
用于手动AI可见性测试的提示库
了解如何构建和使用提示库进行手动AI可见性测试。DIY指南,帮助你测试AI系统如何在ChatGPT、Perplexity和Google AI等平台引用你的品牌。...
1 分钟阅读
提示测试是指系统性地向AI引擎提交查询,以衡量您的内容是否出现在其响应中的过程。与传统SEO测试关注搜索排名和点击率不同,AI可见性测试评估您在诸如ChatGPT、Perplexity和Google AI概览等生成式AI平台上的存在感。这一区别至关重要,因为AI引擎采用的排名机制、检索系统和引用模式与传统搜索引擎不同。测试您的存在感于AI回复中,需要一种根本不同的方法——这种方法要考虑大型语言模型如何从全网检索、综合和归属信息。

手动提示测试依然是理解AI可见性的最便捷入门方式,尽管它需要自律和详细记录。以下是主要AI平台上的测试方式:
| AI引擎 | 测试步骤 | 优点 | 缺点 |
|---|---|---|---|
| ChatGPT | 提交提示,查看回复,记录提及/引用,归档结果 | 直接访问,回复详细,可追踪引用 | 耗时,结果不一致,历史数据有限 |
| Perplexity | 输入查询,分析来源归因,追踪引用位置 | 来源归因清晰,数据实时,用户友好 | 需手动记录,查询量有限 |
| Google AI概览 | 在Google中搜索查询,查看AI生成摘要,记录来源收录情况 | 搜索集成,流量潜力大,用户行为自然 | 查询变体控制有限,出现不稳定 |
| Google AI模式 | 通过Google Labs访问,测试特定查询,追踪精选摘要 | 新兴平台,直接测试入口 | 平台早期,开放性有限 |
ChatGPT测试及Perplexity测试构成大多数手动测试策略的基础,因为这些平台用户量最大且引用机制最透明。
虽然手动测试能带来宝贵洞见,但在规模扩展时很快变得不可行。仅在四个AI引擎上手动测试50个提示,就需要提交200多次查询,每次都需手动记录、截图和分析结果——每轮测试要消耗10-15小时。手动测试的局限性不仅仅体现在时间投入:人工测试者在记录标准上易产生不一致,难以维持跟踪趋势所需的测试频率,也无法横跨数百个提示聚合数据以识别模式。需要同时测试品牌、非品牌变体、长尾查询及竞争基准时,可扩展性问题尤为突出。此外,手动测试只提供某一时点的快照;没有自动化系统,您无法追踪可见性在每周的变化,也无法识别哪些内容更新真正提升了AI存在感。
自动化的AI可见性工具通过持续向AI引擎提交提示、捕获回复并聚合结果到仪表板,从而免去手动负担。这些平台通过API和自动化流程,按您自定义的计划(每日、每周或每月),在无需人工干预的情况下测试数百上千个提示。自动化测试可实时捕获所有主流AI引擎上的提及、引用、归因准确性及情感等结构化数据。实时监控让您能够立即发现可见性变化,将其与内容更新或算法调整相关联,并做出策略响应。这些平台的数据聚合能力揭示了手动测试难以察觉的模式:哪些话题引用最多、AI引擎偏好哪种内容形式、您的声音占比与竞争对手如何、引用是否包含准确归因和链接。这种系统化方法将AI可见性从偶尔审计变为持续智能流,反哺内容策略和竞争定位。
