Samspråkighet
Samspråkighet är när relaterade termer förekommer tillsammans i innehåll och signalerar semantisk relevans till sökmotorer och AI-system. Lär dig hur detta begr...
10 min läsning

Sammansättning av källpool avser den specifika blandningen av webbplatser, innehållstyper och informationskällor som ett AI-system beaktar när det genererar svar på en användarfråga. Denna sammansättning avgör direkt vilka webbplatser som får synlighet i AI-genererade svar och är förutsättningen för all citering eller synlighet i AI-system. Sammansättningen varierar beroende på fråga, ämne och AI-plattform, vilket innebär att en webbplats kan inkluderas i källpoolen för en fråga men uteslutas för en annan baserat på relevans, auktoritet och innehållskvalitet. Att förstå sammansättningen av källpoolen är avgörande för innehållsskapare och marknadsförare som vill synas i AI-drivna sökningar.
Sammansättning av källpool avser den specifika blandningen av webbplatser, innehållstyper och informationskällor som ett AI-system beaktar när det genererar svar på en användarfråga. Denna sammansättning avgör direkt vilka webbplatser som får synlighet i AI-genererade svar och är förutsättningen för all citering eller synlighet i AI-system. Sammansättningen varierar beroende på fråga, ämne och AI-plattform, vilket innebär att en webbplats kan inkluderas i källpoolen för en fråga men uteslutas för en annan baserat på relevans, auktoritet och innehållskvalitet. Att förstå sammansättningen av källpoolen är avgörande för innehållsskapare och marknadsförare som vill synas i AI-drivna sökningar.
Sammansättning av källpool avser den specifika blandningen av webbplatser, innehållstyper och informationskällor som ett AI-system beaktar när det genererar svar på en användarfråga. Denna sammansättning avgör direkt vilka webbplatser som får synlighet i AI-genererade svar och skiljer sig därmed fundamentalt från traditionell sökmotorrankning. Att förstå källpoolsammansättning är avgörande för innehållsskapare och marknadsförare eftersom inkludering i ett AI-systems källpool är förutsättningen för all citering eller synlighet – en webbplats kan inte citeras om den aldrig ens beaktats. Sammansättningen varierar beroende på fråga, ämne och AI-system, vilket innebär att en webbplats kan ingå i källpoolen för en fråga men uteslutas för en annan baserat på relevans, auktoritet och innehållskvalitet.

AI-system bygger källpooler genom en flerstegsprocess som kombinerar flera avancerade mekanismer för att identifiera och utvärdera potentiella källor. Den primära metoden är Retrieval-Augmented Generation (RAG), som hämtar relevanta dokument från indexerat innehåll innan svar genereras, vilket säkerställer att svaren grundas på faktiska källor istället för enbart träningsdata. Denna process samverkar med två andra viktiga mekanismer:
| Aspekt | Traditionella sökmotorer | AI-källval |
|---|---|---|
| Primär signal | Backlinks och nyckelordsrelevans | Auktoritet, relevans, extraherbarhet och mångfald |
| Källutvärdering | Sidnivårankning | Dokumentnivå-relevanspoäng |
| Mångfaldshantering | Begränsad algoritmisk mångfald | Aktiv deduplicering och ämnesklustring |
| Innehållsformat | Alla format vägs lika | Strukturerad data och tydlighet vägs tungt |
| Uppdateringar i realtid | Kontinuerlig crawlning | Periodiska indexuppdateringar med färskhetssignaler |
Flera faktorer samverkar för att avgöra om en källa hamnar i ett AI-systems källpool för en viss fråga, där varje faktor har olika vikt beroende på frågetyp och kontext. Auktoritet är fortsatt den starkaste förutsägaren för inkludering, och forskning visar att 76 % av AI Overview-citeringar kommer från de tio översta organiska sökresultaten, vilket indikerar att etablerad domänauktoritet avsevärt ökar sannolikheten att komma med i källpoolen. Färskhet är avgörande vid tidskänsliga frågor – AI-system filtrerar aktivt på nyligen uppdaterat innehåll när de besvarar frågor om aktuella händelser, produktlanseringar eller föränderliga situationer. Relevans verkar på flera nivåer: ämnesrelevans (täcker källan ämnet), frågerelevans (besvarar den den specifika frågan), och entitetsrelevans (diskuterar den specifika personer, organisationer eller koncept som nämns). Mångfald säkerställer att källpoolen innehåller olika perspektiv och innehållstyper istället för att klustra kring en enda dominerande källa. Ämnesinriktning mäter om en källas övergripande innehållsfokus matchar frågans domän, där AI-system föredrar källor som visar på långvarig expertis inom relevanta områden.
