
FAQ-expansion
Lär dig hur FAQ-expansion utvecklar omfattande frågor och svar för AI-system. Upptäck strategier för att förbättra AI-citeringar, plattformsanpassad optimering ...
8 min läsning
Optimering av förfrågningsutvidgning är processen att förbättra användares sökförfrågningar med relaterade termer, synonymer och kontextuella variationer för att öka AI-systemens träffsäkerhet och innehållsrelevans. Det överbryggar vokabulärsgapet mellan användarförfrågningar och relevanta dokument, vilket säkerställer att AI-system som GPT:er och Perplexity kan hitta och referera till mer passande innehåll. Denna teknik är avgörande för att förbättra både omfattning och noggrannhet i AI-genererade svar. Genom att utvidga förfrågningar på ett intelligent sätt kan AI-plattformar dramatiskt förbättra hur de upptäcker och citerar relevanta källor.
Optimering av förfrågningsutvidgning är processen att förbättra användares sökförfrågningar med relaterade termer, synonymer och kontextuella variationer för att öka AI-systemens träffsäkerhet och innehållsrelevans. Det överbryggar vokabulärsgapet mellan användarförfrågningar och relevanta dokument, vilket säkerställer att AI-system som GPT:er och Perplexity kan hitta och referera till mer passande innehåll. Denna teknik är avgörande för att förbättra både omfattning och noggrannhet i AI-genererade svar. Genom att utvidga förfrågningar på ett intelligent sätt kan AI-plattformar dramatiskt förbättra hur de upptäcker och citerar relevanta källor.
Optimering av förfrågningsutvidgning är processen att omformulera och förbättra sökförfrågningar genom att lägga till relaterade termer, synonymer och semantiska variationer för att förbättra återhämtningsprestanda och svarskvalitet. I grunden tar förfrågningsutvidgning itu med vokabulärsmissmatchproblemet – den grundläggande utmaningen att användare och AI-system ofta använder olika terminologi för att beskriva samma begrepp, vilket leder till att relevanta resultat missas. Denna teknik är avgörande för AI-system eftersom den överbryggar gapet mellan hur människor uttrycker sina informationsbehov och hur innehållet faktiskt indexeras och lagras. Genom att utvidga förfrågningar på ett intelligent sätt kan AI-plattformar dramatiskt förbättra både relevansen och omfattningen av sina svar.
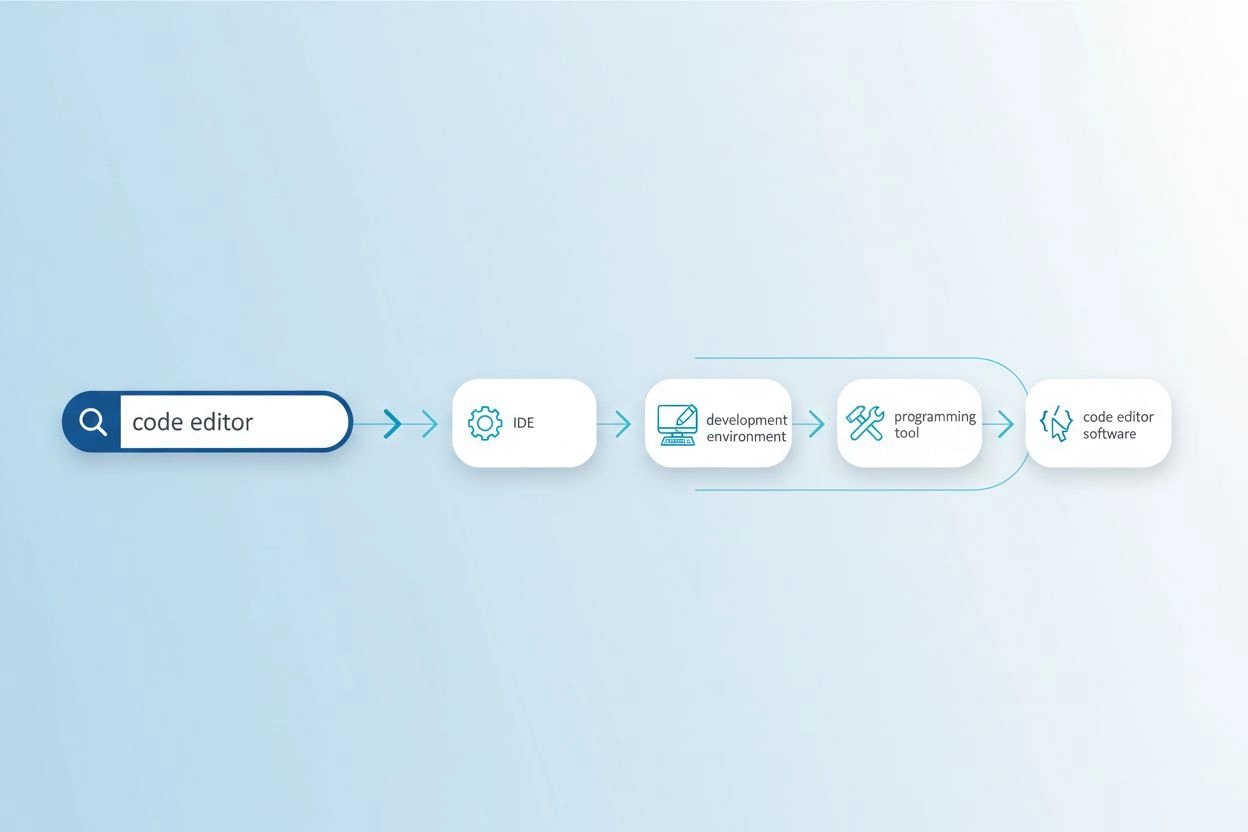
