
内容相关性评分
了解内容相关性评分如何利用AI算法衡量内容与用户查询和意图的匹配度。了解BM25、TF-IDF,以及搜索引擎和AI平台如何排名内容相关性。...
1 分钟阅读

AI 检索评分是量化与用户查询相关的文档或片段的相关性和质量的过程。它采用复杂的算法评估语义意义、上下文适宜性和信息质量,从而决定哪些来源被传递给语言模型用于 RAG 系统中的答案生成。
AI 检索评分是量化与用户查询相关的文档或片段的相关性和质量的过程。它采用复杂的算法评估语义意义、上下文适宜性和信息质量,从而决定哪些来源被传递给语言模型用于 RAG 系统中的答案生成。
AI 检索评分是量化与用户查询或任务相关的已检索文档或片段的相关性和质量的过程。与仅仅识别表层词汇重叠的关键词匹配不同,检索评分采用复杂的算法来评估语义意义、上下文适宜性和信息质量。这一评分机制是检索增强生成(RAG)系统的基础,它决定了哪些来源会被传递给语言模型用于答案生成。在现代大语言模型应用中,检索评分直接影响答案准确性、幻觉减少和用户满意度,通过确保只有最相关的信息进入生成阶段,从而提升整体效果。因此,检索评分的质量是系统性能和可靠性的重要组成部分。
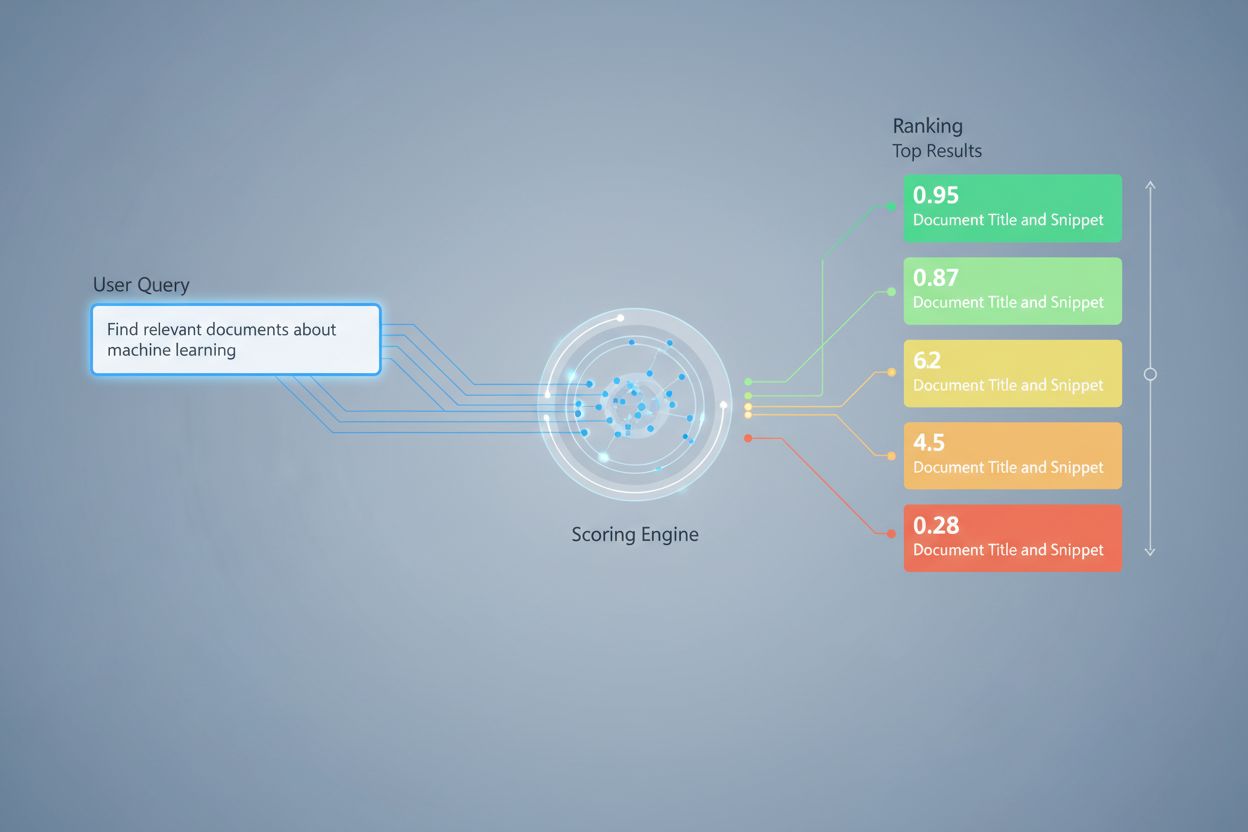
检索评分采用多种算法方法,每种方法针对不同场景有独特优势。语义相似度评分利用嵌入模型,在向量空间中衡量查询与文档之间的概念对齐,捕捉超越表层关键词的意义。BM25(Best Matching 25)是一种概率排序函数,考虑词频、逆文档频率和文档长度归一化,在传统文本检索中表现出色。TF-IDF(词频-逆文档频率)根据词语在文档中的重要性和在集合中的稀有性加权,尽管缺乏语义理解。混合方法则结合多种方式,例如合并 BM25 和语义分数,既利用词汇信号又利用语义信号。除了评分方法外,像Precision@k(前 k 个结果的相关文档比例)、Recall@k(前 k 个结果覆盖的相关文档比例)、NDCG(归一化折损累计增益,考虑排名位置)和 MRR(平均倒数排名)等评估指标,为检索质量提供了定量衡量。理解每种方法的优劣——如 BM25 的高效与语义评分的深度理解——对于选择特定应用的合适方案至关重要。
| 评分方法 | 工作原理 | 最适用场景 | 主要优势 |
|---|---|---|---|
