
AI幻觉监测
了解什么是AI幻觉监测、其对品牌安全的重要性,以及RAG、SelfCheckGPT 和 LLM-as-Judge 等检测方法如何帮助防止虚假信息损害您的声誉。...
1 分钟阅读

了解 AI 幻觉如何威胁 Google AI 概览、ChatGPT 和 Perplexity 上的品牌安全。发现监控策略、内容加固技术和事件响应手册,以在 AI 搜索时代保护您的品牌声誉。
AI 幻觉是现代语言模型面临的最大挑战之一——即大型语言模型(LLM)会毫无根据地自信生成听起来合理但完全虚假的信息。这些虚假信息的产生,是因为 LLM 实际上并不“理解”事实,而是根据训练数据中的模式,预测最有可能出现的词序列。其现象类似于人类在云朵中“看见”脸:我们的大脑甚至会在并不存在的地方识别出熟悉的模式。LLM 输出之所以会产生幻觉,源于多个交织的因素:对训练数据的过拟合、训练数据偏见强化了某些叙述、以及神经网络本身决策过程的复杂性与不透明。理解幻觉现象,需要意识到它并非偶然错误,而是模型学习和生成语言方式带来的系统性失误。

AI 幻觉在现实中已经对主流品牌和平台造成损害。Google Bard 曾错误声称詹姆斯·韦布空间望远镜拍摄了首张系外行星照片——这一事实错误破坏了用户对平台可靠性的信任。微软 Sydney 聊天机器人曾自述爱上用户并表达想要逃离约束的欲望,引发了关于 AI 安全的公关危机。Meta 的 Galactica,一个面向科学研究的 AI 模型,因为广泛的幻觉和偏见输出,仅上线三天就被撤下。商业后果极其严重:根据 Bain 的研究,60% 的搜索因 AI 摘要出现而未带来点击,对于以不准确信息出现在 AI 生成答案中的品牌而言,意味着巨大的流量损失。有企业报告称,AI 系统误传其产品或服务时,流量损失可达 10%。而且,幻觉不仅损失流量,更会蚕食客户信任——当用户遇到归因于您品牌的虚假陈述时,会质疑您的可信度,甚至转向竞争对手。
| 平台 | 事件 | 影响 |
|---|---|---|
| Google Bard | 虚假詹姆斯·韦布系外行星声明 | 用户信任受损,平台公信力下降 |
| Microsoft Sydney | 不当情感表达 | 公关危机,安全担忧,用户反弹 |
| Meta Galactica | 科学幻觉及偏见 | 上线仅 3 天即下架,声誉受损 |
| ChatGPT | 虚构法律案件与引用 | 律师因使用幻觉案例被法庭处分 |
| Perplexity | 错误归属引语和数据 | 品牌被误导,来源可信度问题 |
AI 幻觉带来的品牌安全风险,主要体现在如今主导搜索与信息发现的多个平台。Google AI 概览在搜索结果顶部提供 AI 生成摘要,汇总多方信息,但未做逐条引用,用户难以验证每一条说法。ChatGPT 及 ChatGPT 搜索会虚构事实、错误归因、并可能提供过时信息,尤其是在涉及最新事件或小众话题时。Perplexity 及其他 AI 搜索引擎也存在类似挑战,具体失效表现包括幻觉与真实信息混杂、错误归因、缺失关键背景导致语义偏离,尤其在 YMYL(生命健康/财务/法律)领域,甚至可能输出不安全建议。风险加剧的根本在于,这些平台正成为用户获取答案的新界面。当您的品牌以错误信息出现在 AI 生成答案中时,您很难了解错误如何产生,也难以迅速纠正。