Vokabulärsmissmatchproblemet uppstår när de exakta orden som används i en förfrågan inte matchar den terminologi som finns i relevanta dokument, vilket gör att söksystem missar värdefull information. Till exempel kan en användare som söker efter “kodredigerare” missa resultat om “IDE:er” (Integrated Development Environments) eller “textredigerare”, även om dessa är mycket relevanta alternativ. På samma sätt kanske någon som söker efter “fordon” inte hittar resultat taggade med “bil”, “automobil” eller “motorfordon”, trots tydlig semantisk överlappning. Problemet blir allt allvarligare i specialiserade områden där flera tekniska termer beskriver samma begrepp, och det påverkar direkt kvaliteten på AI-genererade svar genom att begränsa det tillgängliga källmaterialet. Förfrågningsutvidgning löser detta genom att automatiskt generera relaterade förfrågningsvarianter som fångar olika sätt samma information kan uttryckas på.
| Ursprunglig förfrågan | Utvidgad förfrågan | Effekt |
|---|---|---|
| kodredigerare | IDE, textredigerare, utvecklingsmiljö, källkodredigerare | Finner 3–5x fler relevanta resultat |
| maskininlärning | AI, artificiell intelligens, djupinlärning, neurala nätverk | Fångar domänspecifika terminologivarianter |
| fordon | bil, automobil, motorfordon, transportmedel | Inkluderar vanliga synonymer och relaterade termer |
| huvudvärk | migrän, spänningshuvudvärk, smärtlindring, behandling av huvudvärk | Hanterar medicinska terminologivarianter |
Modern förfrågningsutvidgning använder flera kompletterande tekniker, var och en med distinkta fördelar beroende på användningsområde och domän:
Varje teknik erbjuder olika avvägningar mellan beräkningskostnad, utvidgningskvalitet och domänspecifikhet, där LLM-baserade metoder ger högsta kvalitet men kräver mer resurser.
Förfrågningsutvidgning förbättrar AI-svar genom att ge språkmodeller och återhämtningssystem ett rikare och mer omfattande urval av källmaterial att hämta från vid generering av svar. När en förfrågan utvidgas med synonymer, relaterade begrepp och alternativa formuleringar kan återhämtningssystemet få tillgång till dokument som använder annan terminologi men innehåller lika relevant information, vilket dramatiskt ökar recall i sökprocessen. Denna utökade kontext gör att AI-system kan sammanfatta mer kompletta och nyanserade svar, eftersom de inte längre begränsas av den specifika vokabulären i den ursprungliga förfrågan. Dock innebär förfrågningsutvidgning ett avvägning mellan precision och recall: medan utvidgade förfrågningar hämtar fler relevanta dokument kan de också introducera brus och mindre relevanta resultat om utvidgningen är för aggressiv. Nyckeln till optimering är att kalibrera utvidgningsintensiteten för att maximera relevansförbättringar och minimera irrelevant brus, så att AI-svar blir mer heltäckande utan att förlora i noggrannhet.
