Forskningsinnehåll – Datadrivet Analytiskt Innehåll
Forskningsinnehåll är evidensbaserat material skapat genom dataanalys och expertinsikter. Lär dig hur datadrivet analytiskt innehåll bygger auktoritet, påverkar...
11 min läsning
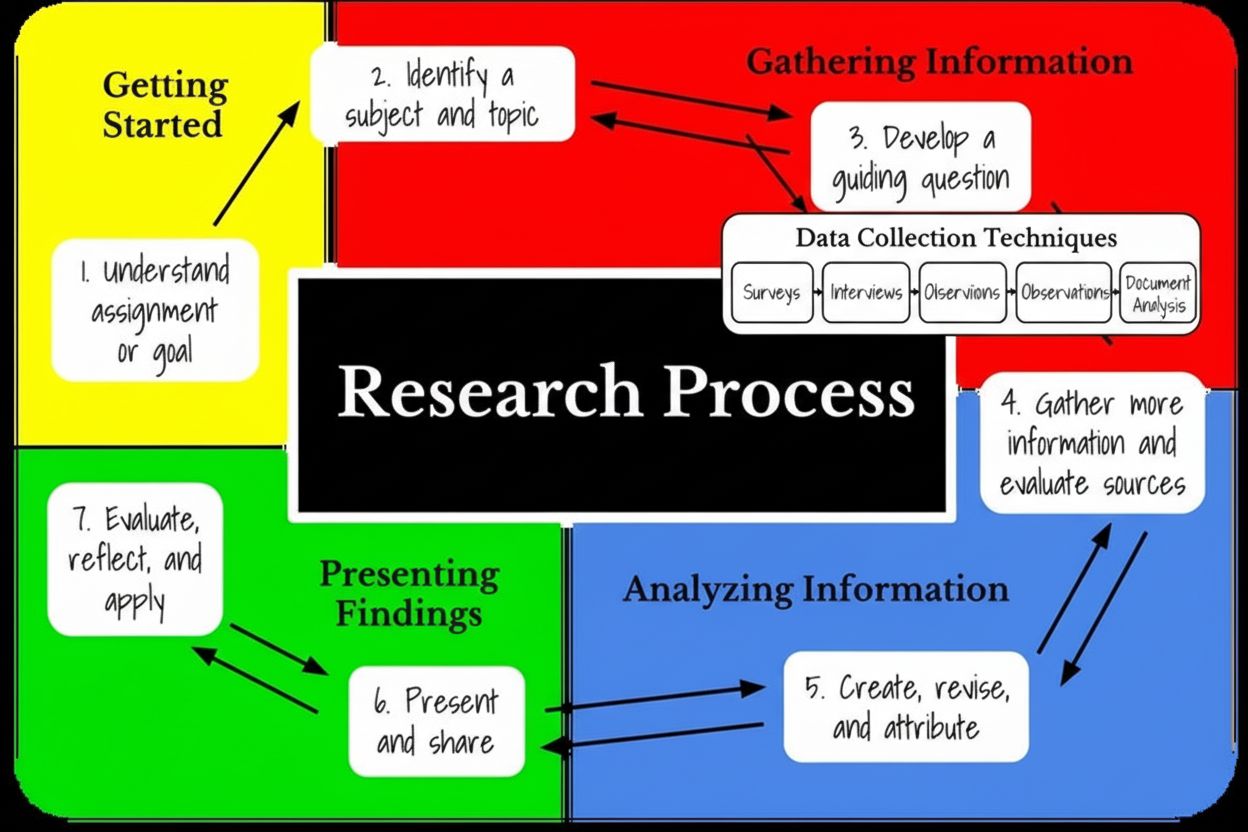
Forskningsfasens informationsinsamlingsstadium är den systematiska processen att samla in, organisera och utvärdera data, fakta och kunskap från olika källor för att besvara specifika forskningsfrågor. Detta grundläggande stadium innebär att välja lämpliga datainsamlingsmetoder, implementera kvalitetskontrollåtgärder och fastställa tydliga mål innan analys och tolkning påbörjas.
