
Vad är Skyskrapetekniken för AI? Komplett Strategiguide
Lär dig hur skyskrapetekniken fungerar för AI-sökmotorer. Upptäck hur du skapar överlägset innehåll, får bakåtlänkar och förbättrar synlighet i AI-genererade sv...
13 min läsning

En scraperwebbplats är en webbplats som automatiskt kopierar innehåll från andra källor utan tillstånd och återpublicerar det, ofta med minimala ändringar. Dessa sajter använder automatiserade botar för att samla in data, text, bilder och annat innehåll från legitima webbplatser för att fylla sina egna sidor, vanligtvis i bedrägligt syfte, för plagiat eller för att generera annonsintäkter.
En scraperwebbplats är en webbplats som automatiskt kopierar innehåll från andra källor utan tillstånd och återpublicerar det, ofta med minimala ändringar. Dessa sajter använder automatiserade botar för att samla in data, text, bilder och annat innehåll från legitima webbplatser för att fylla sina egna sidor, vanligtvis i bedrägligt syfte, för plagiat eller för att generera annonsintäkter.
En scraperwebbplats är en webbplats som automatiskt kopierar innehåll från andra källor utan tillstånd och återpublicerar det, ofta med minimala ändringar eller omformuleringar. Dessa sajter använder automatiserade botar för att samla in data, text, bilder, produktbeskrivningar och annat innehåll från legitima webbplatser för att fylla sina egna sidor. Metoden är tekniskt sett olaglig enligt upphovsrättslagstiftningen och bryter mot de flesta webbplatsers användarvillkor. Innehållsskrapning skiljer sig fundamentalt från legitim web scraping eftersom det handlar om otillåten kopiering av publicerat innehåll i skadliga syften, inklusive bedrägeri, plagiat, annonsintäkter och stöld av immateriella rättigheter. Den automatiserade naturen av skrapning gör det möjligt för illasinnade aktörer att kopiera tusentals sidor på några minuter, vilket skapar enorma problem med duplicerat innehåll på internet.
Innehållsskrapning har funnits sedan internets tidiga dagar, men problemet har eskalerat dramatiskt med utvecklingen av automationsteknologi och artificiell intelligens. I början av 2000-talet var skrapare relativt enkla och lätta att upptäcka. Men moderna scraperbotar har blivit alltmer sofistikerade och använder tekniker som omformuleringsalgoritmer, roterande IP-adresser och webbläsarautomation för att undvika upptäckt. Uppkomsten av AI-drivet innehållsskapande har förvärrat problemet, då skrapare nu använder maskininlärning för att skriva om stulet innehåll på sätt som är svårare att identifiera som dubbletter. Enligt branschrapporter står scraperwebbplatser för en betydande del av skadlig bottrafik, och vissa uppskattningar säger att automatiserade botar utgör över 40 % av all internettrafik. Framväxten av AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews har skapat nya utmaningar, eftersom dessa system av misstag kan citera scraperwebbplatser istället för ursprungliga innehållsskapare och därmed förstärka problemet.
Scraperbotar arbetar genom en flerstegs, automatiserad process som kräver minimal mänsklig inblandning. Först genomsöker boten målsajter genom att följa länkar och besöka sidor, laddar ner HTML-kod och allt tillhörande innehåll. Boten tolkar sedan HTML:en för att extrahera relevant data som artikeltext, bilder, metadata och produktinformation. Detta extraherade innehåll lagras i en databas där det kan bearbetas vidare med omformuleringsverktyg eller AI-baserad omskrivningsmjukvara för att skapa varianter som ser annorlunda ut än originalet. Slutligen återpubliceras det skrapade innehållet på scraperwebbplatsen, ofta med minimal tillskrivning eller med falska upphovsmansanspråk. Vissa avancerade skrapare använder roterande proxies och user-agent-förfalskning för att maskera sina förfrågningar som legitim mänsklig trafik, vilket gör dem svårare att upptäcka och blockera. Hela processen kan vara helt automatiserad, vilket gör det möjligt för en enda skrapningsoperation att kopiera tusentals sidor dagligen från flera webbplatser samtidigt.