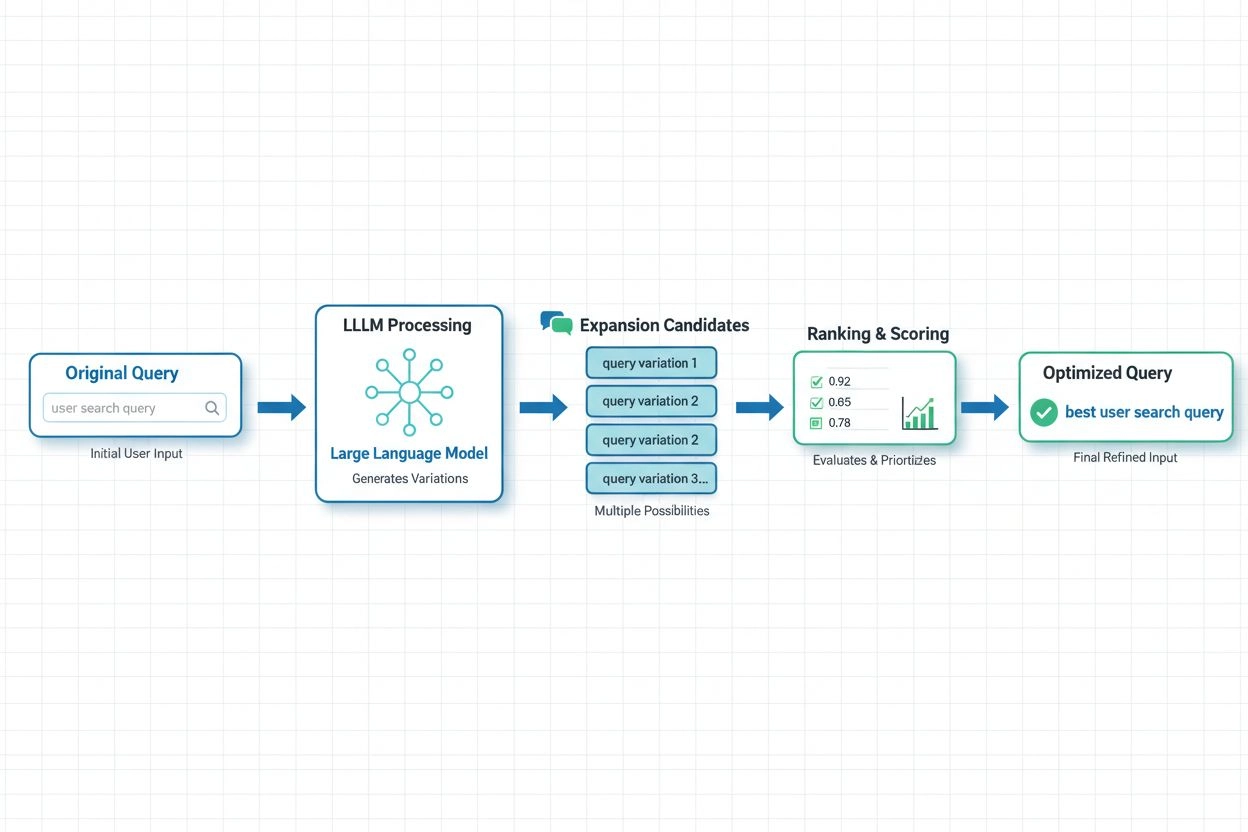
I moderna AI-system har LLM-baserad förfrågningsutvidgning blivit det mest sofistikerade tillvägagångssättet och utnyttjar de semantiska förståelsemöjligheterna hos stora språkmodeller för att generera kontextuellt lämpliga förfrågningsvarianter. Färsk forskning från Spotify visar kraften i detta tillvägagångssätt: deras implementation med preferensjusteringstekniker (kombinerande RSFT- och DPO-metoder) uppnådde cirka 70 % minskning av bearbetningstiden samtidigt som topp-1 träffsäkerheten förbättrades. Dessa system fungerar genom att träna språkmodeller att förstå användarpreferenser och avsikt och sedan generera utvidgningar som överensstämmer med vad användare faktiskt värdesätter, istället för att bara lägga till godtyckliga synonymer. Realtidsoptimering anpassar kontinuerligt utvidgningsstrategier baserat på användarfeedback och återhämtningsresultat, vilket gör att systemen lär sig vilka utvidgningar som fungerar bäst för specifika förfrågningstyper och domäner. Detta dynamiska tillvägagångssätt är särskilt värdefullt för AI-övervakningsplattformar, eftersom det gör det möjligt att spåra hur förfrågningsutvidgning påverkar citeringsnoggrannhet och innehållsupptäckt över olika ämnen och branscher.
