En Retrieval-Augmented Generation (RAG)-pipeline är ett arbetsflöde som gör det möjligt för AI-system att hitta, rangordna och citera externa källor vid generering av svar. Den kombinerar dokumenthämtning, semantisk rangordning och LLM-generering för att ge exakta, kontextuellt relevanta svar baserade på verklig data. RAG-system minskar hallucinationer genom att konsultera externa kunskapsbaser innan svar produceras, vilket gör dem oumbärliga för applikationer som kräver faktakontroll och källhänvisning.
RAG-pipeline
En Retrieval-Augmented Generation (RAG)-pipeline är ett arbetsflöde som gör det möjligt för AI-system att hitta, rangordna och citera externa källor vid generering av svar. Den kombinerar dokumenthämtning, semantisk rangordning och LLM-generering för att ge exakta, kontextuellt relevanta svar baserade på verklig data. RAG-system minskar hallucinationer genom att konsultera externa kunskapsbaser innan svar produceras, vilket gör dem oumbärliga för applikationer som kräver faktakontroll och källhänvisning.
Vad är en RAG-pipeline?
En Retrieval-Augmented Generation (RAG)-pipeline är en AI-arkitektur som kombinerar informationshämtning med generering från stora språkmodeller (LLM) för att producera mer exakta, kontextuellt relevanta och verifierbara svar. Istället för att förlita sig enbart på en LLM:s träningsdata hämtar RAG-system dynamiskt relevanta dokument eller data från externa kunskapsbaser före svarsgenerering, vilket kraftigt minskar hallucinationer och förbättrar faktakontrollen. Pipen fungerar som en bro mellan statisk träningsdata och realtidsinformation, vilket gör att AI-system kan referera till aktuellt, domänspecifikt eller proprietärt innehåll. Detta tillvägagångssätt har blivit avgörande för organisationer som kräver källhänvisade svar, uppfyllnad av faktakrav och transparens i AI-genererat innehåll. RAG-pipelines är särskilt värdefulla i övervakning av AI-system där spårbarhet och källattribuering är kritiska krav.
Kärnkomponenter
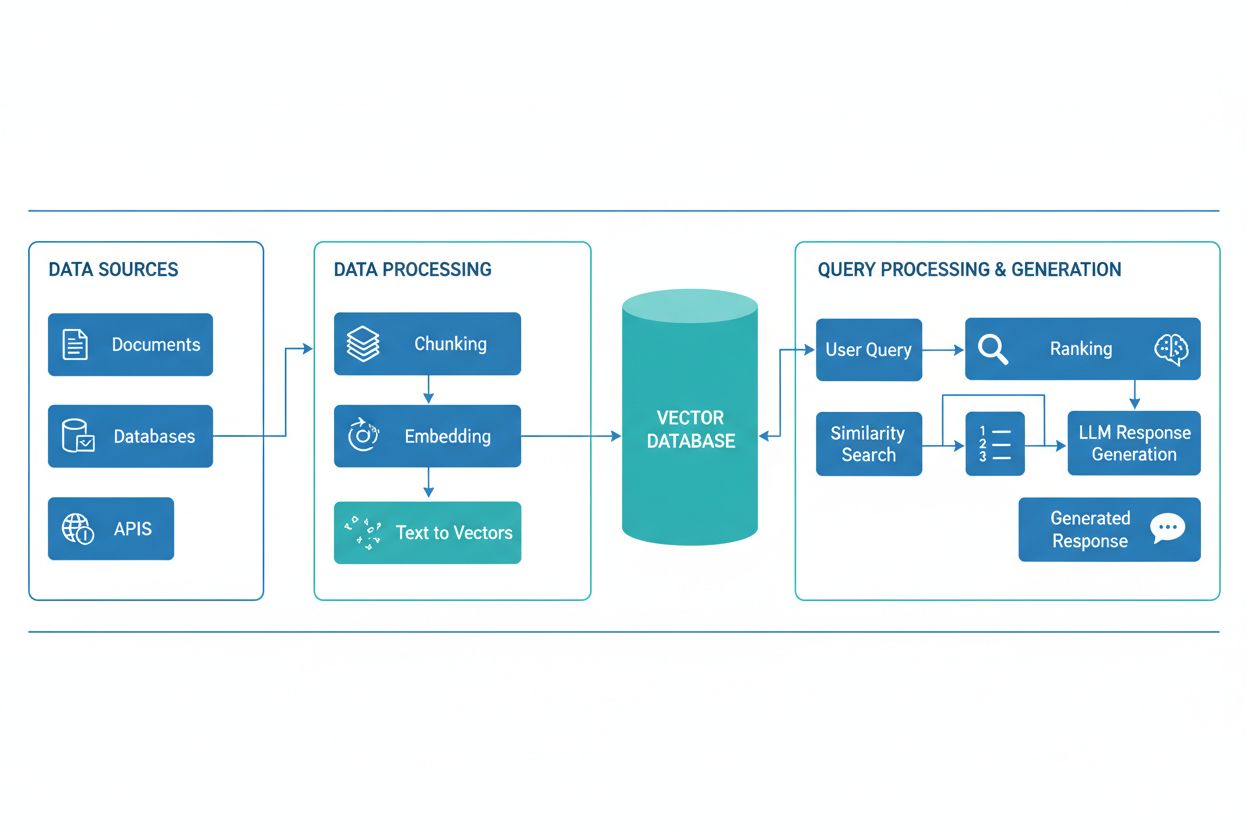
