

你的图表和信息图被 AI 引用了吗?我们是如何优化视觉内容的
社区讨论数据可视化和视觉内容在 AI 搜索中的表现。关于优化图表、信息图和图片以提升 AI 可见性的策略。
2 分钟阅读
Discussion
Visual Content
+1
可视数据为现代大语言模型带来了根本性的瓶颈,这些模型主要以基于文本的信息训练,在处理、解释和引用图表时,无法达到处理文字内容时的同等精度。现有LLM在面对数据可视化时存在显著局限——它们需先将可视元素转为文本描述,而这一过程常常丢失原始图表中蕴含的重要细节、精确数值和上下文关系。LLM系统无法准确处理可视数据,意味着图表、图形和信息图常常未被引用或被错误引用,这让投入大量时间制作高质量可视化作品的内容创作者面临公信力缺失。对于依赖AI图表处理进行信息整合的研究者、分析师与机构而言,这一挑战尤为重要,因为归属不当既削弱了原作者的成果,也影响了AI生成摘要的可靠性。了解这些局限性,对于任何在AI驱动的信息环境中创作可视内容的人来说都至关重要。

不同AI系统在可视内容引用方面展现出不同程度的成熟度,反映了各自的底层架构和训练方法。下表展示了主流AI平台对可视内容引用的处理方式:
| AI模型 | 可视引用能力 | 引用格式 | 准确度 | 多模态支持 |
|---|---|---|---|---|
| ChatGPT (GPT-4V) | 中等 | 描述性文本 | 65-75% | 是(支持图片输入) |
| Claude 3 | 高 | 详细归属信息 | 80-85% | 是(支持视觉) |
| Perplexity AI | 高 | 来源+可视引用 | 85-90% | 是(集成网页) |
| Google AI Overviews | 中高 | 行内引用 | 75-80% | 是(图片搜索) |
| Gemini Pro Vision | 中等 | 上下文引用 | 70-78% | 是(多模态) |
Claude在可视内容归属方面表现优异,引用图表时常能提供详细的来源信息和可视上下文;而Perplexity AI擅长将可视引用与网页来源结合,形成更完整的归属链。ChatGPT的GPT-4V虽能处理图片,但面对复杂财经图表或科学可视化时,常默认为泛化描述而非精确引用。Google AI Overviews尝试为可视内容保留行内引用,但有时会混淆图表创作者与数据来源,导致归属模糊。对于内容创作者而言,这种差异意味着同一份可视化在不同AI系统中可能收到截然不同的处理——一张图表在Claude中被正确引用,却在ChatGPT中完全未被归属,凸显出在AI生态中亟需标准化可视引用协议。
数据可视化在塑造AI模型如何理解和表达信息方面,起着出乎意料的重要作用。嵌入训练数据集中的图表和图形,教会模型识别复杂数据中的模式、关系和层级。训练集中可视数据的质量和多样性,直接决定了AI系统后续对类似可视化的解读和引用能力——在全面可视数据集上训练的模型,在可视内容归属上表现显著优于仅基于文本训练的模型。训练中习得的可视模式会以细微但可测量的方式影响模型输出——比如,经过大量标注科学图表训练的模型,更容易为类似可视化生成准确引用。问题在于,大多数LLM训练使用的是互联网级数据,许多可视内容缺乏规范元数据、alt文本或来源标注,导致AI系统学会了处理图表,却未学会正确引用。企业若在高质量、详细标注的数据可视化数据集上投入,将为未来AI系统打下更坚实的基础,尽管目前行业对此投资还未被充分重视。