Trots sina fördelar innebär förfrågningsutvidgning betydande utmaningar som kräver noggranna optimeringsstrategier. Överutvidgningsproblemet uppstår när för många förfrågningsvarianter läggs till, vilket introducerar brus och hämtar irrelevanta dokument som försämrar svarskvaliteten och ökar beräkningskostnaderna. Domänspecifik justering är avgörande eftersom utvidgningstekniker som fungerar bra för allmän webbsökning kan misslyckas i specialiserade områden som medicinsk forskning eller juridisk dokumentation, där terminologisk precision är kritisk. Organisationer måste balansera täckning mot noggrannhet – utvidga tillräckligt för att fånga relevanta variationer utan att utvidga så mycket att irrelevanta resultat överskuggar signalen. Effektiva valideringsmetoder inkluderar A/B-testning av olika utvidgningsstrategier mot mänskligt bedömda relevansbetyg, övervakning av mätvärden som precision@k och recall@k samt kontinuerlig analys av vilka utvidgningar som faktiskt förbättrar nedströmsuppgifter. De mest framgångsrika implementationerna använder adaptiv utvidgning som justerar intensiteten baserat på förfrågans egenskaper, domänkontext och observerad återhämtningskvalitet, istället för att tillämpa enhetliga utvidgningsregler för alla förfrågningar.
För AmICited.com och AI-övervakningsplattformar är optimering av förfrågningsutvidgning grundläggande för att korrekt kunna spåra hur AI-system citerar och refererar källor över olika ämnen och sökkontexter. När AI-system använder utvidgade förfrågningar internt får de tillgång till ett bredare utbud av potentiella källmaterial, vilket direkt påverkar vilka citeringar som visas i deras svar och hur heltäckande de täcker tillgänglig information. Det innebär att övervakning av AI-svarens kvalitet kräver förståelse inte bara för vad användare frågar, utan även vilka utvidgade förfrågningsvarianter AI-systemet använder bakom kulisserna för att hämta stödjande information. Varumärken och innehållsskapare bör optimera sin innehållsstrategi genom att överväga hur deras material kan upptäckas via förfrågningsutvidgning – använda flera terminologivarianter, synonymer och relaterade begrepp i sitt innehåll för att säkerställa synlighet över olika förfrågningsformuleringar. AmICited hjälper organisationer att spåra detta genom att övervaka hur deras innehåll förekommer i AI-genererade svar över olika förfrågningstyper och utvidgningar, avslöja luckor där innehåll kan missas på grund av vokabulärsmissmatch och ge insikter om hur strategier för förfrågningsutvidgning påverkar citeringsmönster och innehållsupptäckt i AI-system.
Förfrågningsutvidgning lägger till relaterade termer och synonymer till den ursprungliga förfrågan samtidigt som kärnsyftet behålls, medan förfrågningsomskrivning omformulerar hela förfrågan för att bättre matcha söksystemets kapacitet. Förfrågningsutvidgning är additiv – den breddar sökomfånget – medan omskrivning är transformerande och ändrar hur förfrågan uttrycks. Båda teknikerna förbättrar återhämtning, men utvidgning är vanligtvis mindre riskfylld då den bevarar den ursprungliga förfrågans syfte.
