

训练数据 vs 实时搜索:AI 系统如何获取信息
了解 AI 训练数据与实时搜索的区别。学习知识截止、RAG 及实时检索如何影响 AI 可见性与内容策略。
2 分钟阅读
大型语言模型通过海量文本数据进行训练,但该训练过程存在一个关键局限:它仅能捕捉到特定时间点之前的信息,这一时间点被称为知识截止日期。例如,如果某LLM的训练数据截止到2023年12月,那么它对之后发生的事件、发现或进展一无所知。当用户询问当前事件、最新产品发布或突发新闻时,模型无法从训练数据中获得这些信息。LLM往往不会承认自己的不确定性,而是生成听起来合理但实际上错误的回答——这就是幻觉现象。在对准确性要求极高的应用场景中,如客户支持、金融咨询或医疗信息,过时或虚构的信息可能带来严重后果。
基础化指的是在推理时用外部上下文信息扩充LLM的预训练知识。基础化不再仅依赖训练期间学习到的模式,而是将模型连接到真实世界的数据源——无论是网页、内部文档、数据库还是API。其理念来源于认知心理学,特别是情境认知理论,即知识只有在实际应用的情境中才能被有效应用。在实际操作中,基础化将问题从“根据记忆生成答案”转变为“根据提供的信息综合答案”。最新研究对基础化有严格定义:LLM必须利用所提供上下文的全部关键信息,并严格限定在上下文范围内,不能凭空生成额外内容。
| 方面 | 非基础化回答 | 基础化回答 |
|---|---|---|
| 信息来源 | 仅预训练知识 | 预训练知识 + 外部数据 |
| 近期事件准确性 | 低(受知识截止限制) | 高(可获取最新信息) |
| 幻觉风险 | 高(模型凭空猜测) | 低(受上下文约束) |
| 引用能力 | 有限或无法实现 | 可完全溯源 |
| 可扩展性 | 固定(受模型规模限制) | 灵活(可添加新数据源) |
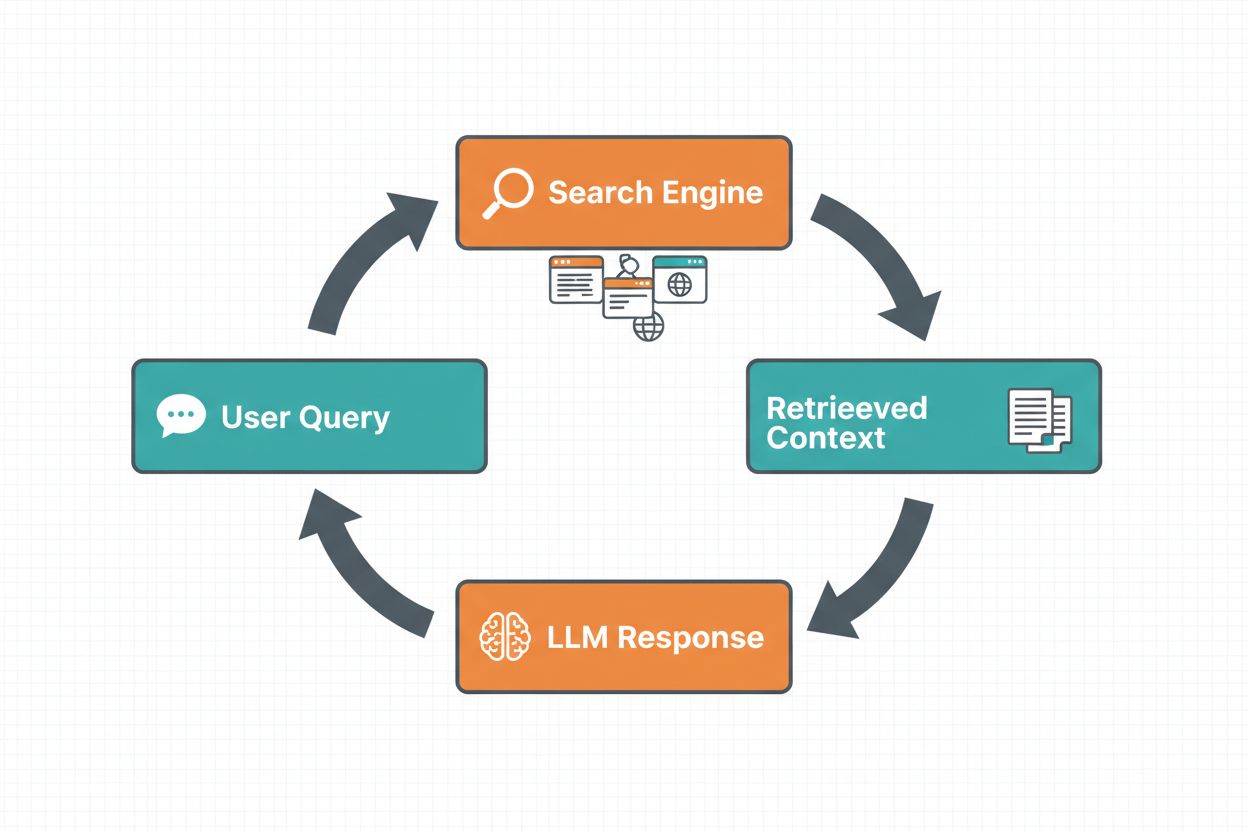
网页搜索基础化让LLM能够通过自动搜索互联网并将结果融入回答流程,从而访问实时信息。整个流程包括:首先,系统分析用户问题,判断是否需要网页搜索以优化答案;其次,生成一个或多个针对性检索相关信息的搜索查询;第三,调用搜索引擎(如Google Search或DuckDuckGo)执行这些查询;第四,对搜索结果进行处理并提取相关内容;最后,将这些上下文作为提示的一部分提供给LLM,让模型生成基础化答案。系统还会返回基础化元数据——即关于执行了哪些查询、检索了哪些来源、以及答案中的哪些部分由哪些来源支持的结构化信息。这些元数据对于建立信任和让用户验证结果至关重要。
网页搜索基础化工作流程:
**检索增强生成(RAG)**已成为主流基础化技术,它将多年来的信息检索研究与现代LLM能力结合。RAG首先从外部知识源(通常是向量数据库)检索出相关文档或片段,然后将这些检索内容作为上下文提供给LLM。检索通常分为两步:检索器用高效算法(如BM25或嵌入语义搜索)筛选候选文档,排序器则用更复杂的神经模型按相关性重新排序。检索到的上下文随后被注入提示中,使LLM能够基于权威信息进行综合。RAG相比微调有显著优势:无需重新训练模型,成本更低;只需添加新文档即可扩展,易于维护;信息更新也无需重新训练。例如,RAG的一个提示可能如下:
请利用以下文档回答问题。
[问题]
加拿大的首都是哪?
[文档1]
渥太华是加拿大的首都,位于安大略省...
[文档2]
加拿大是北美的一个国家,有十个省份...