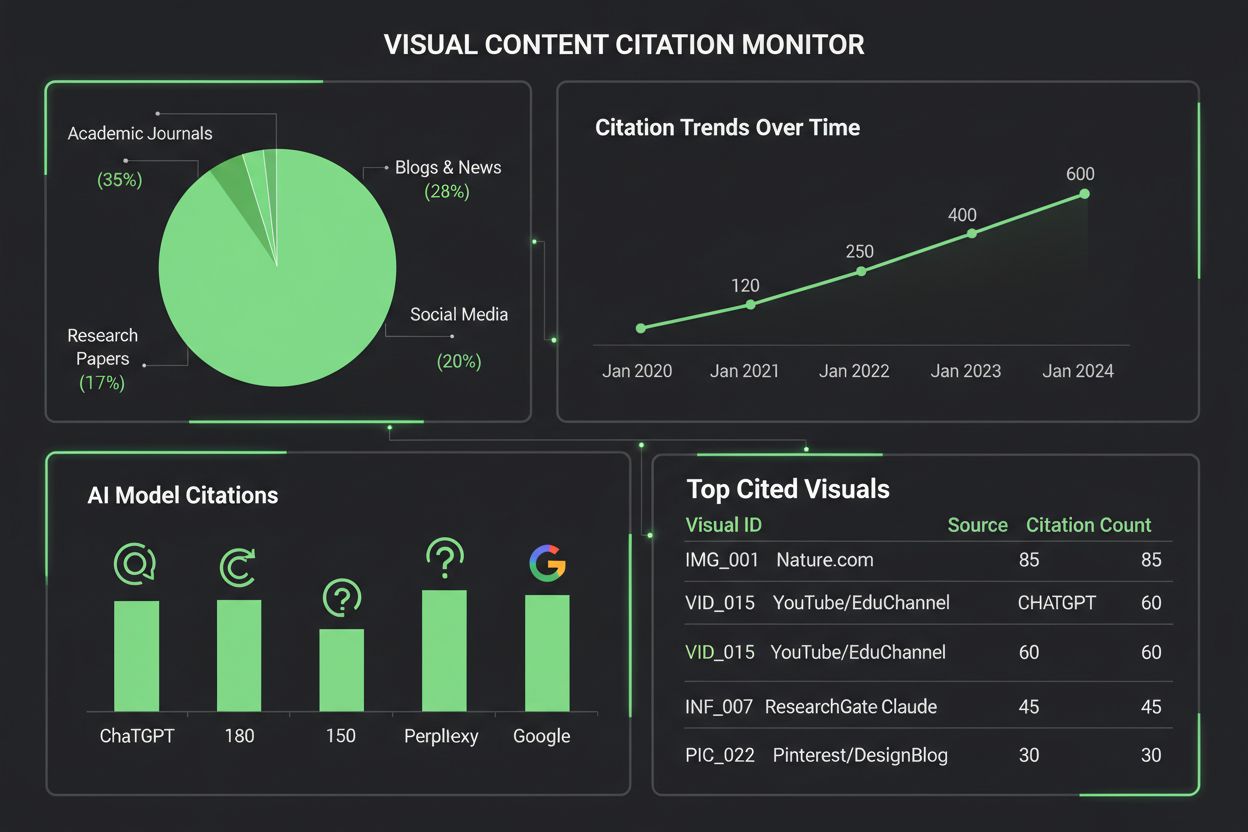
监测AI系统如何引用可视内容,需要结合自动化检测与人工核查的多层次方法。主要监测手段包括:
AmICited.com专注于跨多AI平台追踪可视内容引用,为内容创作者提供详细报告,展示他们的图表如何被ChatGPT、Claude、Perplexity、Google AI等系统引用、归属或忽略。监测可视引用的重要性不可低估——没有有效追踪,创作者无法了解自己的作品如何影响AI生成内容,也无法推动更佳归属实践或认知可视化作品的真实传播力。AmICited的可视内容监测工具为创作者提供实时引用预警、引用准确性分析和提升可发现性的可操作洞察,填补了这一关键缺口。
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
要让AI系统更容易引用您的可视化作品,需要在设计时有意突出清晰度、元数据丰富性和机器可读性。醒目的高对比色彩和清晰标注大幅提升AI对图表的处理能力,因为模型难以读取人类易于辨别的渐变色、重叠元素和模糊图例。请务必提供详尽的alt文本描述,不仅要陈述图表内容,还应涵盖数据关系、主要见解和来源信息——这些元数据为AI生成准确引用奠定基础。在可视化中嵌入结构化数据(如JSON-LD或微数据标记),让AI能直接提取精确值和关系,而无需仅凭视觉解读。图表标题要具体、具描述性,而非泛泛而谈,因为AI模型通常以标题为主锚点理解并引用可视内容。通过脚注、水印或集成来源标签,直接在图表中标注来源,让AI无法将图表与其出处分离。坚持这些实践的组织,会显著提升作品在AI平台上的引用率、可见性和专业影响力。
随着企业越来越重视AI如何引用可视内容,可视引用监测工具生态持续扩展。AmICited.com作为专为多平台可视内容引用监测而设计的综合型解决方案,为创作者提供详细仪表盘,直观展示他们的图表何时、如何被ChatGPT、Claude、Perplexity、Google AI Overviews等AI系统引用。Google Scholar和Scopus等传统引用监测平台主要关注学术论文和文本引用,基本不涵盖可视内容的监控和归属。像Tinybird及类似数据可视化平台已开始集成引用监测功能,让企业实时跟踪其数据可视化作品被AI系统消费和引用的情况。AmICited的可视分析能力可量化引用频率、准确率及平台分布,让内容创作者了解哪些AI系统能正确归属作品,哪些还需改善。对于重视可视知识产权保护和内容影响力的组织来说,部署像AmICited.com这样的专用可视引用监测方案已成必然——它让引用监测从被动观察转型为主动管理,推动更优归属成果。
社区讨论数据可视化和视觉内容在 AI 搜索中的表现。关于优化图表、信息图和图片以提升 AI 可见性的策略。
了解如何在 ChatGPT、Perplexity、Google AI Overviews 和 Claude 等平台追踪你的内容 AI 引用。监控品牌可见性,衡量影响力,并针对 AI 搜索引擎进行优化。...