En RAG-pipeline består av flera sammankopplade komponenter som tillsammans hämtar relevant information och genererar förankrade svar. Arkitekturen innefattar vanligtvis ett dokumentinsamlingslager som bearbetar och förbereder rådata, en vektordatabas eller kunskapsbas som lagrar embeddingar och indexerat innehåll, en hämtmekanism som identifierar relevanta dokument baserat på användarens fråga, ett rangordningssystem som prioriterar de mest relevanta resultaten, samt en genereringsmodul driven av en LLM som syntetiserar hämtad information till sammanhängande svar. Ytterligare komponenter inkluderar frågebehandling och förbehandlingsmoduler som normaliserar användarinmatning, embeddingmodeller som konverterar text till numeriska representationer och en återkopplingsslinga som kontinuerligt förbättrar hämtningens precision. Hur dessa komponenter samverkar avgör RAG-systemets totala effektivitet och prestanda.
RAG-pipelinen fungerar i två distinkta faser: hämtfasen och genereringsfasen. Under hämtfasen omvandlar systemet användarens fråga till en embedding med samma embeddingmodell som använts för kunskapsbasens dokument och söker därefter i vektordatabasen för att hitta de semantiskt mest liknande dokumenten eller passagerna. Denna fas returnerar vanligtvis en rangordnad lista över kandidater, som kan förfinas ytterligare med omrankningsalgoritmer baserade på cross-encoders eller LLM-baserad poängsättning för att säkerställa relevans. I genereringsfasen formateras de topprankade hämtade dokumenten till ett kontextfönster och skickas till LLM-modellen tillsammans med den ursprungliga frågan, vilket gör att modellen kan generera svar som är förankrade i verkliga källor. Detta tvåstegsförfarande säkerställer att svaren är både kontextuellt lämpliga och spårbara till specifika källor, vilket gör det idealiskt för applikationer som kräver citering och ansvarstagande. Kvaliteten på slutresultatet beror kritiskt på både relevansen hos de hämtade dokumenten och LLM:ens förmåga att syntetisera information på ett sammanhängande sätt.