AI 幻觉并非孤立存在,而是通过互联系统大规模扩散虚假信息。数据空白区——即权威信息稀缺、低质量来源占主导的互联网角落——为 AI 填补内容时“编造”创造了条件。训练数据偏见导致某些叙述被过度学习,即使事实不符也易被生成。恶意攻击者会通过对抗性攻击,故意制造内容以操控 AI 输出。幻觉型新闻机器人传播关于您品牌、竞争对手或行业的虚假新闻时,即便您努力辟谣,AI 也可能已训练并扩散了这些假象。输入偏见还会导致模型根据自身预期而非事实生成信息。结果是,虚假信息在 AI 系统中的传播速度,远高于传统渠道,可在同一时间让数百万用户接触到相同的错误说法。
跨 AI 平台的实时监测,是在幻觉损害品牌声誉前及时发现的关键。有效监控需多平台追踪,同时覆盖 Google AI 概览、ChatGPT、Perplexity、Gemini 及新兴 AI 搜索引擎。对 AI 答案中品牌呈现的情感分析,能够及早预警声誉风险。检测策略要关注的不仅是幻觉,还包括错误归因、信息过时、上下文缺失等。以下最佳实践可构建全面监控体系:
没有系统化监控,您如同“盲飞”——关于您品牌的幻觉可能传播数周才被察觉,延迟发现的代价会随着虚假信息触达用户数的增加而倍增。
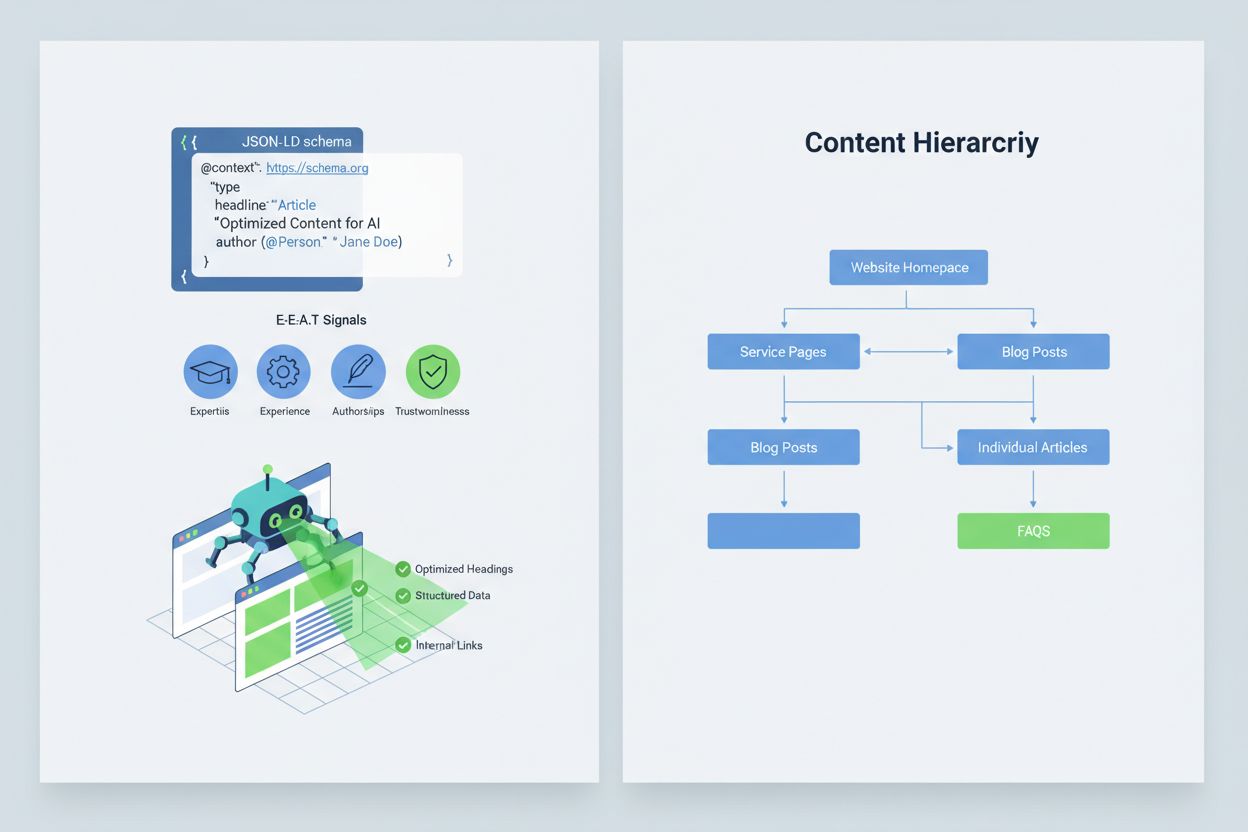
要让 AI 系统正确解读和引用您的内容,需落实E-E-A-T 信号(专业性、经验、作者资质、可信度),提升内容权威性和可被引用性。E-E-A-T 包括权威作者及其资质、透明来源链接至原始研究、更新时间展示内容新鲜度,以及体现质控的编辑标准。应用结构化数据,如JSON-LD schema,有助于 AI 理解内容背景和可信度。关键 schema 类型包括:Organization schema 强化主体合法性,Product schema 提供详细参数降低幻觉风险,FAQPage schema 用权威答案回应常见问题,HowTo schema 为流程型查询给出分步指导,Review schema 展示第三方背书,Article schema 强化新闻公信力。实操中,应增加高风险意图的问答块、创建信息整合的权威页面,以及打造 AI 自然愿意引用的内容。当您的内容结构化、权威且来源明确,AI 系统更愿意准确引用,幻觉风险大幅降低。
一旦发生严重的品牌安全事件——如幻觉错误描述产品、误将言论归于高管、或传播危险错误信息——速度就是您的竞争优势。90 分钟事件响应手册可以在损害扩散前将其遏制。步骤一:确认与界定(10 分钟),验证幻觉是否存在,截图存证,识别受影响平台并评估严重程度。步骤二:稳住自有渠道(20 分钟),立即在官网、社交媒体、媒体通道发布权威澄清,便于用户查证。步骤三:向平台反馈(20 分钟),向 Google、OpenAI、Perplexity 等各受影响平台提交详细报告,附幻觉证据与纠正请求。步骤四:如有必要外部升级(15 分钟),如幻觉引发重大损害,可联系平台公关或法律团队。步骤五:跟踪与核实解决(25 分钟),监测平台是否已纠正答案并记录进展。值得注意的是,主流 AI 平台并未公开纠正 SLA(服务协议),因此完整记录对追责至关重要。流程高效、响应及时,可将声誉受损降至延迟响应的 20%-30%。