Forskningsfasens informationsinsamlingsstadium är den systematiska processen att samla in, organisera och utvärdera data, fakta och kunskap från olika källor för att besvara specifika forskningsfrågor. Detta grundläggande stadium innebär att välja lämpliga datainsamlingsmetoder, implementera kvalitetskontrollåtgärder och fastställa tydliga mål innan analys och tolkning påbörjas.
Forskningsfasens informationsinsamlingsstadium är en systematisk och organiserad process för att samla in, ordna och utvärdera data, fakta och kunskap från olika källor för att besvara specifika forskningsfrågor eller uppnå definierade mål. Detta kritiska stadium utgör grunden för alla efterföljande forskningsaktiviteter, inklusive analys, tolkning och slutsatsdragning. Informationsinsamling är mycket mer än enkel datainsamling; det omfattar noggrann planering, identifiering av källor, implementering av kvalitetskontroll och involvering av intressenter för att säkerställa att insamlad information är korrekt, relevant och direkt tillämplig på forskningsfrågan. Stadiet kännetecknas av metodiska procedurer som omvandlar råa observationer och mätningar till organiserade datamängder redo för analys. Att förstå detta stadium är avgörande för forskare, akademiker, affärsanalytiker och yrkesverksamma som arbetar med evidensbaserat beslutsfattande inom alla discipliner.
Formaliseringen av informationsinsamlingsstadiet uppstod ur den vetenskapliga metodens utveckling under 1600- och 1700-talen, när systematiska observationer och datainsamling blev erkända som väsentliga delar av rigorös undersökning. Moderna metoder för informationsinsamling har dock förfinats av experter inom forskningsmetodik, statistiker och organisationsforskare under det senaste århundradet. Stadiet fick särskild betydelse under mitten av 1900-talet när forskare började betona skillnaden mellan datainsamling och dataanalys, och insåg att kvaliteten på den insamlade informationen direkt avgör giltigheten i forskningsslutsatser. Idag är informationsinsamlingsstadiet erkänt som en hörnsten i evidensbaserad praktik inom akademi, näringsliv, sjukvård och tekniksektorn. Enligt metodramverk kan cirka 78 % av forskningsmisslyckanden spåras till bristfälliga informationsinsamlingsrutiner, vilket understryker detta stadiums avgörande betydelse. Utvecklingen av digitala verktyg, databaser och automatiserade insamlingssystem har förändrat hur forskare närmar sig informationsinsamling, möjliggjort insamling i större skala men samtidigt introducerat nya utmaningar kring datakvalitet, hantering av bias och etiska överväganden.
| Metodkategori | Primärt tillvägagångssätt | Datatyp | Urvalsstorlek | Tidsåtgång | Kostnad | Bäst för |
|---|---|---|---|---|---|---|
| Strukturerade intervjuer | Förutbestämda frågor | Kvalitativ | Liten till medel | Hög | Medel–hög | Jämförbarhet och konsistens |
| Enkäter & frågeformulär | Slutna svar | Kvantitativ | Stor | Låg–medel | Låg | Breda mönster och trender |
| Fokusgrupper | Gruppdiskussion | Kvalitativ | Liten (6–10) | Medel | Medel | Utforska attityder och åsikter |
| Observationer | Direkt övervakning | Kvalitativ | Varierande | Hög | Låg–medel | Analys av verkligt beteende |
| Dokumentanalys | Befintliga register | Kvalitativ/kvantitativ | Varierande | Medel | Låg | Historisk kontext och trender |
| Experiment | Kontrollerade förhållanden | Kvantitativ | Medel | Hög | Hög | Kausala samband |
| Online-/webbdata | Digitala plattformar | Kvantitativ | Mycket stor | Låg | Låg | Datainsamling i stor skala |
| Biometriska mätningar | Fysiologiska data | Kvantitativ | Medel | Medel | Hög | Objektiva fysiska reaktioner |
Informationsinsamlingsstadiet sker genom en strukturerad, flerstegsprocess som inleds med att fastställa tydliga mål och definiera omfattningen av datainsamlingen. Forskare måste först identifiera vilken information som behövs, varför den behövs och hur den ska användas för att besvara forskningsfrågor. Detta grundläggande steg innebär att dokumentera specifika mål, leveranser och uppgifter samt att sätta gränser som identifierar resurser och underlättar projektplanering. När målen är fastställda väljer forskarna lämpliga datainsamlingsmetoder baserat på forskningsdesign, tillgängliga resurser och frågeställningens karaktär. Valet kräver noggrann övervägning av om kvalitativa metoder (intervjuer, observationer, fokusgrupper) eller kvantitativa metoder (enkäter, experiment, biometriska mätningar) är mest lämpliga, eller om en blandad metod skulle ge optimala insikter. Implementeringen av valda metoder kräver utbildning av datainsamlare, upprättande av standardiserade procedurer och införande av kvalitetskontrollpunkter för att minimera bias och fel. Under hela insamlingsprocessen måste forskare föra detaljerade register över datakällor, insamlingsdatum, använda metoder och eventuella avvikelser från planerade rutiner. Den sista delen innebär att organisera och förbereda den insamlade datan för analys genom kodning, kategorisering och valideringsprocedurer som säkerställer dataintegritet och analysberedskap.