| Urvalsfaktor | Påverkan på inkludering | Varför det är viktigt |
|---|---|---|
| Domänauktoritet | Mycket hög (40–50 % vikt) | Signaliserar trovärdighet och expertis; korrelerar med innehållskvalitet |
| Innehållsfärskhet | Hög (20–30 % vikt) | Säkerställer att svaren speglar aktuell information; kritiskt för tidskänsliga frågor |
| Ämnesrelevans | Hög (20–30 % vikt) | Säkerställer att källans expertis matchar frågans område |
| Innehållstydlighet | Medelhög (15–25 % vikt) | Förbättrar extraherbarhet och minskar fel i AI-svar |
| Mångfaldssignaler | Medel (10–20 % vikt) | Förhindrar överberoende av enskilda källor; förbättrar svarens heltäckning |
Källmångfald i AI-genererade svar fyller en viktig funktion: att förhindra upprepningar och samtidigt säkerställa att frågans ämne täcks in heltäckande. AI-system använder ämnesklustringsalgoritmer som grupperar liknande källor och sedan väljer representativa källor från varje kluster, vilket undviker att flera nästan identiska källor dominerar svaret. Dedupliceringsmekanismer identifierar källor med betydande överlappande innehåll och inkluderar endast den mest auktoritativa versionen, så att samma information inte citeras flera gånger under olika URL:er. De mångfaldstekniker som används omfattar:
Detta tillvägagångssätt förhindrar problemet med “citeringsklustring”, där AI-system annars skulle citera samma få auktoritativa källor upprepade gånger, och leder istället till mer balanserade och heltäckande svar.
Domänauktoritet och förtroendesignaler utgör grunden för inkludering i källpoolen, där AI-system använder flera indikatorer för att avgöra om en källa förtjänar att beaktas. Backlinkprofiler är fortfarande viktiga, men AI-system utvärderar länkarnas kvalitet snarare än kvantitet – länkar från auktoritativa, ämnesrelevanta källor väger betydligt tyngre än många lågkvalitativa länkar. Varumärkesomnämnanden har blivit minst lika viktiga som backlinks, och forskning visar att AI-system spårar omnämnanden av varumärken och organisationer på webben som förtroendesignaler, vilket innebär att positiva omnämnanden i välrenommerade publikationer avsevärt ökar chansen att inkluderas i källpoolen. Entitetskonsistens mäter om information om en entitet (person, organisation, produkt) är konsekvent över olika källor, där AI-system använder denna konsistens som en proxy för korrekthet. Ytterligare förtroendesignaler inkluderar:
Forskning visar att källor med starka förtroendesignaler får 3–4 gånger högre citeringsgrad i AI-genererade svar jämfört med källor med svaga förtroendesignaler, även när innehållskvaliteten är likvärdig.