Förfrågningsutvidgning påverkar direkt vilka källor AI-system upptäcker och citerar eftersom det förändrar vilka dokument som är tillgängliga för återhämtning. När AI-system använder utvidgade förfrågningar internt får de tillgång till ett bredare utbud av potentiella källor, vilket påverkar vilka citeringar som visas i deras svar. Det innebär att övervakning av AI-svarens kvalitet kräver förståelse för inte bara vad användare frågar, utan även vilka utvidgade förfrågningsvarianter AI-systemet kan använda bakom kulisserna.
Ja, överutvidgning kan introducera brus och hämta irrelevanta dokument som försämrar svarskvaliteten. Detta sker när för många förfrågningsvarianter läggs till utan korrekt filtrering. Nyckeln är att balansera utvidgningsintensiteten för att maximera relevansförbättringar och minimera irrelevant brus. Effektiva implementationer använder adaptiv utvidgning som justerar intensiteten baserat på förfrågans egenskaper och observerad återhämtningskvalitet.
Stora språkmodeller har revolutionerat förfrågningsutvidgning genom att möjliggöra semantisk förståelse av användarens avsikt och generera kontextuellt lämpliga förfrågningsvarianter. LLM-baserad utvidgning använder preferensjusteringstekniker för att träna modeller att generera utvidgningar som faktiskt förbättrar återhämtningsresultaten, istället för att bara lägga till godtyckliga synonymer. Färsk forskning visar att LLM-baserade metoder kan minska bearbetningstiden med cirka 70 % samtidigt som återhämtningsnoggrannheten förbättras.
Varumärken bör använda flera terminologiska variationer, synonymer och relaterade begrepp i sitt innehåll för att säkerställa synlighet över olika förfrågningsformuleringar. Det innebär att överväga hur ditt material kan upptäckas genom förfrågningsutvidgning – använda både tekniska och vardagliga termer, inkludera alternativa formuleringar och ta upp relaterade begrepp. Denna strategi gör att ditt innehåll kan upptäckas oavsett vilka förfrågningsvarianter AI-systemen använder.
Viktiga mätvärden inkluderar precision@k (relevans för de k bästa resultaten), recall@k (täckning av relevant innehåll i de k bästa resultaten), Mean Reciprocal Rank (positionen för det första relevanta resultatet) och resultat för nedströmsuppgifter. Organisationer övervakar även bearbetningstid, beräkningskostnader och användartillfredsställelse. A/B-testning av olika utvidgningsstrategier mot mänskligt bedömda relevansbetyg ger den mest tillförlitliga valideringen.
Nej, de är kompletterande men olika tekniker. Förfrågningsutvidgning ändrar indataförfrågan för att förbättra återhämtning, medan semantisk sökning använder inbäddningar och vektorrepresentationer för att hitta konceptuellt liknande innehåll. Förfrågningsutvidgning kan vara en del av en semantisk sökningspipeline, men semantisk sökning kan också fungera utan explicit förfrågningsutvidgning. Båda teknikerna hanterar vokabulärsmissmatch men genom olika mekanismer.
AmICited spårar hur AI-system citerar och refererar källor över olika ämnen och sökkontexter, och avslöjar vilka utvidgade förfrågningar som leder till att ditt varumärke refereras. Genom att övervaka citeringsmönster över olika förfrågningstyper och utvidgningar ger AmICited insikter om hur strategier för förfrågningsutvidgning påverkar innehållsupptäckt och citeringsnoggrannhet i AI-system som GPT:er och Perplexity.
Optimering av förfrågningsutvidgning påverkar hur AI-system som GPT:er och Perplexity upptäcker och citerar ditt innehåll. Använd AmICited för att spåra vilka utvidgade förfrågningar som leder till att ditt varumärke refereras i AI-svar.
Lär dig hur FAQ-expansion utvecklar omfattande frågor och svar för AI-system. Upptäck strategier för att förbättra AI-citeringar, plattformsanpassad optimering ...

Lär dig hur kontinuerlig optimering för AI-sök hjälper dig att övervaka och förbättra ditt varumärkes synlighet i AI-sökmotorer genom realtidsövervakning och da...
Lär dig AI-söknoptimeringsstrategier för att förbättra varumärkessynlighet i ChatGPT, Google AI Översikter och Perplexity. Optimera innehåll för LLM-citering oc...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.