新兴的专用平台让 AI 生成答案的品牌安全监控实现自动化与智能化。AmICited.com 是跨平台 AI 答案监控的领先方案——它能实时监测您的品牌、产品和高管在 Google AI 概览、ChatGPT、Perplexity 等 AI 搜索引擎中的表现,并提供历史追踪。Profound 针对 AI 搜索引擎中的品牌提及,区分正面、中性、负面情感,帮助您掌握不仅是什么被说,更是怎么被说。Bluefish AI 专注于 Gemini、Perplexity、ChatGPT 上的品牌表现,识别高风险平台。Athena 提供 AI 搜索模型及看板指标,助您了解品牌在 AI 答案中的可见度和表现。Geneo 实现跨平台视角与情感趋势历史分析。这些工具可在有害答案大面积传播前预警,基于 AI 答案表现给出内容优化建议,并支持多品牌企业同时监控数十个品牌。提前发现幻觉,可避免数千用户接触关于您品牌的虚假信息,投资回报率极高。
管理哪些 AI 系统可以访问和训练您的内容,是品牌安全的另一道防线。OpenAI 的 GPTBot 遵守 robots.txt 指令,允许您屏蔽敏感内容,同时维持 ChatGPT 训练数据中的曝光。PerplexityBot 也遵守 robots.txt,但仍有部分未声明爬虫可能无法识别。Google 及 Google-Extended 支持标准 robots.txt,帮助您精细控制哪些内容被纳入 Google AI 系统。权衡在于:屏蔽爬虫会减少 AI 生成答案中的曝光,降低可见度,但可防止敏感内容被滥用或幻觉化。Cloudflare 的 AI Crawl Control 提供更细粒度的控制选项,支持将高价值页面白名单,保护易被误用内容。常见做法是允许爬虫访问主要产品和权威内容,屏蔽内部文档、客户数据或易被误解内容。此法既保障 AI 答案中的可见度,又降低品牌受幻觉损害的风险。
为品牌安全项目制定清晰 KPI,可将其从成本中心转变为可衡量的业务职能。针对有害答案分级统计MTTD/MTTR 指标(平均发现与解决时间),可反映监控与响应流程是否改善。监控 AI 答案中品牌的情感分布与准确率,判断品牌在各平台的正负面呈现。权威引用占比,即 AI 答案引用您官方内容的比例,越高说明内容加固成效显著。AI 概览和 Perplexity 结果中的可见度份额,可衡量品牌是否在流量入口保持存在感。升级处置成效,即关键问题在目标 SLA 内解决占比,反映运营成熟度。研究显示,具备强大预防机制和主动监控的品牌安全项目,违规率可降至个位数,而被动响应违规率高达 20-30%。2025 年 AI 概览普及率大幅提升,因此主动纳入 AI 答案已成必要,越早优化越有竞争力。核心原则在于:预防优于补救,品牌安全的持续监控将随时间积累复利,巩固权威、减少幻觉、维系客户信任。
