
Sådan hjælper datavisualiseringer AI-søgning og LLM-synlighed
Lær hvordan datavisualiseringer forbedrer AI-søgesynlighed, hjælper LLM'er med at forstå indhold og øger citater i AI-genererede svar. Opdag optimeringsstrategi...
10 min læsning

Opdag hvordan AI-modeller citerer visuelle data og diagrammer. Lær hvorfor datavisualisering betyder noget for AI-citater, og hvordan du kan spore dit visuelle indhold med AmICited.
Visuelle data udgør en grundlæggende flaskehals for moderne store sprogmodeller, som primært blev trænet på tekstbaseret information og har svært ved at behandle, fortolke og citere diagrammer med samme præcision, som de anvender på skriftligt indhold. Nuværende LLM’er står over for betydelige begrænsninger, når de møder datavisualiseringer—de skal først konvertere visuelle elementer til tekstbeskrivelser, en proces der ofte mister vigtige nuancer, præcise værdier og kontekstuelle relationer indlejret i det oprindelige diagram. Manglende evne til nøjagtigt at behandle visuelle data i LLM-systemer betyder, at diagrammer, grafer og infografikker ofte ikke bliver citeret eller bliver citeret forkert, hvilket skaber et troværdighedsgab for indholdsskabere, der investerer tid i at producere visualiseringer af høj kvalitet. Denne udfordring er særligt vigtig for forskere, analytikere og organisationer, der er afhængige af AI-diagrambehandling til informationssyntese, da manglende korrekt tilskrivning underminerer både den oprindelige skabers arbejde og pålideligheden af AI-genererede resumeer. At forstå disse begrænsninger er afgørende for alle, der skaber visuelt indhold i et stadig mere AI-drevet informationslandskab.

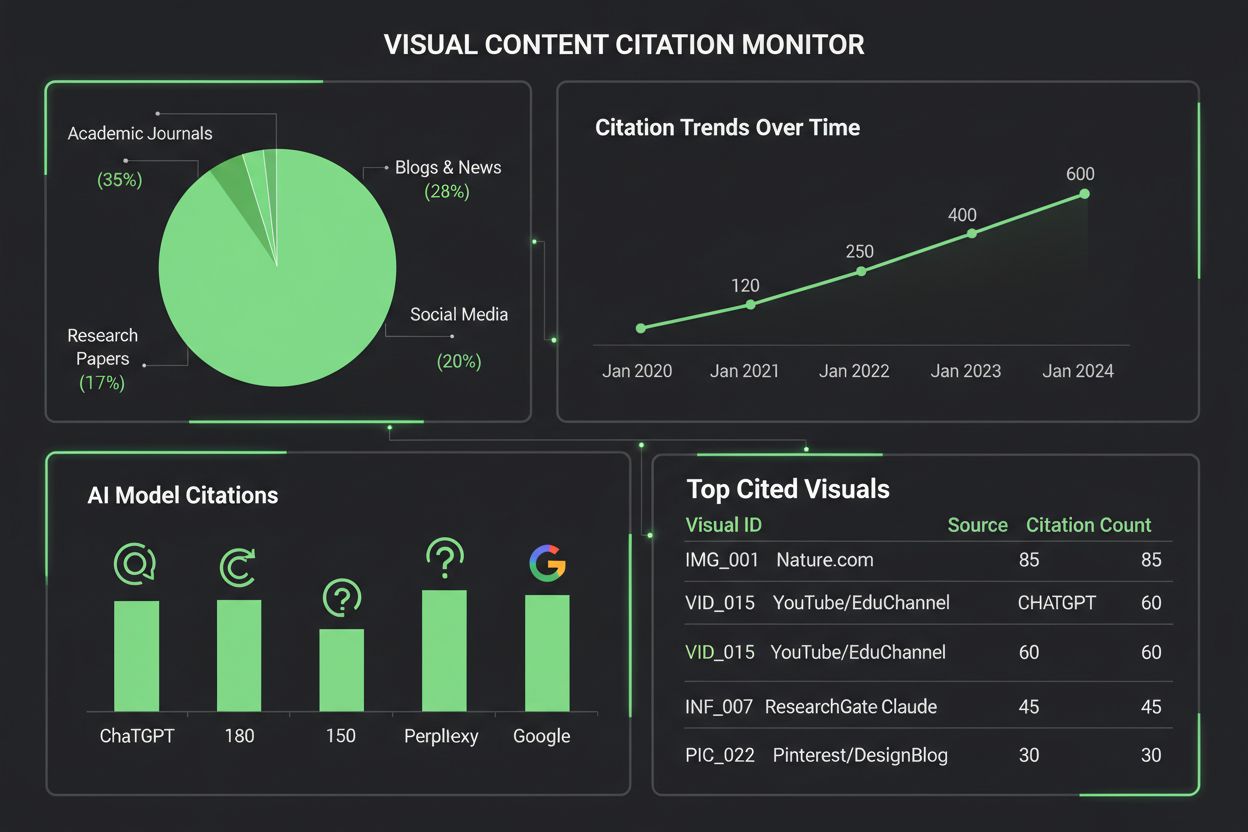
Forskellige AI-systemer tilgår citat af visuelt indhold med varierende grad af sofistikation, hvilket afspejler deres underliggende arkitektur og træningsmetoder. Tabellen herunder illustrerer, hvordan store AI-platforme håndterer visuelle citater:
| AI-model | Visuel citations-evne | Citatformat | Nøjagtighedsniveau | Multimodal support |
|---|---|---|---|---|
| ChatGPT (GPT-4V) | Moderat | Beskrivende tekst | 65-75% | Ja (billedinput) |
| Claude 3 | Høj | Detaljeret tilskrivning | 80-85% | Ja (vision-aktiveret) |
| Perplexity AI | Høj | Kilde + visuel reference | 85-90% | Ja (web-integreret) |
| Google AI Overviews | Moderat-høj | Indlejrede citater | 75-80% | Ja (billedsøgning) |
| Gemini Pro Vision | Moderat | Kontekstuel reference | 70-78% | Ja (multimodal) |