要获得提示测试最佳实践的成功,需精心挑选提示并构建平衡的测试组合。请注意这些核心要素:
AI可见性指标带来您在生成式AI平台上的多维度视角。引用追踪不仅揭示您是否出现,还包括出现的突出程度——是主要来源、众多来源之一还是仅被顺带提及。声音占比将您的引用频率与同话题领域竞争对手做对比,指示竞争地位和内容权威度。由Profound等平台开创的情感分析,评估您的引用在AI回复中是正面、中性还是负面呈现——这是单纯提及次数无法反映的重要背景。归因准确性同样关键:AI引擎是否用链接正确归属于您的内容,还是在未归属的情况下转述?理解这些指标需结合情境分析——高流量查询中的一次提及,可能胜过低流量查询中的十次。竞争基准对比同样重要:若您在相关提示中出现率为40%,而竞争对手为60%,则暴露出值得关注的可见性缺口。
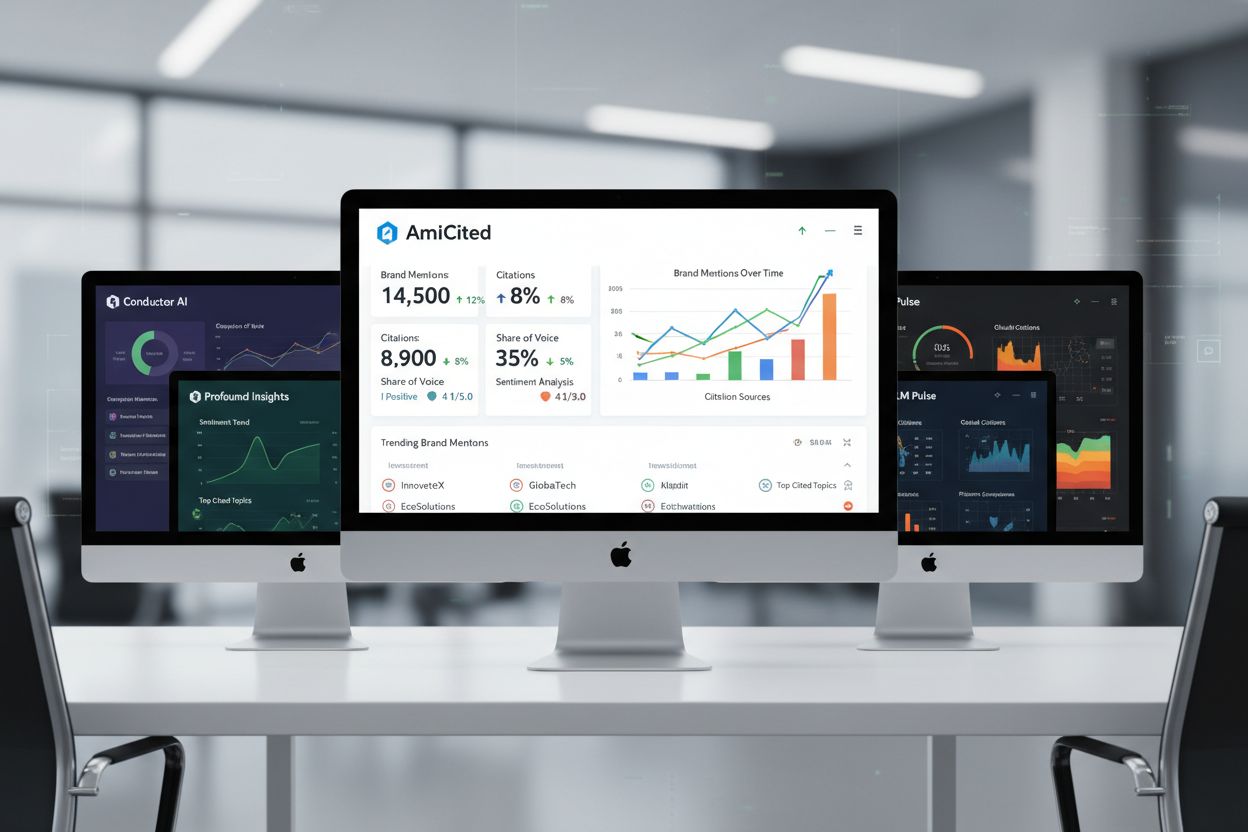
AI可见性平台市场包含多个专用工具,各有优势。AmICited在ChatGPT、Perplexity和Google AI概览中提供全面的引用追踪、详细的归因分析和竞争基准比对。Conductor专注于提示级追踪和话题权威度地图,帮助团队了解哪些话题带来最多AI可见性。Profound强调情感分析和来源归因准确性,这对于理解AI引擎如何呈现您的内容至关重要。LLM Pulse则提供手动测试指导和新兴平台覆盖,对从零建立测试流程的团队尤为有价值。选择取决于您的优先级:若以全面自动化和竞争分析为主,AmICited表现最佳;若以话题权威度为战略核心,Conductor更为合适;若重在理解AI引擎如何框定您的内容,Profound的情感分析能力突出。大多数成熟团队会结合多平台,以获得互补洞见。
企业常因可避免的错误而削弱测试效果。过度依赖品牌提示会造成虚假可见性——您也许在“公司名称”搜索中表现良好,却在真正带来发现和流量的行业话题中毫无存在感。测试安排不规律会导致数据不可靠;零散测试让您无法区分真实可见性趋势和正常波动。忽略情感分析易导致结果误判——若AI回复将您的内容负面呈现或抬高竞争对手,实际上可能损害您的定位。缺失页面级数据阻碍优化:知道您在哪个话题有曝光固然有价值,但了解具体页面及其归因方式,才能进行有针对性的内容提升。另一个关键错误是只测试当前内容;测试历史内容能揭示老页面是否仍有AI可见性,或已被新源取代。最后,不将测试结果与内容更新关联,意味着您无法判断哪些内容优化实际提升了AI可见性,从而阻碍持续优化。
提示测试结果应直接指导您的内容策略和AI优化重点。当测试发现竞争对手在高流量话题领域占主导而您几乎无可见性时,该话题就应成为内容创作重点——无论是新内容产出还是现有页面优化。测试结果能识别AI引擎偏好的内容形式:若竞争对手的清单类文章比您的长篇指南更常被引用,则优化内容形式可提升可见性。话题权威度可通过测试数据显现——在多个提示变体中持续出现,表明已建立权威;偶尔出现则提示内容短板或定位不足。利用测试先验证内容策略再大规模投入:若计划切入新话题领域,先测试现有可见性,以了解竞争强度和实际潜力。测试还能揭示归因模式:若AI引用您的内容却不给链接,则内容策略应更多强调独家数据、原创研究和独特观点,以促使AI引擎必须归因。最后,将测试周期纳入内容发布日历——围绕重大内容上线安排测试,以衡量影响,并根据真实AI可见性结果而非假设调整策略。