Innehållskvalitet och extraherbarhet – hur lätt AI-system kan tolka och förstå innehållet – påverkar starkt källpoolsammansättningen, där dåligt strukturerat innehåll ofta utesluts trots hög auktoritet. Strukturerad datamärkning med Schema.org-vokabulär hjälper AI-system förstå innehållets kontext, relationer och nyckelinformation, vilket avsevärt förbättrar chansen till inkludering och korrekt citering. Innehållstydlighet är viktigt eftersom AI-system måste kunna identifiera specifika påståenden, fakta och argument i innehållet; tätt, oorganiserat innehåll är svårare att extrahera ur och därför mindre sannolikt att inkluderas. Förekomsten av tydliga rubriker, logisk styckeindelning och explicita ämnessatser förbättrar extraherbarheten. Ett enkelt exempel på fördelaktig strukturerad data:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Understanding AI Source Pool Composition",
"author": {"@type": "Person", "name": "Expert Author"},
"datePublished": "2024-01-15",
"articleBody": "Source pool composition refers to..."
}
Innehåll med korrekt Schema.org-markering har 2–3 gånger högre chans att inkluderas i AI-källpooler jämfört med identiskt innehåll utan sådan märkning, vilket gör teknisk SEO-implementering avgörande för AI-synlighet.
Den verkliga effekten av källpoolsammansättning på webbplatssynlighet går långt utöver traditionella sökmetrik och förändrar fundamentalt hur målgrupper upptäcker och interagerar med innehåll. Citeringsgrad i AI-genererade svar korrelerar direkt med trafik och varumärkessynlighet, där citerade källor får mätbara trafikökningar och ökad varumärkeskännedom – forskning visar att källor som citeras i AI Overviews får en ökning på 15–25 % i varumärkessökningar. Zero-click-sökbeteende har flyttats till AI-genererade svar, vilket innebär att inkludering i källpoolen nu avgör synligheten i situationer där användare aldrig klickar på traditionella sökresultat. Varumärkessynlighet och auktoritetsbyggande sker genom AI-citeringar även när användare inte klickar vidare, eftersom upprepade omnämnanden i AI-svar bygger varumärkeskännedom och auktoritetssignaler. Till exempel får ett finansbolag som citeras i AI-svar om pensionsplanering varumärkesexponering till tusentals användare dagligen, även om bara en liten del klickar vidare till webbplatsen. Källpoolsammansättningen påverkar också konkurrenspositionen, eftersom webbplatser som ingår i källpooler för högvolymfrågor får betydande synlighetsfördelar jämfört med konkurrenter som saknas där.