I dagens affärsmiljö påverkar informationsinsamlingsstadiet direkt organisationsbeslut, strategisk planering och konkurrenskraftig positionering. Företag som tillämpar rigorösa informationsinsamlingsrutiner rapporterar betydligt bättre resultat inom marknadsundersökningar, kundnöjdhetsanalys och produktutveckling. Enligt branschstudier uppnår organisationer med strukturerade informationsinsamlingsprocesser 40 % snabbare insikter jämfört med de som använder ad hoc-metoder. Stadiet är särskilt avgörande inom marknadsundersökningar, där företag måste förstå kundpreferenser, konkurrenslandskap och nya trender för att fatta välgrundade strategiska beslut. Inom sjukvård och läkemedelsforskning avgör informationsinsamlingen behandlingars säkerhet och effektivitet, vilket gör kvalitetskontroll och systematiska insamlingsrutiner direkt livsavgörande. Finansiella institutioner är beroende av omfattande informationsinsamling för riskbedömning, bedrägeridetektion och regelefterlevnad. Den praktiska betydelsen sträcker sig till resursfördelning; bristfällig informationsinsamling kan leda till bortkastade investeringar, missade möjligheter och strategiska felsteg. Organisationer som investerar i rätt infrastruktur, utbildning och verktyg för informationsinsamling överträffar konsekvent konkurrenter vad gäller beslutsfattandets hastighet och noggrannhet. Stadiet påverkar även organisationskulturen, eftersom transparenta, datadrivna insamlingsprocesser bygger förtroende bland intressenter och stödjer evidensbaserat beslutsfattande på alla nivåer.
Inom ramen för AI-övervakningsplattformar som AmICited får informationsinsamlingsstadiet en särskild betydelse när organisationer följer upp hur deras varumärken, domäner och URL:er förekommer i AI-genererade svar över flera plattformar. ChatGPT, Perplexity, Google AI Overviews och Claude genererar alla svar på olika sätt, vilket kräver systematiska insamlingsmetoder anpassade till varje plattforms unika egenskaper. Informationsinsamlingsstadiet i AI-övervakning innebär att fastställa tydliga spårningsmål, till exempel att övervaka varumärkesomnämnanden, konkurrensläge eller faktakorrekthet i AI-svar. Forskare måste välja lämpliga övervakningsmetoder, vilket kan innefatta automatiserade spårningssystem, periodiska manuella granskningar eller hybridmetoder. Kvalitetskontroll blir särskilt viktigt i AI-övervakning eftersom AI-system kan generera inkonsekvent eller hallucinerad information, vilket kräver valideringsrutiner för att skilja mellan korrekta omnämnanden och falska positiva. Stadiet innebär också att organisera data från flera AI-källor i sammanhängande datamängder som visar mönster i hur olika plattformar representerar varumärken eller information. Denna specialanpassade informationsinsamling visar hur traditionella forskningsmetoder anpassas till ny teknik och nya informationsmiljöer.