| Aspekt | Scraperwebbplats | Original innehållssajt | Legitim dataaggregator |
|---|---|---|---|
| Innehållets ursprung | Kopierat utan tillstånd | Skapat ursprungligen | Kurerat med tillskrivning och länkar |
| Juridisk status | Olaglig (upphovsrättsbrott) | Skyddad av upphovsrätt | Laglig (med korrekt licensiering) |
| Tillskrivning | Minimal eller falsk | Originalförfattare anges | Källor anges och länkas |
| Syfte | Bedrägeri, plagiat, annonsintäkter | Ge värde till publiken | Sammanställa och organisera information |
| SEO-påverkan | Negativ (duplicerat innehåll) | Positiv (originalinnehåll) | Neutral till positiv (med korrekt kanonisering) |
| Användarupplevelse | Dålig (lågkvalitativt innehåll) | Hög (unikt, värdefullt innehåll) | Bra (organiserat, kurerat innehåll) |
| Användarvillkor | Bryter mot användarvillkor | Följer egna användarvillkor | Respekterar webbplatsers villkor och robots.txt |
| Upptäcktsmetoder | IP-spårning, botsignaturer | Ej tillämpligt | Transparenta crawlmönster |
Scraperwebbplatser bygger på flera distinkta affärsmodeller, alla utformade för att generera intäkter från stulet innehåll. Den vanligaste modellen är annonsbaserad intäktsgenerering, där skrapare fyller sina sidor med annonser från nätverk som Google AdSense eller andra annonstjänster. Genom att återpublicera populärt innehåll lockar skrapare organisk söktrafik och genererar annonsvisningar och klick utan att skapa något eget värde. En annan vanlig modell är e-handelsbedrägeri, där skrapare skapar falska nätbutiker som efterliknar legitima återförsäljare och kopierar produktbeskrivningar, bilder och prisinformation. Ovetande kunder handlar från dessa bedrägliga sajter och får antingen förfalskade produkter eller får sin betalningsinformation stulen. E-postinsamling är ytterligare en betydande affärsmodell för skrapare, där kontaktuppgifter samlas in från webbplatser och säljs till spammare eller används för riktade phishing-kampanjer. Vissa skrapare ägnar sig också åt affiliate-marknadsföringsbedrägeri genom att kopiera produktrecensioner och innehåll och lägga in sina egna affiliatelänkar för att tjäna provision. De låga driftkostnaderna för skrapning—som endast kräver serverutrymme och automatiserad programvara—gör dessa affärsmodeller mycket lönsamma trots deras olagliga natur.
Konsekvenserna av innehållsskrapning för ursprungliga skapare är allvarliga och mångfacetterade. När skrapare återpublicerar ditt innehåll på sina domäner skapar de duplicerat innehåll som förvirrar sökmotorer om vilken version som är originalet. Googles algoritm kan ha svårt att identifiera den auktoritativa källan, vilket kan leda till att både originalet och de skrapade versionerna rankas lägre i sökresultaten. Detta påverkar direkt den organiska trafiken eftersom ditt noggrant optimerade innehåll tappar synlighet till scraperwebbplatser som inte bidragit med något eget. Utöver sökrankningar förvränger skrapare din webbplatsanalys genom att generera falsk trafik från botar, vilket gör det svårt att förstå verkligt användarbeteende och engagemangsdata. Dina serverresurser slösas också bort på att hantera förfrågningar från scraperbotar, vilket ökar bandbreddskostnader och potentiellt saktar ner din sajt för riktiga besökare. Den negativa SEO-påverkan sträcker sig till din domänauktoritet och länkprofil, eftersom skrapare kan skapa lågkvalitativa länkar till din sajt eller använda ditt innehåll i spamkontexter. När skrapare rankar högre än ditt originalinnehåll i sökresultaten tappar du även möjligheten att etablera dig som tankeledare och auktoritet i din bransch, vilket skadar ditt varumärkes rykte och trovärdighet.
