor inom sitt område innan standarden blir allmänt utbredd. Implementeringen fungerar också som ett framtidssäkrande steg och förbereder din webbplats för den oundvikliga övergången mot AI-baserad innehållsupptäckt.
Viktiga användningsområden inkluderar:
LLM-vänligt innehåll har specifika egenskaper som gör det mer värdefullt och användbart för artificiella intelligenssystem vid inferens. Den viktigaste egenskapen är tydlig struktur med korrekt rubrikhierarki, där H1-, H2- och H3-taggar används för att organisera information logiskt så att AI-system kan förstå innehållets flöde och relationer. Korta stycken (vanligtvis 2–4 meningar) föredras eftersom de låter AI-system extrahera separata koncept och idéer mer effektivt än täta textblock. Innehållet bör innehålla listor, tabeller och punktlistor som bryter ner komplex information i hanterbara delar, vilket gör det lättare för AI att tolka och referera till specifika punkter. Minimalt med distraktioner som autospelande videor, pop-ups eller överdriven reklam bör undvikas, eftersom de inte bidrar till innehållets kärnvärde. Semantisk tydlighet är avgörande—att använda tydligt språk, definiera tekniska termer och undvika tvetydighet hjälper AI-system att förstå din mening korrekt. Innehållet bör vara självständigt och kontextuellt, så att det är begripligt även när det används utanför sitt ursprungliga sammanhang. Detta tillvägagångssätt stöder direkt AI-SEO och ökar sannolikheten att ditt innehåll citeras korrekt och fullständigt när AI-system refererar till ditt arbete.
Korrekt implementering av LLMs.txt kräver strategiskt tänkande kring vilket innehåll som verkligen förtjänar att inkluderas och hur det organiseras för maximalt värde. Filen måste placeras i rotkatalogen (t.ex. example.com/llms.txt) för att vara lättupptäckt av AI-system och crawlare. Istället för att dumpa hela din sitemap i LLMs.txt, fokusera på kvalitet framför kvantitet—inkludera endast ditt mest auktoritativa, tidlösa och värdefulla innehåll som du vill att AI-system ska referera till. Prioritera högvärdiga resurser som omfattande guider, dokumentation, handledningar och originalforskning som visar expertis och tillför verkligt värde. Överväg att inkludera din hemsida eller om-sida för att hjälpa AI-system att förstå din organisations uppdrag och trovärdighet. Det innehåll du väljer bör vara väl underhållet och regelbundet uppdaterat, eftersom föråldrad information kan skada din trovärdighet hos AI-system. Organisera innehållet logiskt med tydliga sektionsrubriker som speglar webbplatsens struktur och innehållskategorier. Undvik att inkludera innehåll som kräver inloggning, betalväggar eller sidor som kräver användarkonto, eftersom AI-system inte kan komma åt dem. Utför regelbundna granskningar och uppdateringar av din LLMs.txt-fil för att återspegla förändringar i din innehållsstrategi, ta bort brutna länkar och lägga till nya auktoritativa resurser när de skapas.
LLMs.txt-användningen ökar snabbt bland stora AI-plattformar och företag som inser värdet av kurerade innehållskällor. OpenAI, Anthropic, Perplexity och Google har alla indikerat stöd för eller intresse av LLMs.txt-standarden, och vissa plattformar använder den aktivt för att förbättra sina hämtnings- och citeringssystem. Standarden är fortfarande under utveckling och ännu inte obligatorisk, men den blir alltmer erkänd som bästa praxis för webbplatser som vill optimera sin synlighet i AI-drivna applikationer. Flera kataloger och register har uppstått för att katalogisera webbplatser som implementerar LLMs.txt, vilket gör det lättare för AI-system att upptäcka och prioritera kurerade innehållskällor. Tidiga användare får en betydande fördel genom att etablera sig som auktoritativa källor innan standarden blir allmänt utbredd på alla AI-plattformar. Exempel från verkligheten visar att webbplatser som implementerar LLMs.txt får fler citeringar och bättre representation i AI-genererat innehåll. Användningstrenden tyder på att LLMs.txt kommer bli lika standard som robots.txt och sitemap.xml inom några år, vilket gör implementering till en klok investering för framtidsinriktade organisationer.
Skillnaden mellan llms.txt och llms-full.txt representerar två kompletterande sätt att vägleda AI-system genom ditt innehåll. LLMs.txt är den kurerade, människovalda versionen som bara innehåller ditt viktigaste, mest auktoritativa och värdefulla innehåll—vanligtvis 20–100 URL:er organiserade efter kategori med beskrivningar. LLMs-full.txt är däremot en komplett, maskinläsbar version som inkluderar varje sida på din webbplats i ett strukturerat format, ofta genererat automatiskt från din sitemap eller CMS. Den primära skillnaden är avsikt: llms.txt kräver mänsklig bedömning och urval, medan llms-full.txt är omfattande och uttömmande. LLMs.txt bör användas när du vill vägleda AI-system till ditt bästa innehåll och etablera tydliga auktoritetssignaler, medan llms-full.txt används som backup för AI-system som vill ha full täckning av din webbplats. Båda filer använder markdownformat men med olika organisationsfilosofier—llms.txt är selektiv och strategisk, medan llms-full.txt är inkluderande och komplett. Många organisationer implementerar båda filerna tillsammans, vilket gör att AI-system kan välja mellan kurerad vägledning (llms.txt) eller fullständig täckning (llms-full.txt). Till exempel erbjuder AIOSEO verktyg för att automatiskt generera båda versionerna, där llms.txt lyfter fram premiuminnehåll och llms-full.txt ger komplett webbplatstäckning.