Viktiga tekniker & verktyg
RAG-ekosystemet omfattar en mångfald av specialiserade verktyg och ramverk som förenklar konstruktion och implementering av pipelines. Moderna RAG-implementationer utnyttjar flera teknikkategorier:
Orkestreringsramverk: LangChain, LlamaIndex (tidigare GPT Index) och Haystack erbjuder abstraktionslager för att bygga RAG-arbetsflöden utan att behöva hantera varje komponent separat
Vektordatabaser: Pinecone, Weaviate, Milvus, Qdrant och Chroma erbjuder skalbar lagring och hämtning av högdimensionella embeddingar med submillisekundsfrågetider
Embeddingmodeller: OpenAI:s text-embedding-3, Cohere’s Embed API och open source-modeller som all-MiniLM-L6-v2 omvandlar text till semantiska representationer
LLM-leverantörer: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) och Mistral erbjuder olika modellstorlekar och funktioner för genereringsuppgifter
Omrankningslösningar: Cohere’s Rerank API, cross-encoder-modeller från Hugging Face och proprietära LLM-baserade omrankare förbättrar hämtningens precision
Databeredskapsverktyg: Unstructured, Apache Kafka och anpassade ETL-pipelines hanterar dokumentinsamling, uppdelning och förbearbetning
Övervakning och utvärdering: Verktyg som Ragas, TruLens och anpassade utvärderingsramverk bedömer RAG-systemets prestanda och identifierar felkällor
Dessa verktyg kan kombineras modulärt, vilket gör att organisationer kan bygga RAG-system anpassade till sina specifika krav och infrastrukturbegränsningar.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hämtningmekanismer
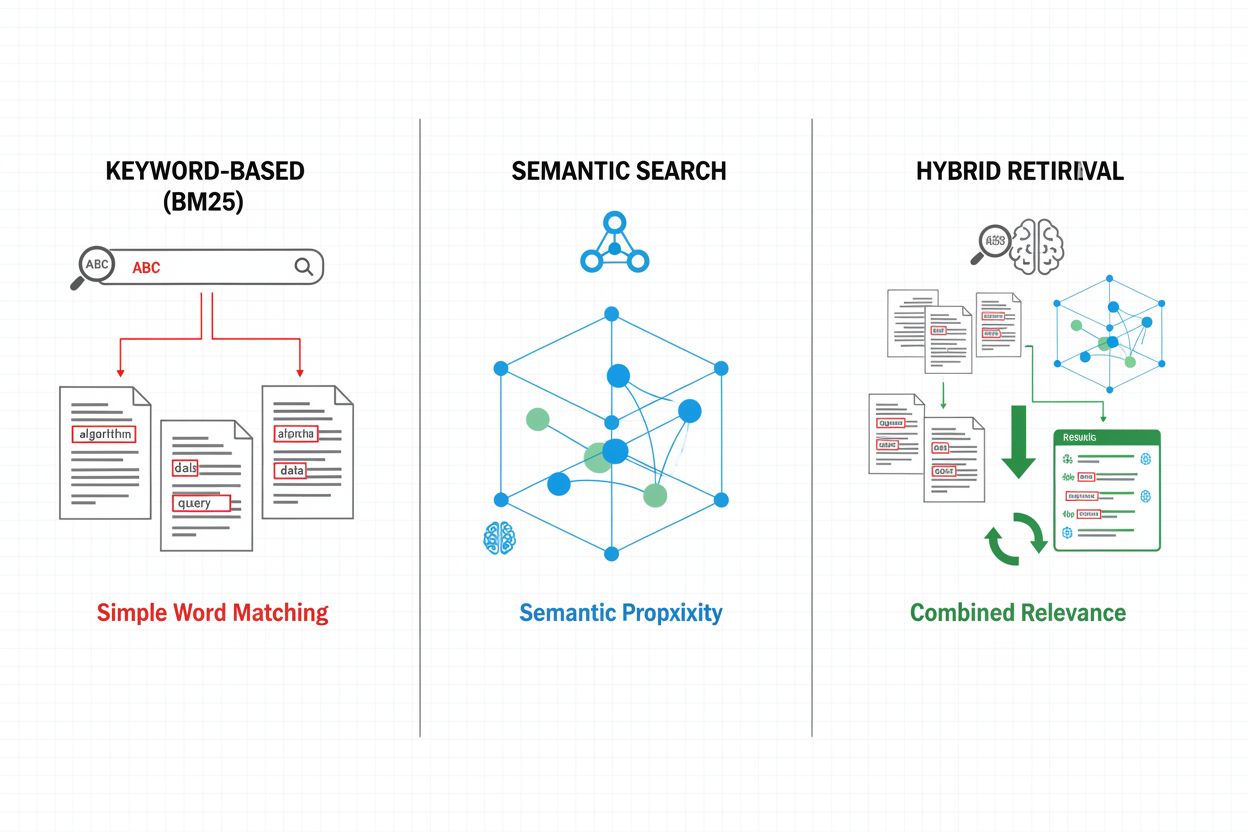
Hämtningmekanismer utgör grunden för RAG-pipeline:ens effektivitet och har utvecklats från enkla nyckelordsbaserade metoder till avancerade semantiska sökmetoder. Traditionell nyckelordsbaserad hämtning med BM25-algoritmer är fortsatt beräkningsmässigt effektiv och lämplig för exakta träffar, men har svårt med semantisk förståelse och synonymer. Dense Passage Retrieval (DPR) och andra neurala hämtmetoder hanterar dessa brister genom att koda både frågor och dokument till täta vektorembeddingar, vilket möjliggör semantisk likhetsmatchning som fångar mening bortom ytliga nyckelord. Hybridmetoder kombinerar nyckelordsbaserad och semantisk sökning och drar nytta av båda metodernas styrkor för att förbättra återvinning och precision över olika frågetyper. Avancerade hämtningmekanismer inkluderar frågeexpansion, där ursprungsfrågan utökas med relaterade termer eller omformuleringar för att fånga fler relevanta dokument. Omrankningslager förfinar ytterligare resultaten genom att använda mer beräkningsintensiva modeller som poängsätter kandidater baserat på djupare semantisk förståelse eller uppgiftspecifik relevans. Valet av hämtningmekanism påverkar starkt både precisionen i hämtad kontext och RAG-pipeline:ens beräkningskostnad och kräver noggrann avvägning mellan hastighet och kvalitet.