Att identifiera scraperwebbplatser kräver en kombination av manuella och automatiserade metoder. Google Alerts är ett av de mest effektiva kostnadsfria verktygen och låter dig övervaka dina artikelrubriker, unika fraser och varumärkesnamn för otillåten återpublicering. När Google Alerts meddelar om en träff kan du undersöka om det är en legitim citering eller en scraperwebbplats. Pingback-övervakning är särskilt användbart för WordPress-sajter, eftersom pingbacks genereras när en annan sida länkar till ditt innehåll. Om du får pingbacks från okända eller misstänkta domäner kan det vara scraperwebbplatser som kopierat dina interna länkar. SEO-verktyg som Ahrefs, SEM Rush och Grammarly erbjuder funktioner för att hitta duplicerat innehåll och skannar webben efter sidor som matchar ditt innehåll. Dessa verktyg kan identifiera både exakta dubbletter och omformulerade versioner av dina artiklar. Serverloggsanalys ger teknisk insikt om bottrafik och avslöjar misstänkta IP-adresser, ovanliga förfrågningsfrekvenser och bot-user-agents. Omvänd bildsökning med Google Bilder eller TinEye kan hjälpa dig att hitta var dina bilder återpublicerats utan tillstånd. Regelbunden övervakning av din Google Search Console kan avslöja indexeringsavvikelser och problem med duplicerat innehåll som tyder på skrapningsaktivitet.
Innehållsskrapning bryter mot flera lager av lagligt skydd och är en av de mest åtkomliga formerna av nätbedrägeri. Upphovsrättslagen skyddar automatiskt allt originalinnehåll, både online och i tryck, och ger skapare exklusiva rättigheter att reproducera, distribuera och visa sitt verk. Att skrapa innehåll utan tillstånd är ett direkt upphovsrättsbrott och utsätter skrapare för civilrättsligt ansvar inklusive skadestånd och förelägganden. Digital Millennium Copyright Act (DMCA) ger ytterligare skydd genom att förbjuda kringgående av tekniska åtgärder som kontrollerar åtkomst till upphovsrättsskyddade verk. Om du inför åtkomstkontroller eller anti-scraping-åtgärder gör DMCA det olagligt att kringgå dem. Computer Fraud and Abuse Act (CFAA) kan också tillämpas på skrapning, särskilt när botar får tillgång till system utan tillstånd eller överskrider auktoriserad åtkomst. Webbplatsers användarvillkor förbjuder uttryckligen skrapning, och att bryta mot dessa villkor kan leda till rättsliga åtgärder för avtalsbrott. Många innehållsskapare har framgångsrikt vidtagit rättsliga åtgärder mot skrapare och fått domstolsbeslut om att ta bort innehåll och upphöra med skrapningsaktiviteter. Vissa jurisdiktioner har också erkänt skrapning som en form av illojal konkurrens, vilket ger företag rätt att stämma för skadestånd på grund av förlorade intäkter och marknadsskada.
Framväxten av AI-sökmotorer och stora språkmodeller (LLM) har skapat en ny dimension av scraperwebbplatsproblemet. När AI-system som ChatGPT, Perplexity, Google AI Overviews och Claude genomsöker webben för att samla träningsdata eller generera svar kan de stöta på scraperwebbplatser parallellt med originalinnehåll. Om scraperwebbplatsen förekommer oftare eller har bättre teknisk SEO kan AI-systemet citera skraparen istället för originalkällan. Detta är särskilt problematiskt eftersom AI-citeringar har stor betydelse för varumärkessynlighet och auktoritet. När en scraperwebbplats citeras i ett AI-svar istället för ditt originalinnehåll förlorar du möjligheten att etablera ditt varumärke som auktoritativ källa i AI-drivna sökresultat. Dessutom kan skrapare införa felaktigheter eller föråldrad information i AI-träningsdata, vilket kan leda till att AI-system genererar felaktiga eller missvisande svar. Problemet förvärras av att många AI-system inte ger transparent källtillskrivning, vilket gör det svårt för användare att verifiera om de läser originalinnehåll eller skrapat material. Övervakningsverktyg som AmICited hjälper innehållsskapare att spåra var deras varumärke och innehåll syns på AI-plattformar och identifiera när skrapare konkurrerar om synlighet i AI-svar.