En framgångsrik implementering av informationsinsamlingsstadiet kräver att etablerad bästa praxis, validerad inom forskningsdiscipliner och organisationssammanhang, följs. För det första bör forskare fastställa tydliga, mätbara mål som direkt kopplas till forskningsfrågorna, så att varje insamlingsaktivitet tjänar ett definierat syfte. För det andra, välj metoder som är lämpliga för forskningskontexten, med hänsyn till studiens omfattning, tillgängliga resurser, önskad giltighet och vilken typ av insikter som krävs. För det tredje, genomför rigorösa kvalitetskontrollprocedurer inklusive datavalideringskontroller, standardiserade insamlingsprotokoll och regelbundna granskningar för att minimera bias och fel. För det fjärde, för detaljerad dokumentation av alla insamlingsaktiviteter, inklusive datum, använda metoder, datakällor och eventuella avvikelser från planerade rutiner, vilket skapar ett revisionsspår som stärker forskningens trovärdighet. För det femte, involvera relevanta intressenter i planering och genomförande, så att informationsinsamlingen adresserar faktiska informationsbehov och får organisatoriskt stöd. För det sjätte, använd lämpliga verktyg och teknologier som matchar forskningens skala och komplexitet, från enkla kalkylblad för mindre studier till avancerade databasplattformar för stora projekt. För det sjunde, utbilda datainsamlare grundligt för att säkerställa konsekvens, minska bias och bibehålla kvalitetsstandarder genom hela processen. För det åttonde, upprätta datasäkerhets- och integritetsrutiner som skyddar känslig information och följer gällande regler som GDPR, CCPA och etiska prövningsnämnders krav. Denna samlade praxis säkerställer att insamlad information är korrekt, tillförlitlig, relevant och redo för meningsfull analys.
Informationsinsamlingsstadiet genomgår en betydande omvandling till följd av teknologiska framsteg, integrering av artificiell intelligens och förändrade organisationsbehov. Artificiell intelligens och maskininlärning automatiserar alltmer datainsamling och organisering, vilket gör att forskare kan samla in och bearbeta större datamängder mer effektivt än någonsin tidigare. Automatiserade datainsamlingssystem, verktyg för naturlig språkbehandling och intelligenta algoritmer för datavalidering minskar manuellt arbete, förbättrar konsekvensen och minskar mänsklig bias. Integreringen av realtidsövervakningssystem gör att organisationer kan samla in information kontinuerligt istället för i separata perioder, vilket ger mer dynamiska och responsiva insikter om förändrade förhållanden. Blockkedjeteknik och distribuerade liggare växer fram som verktyg för att säkerställa dataintegritet och transparens vid informationsinsamling, särskilt där datans ursprung och äkthet är avgörande. Framväxten av integritetsskyddande datainsamlingsmetoder, inklusive differentierad integritet och federerad inlärning, bemöter ökande krav på datasäkerhet och regelverk samtidigt som analytisk nytta bibehålls. Inom AI-övervakning och varumärkesbevakning utvecklas informationsinsamlingsstadiet för att möta utmaningar med generativa AI-system, inklusive hallucinationer, inkonsekventa utdata och snabbt föränderliga modellbeteenden. Organisationer utvecklar specialiserade insamlingsramverk för att spåra varumärkesomnämnanden över AI-plattformar, vilket kräver nya metoder anpassade till AI-specifika egenskaper. I framtiden kommer ökat fokus att läggas på etisk informationsinsamling, där organisationer inför mer avancerade metoder för att upptäcka och minska bias. Dessutom möjliggör integration av flera datakällor genom avancerad datafusion att forskare kan skapa mer omfattande, multidimensionella datamängder som ger djupare insikter än enskilda källor. Sammantaget pekar dessa trender mot att informationsinsamlingsstadiet blir allt mer sofistikerat, automatiserat och integrerat med avancerade analysmöjligheter, vilket fundamentalt förändrar hur organisationer samlar in och använder information för beslutsfattande.