Fördelar med RAG-pipelines
RAG-pipelines ger betydande fördelar jämfört med traditionella LLM-baserade metoder, särskilt för applikationer som kräver noggrannhet, aktualitet och spårbarhet. Genom att förankra svaren i hämtade dokument minskar RAG-system dramatiskt hallucinationer—fall där LLM:er genererar trovärdiga men felaktiga uppgifter—och gör dem därmed lämpliga för områden med höga krav som hälsa, juridik och finans. Förmågan att referera till externa kunskapsbaser gör att RAG-system kan ge aktuell information utan att behöva träna om modeller, vilket gör det möjligt för organisationer att hålla svar uppdaterade när ny information tillkommer. RAG-pipelines stödjer domänspecifik anpassning genom att inkludera egna dokument, interna kunskapsbaser och specialiserad terminologi, vilket möjliggör mer relevanta och kontextuellt anpassade svar. Hämtkomponenten ger transparens och möjlighet till revision genom att tydligt visa vilka källor som ligger bakom varje svar, vilket är kritiskt för efterlevnadskrav och användarförtroende. Kostnadseffektiviteten ökar genom användning av mindre, effektivare LLM:er som kan generera högkvalitativa svar när de får rätt kontext, vilket minskar beräkningsbördan jämfört med större modeller. Dessa fördelar gör RAG särskilt värdefullt för organisationer som implementerar AI-övervakningssystem där citeringsnoggrannhet och innehållssynlighet är avgörande.
Utmaningar och begränsningar
Trots sina fördelar står RAG-pipelines inför flera tekniska och operationella utmaningar som kräver noggrann hantering. Kvaliteten på de hämtade dokumenten avgör direkt kvaliteten på svaren, vilket gör det svårt att återhämta sig från hämtfel—ett fenomen känt som “garbage in, garbage out” där irrelevanta eller föråldrade dokument i kunskapsbasen får genomslag i slutsvaren. Embeddingmodeller kan ha svårt med domänspecifik terminologi, sällsynta språk eller mycket tekniskt innehåll, vilket leder till dålig semantisk matchning och missade relevanta dokument. Beräkningskostnaden för hämtning, embeddinggenerering och omrankning kan vara betydande i stor skala, särskilt vid bearbetning av stora kunskapsbaser eller vid hög belastning. Begränsningar i LLM:ens kontextfönster begränsar mängden hämtad information som kan tas med i prompten, vilket kräver noggrann urval och sammanfattning av relevanta passager. Att hålla kunskapsbasen aktuell och konsekvent innebär operationella utmaningar, särskilt i dynamiska miljöer där information ofta ändras eller kommer från flera källor. Utvärdering av RAG-system kräver omfattande mätvärden, utöver traditionell noggrannhet, såsom hämtningens precision, svarsrelevans och citeringskorrekthet, vilket kan vara svårt att bedöma automatiskt.
RAG vs. andra metoder
RAG utgör ett av flera tillvägagångssätt för att förbättra LLM:s noggrannhet och relevans, där varje strategi har sina egna avvägningar. Finjustering innebär ominlärning av LLM på domänspecifik data, vilket ger djup anpassning men kräver betydande beräkningsresurser, annoterad träningsdata och kontinuerligt underhåll vid informationsförändringar. Prompt engineering optimerar instruktioner och kontext till LLM utan att ändra modellvikterna, vilket ger flexibilitet och låga kostnader men begränsas av modellens träningsdata och kontextfönster. In-context learning använder exempel i prompten för att styra modellens beteende, vilket ger snabb anpassning men förbrukar värdefulla kontexttokens och kräver noggrant urval av exempel. Jämfört med dessa erbjuder RAG en medelväg: dynamisk tillgång till aktuell information utan ominlärning, transparens genom tydlig källhänvisning och effektiv skala över olika kunskapsområden. Dock introducerar RAG extra komplexitet genom hämtinfrastruktur och potentiella hämtfel, medan finjustering ger tightare integration av domänkunskap i modellens beteende. Den optimala strategin innebär ofta en kombination av flera metoder—till exempel att använda RAG tillsammans med finjusterade modeller och noggrant utformade prompts för att maximera noggrannhet och relevans i specifika tillämpningar.