Att skydda ditt innehåll från skrapning kräver ett flerskiktat tekniskt och operativt tillvägagångssätt. Botdetekterings- och blockeringsverktyg som ClickCease’s Bot Zapping kan identifiera och blockera skadliga botar innan de får tillgång till ditt innehåll och styra dem till felsidor istället för riktiga sidor. Robots.txt-konfiguration gör att du kan begränsa botars åtkomst till specifika kataloger eller sidor, även om envisa skrapare kan ignorera dessa direktiv. Noindex-taggar kan användas på känsliga sidor eller automatiskt genererat innehåll (som WordPress tagg- och kategorisidor) för att förhindra att de indexeras och skrapas. Content gating kräver att användare fyller i formulär eller loggar in för att få tillgång till premiuminnehåll, vilket gör det svårare för botar att samla information i stor skala. Begränsning av förfrågningsfrekvens på din server begränsar antalet förfrågningar från en enskild IP-adress under en viss tidsperiod, vilket saktar ner scraperbotar och gör deras verksamhet mindre effektiv. CAPTCHA-utmaningar kan verifiera att förfrågningar kommer från människor snarare än botar, även om avancerade botar ibland kan kringgå dessa. Serverövervakning av förfrågningsmönster hjälper till att identifiera misstänkt aktivitet så att du proaktivt kan blockera problematiska IP-adresser. Regelbundna säkerhetskopior av ditt innehåll säkerställer att du har bevis på ursprungliga skapandedatum, vilket är värdefullt om du behöver vidta rättsliga åtgärder mot skrapare.
Scraperlandskapet fortsätter att utvecklas i takt med teknologiska framsteg och nya möjligheter. AI-driven omformulering blir alltmer sofistikerad, vilket gör skrapat innehåll svårare att upptäcka som dubbletter med traditionella plagiatverktyg. Skrapare investerar i mer avancerad proxyrotation och webbläsarautomation för att undvika botdetektering. Framväxten av AI-träningsdataskrapning är en ny front där skrapare riktar sig mot innehåll specifikt för att träna maskininlärningsmodeller, ofta utan kompensation till ursprungliga skapare. Vissa skrapare använder nu headless browsers och JavaScript-rendering för att få tillgång till dynamiskt innehåll som traditionella skrapare inte kunde nå. Kombinationen av skrapning med affiliate-nätverk och annonsbedrägerier skapar mer komplexa och svårupptäckta skraparverksamheter. Det finns dock också positiva utvecklingar: AI-baserade detektionssystem blir bättre på att känna igen skrapat innehåll och sökmotorer straffar i allt högre grad scraperwebbplatser i sina algoritmer. Googles core update i november 2024 riktade sig särskilt mot scraperwebbplatser, vilket resulterade i stora synlighetsförluster för många scraperdomäner. Innehållsskapare använder också watermarking-teknik och blockkedjebaserad verifiering för att bevisa originalitet och äganderätt. När AI-sökmotorer mognar inför de bättre källtillskrivning och transparens för att säkerställa att originalskapare får rätt kredit och synlighet.
För innehållsskapare och varumärkesansvariga sträcker sig utmaningen med scraperwebbplatser bortom traditionella sökmotorer till det framväxande landskapet av AI-drivna sök- och svarssystem. AmICited erbjuder specialiserad övervakning för att spåra var ditt varumärke, innehåll och domän syns på AI-plattformar inklusive Perplexity, ChatGPT, Google AI Overviews och Claude. Genom att övervaka din AI-synlighet kan du identifiera när scraperwebbplatser konkurrerar om citeringar i AI-svar, när ditt originalinnehåll tillskrivs korrekt och när otillåtna kopior vinner mark. Denna information gör att du kan vidta proaktiva åtgärder för att skydda din immateriella egendom och behålla din varumärkesauktoritet i AI-drivna sökresultat. Att förstå skillnaden mellan legitim innehållsaggregering och skadlig skrapning är avgörande i AI-eran, då insatsen för varumärkessynlighet och auktoritet aldrig varit högre.
