
主流平台如何选择退出 AI 训练
全面指南,教你如何在 ChatGPT、Perplexity、LinkedIn 及其他平台选择退出 AI 训练数据收集。一步步了解如何保护您的数据不被用于 AI 模型训练。...
2 分钟阅读
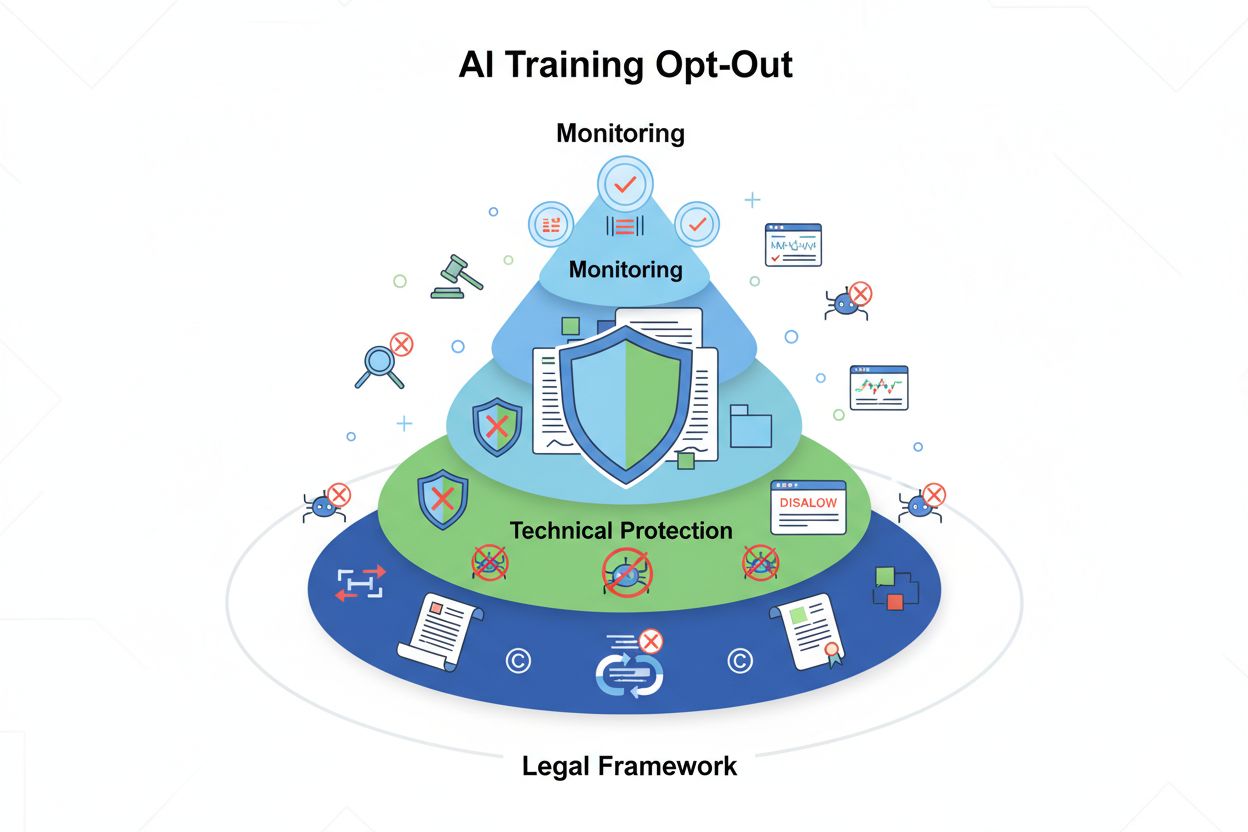
允许内容创作者和版权所有者阻止其作品被用于大型语言模型训练数据集的技术和法律机制。这些机制包括robots.txt指令、法律选择退出声明,以及如欧盟AI法案等法规下的合同保护措施。
允许内容创作者和版权所有者阻止其作品被用于大型语言模型训练数据集的技术和法律机制。这些机制包括robots.txt指令、法律选择退出声明,以及如欧盟AI法案等法规下的合同保护措施。
AI训练选择退出是指允许内容创作者、版权所有者和网站所有者阻止其作品被用于大型语言模型(LLM)训练数据集的技术和法律机制。随着AI公司从互联网抓取大量数据以训练日益复杂的模型,控制您的内容是否参与这一过程已成为保护知识产权和维护创作主权的关键。这些选择退出机制分为两大类:一是通过技术指令引导AI爬虫跳过您的内容,二是通过法律框架明确排除您的作品进入训练数据集的合同权利。全面理解这两个层面,对于关心自己内容在AI时代被如何使用的任何人而言都至关重要。

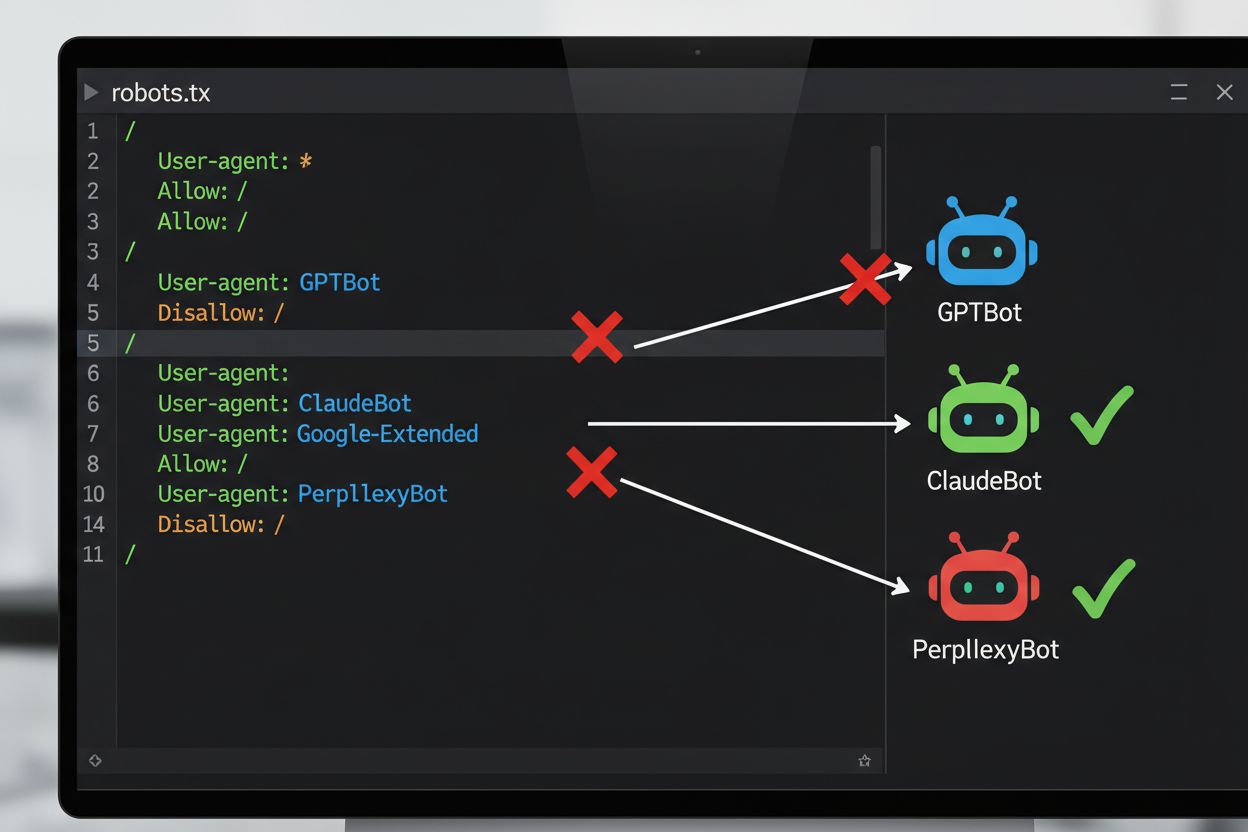
最常见的AI训练选择退出技术方法是通过robots.txt文件实现。该文件是放置在网站根目录下的一个简单文本文件,用于向自动化爬虫传达访问权限。当AI爬虫访问您的网站时,会首先检查robots.txt文件,以确定是否被允许抓取您的内容。通过为特定爬虫用户代理添加禁止指令,您可以指示AI机器人完全跳过您的网站。每家AI公司运营着多个具有不同用户代理标识的爬虫——这些标识本质上是机器人在发起请求时自报身份的“名称”。例如,OpenAI的GPTBot使用用户代理字符串"GPTBot"进行标识,Anthropic的Claude使用"ClaudeBot"。语法很简单:指定用户代理名称,再声明禁止访问的路径,如"Disallow: /“可屏蔽整个站点。