| 语义相似度 | 利用余弦相似度或其他距离指标比较嵌入 | 概念意义、同义词、释义 | 捕捉超越关键词的语义关系 |
| BM25 | 概率排序,考虑词频与文档长度 | 精确短语匹配、基于关键词的查询 | 快速高效,生产系统验证 |
| TF-IDF | 根据词频和跨集合稀有性加权 | 传统信息检索 | 简单、可解释、轻量级 |
| 混合评分 | 语义与关键词方法加权融合 | 通用检索、复杂查询 | 兼具多种方法优势 |
| 基于大模型评分 | 用语言模型结合定制提示判断相关性 | 复杂上下文、领域任务 | 捕捉细致语义关系 |
在RAG 系统中,检索评分通常分多层进行,以确保生成质量。系统通常对文档内的片段或段落进行评分,实现更细粒度的相关性评估,而不是将整篇文档作为不可分割的单元处理。这种按片段相关性评分使系统能够仅提取最重要的信息片段,减少噪音和无关上下文,避免干扰语言模型。RAG 系统常用评分阈值或截断机制,在生成阶段前过滤掉低分结果,防止低质量来源影响最终答案。所检索上下文的质量与生成质量直接相关——高分、相关片段带来更准确、根据事实的响应,而低质量检索则增加幻觉和事实错误。对检索分数的监控也为系统性能下滑提供预警,是AI 答案监控与生产质量保障的关键指标。
重排序是对初步检索结果进行二次筛选与优化的机制,通常能显著提升排序准确度。初始检索器生成候选结果及初步分数后,重排序器用更复杂的评分逻辑对这些候选进行重新排序或筛选,往往借助计算代价更高、但分析更深入的模型。Reciprocal Rank Fusion (RRF) 是一种流行技术,通过将多个检索器的排名按结果位置分配分数,再融合这些分数生成统一排名,通常优于单一检索器。结合不同检索方法时,分数归一化变得关键,因为 BM25、语义相似度等方法的原始分数尺度不一,需校准到可比区间。集成检索方法则同时利用多种策略,由重排序机制根据综合证据决定最终排序。这种多阶段方式在复杂领域中远优于单阶段检索,大幅提升准确性和鲁棒性,因为不同检索方法可捕捉互补的相关信号。
Precision@k:衡量前 k 个结果中相关文档的比例;用于评估检索结果的可靠性(如 Precision@5 = 4/5 表示前 5 个结果中有 80% 相关)
Recall@k:计算所有相关文档中有多少被前 k 个结果覆盖;确保相关信息的全面覆盖