Att bygga och implementera RAG
Att implementera en produktionsklar RAG-pipeline kräver systematisk planering kring databeredskap, arkitekturdesign och drift. Processen börjar med förberedelse av kunskapsbasen: samla in relevanta dokument, rensa och standardisera format samt dela upp innehåll i lagom stora segment som balanserar kontextbevarande med hämtprecision. Därefter väljs embeddingmodeller och vektordatabaser utifrån prestandakrav, svarstid och skalbarhet, med hänsyn till embeddingdimensioner, frågekapacitet och lagringsbehov. Hämtsystemet konfigureras sedan, inklusive val av hämtalgoritmer (nyckelord, semantisk eller hybrid), omrankningsstrategier och filtreringskriterier. Integration med LLM-leverantörer följer, där man sätter upp anslutningar till genereringsmodeller och definierar promptmallar som effektivt införlivar hämtad kontext. Testning och utvärdering är avgörande, med mätvärden för hämtkvalitet (precision, recall, MRR), genereringskvalitet (relevans, sammanhang, faktakontroll) och helhetsprestanda. Vid implementering krävs övervakning av hämtprecision och genereringskvalitet, återkopplingsslingor för att identifiera och hantera felkällor samt processer för uppdatering och underhåll av kunskapsbasen. Slutligen innebär kontinuerlig optimering att analysera användarinteraktioner, identifiera vanliga felmönster och successivt förbättra hämtmekanismer, omrankningsstrategier och prompt engineering för att höja systemets totala prestanda.
RAG i AI-övervakning och citering
RAG-pipelines är grundläggande för moderna AI-övervakningsplattformar som AmICited.com, där spårning av ursprung och noggrannhet i AI-genererat innehåll är avgörande. Genom att explicit hämta och citera källdokument skapar RAG-system en reviderbar spårbarhet som gör det möjligt för övervakningsplattformar att verifiera påståenden, bedöma faktakontroll och identifiera potentiella hallucinationer eller felattribueringar. Denna citeringskapacitet åtgärdar en kritisk brist i AI-transparens: användare och revisorer kan spåra svar till ursprungskällor, vilket möjliggör oberoende verifiering och stärker förtroendet för AI-genererat innehåll. För innehållsskapare och organisationer som använder AI-verktyg ger RAG-baserad övervakning insyn i vilka källor som ligger till grund för specifika svar och stödjer efterlevnad av krav på attribuering och innehållsstyrning. RAG-pipelinen genererar rik metadata—inklusive relevanspoäng, dokumentrangordning och hämtkonfidens—som övervakningssystem kan analysera för att bedöma svarens tillförlitlighet och identifiera när AI-system agerar utanför sitt kunskapsområde. Integrationen av RAG med övervakningsplattformar möjliggör upptäckt av citeringsdrift, där AI-system gradvis förskjuter sig från auktoritativa till mindre pålitliga källor, samt stöder upprätthållande av innehållspolicyer kring källkvalitet och mångfald. I takt med att AI-system blir alltmer integrerade i kritiska arbetsflöden skapas med kombinationen av RAG-pipelines och omfattande övervakning ansvarsmekanismer som skyddar användare, organisationer och det bredare informationsekosystemet mot AI-genererad desinformation.
Vanliga frågor
Vad är skillnaden mellan RAG och finjustering?
RAG och finjustering är kompletterande metoder för att förbättra LLM-prestanda. RAG hämtar externa dokument vid förfrågan utan att ändra modellen, vilket möjliggör åtkomst till realtidsdata och enkla uppdateringar. Finjustering tränar om modellen på domänspecifik data, ger djupare anpassning men kräver betydande datorkraft och manuella uppdateringar när information ändras. Många organisationer använder båda teknikerna tillsammans för optimala resultat.
Hur minskar RAG hallucinationer i AI-svar?