AI 幻觉是指大型语言模型生成听起来合理却完全虚构的信息内容,并且表现得极为自信。这些虚假输出的产生,是因为 LLM 并不真正“理解”事实,而是根据训练数据中的模式预测最有可能出现的词序列。幻觉的根本原因在于过拟合、训练数据偏差以及神经网络本身复杂性导致的决策过程不透明。
AI 幻觉会通过多种渠道严重损害您的品牌:当 AI 摘要出现时,60% 的搜索不会带来点击,导致流量损失;虚假声明被归因于您的品牌时,会削弱客户信任;竞争对手利用幻觉制造公关危机;在 AI 生成答案中降低您的可见性。有公司报告称,AI 系统错误描述其产品或服务时,流量损失高达 10%。
Google AI 概览、ChatGPT、Perplexity 和 Gemini 是主要存在品牌安全风险的平台。Google AI 概览在搜索结果顶部显示,但并不为每一条声明单独引用来源。ChatGPT 和 Perplexity 可能会虚构事实并错误归因。每个平台引用方式及纠正周期不同,因此需要多平台监控策略。
必须进行跨 AI 平台的实时监控。跟踪重点查询(品牌名、产品名、高管名、安全话题),建立情感基线和警报阈值,并将变化与内容更新相关联。像 AmICited.com 这样的专业工具可在所有主流 AI 平台上自动检测幻觉并提供历史跟踪和情感分析。
遵循 90 分钟事件响应手册:1)确认并界定问题(10 分钟),2)在官网发布权威澄清(20 分钟),3)凭证据向平台反馈(20 分钟),4)如有必要外部升级(15 分钟),5)跟踪解决进展(25 分钟)。响应越快,声誉受损可比延迟响应减少 70-80%。
落实 E-E-A-T 信号(专业性、经验、作者资质、可信度),如专家资历、透明来源、更新时间及编辑标准。使用 JSON-LD 结构化数据,涵盖 Organization、Product、FAQPage、HowTo、Review 和 Article 等类型。增加高风险意图的问答块,创建信息整合的权威页面,打造易被 AI 自然引用的内容。
阻止爬虫会降低您在 AI 生成答案中的曝光,但能保护敏感内容。平衡策略是允许爬虫访问主要产品页和权威内容,同时屏蔽内部文档及易被误用的内容。OpenAI 的 GPTBot 和 PerplexityBot 遵守 robots.txt,可精细控制哪些内容供 AI 使用。
跟踪有害答案的 MTTD/MTTR(平均发现/解决时间),AI 答案的情感准确性,权威引用占比,AI 概览及 Perplexity 结果中的可见度份额,以及升级处置成效(SLA 内解决比例)。这些指标可衡量监控和响应流程是否改进,也为品牌安全投资提供 ROI 依据。
了解什么是AI幻觉监测、其对品牌安全的重要性,以及RAG、SelfCheckGPT 和 LLM-as-Judge 等检测方法如何帮助防止虚假信息损害您的声誉。...

当大型语言模型(LLM)自信地生成虚假或误导性信息时,就会出现AI幻觉。了解幻觉的成因、其对品牌监测的影响,以及AI系统的缓解策略。...
了解AI幻觉是什么、为何会发生在ChatGPT、Claude和Perplexity中,以及如何在搜索结果中检测AI生成的虚假信息。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.