Ja, innehållsskrapning är tekniskt sett olagligt i de flesta jurisdiktioner. Det bryter mot upphovsrättslagar som skyddar digitalt innehåll på samma sätt som fysiska publikationer. Dessutom bryter skrapning ofta mot webbplatsers användarvillkor och kan utlösa rättsliga åtgärder enligt Digital Millennium Copyright Act (DMCA) och Computer Fraud and Abuse Act (CFAA). Webbplatsägare kan driva civilrättsliga och straffrättsliga åtgärder mot skrapare.
Scraperwebbplatser påverkar SEO negativt på flera sätt. När duplicerat innehåll från skrapare rankas högre än originalet minskar den ursprungliga webbplatsens synlighet och organiska trafik. Googles algoritm har svårt att avgöra vilken version som är originalet, vilket kan leda till att alla versioner rankas lägre. Dessutom slösar skrapare bort din webbplats crawlbudget och kan förvränga din analys, vilket gör det svårt att förstå verkligt användarbeteende och prestationsmått.
Scraperwebbplatser tjänar flera skadliga syften: skapa falska e-handelssajter för att begå bedrägeri, vara värd för förfalskade webbplatser som efterliknar legitima varumärken, generera annonsintäkter genom bedräglig trafik, plagiera innehåll för att fylla sidor utan ansträngning och samla in e-postlistor och kontaktuppgifter för spamkampanjer. Vissa skrapare riktar också in sig på prisinformation, produktdetaljer och innehåll från sociala medier för konkurrensanalys eller vidareförsäljning.
Du kan upptäcka skrapat innehåll med flera metoder: ställ in Google Alerts för dina artikelrubriker eller unika fraser, sök dina innehållsrubriker på Google för att se om dubbletter dyker upp, kontrollera pingbacks på interna länkar (särskilt i WordPress), använd SEO-verktyg som Ahrefs eller SEM Rush för att hitta duplicerat innehåll och övervaka din webbplats trafikmönster för ovanlig botaktivitet. Regelbunden övervakning hjälper dig att snabbt identifiera skrapare.
Web scraping är en bredare teknisk term för att extrahera data från webbplatser, vilket kan vara legitimt när det görs med tillstånd för forskning eller dataanalys. Content scraping syftar specifikt på otillåten kopiering av publicerat innehåll som artiklar, produktbeskrivningar och bilder för återpublicering. Medan web scraping kan vara lagligt är content scraping i sig skadligt och olagligt eftersom det bryter mot upphovsrätt och användarvillkor.
Scraperbotar använder automatiserad programvara för att genomsöka webbplatser, ladda ner HTML-innehåll, extrahera text och bilder samt lagra dem i databaser. Dessa botar simulerar mänskligt surfbeteende för att kringgå grundläggande detektionsmetoder. De kan komma åt både publikt synligt innehåll och ibland dolda databaser om säkerheten är svag. Den insamlade datan bearbetas sedan, ibland omformuleras med AI-verktyg och återpubliceras på scraperwebbplatser med minimala ändringar för att undvika exakt duplicerat innehåll.
Effektiva förebyggande strategier inkluderar att implementera botdetekterings- och blockeringsverktyg, använda robots.txt för att begränsa botars åtkomst, lägga till noindex-taggar på känsliga sidor, skydda premiuminnehåll bakom inloggningsformulär, övervaka din webbplats regelbundet med Google Alerts och SEO-verktyg, använda CAPTCHA-utmaningar, införa begränsningar av antalet förfrågningar på din server och övervaka dina serverloggar för misstänkta IP-adresser och trafikmönster. Ett flerskiktat tillvägagångssätt är mest effektivt.
Scraperwebbplatser utgör en betydande utmaning för AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. När AI-system genomsöker webben för träningsdata eller för att generera svar kan de stöta på skrapat innehåll och citera scraperwebbplatser istället för originalkällor. Detta minskar synligheten för legitima innehållsskapare i AI-svar och kan orsaka att AI-system sprider felaktig information. Övervakningsverktyg som AmICited hjälper dig att spåra var ditt varumärke och innehåll visas på AI-plattformar.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig hur skyskrapetekniken fungerar för AI-sökmotorer. Upptäck hur du skapar överlägset innehåll, får bakåtlänkar och förbättrar synlighet i AI-genererade sv...