命中率(Hit Rate):二元指标,表示前 k 个结果中是否至少有一个相关文档;适用于生产环境的快速质量检查
NDCG(归一化折损累计增益):根据排名位置赋予更高权重,相关文档越靠前得分越高;取值 0-1,适合评估排序质量
MRR(平均倒数排名):衡量多个查询下首个相关结果的平均排名位置;评估最相关文档是否足够靠前
F1 分数:精确率与召回率的调和平均;当误报与漏报同等重要时提供平衡评估
MAP(平均平均精度):对每个相关文档出现位置的精度取平均,再对多个查询求平均;全面衡量整体排序质量
基于大语言模型的相关性评分直接利用语言模型作为文档相关性评判者,为传统算法提供灵活替代。在此范式下,可以通过定制提示让大模型判断检索片段是否回答了查询,产出二元相关性分数(相关/不相关)或数值分数(如 1-5 分表示相关强度)。这种方法能捕捉更细致的语义关系和领域相关性,特别适合需要深度理解的复杂查询。但基于大模型的评分也带来挑战,如计算成本高(模型推理远高于嵌入相似度)、不同提示和模型间存在不一致性,以及需与人工标签校准以确保分数与真实相关性一致。尽管如此,这一评分方式已在评估 RAG 系统质量和生成专用评分模型训练数据方面展现出重要价值,是评估答案质量的 AI 监控工具箱的重要组成部分。
高效检索评分的实现需综合多种实际因素。方法选择取决于用例需求:语义评分善于捕捉意义,但需嵌入模型支持;BM25 便于词汇匹配且速度快。速度与准确性的权衡至关重要——基于嵌入的评分相关性理解更强但有延迟,BM25 与 TF-IDF 则更快但语义能力有限。计算成本包括模型推理时间、内存需求和基础设施扩展,尤其对高并发生产系统非常重要。参数调优涵盖阈值、混合方法加权和重排序截断等,用于适配特定领域和用例。持续通过 NDCG、Precision@k 等指标监控评分表现,有助于及时发现系统劣化,实现主动优化,确保生产 RAG 系统答案质量始终如一。
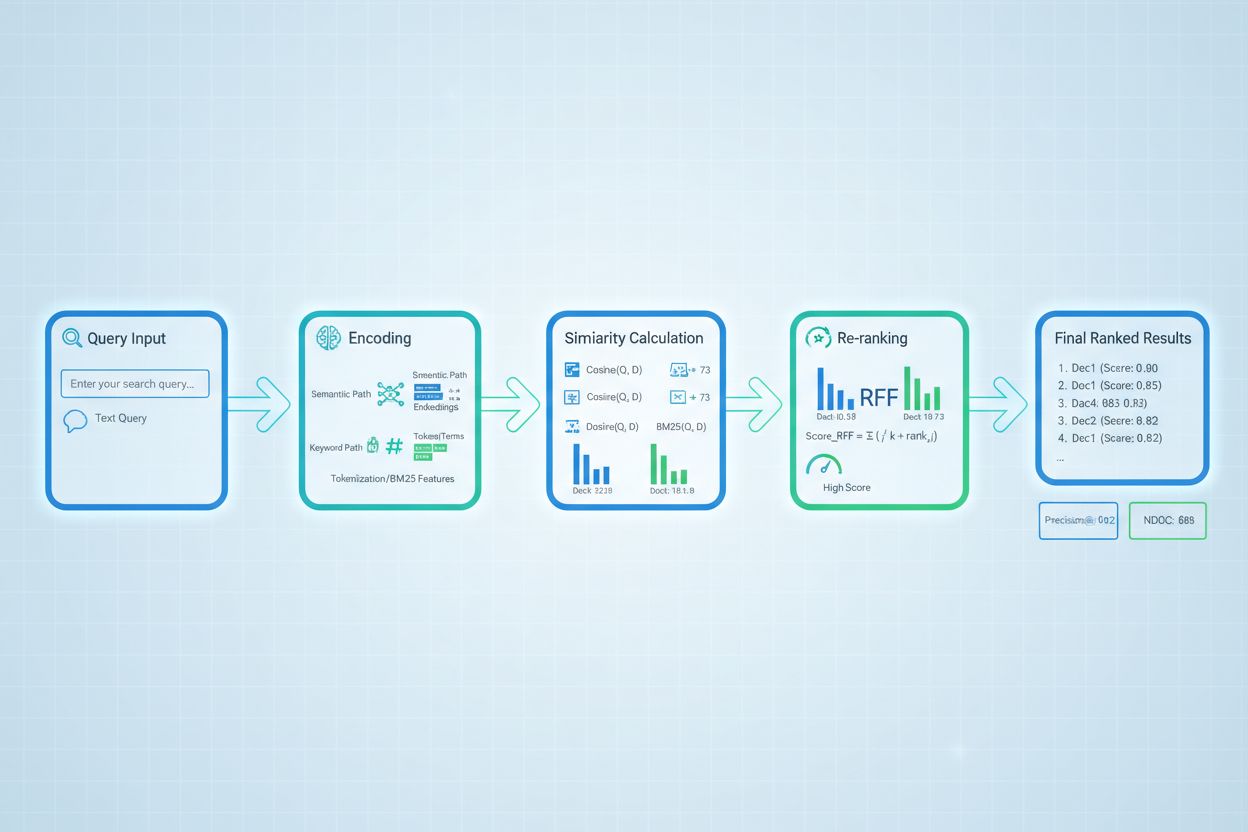
高级检索评分技术突破了基础相关性评估,能够捕捉更复杂的上下文关系。查询重写通过将用户查询改写为多种语义等价形式,可提升评分效果,使检索器发现原始字面匹配可能遗漏的相关文档。**假设性文档嵌入(HyDE)**从查询生成合成相关文档,再用这些假设文档提升检索评分,找到更接近理想答案的真实文档。多查询方法向检索器提交多种查询变体并聚合其分数,相较单一查询更具鲁棒性和覆盖面。领域专用评分模型基于特定行业或知识领域的标注数据训练,在专业应用(如医疗、法律 AI 系统)中效果优于通用模型。上下文评分调整则考虑文档时效性、来源权威性和用户上下文等因素,使相关性评估更贴近实际生产需求,突破仅靠语义相似度的限制。