手动测试需要逐个向AI引擎提交提示并手动记录结果,这既耗时又难以扩展。自动化测试则使用平台按计划持续向多个AI引擎提交数百个提示,捕获结构化数据,并将结果聚合到仪表板中,便于趋势分析和竞争基准对比。
建议至少每周或每两周建立一次固定的测试频率,以跟踪有意义的趋势,并将可见性变化与内容更新或算法调整关联起来。对于高优先级话题或竞争激烈的市场,更频繁的测试(每日)更有益;而对于稳定成熟的内容领域,较低频率(月度)可能已足够。
遵循75/25原则:大约75%的非品牌提示(行业话题、问题陈述、信息查询),25%的品牌提示(公司名称、产品名称、品牌关键词)。这种平衡能帮助您了解发现可见性和品牌专属存在感,同时避免用您已占主导地位的查询人为提升结果。
在最初几轮测试周期内,您就会看到初步信号,但有意义的模式通常会在4-6周持续跟踪后出现。这段时间可以让您建立基线,考虑AI回复的自然波动,并将可见性变化与具体内容更新或优化行为关联起来。
可以,您可以直接访问ChatGPT、Perplexity、Google AI概览和Google AI模式,免费进行手动测试。但免费手动测试在规模和一致性上有限。像AmICited这样的自动化平台通常提供免费试用或免费套餐,便于在付费前先测试方法。
最重要的指标包括引用(AI引擎链接到您的内容时)、提及(品牌被引用时)、声音占比(您的可见性与竞争对手相比)、情感(您的引用被正面呈现与否)。归因准确性——AI引擎是否正确归属于您的内容——对了解真实可见性影响同样至关重要。
有效的提示能生成与您的业务目标相关的、可操作的、持续的数据。通过与搜索查询数据、客户访谈和销售对话对比,测试您的提示是否反映真实用户行为。内容更新后能带来可见性变化的提示,尤其有助于验证您的测试策略。
建议从主要引擎(ChatGPT、Perplexity、Google AI概览)入手,这些平台拥有最大用户基础和流量潜力。随着项目成熟,可扩展到Gemini、Claude等新兴引擎,或其它与受众相关的平台。选择重点取决于目标客户的活跃平台及哪些引擎为网站带来最多推荐流量。
了解如何构建和使用提示库进行手动AI可见性测试。DIY指南,帮助你测试AI系统如何在ChatGPT、Perplexity和Google AI等平台引用你的品牌。...
了解如何手动测试您的品牌在AI搜索引擎(如ChatGPT、Perplexity和谷歌AI概览)中的可见性。分步DIY指南,助您无需昂贵工具也能测试AI可见性。...

发现最佳免费AI可见性测试工具,监控您的品牌在ChatGPT、Perplexity和Google AI Overviews等平台上的提及情况。比较功能,立即开始使用。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.