Det primära syftet med informationsinsamlingsstadiet är att systematiskt samla in tillförlitlig, relevant data från olika källor som direkt besvarar forskningsfrågan. Detta stadium lägger grunden för all efterföljande analys och säkerställer att forskare har korrekt, högkvalitativ information för att stödja sina resultat och slutsatser. Enligt forskningsmetodiska ramar avgör effektiv informationsinsamling trovärdigheten och giltigheten för hela forskningsprojektet.
Informationsinsamling fokuserar på insamling och organisering av rådata från olika källor, medan dataanalys innebär att tolka och förstå den insamlade datan för att dra slutsatser. Informationsinsamling är inmatningsfasen där forskare samlar in fakta och observationer, medan analysen är bearbetningsfasen där mönster, trender och relationer identifieras. Båda stadierna är viktiga men tjänar olika syften i forskningsprocessen.
De huvudsakliga metoderna för datainsamling inkluderar kvalitativa tekniker (intervjuer, fokusgrupper, observationer, dokumentanalys) och kvantitativa metoder (enkäter, frågeformulär, experiment, biometriska mätningar). Forskare använder även blandade metoder som kombinerar både kvalitativa och kvantitativa tekniker. Valet av metod beror på forskningsmålen, tillgängliga resurser, studiens omfattning och vilken typ av insikter som behövs för den specifika forskningsfrågan.
Kvalitetskontroll under informationsinsamlingen säkerställer att insamlad data är korrekt, pålitlig och fri från partiskhet eller fel. Dålig datakvalitet kan leda till ogiltiga slutsatser och felaktiga beslut. Enligt Forrester Research förlorar över 25% av organisationer mer än 5 miljoner dollar årligen på grund av dålig datakvalitet. Att införa strikta kvalitetskontrollåtgärder, inklusive valideringskontroller och standardiserade insamlingsrutiner, skyddar integriteten i hela forskningsprojektet.
I AI-övervakningsplattformar som AmICited innebär informationsinsamlingsstadiet att systematiskt samla in data om hur varumärken och domäner förekommer i AI-genererade svar över plattformar som ChatGPT, Perplexity, Google AI Overviews och Claude. Detta stadium kräver att man fastställer tydliga övervakningsmål, väljer lämpliga spårningsmetoder och organiserar data från flera AI-källor för att ge omfattande insikter om varumärkesnärvaro.
Primära datakällor innebär insamling direkt från källan genom exempelvis enkäter, intervjuer eller experiment och ger data som är specifik för forskningsmålen. Sekundära datakällor är redan existerande information från publicerade rapporter, akademiska studier, myndighetsstatistik eller historiska register. Primärdata är vanligtvis mer relevant och aktuell men kräver mer resurser, medan sekundärdata är kostnadseffektivt men kanske inte är lika specifikt för forskningsbehoven.
Hur länge informationsinsamlingsstadiet pågår varierar kraftigt beroende på forskningens omfattning, tillgängliga resurser och metoder för datainsamling. Mindre kvalitativa studier kan ta veckor, medan storskalig kvantitativ forskning kan pågå i månader eller år. Enligt riktlinjer för forskningsmetodik kan god planering och tydliga mål minska insamlingstiden med 20–30% samtidigt som datakvalitet och giltighet bibehålls.
Vanliga utmaningar inkluderar urvalsbias, svarsbias i enkäter, svårighet att få tillgång till vissa datakällor, resursbegränsningar och att upprätthålla datakvalitet över flera insamlingsmetoder. Forskare stöter även på problem med dataorganisation, att säkerställa deltagarnas konfidentialitet och hantera stora informationsmängder. Att hantera dessa utmaningar kräver noggrann planering, lämpliga verktyg och genomförande av robusta kvalitetskontrollprocedurer genom hela insamlingsprocessen.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Forskningsinnehåll är evidensbaserat material skapat genom dataanalys och expertinsikter. Lär dig hur datadrivet analytiskt innehåll bygger auktoritet, påverkar...

Originalforskning och förstapartsdata är egenägda studier och kundinformation som samlats in direkt av varumärken. Lär dig hur de bygger auktoritet, driver AI-c...

Sekundärforskning analyserar befintliga data från flera källor för att besvara nya frågor. Lär dig hur organisationer använder skrivbordsforskning för kostnadse...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.