检索评分根据文档与查询的关系为其分配数值相关性分数,而排序则根据这些分数对文档进行排序。评分是评估过程,排序是排序结果。两者对于 RAG 系统输出准确答案都很关键。
检索评分决定了哪些来源能够被传递给语言模型进行答案生成。高质量的评分能确保选中相关信息,减少幻觉并提升答案准确性。评分不佳则会导致无关上下文与不可靠的 AI 回答。
语义评分利用嵌入模型理解概念意义,能够捕捉同义词和相关概念。基于关键词的评分(如 BM25)匹配精确词语和短语。语义评分更适合理解意图,关键词评分则擅长查找具体信息。
主要指标包括 Precision@k(前 k 个结果的准确率)、Recall@k(相关文档的覆盖率)、NDCG(排名质量)和 MRR(首个相关结果的位置)。根据用例选择指标:质量优先用 Precision@k,全面覆盖用 Recall@k。
可以,基于大语言模型的评分是利用语言模型作为“裁判”来评估相关性。这种方式能够捕捉更细腻的语义关系,但计算成本较高。它适用于评估 RAG 系统质量和生成训练数据,但需与人工标签进行校准。
重排序是用更复杂的模型对初步结果进行二次筛选。诸如 Reciprocal Rank Fusion 等技术结合多种检索方法,提升准确性与鲁棒性。在复杂领域,重排序远优于单阶段检索。
BM25 和 TF-IDF 快速且轻量,适合实时系统。语义评分需嵌入模型推理,带来延迟。基于大语言模型的评分成本最高。应根据延迟需求和算力资源选择。
优先事项不同选择也不同:注重语义理解用语义评分,追求速度和效率用 BM25,混合方法兼顾性能。可用 NDCG、Precision@k 等指标在具体领域进行评估。多方法测试并衡量其对最终答案质量的影响。
追踪 ChatGPT、Perplexity 和 Google AI 等系统如何引用您的品牌,并评估其检索与排序来源的质量。确保您的内容被 AI 系统正确引用和排名。
了解内容相关性评分如何利用AI算法衡量内容与用户查询和意图的匹配度。了解BM25、TF-IDF,以及搜索引擎和AI平台如何排名内容相关性。...