RAG minskar hallucinationer genom att förankra LLM-svar i hämtade faktadokument. Istället för att enbart förlita sig på träningsdata hämtar systemet relevanta källor före generering och ger modellen konkret bevis att referera till. Detta tillvägagångssätt säkerställer att svaren baseras på verklig information istället för modellens inlärda mönster, vilket avsevärt förbättrar faktakontroll och minskar falska eller vilseledande påståenden.
Vad är vektorembeddingar och varför är de viktiga i RAG?
Vektorembeddingar är numeriska representationer av text som fångar semantisk mening i ett flerdimensionellt rum. De möjliggör semantisk sökning i RAG-system, så att dokument med liknande betydelse kan hittas även om de använder olika ord. Embeddingar är avgörande eftersom de låter RAG gå bortom nyckelords-matchning och förstå begreppsrelationer, vilket förbättrar relevansen och möjliggör mer exakta svarsgenereringar.
Kan RAG-pipelines fungera med realtidsdata?
Ja, RAG-pipelines kan integrera realtidsdata genom kontinuerlig insamling och indexering. Organisationer kan upprätta automatiserade pipelines som regelbundet uppdaterar vektordatabasen med nya dokument, så att kunskapsbasen hålls aktuell. Denna kapacitet gör RAG idealiskt för applikationer som kräver uppdaterad information, såsom nyhetsanalys, prisintelligens och marknadsövervakning, utan att behöva träna om den underliggande LLM:n.
Vad är skillnaden mellan semantisk sökning och RAG?
Semantisk sökning är en hämtningsteknik som hittar dokument baserat på betydelseslikhet via vektorembeddingar. RAG är en komplett pipeline som kombinerar semantisk sökning med LLM-generering för att skapa svar som grundas i hämtade dokument. Medan semantisk sökning fokuserar på att hitta relevant information, tillför RAG en genereringskomponent som sammanställer hämtat innehåll till sammanhängande svar med källhänvisningar.
Hur bestämmer RAG-system vilka källor som ska citeras?
RAG-system använder flera mekanismer för att välja källor att citera. De använder hämtalgoritmer för att hitta relevanta dokument, omrankningsmodeller för att prioritera de mest relevanta resultaten och verifieringsprocesser för att säkerställa att citeringar faktiskt stöder påståendena. Vissa system använder 'citera-under-skrivande'-metoder där påståenden endast görs om de stöds av hämtade källor, medan andra verifierar citeringar efter generering och tar bort icke-underbyggda påståenden.
Vilka är de största utmaningarna vid byggandet av RAG-pipelines?
Viktiga utmaningar inkluderar att hålla kunskapsbasen aktuell och av hög kvalitet, optimera hämtningens precision över olika innehållstyper, hantera beräkningskostnader i stor skala, hantera domänspecifik terminologi som embeddingmodeller kan ha svårt med samt utvärdera systemets prestanda med omfattande mätvärden. Organisationer måste också hantera begränsade kontextfönster i LLM och säkerställa att hämtade dokument förblir relevanta när information förändras.
Hur övervakar AmICited RAG-citeringar i AI-system?
AmICited följer hur AI-system som ChatGPT, Perplexity och Google AI Overviews hämtar och citerar innehåll via RAG-pipelines. Plattformen övervakar vilka källor som väljs för citering, hur ofta ditt varumärke förekommer i AI-svar och om citeringarna är korrekta. Denna insyn hjälper organisationer att förstå sin närvaro i AI-förmedlad sökning och säkerställa korrekt attribuering av sitt innehåll.
Övervaka ditt varumärke i AI-svar
Följ hur AI-system som ChatGPT, Perplexity och Google AI Overviews refererar till ditt innehåll. Få insyn i RAG-citeringar och AI-svarsövervakning.
Vad är RAG i AI-sök: Komplett guide till Retrieval-Augmented Generation
Lär dig vad RAG (Retrieval-Augmented Generation) är inom AI-sök. Upptäck hur RAG förbättrar noggrannhet, minskar hallucinationer och driver ChatGPT, Perplexity ...
Hur Retrieval-Augmented Generation Fungerar: Arkitektur och Process
Lär dig hur RAG kombinerar LLM:er med externa datakällor för att generera exakta AI-svar. Förstå processen i fem steg, komponenterna och varför det är viktigt f...
Lär dig vad Retrieval-Augmented Generation (RAG) är, hur det fungerar och varför det är avgörande för exakta AI-svar. Utforska RAG-arkitektur, fördelar och före...
11 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.