Upptäck de avgörande skillnaderna mellan AI-träningscrawlare och sökmotorcrawlare. Lär dig hur de påverkar din innehållssynlighet, dina optimeringsstrategier oc...
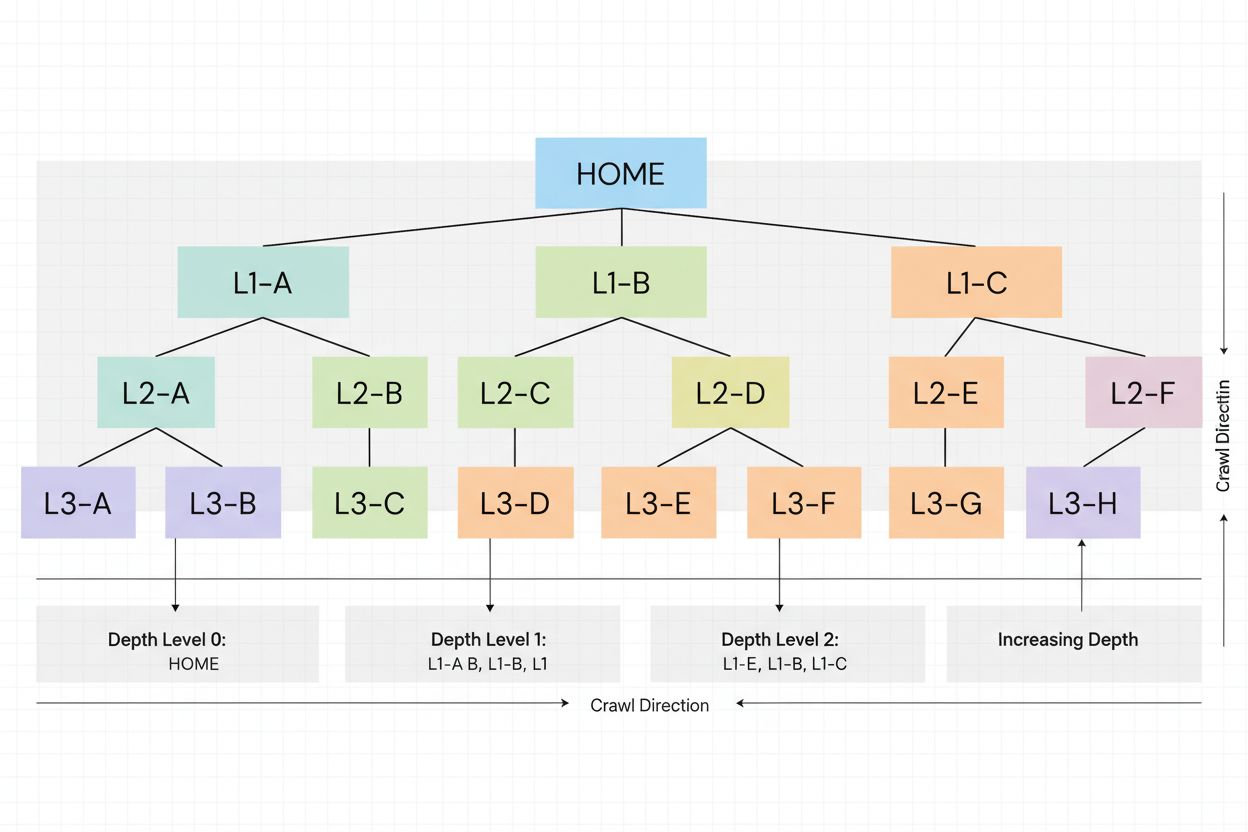
Crawl-djup är hur djupt sökmotorernas botar navigerar din webbplatsstruktur. Lär dig varför det är viktigt för SEO, hur det påverkar indexering och strategier f...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.