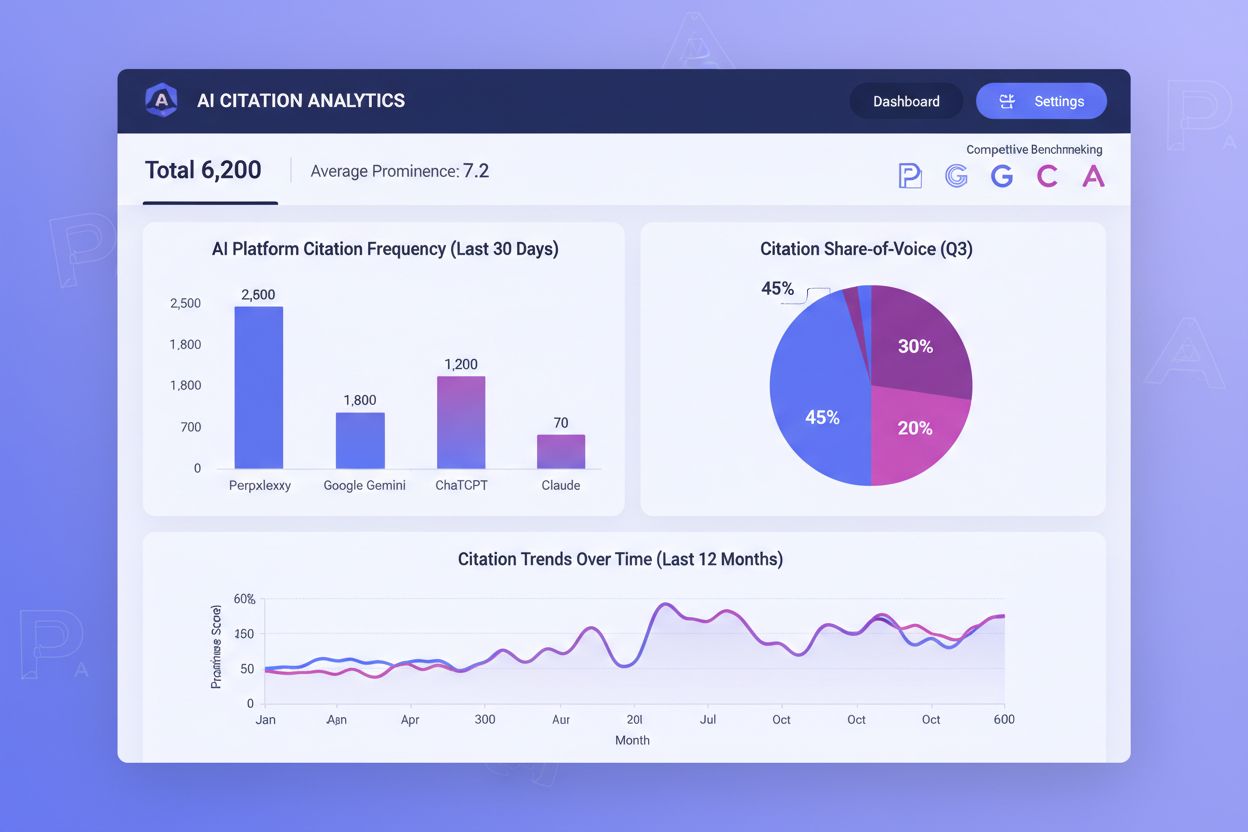
了解如何创建AI系统积极引用的原创数据和研究。发现让您的数据被ChatGPT、Perplexity、Google Gemini 和 Claude 发现的策略,同时建立可持续的AI可见性。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.