了解可读性分数对 AI 搜索可见性的意义。探索 Flesch-Kincaid、句子结构和内容格式如何影响 ChatGPT、Perplexity 和 Google AI Overviews 中的 AI 引用。...
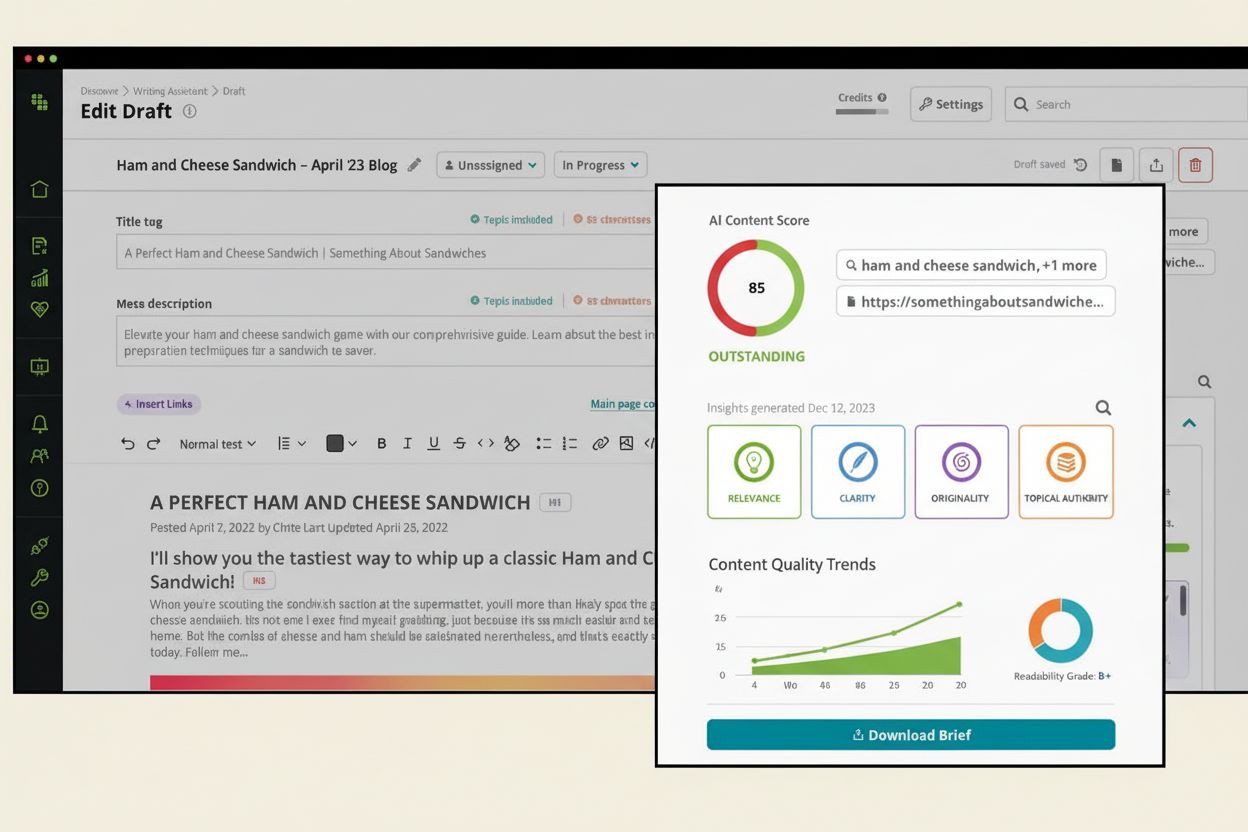
了解什么是AI内容评分、其如何评估AI系统的内容质量,以及为什么它对ChatGPT、Perplexity和其他AI平台的可见性至关重要。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.