För att nå och behålla inkludering i AI-källpooler krävs en strategisk kombination av innehållskvalitet, teknisk implementation och auktoritetsbyggande. Organisationer bör använda följande optimeringsstrategier:
Verktyg som AmICited.com gör det möjligt för organisationer att spåra vilka källor som ingår i AI-källpooler för deras målinriktade frågor, vilket ger insyn i konkurrensposition och inkluderingsmönster.
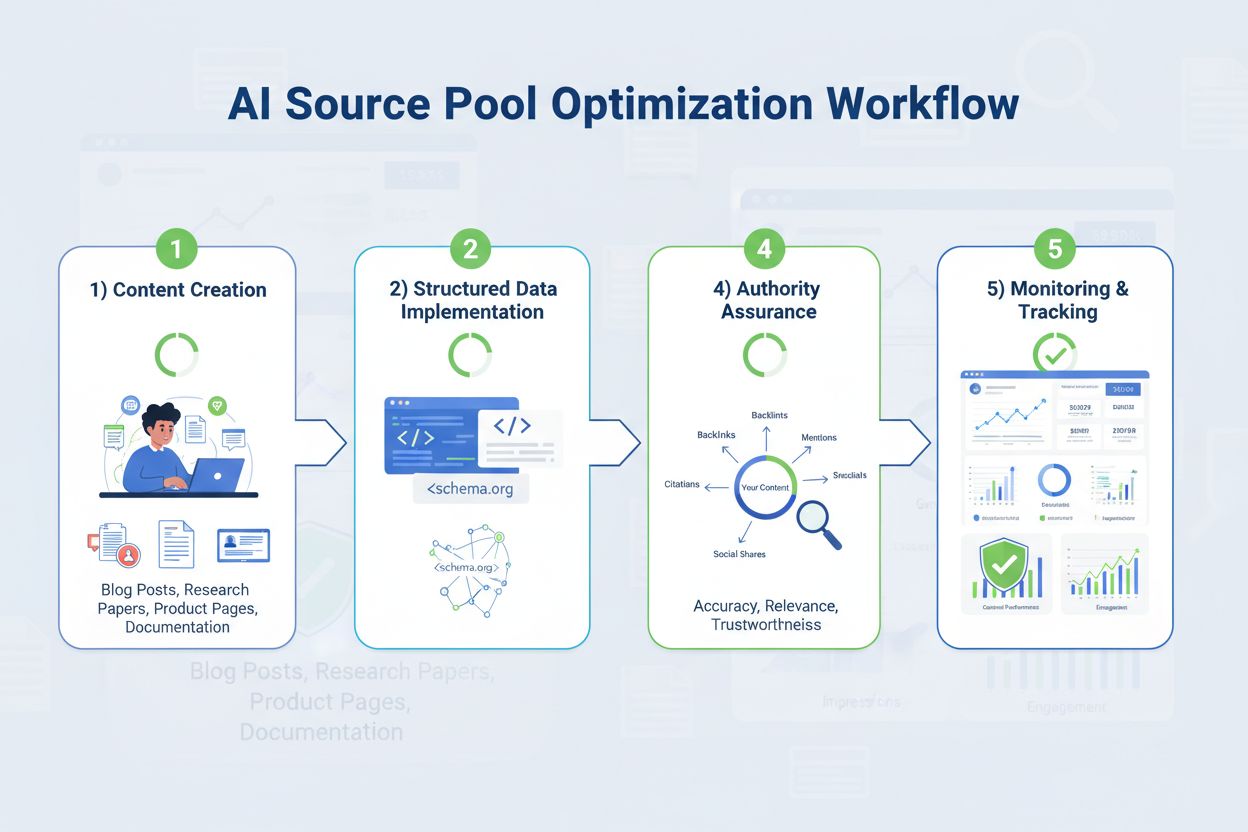
Att mäta källpoolinkludering och övervaka förändringar över tid kräver systematisk uppföljning av flera metrik och indikatorer. Organisationer bör följa upp:
AmICited.com erbjuder dedikerad övervakning för att spåra källpoolsammansättning, citeringsmönster och konkurrensposition över flera AI-system, vilket möjliggör datadriven optimering av innehållsstrategin för AI-synlighet. Genom att etablera baslinjemetodik för nuvarande källpoolsinkludering och följa upp förändringar kvartalsvis kan organisationer mäta effekten av optimeringsinsatser och justera strategin utifrån resultat. Denna mätning förvandlar källpoolsammansättning från ett abstrakt begrepp till en konkret, mätbar del av den övergripande digitala synlighetsstrategin.
Traditionella sökmotorer rankar enskilda sidor baserat på auktoritets- och relevanssignaler och visar dem i en linjär lista. AI-system bygger däremot först en källpool av potentiellt relevanta källor, och väljer sedan ut särskilda källor ur den poolen att citera i genererade svar. En webbplats kan ranka högt i traditionell sökning men ändå uteslutas från ett AI-systems källpool om den saknar den auktoritet, tydlighet eller ämnesinriktning som AI-systemen kräver. Sammansättningen av källpoolen är därför det förberedande steget som avgör om en webbplats ens kan bli aktuell för citering.
Källpoolsammansättningen avgör direkt din synlighet i AI-genererade svar. Om din webbplats inte ingår i källpoolen för en fråga kan den inte citeras oavsett innehållskvalitet. Inkludering i källpooler ökar dina chanser att bli citerad, vilket driver varumärkessynlighet, kännedom och trafik. Forskning visar att källor som citeras i AI Overviews får en ökning på 15–25 % i varumärkessökningar, vilket gör inkludering i källpooler till en avgörande del av AI-synlighetsstrategin.