Flera vanliga misstag kan undergräva effektiviteten i din LLMs.txt-implementering och bör noggrant undvikas. Det mest kritiska felet är att placera filen på fel plats—den måste ligga i rotkatalogen (example.com/llms.txt), inte i underkataloger eller med andra namnkonventioner. Brist på nödvändiga element som H1-titel och inledande blockcitat kan förvirra AI-system om din webbplats syfte och auktoritet. Att inkludera brutna eller föråldrade URL:er skadar din trovärdighet och slösar AI-systemens resurser som försöker komma åt innehåll som inte finns. Överinkludering är ett annat vanligt misstag—att lägga till för många URL:er (hundratals eller tusentals) motverkar syftet med kurering och gör det svårare för AI-system att identifiera verkligt viktigt innehåll. Dåliga eller saknade beskrivningar för varje URL innebär att AI-system inte förstår varför innehållet är värdefullt eller vad det handlar om. Att inte uppdatera din LLMs.txt-fil regelbundet gör att den blir inaktuell, med brutna länkar och irrelevant innehåll som inte längre speglar din webbplats fokus. Att inkludera inloggningskrävande innehåll eller betalväggade artiklar som AI-system inte kan komma åt skapar frustration och minskat förtroende. Slutligen, se till att du använder rätt MIME-typ (text/plain eller text/markdown) när du serverar filen, eftersom fel konfiguration kan förhindra att AI-system kan tolka den korrekt.
Flera verktyg och resurser har utvecklats för att förenkla skapandet och underhållet av LLMs.txt-filer. AIOSEO erbjuder en dedikerad plugin som automatiskt genererar både llms.txt och llms-full.txt-filer, vilket gör implementeringen tillgänglig även för icke-tekniska användare. För dem som föredrar manuell skapande är processen enkel—skapa bara en textfil i markdownformat och ladda upp den till din rotkatalog. Valideringsverktyg finns online för att kontrollera din LLMs.txt-fil för korrekt formatering, brutna länkar och överensstämmelse med standarden. GitHub-communityn har skapat många repositorier med mallar, exempel och bästa praxis för LLMs.txt-implementering. Officiell dokumentation på llmstxt.org tillhandahåller omfattande vägledning om filstruktur, formateringskrav och implementeringsstrategier. Många AI-plattformsdokumentationer innehåller nu sektioner om stöd för LLMs.txt, vilket hjälper dig att förstå hur olika system använder ditt kurerade innehåll. Dessa resurser gör det sammantaget enklare än någonsin att implementera LLMs.txt och säkerställa att ditt innehåll är ordentligt optimerat för AI-baserad upptäckt och citering.
LLMs.txt vägleder AI-system till ditt bästa innehåll för användning vid inferenstid, medan robots.txt styr vad sökmotorscrawlare kan komma åt. De har olika syften och kan samexistera på samma domän. LLMs.txt handlar om kurering och vägledning, medan robots.txt handlar om åtkomstkontroll.
Nej, det är inte obligatoriskt, men det håller på att bli en bästa praxis. Implementering av LLMs.txt ger dig ett konkurrensfördel i AI-drivna sökresultat och säkerställer att ditt innehåll får korrekt attribution när det citeras av AI-system.
Filen måste placeras i rotkatalogen på din domän (t.ex. dinwebbplats.com/llms.txt) för att kunna upptäckas av AI-system och crawlare. Den ska vara offentligt tillgänglig utan autentisering.
Nej, llms.txt är inte avsedd för blockering eller kontroll av träning. Den är specifikt för att vägleda AI-system under inferens (när svar genereras). Använd robots.txt eller andra mekanismer om du vill styra åtkomst för träning.
Granska och uppdatera varje kvartal eller när du gör betydande ändringar i din webbplatsstruktur, lägger till nytt viktigt innehåll eller ändrar URL:er. Regelbundet underhåll säkerställer att din fil förblir korrekt och värdefull.
OpenAI, Anthropic, Perplexity och Google har börjat implementera stöd för llms.txt. Användningen ökar i takt med att standarden blir mer etablerad och erkänd som en bästa praxis.
LLMs.txt är en kurerad lista över ditt bästa innehåll (vanligtvis 20-100 URL:er), medan llms-full.txt innehåller en komplett maskinläsbar version av allt ditt innehåll i Markdown-format. Båda kan användas tillsammans för maximal flexibilitet.
Fokusera på kvalitet framför kvantitet. Inkludera 10-20 av dina viktigaste, mest auktoritativa sidor som bäst representerar din expertis och innehållsvärde. Undvik att lägga in hela din sitemap i filen.
AmICited spårar hur AI-system refererar till ditt varumärke i ChatGPT, Perplexity, Google AI Overviews och mer. Säkerställ att ditt innehåll får korrekt attribution och synlighet i AI-genererade svar.
Kritisk analys av LLMs.txt effektivitet. Upptäck om denna AI-innehållsstandard är oumbärlig för din webbplats eller bara hype. Riktig data om användning, plattf...

Lär dig hur du implementerar LLMs.txt på din webbplats för att hjälpa AI-system att förstå ditt innehåll bättre. Komplett steg-för-steg-guide för alla plattform...

Lär dig vad LLMs.txt är, om det faktiskt fungerar och om du bör implementera det på din webbplats. Ärlig analys av denna framväxande AI SEO-standard.
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.