网页搜索基础化最吸引人的优势之一,就是能够将实时信息融入LLM回答。这对需要最新数据的应用极为宝贵——如新闻分析、市场调研、事件信息或产品可用性。不仅如此,基础化还能提供引用和来源归属,这对建立用户信任和可验证性至关重要。当LLM生成基础化回答时,会返回结构化元数据,将具体论述与其来源文档对应,实现如“[1] source.com”这样的内嵌引用。这一能力正好契合AmICited.com等平台的使命,即监控AI系统在不同平台如何引用和参考来源。追踪AI系统参考了哪些来源、如何归属信息,对于品牌监测、内容归属以及确保AI负责任部署日益重要。
幻觉的出现源于LLM本质上只是根据之前的token及所学模式来预测下一个token,并不真正理解其知识的边界。当遇到训练数据范围外的问题时,模型仍会继续生成貌似合理的内容,而不是承认无知。基础化从根本上改变了模型任务:不再“凭记忆生成”,而是“根据提供信息综合”。在技术上,当相关外部上下文被纳入提示时,会引导token概率分布向有现实依据的答案倾斜,从而减少幻觉。研究证明,基础化可将幻觉率降低30-50%,具体取决于任务和实现。例如,问“2024年欧洲杯冠军是谁?”没有基础化时,旧模型可能给出错误答案;有网页检索基础化后,则会准确指出西班牙获胜并附上具体赛况。这是因为模型的注意力机制能够聚焦于所提供的上下文,而非依赖可能不完整或冲突的训练模式。
实施网页搜索基础化需要整合多个组件:搜索API(如Google Search、DuckDuckGo的Serp API或Bing Search)、判断是否需要基础化的逻辑,以及有效融入搜索结果的提示工程。实用方案通常首先判断用户问题是否需要最新信息——这一环节可以直接让LLM判断是否需要超出知识截止时间的信息。如果需要基础化,系统再执行网页搜索、处理结果提取相关片段,并构建含原问题和搜索上下文的提示。成本控制很重要:每次网页搜索都要API费用,因此采用动态基础化(仅在必要时才搜索)可大幅降低开支。例如,“为什么天空是蓝色的?”通常无需网页搜索,而“现任总统是谁?”则肯定需要。进阶实现会用更小更快的模型决策是否基础化,以减少延迟和成本,仅在最终回答时调用大模型。
尽管基础化很强大,但也带来诸多需要精细管理的挑战。数据相关性至关重要——如果检索信息不能真正回答用户问题,基础化反而会引入无关上下文。数据量有悖论:信息似乎越多越好,但研究发现LLM在输入过多时表现反而下降,这就是**“夹在中间”偏差**:模型难以发现和利用长上下文中间的信息。Token效率也成为关注点:每条检索上下文都消耗token,导致延迟和成本上升。“少即是多”原则适用:只取前3-5条最相关结果,使用更小的文本片段而不是全文,或从长文中提取关键句。
| 挑战 | 影响 | 解决方案 |
|---|---|---|
| 数据相关性 | 无关上下文干扰模型 | 用语义搜索+排序器;测试检索质量 |
| 夹在中间偏差 | 模型遗漏中间重要信息 | 缩小输入规模;关键信息置于头/尾 |
| Token效率 | 延迟和成本高 | 检索更少结果;用更小片段 |
| 信息过时 | 知识库中有旧内容 | 实施刷新策略;版本管理 |
| 延迟 | 搜索和推理导致回答慢 | 用异步操作;缓存常见查询 |
在生产环境部署基础化系统,需要高度关注治理、安全和运维等问题。数据质量保障是基础——所用信息必须准确、最新且与用例高度相关。访问控制在使用专有或敏感文档时尤为关键;必须确保LLM仅能访问用户权限范围内的信息。更新与漂移管理需要制定知识库刷新频率及冲突信息处理策略。审计日志对于合规和排障至关重要——应记录检索了哪些文档、排序方式以及提供给模型的上下文。其他重要考量包括:
LLM基础化领域正迅速从文本检索向更多元方向演进。多模态基础化正在兴起,系统将能结合图像、视频及结构化数据进行基础化——对于法律文档分析、医学影像、技术文档等领域尤为重要。自动化推理正与RAG结合,不仅检索信息,还能跨多源综合、逻辑推断并解释推理过程。安全护栏正与基础化深度集成,确保即使可访问外部信息,模型也能维护安全限制和政策合规。模型原地更新是另一前沿——研究者探索用新信息直接更新模型权重,可能减少对庞大外部知识库的依赖。这些进步预示未来基础化系统将更加智能、高效、能处理复杂多步推理任务,同时保持事实准确和可溯源性。
基础化是在推理时为LLM补充外部信息,无需修改模型本身;而微调则是在新数据上重新训练模型。基础化成本更低、实现更快,并且更容易用新信息更新。当需要根本性改变模型行为或需学习特定领域模式时,微调更为适用。
基础化通过为LLM提供事实性上下文,使其不再仅依赖训练数据,从而减少幻觉。当在提示中包含相关的外部信息时,会引导模型的token概率分布朝着有上下文依据的答案转移,从而降低虚构信息的可能性。研究显示,基础化可将幻觉率降低30-50%。
检索增强生成(RAG)是一种基础化技术,它从外部知识源检索相关文档并作为上下文提供给LLM。RAG的重要性在于其可扩展性、成本效益,并可在无需重新训练模型的情况下更新信息。它已成为构建基础化AI应用的行业标准。
当您的应用需要获取最新信息(新闻、事件、近期数据)、对准确性和引用要求高,或LLM知识截止时间成为限制时,应实施网页搜索基础化。建议采用动态基础化,仅在必要时搜索,以降低对不需要新信息的查询的成本和延迟。
关键挑战包括确保数据相关性(检索信息需真实回答问题)、管理数据量(多不一定好)、应对'夹在中间'偏差(模型遗漏长上下文中段信息)、优化token效率。解决方案包括用语义搜索与排序器、检索更少但更高质量的结果、将关键信息置于上下文开头或结尾。
基础化与AI答案监控直接相关,因为它使系统能够提供引用和来源归属。像AmICited这样的平台可以跟踪AI系统如何引用来源,而这只有在正确实现基础化的前提下才能实现。这有助于保障AI的负责任部署和跨平台品牌归属。
“夹在中间”偏差指的是当相关信息位于长上下文的中间时,LLM表现变差,而位于开头或结尾时效果更好。这是因为模型处理大量文本时往往会‘略读’。解决办法包括缩小输入规模、将关键信息置于优选位置、使用更小文本块。
生产部署时应关注数据质量保障,为敏感信息实施访问控制,建立更新和刷新策略,启用审计日志以符合法规,并建立用户反馈机制以识别失效点。监控token使用以优化成本,对知识库进行版本管理,并跟踪模型行为以检测漂移。
AmICited 跟踪 GPT、Perplexity 和 Google AI Overviews 如何引用和参考您的内容。获得有关AI答案监控和品牌归属的实时洞察。
了解 AI 训练数据与实时搜索的区别。学习知识截止、RAG 及实时检索如何影响 AI 可见性与内容策略。

了解维基百科引用如何塑造AI训练数据,并在LLM中产生涟漪效应。了解为何你的维基百科存在对于AI提及和品牌认知至关重要。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.