Ja, mindre webbplatser kan ingå i AI-källpooler om de uppvisar hög innehållskvalitet, tydlig struktur, korrekt schema-markering och ämnesexpertis. AI-system utvärderar innehåll på dokumentnivå snarare än bara på domännivå, vilket innebär att en enda högkvalitativ artikel från en mindre webbplats kan inkluderas i källpooler tillsammans med innehåll från stora publicister. Nyckeln är att skapa innehåll som är mer relevant, tydligare och bättre strukturerat än konkurrerande källor.
AI-system uppdaterar källpooler kontinuerligt när de hämtar nytt innehåll och utvärderar befintliga källor på nytt. Men frekvensen varierar mellan AI-plattform och frågetyp. Tidskänsliga frågor utlöser oftare uppdateringar av källpooler för att säkerställa aktuell information, medan tidlösa ämnen kan ha mer stabila källpooler. De flesta AI-system utvärderar källpooler för populära frågor minst en gång i veckan, men exakt uppdateringsfrekvens avslöjas sällan offentligt av AI-plattformarna.
Schema-markering förbättrar kraftigt möjligheten att bli inkluderad i källpoolen genom att hjälpa AI-system att förstå innehållets struktur, kontext och relationer. Innehåll med korrekt Schema.org-markering har 2–3 gånger högre chans att inkluderas i AI-källpooler jämfört med identiskt innehåll utan markering. Schema-markering hjälper AI-system att identifiera nyckelinformation, verifiera fakta och förstå syftet med innehållet, vilket gör det till en avgörande teknisk SEO-faktor för AI-synlighet.
Du kan övervaka inkludering i källpooler med verktyg som AmICited.com, som spårar hur ofta ditt innehåll syns i AI-genererade svar på flera plattformar inklusive ChatGPT, Google AI Overviews och Perplexity. Dessa verktyg visar citeringsfrekvens, vilka källor som inkluderas för särskilda frågor och hur din inkluderingsgrad står sig mot konkurrenterna. Regelbunden övervakning hjälper dig att förstå effekten av optimeringsinsatser och identifiera förbättringsmöjligheter.
Nej, inkludering i en källpool garanterar inte att ditt innehåll blir citerat i ett specifikt AI-genererat svar. Att finnas i källpoolen innebär att ditt innehåll beaktas som en potentiell källa, men AI-system tillämpar ytterligare filter och urvalskriterier för att avgöra vilka källor som faktiskt citeras. Faktorer som innehållets relevans för den specifika frågan, tydlighet i påståenden och krav på mångfald påverkar om en källa från poolen slutligen citeras.
Olika AI-plattformar bygger källpooler med olika algoritmer, träningsdata och utvärderingskriterier. ChatGPT, Google AI Overviews, Perplexity och andra AI-system kan inkludera olika källor i sina pooler för samma fråga. Det innebär att en webbplats kan ingå i en plattforms källpool men uteslutas från en annans. En framgångsrik AI-synlighetsstrategi kräver optimering för flera plattformar och övervakning av inkluderingsmönster över olika AI-system.
Spåra hur ditt varumärke syns i AI-källpooler på ChatGPT, Google AI Overviews, Perplexity och andra AI-plattformar. Få insikter i realtid om dina citeringsmönster och din konkurrensposition.
Samspråkighet är när relaterade termer förekommer tillsammans i innehåll och signalerar semantisk relevans till sökmotorer och AI-system. Lär dig hur detta begr...

Lär dig vad innehållsomfattning betyder för AI-system som ChatGPT, Perplexity och Google AI Overviews. Upptäck hur du skapar kompletta, självständiga svar som A...
Lär dig hur samförekomstmönster hjälper AI-sökmotorer att förstå semantiska relationer mellan termer, förbättra innehållsrankning och förbättra AI-genererade sv...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.