Claude udviser overlegen ydeevne i tilskrivning af visuelt indhold, og giver ofte detaljerede kildeoplysninger og visuel kontekst, når den refererer til diagrammer, mens Perplexity AI udmærker sig ved at integrere visuelle citater med webkilder, hvilket giver en mere omfattende citationskæde. ChatGPT’s GPT-4V kan behandle billeder, men falder ofte tilbage på generiske beskrivelser fremfor præcise citater, især ved komplekse finansielle diagrammer eller videnskabelige visualiseringer. Google AI Overviews forsøger at opretholde indlejrede citater for visuelt indhold, men forveksler nogle gange diagrammets skaber med datakilden, hvilket skaber uklarhed omkring korrekt tilskrivning. For indholdsskabere betyder denne variation, at den samme visualisering kan få vidt forskellig behandling afhængigt af, hvilket AI-system der behandler den—et diagram kan blive korrekt citeret i Claude, men slet ikke i ChatGPT, hvilket understreger behovet for standardiserede protokoller for visuelle citater på tværs af AI-økosystemet.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Datavisualisering spiller en overraskende indflydelsesrig rolle i, hvordan AI-modeller forstår og repræsenterer information, da diagrammer og grafer indlejret i træningsdatasæt lærer modellerne at genkende mønstre, relationer og hierarkier i komplekse data. Kvaliteten og mangfoldigheden af visuelle data i træningssæt har direkte indflydelse på, hvor godt AI-systemer senere kan fortolke og citere lignende visualiseringer, hvilket betyder, at modeller trænet på omfattende visuelle datasæt viser markant bedre præstation i tilskrivning af visuelt indhold. Visuelle mønstre lært under træning påvirker modellens output på subtile, men målbare måder—en model, der er trænet grundigt på korrekt mærkede videnskabelige diagrammer, vil mere sandsynligt generere nøjagtige citater for lignende visualiseringer end en, der primært er trænet på tekst. Udfordringen forstærkes, fordi de fleste store sprogmodeller blev trænet på internetdata, hvor visuelt indhold ofte mangler ordentlig metadata, alt-tekst eller kildeangivelse, hvilket fastholder en cyklus, hvor AI-systemer lærer at behandle diagrammer uden at lære at citere dem. Organisationer, der investerer i højkvalitets, veldokumenterede datasæt for datavisualisering, bygger i praksis bedre fundamenter for fremtidens AI-systemer, selvom denne investering stadig er underudnyttet i branchen.
Overvågning af, hvordan AI-systemer citerer visuelt indhold, kræver en flerlaget tilgang, der kombinerer automatiseret detektion med manuel verifikation. Centrale sporingsmetoder omfatter:
AmICited.com er specialiseret i at spore citater af visuelt indhold på tværs af flere AI-platforme, og giver indholdsskabere detaljerede rapporter om, hvordan deres diagrammer bliver refereret, tilskrevet eller overset af ChatGPT, Claude, Perplexity, Google AI og andre systemer. Vigtigheden af at overvåge visuelle citater kan ikke understreges nok—uden ordentlig sporing mister skaberen overblikket over, hvordan deres arbejde påvirker AI-genereret indhold, hvilket gør det umuligt at arbejde for bedre tilskrivningspraksis eller forstå den reelle rækkevidde af deres visualiseringer. AmICiteds værktøjer til overvågning af visuelt indhold udfylder dette afgørende hul ved at tilbyde skabere realtidsnotifikationer, når deres diagrammer bliver citeret, detaljeret analyse af citationsnøjagtighed og brugbare indsigter til at forbedre synligheden af visuelt indhold i AI-systemer.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
At skabe visualiseringer, der har større sandsynlighed for at blive citeret af AI-systemer, kræver bevidste designvalg, der prioriterer klarhed, metadata-rigdom og maskinlæsbarhed. Dristige, højkontrast farveskemaer og tydelig mærkning forbedrer AI’s billedbehandling markant, da modeller har svært ved subtile farveovergange, overlappende elementer og tvetydige signaturforklaringer, som mennesker let kan tolke. Inkludér omfattende alt-tekstbeskrivelser, der ikke bare opsummerer, hvad diagrammet viser, men også de underliggende datarelationer, nøgleindsigter og kildeoplysninger—disse metadata bliver fundamentet for nøjagtige AI-citater. Indlejring af strukturerede data i dine visualiseringer med standarder som JSON-LD eller mikrodata-markup gør det muligt for AI-systemer at udtrække præcise værdier og relationer i stedet for kun at stole på visuel tolkning. Sørg for, at diagramtitler er beskrivende og specifikke fremfor generiske, da AI-modeller bruger titler som primære ankre for at forstå og citere visuelt indhold. Giv kildeangivelse direkte i visualiseringen gennem fodnoter, vandmærker eller integrerede kildelabels, så AI-systemer ikke kan adskille diagrammet fra dets ophav. Organisationer, der konsekvent implementerer disse praksisser, oplever målbare forbedringer i, hvordan deres visuelle indhold bliver citeret på tværs af AI-platforme, hvilket fører til bedre tilskrivning, øget synlighed og stærkere professionel troværdighed.
Landskabet for værktøjer til overvågning af visuelle citater udvider sig løbende, efterhånden som organisationer indser vigtigheden af at spore, hvordan AI-systemer refererer visuelt indhold. AmICited.com skiller sig ud som en omfattende løsning, der specifikt er designet til at overvåge citater af visuelt indhold på tværs af flere AI-platforme, og tilbyder skabere detaljerede dashboards, der viser præcis, hvornår og hvordan deres diagrammer bliver citeret af ChatGPT, Claude, Perplexity, Google AI Overviews og nye AI-systemer. Traditionelle platforms for citationssporing som Google Scholar og Scopus fokuserer primært på akademiske artikler og tekstbaserede citater, hvilket efterlader visuelt indhold stort set uovervåget og uden tilskrivning. Specialiserede værktøjer som Tinybird og lignende datavisualiseringsplatforme integrerer nu citationssporing, så organisationer kan overvåge, hvordan deres realtids-datavisualiseringer konsumeres og refereres af AI-systemer. AmICiteds visuelle analysemuligheder giver metrics for citationsfrekvens, nøjagtighed og platformsspecifikke mønstre, så indholdsskabere kan forstå, hvilke AI-systemer der korrekt tilskriver deres arbejde, og hvilke der kræver intervention. For organisationer, der tager beskyttelsen af deres visuelle intellektuelle ejendom og forståelsen af deres indflydelse i det AI-drevne informationsøkosystem seriøst, er det blevet essentielt at implementere en dedikeret løsning til overvågning af visuelle citater som AmICited.com—det forvandler citationssporing fra passiv observation til aktiv forvaltning, der skaber bedre tilskrivningsresultater.
Følg med i, hvordan AI-systemer citerer dine diagrammer og visualiseringer på tværs af ChatGPT, Claude, Perplexity og Google AI. Få realtidsnotifikationer og detaljeret analyse af visuel indholds-tilskrivning.
Lær hvordan datavisualiseringer forbedrer AI-søgesynlighed, hjælper LLM'er med at forstå indhold og øger citater i AI-genererede svar. Opdag optimeringsstrategi...
Fællesskabsdiskussion om, hvordan datavisualiseringer og visuelt indhold klarer sig i AI-søgning. Strategier til at optimere diagrammer, infografikker og billed...

Lær hvordan du optimerer billeder til AI-systemer, LLM'er og visuel søgning. Bliv ekspert i alt-tekst, billedtekster, skemamarkering og teknisk optimering for a...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.