| AI公司 | 爬虫名称 | 用户代理标识 | 目的 |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | 模型训练数据采集 |
| OpenAI | OAI-SearchBot | OAI-SearchBot | ChatGPT搜索索引 |
| Anthropic | ClaudeBot | ClaudeBot | 聊天引用抓取 |
| Google-Extended | Google-Extended | Gemini AI训练数据 | |
| Perplexity | PerplexityBot | PerplexityBot | AI搜索索引 |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | AI模型训练 |
| Common Crawl | CCBot | CCBot | LLM训练开源数据集 |
随着欧盟AI法案于2024年生效,并融合了文本和数据挖掘(TDM)指令,AI训练选择退出的法律环境发生了重大变化。根据相关法规,AI开发者只有在合法获得内容访问权且版权所有者未明确保留排除权利的情况下,才能将受版权保护的作品用于机器学习。这创造了一种正式的法律选择退出机制:版权所有者可为其作品提交选择退出声明,从而有效阻止其作品在未获得明确许可的情况下被用于AI训练。欧盟AI法案标志着从此前“快速迭代,无视规则”模式的重大转变,明确要求AI模型训练企业核查权利人是否已保留其内容,并落实技术与组织层面的保护措施,防止意外使用已选择退出的作品。这一法律框架适用于整个欧盟,并影响全球AI企业的数据收集与训练策略。
实施选择退出机制通常涉及技术配置和法律文档两方面。技术层面,网站所有者可在robots.txt文件中为特定AI爬虫用户代理添加禁止指令,合规爬虫在访问时会遵守这些指令。法律层面,版权所有者可向著作权集体管理组织提交选择退出声明——如荷兰Pictoright和法国音乐集体SACEM已建立正式的选择退出流程,允许创作者保留其作品不被用于AI训练的权利。许多网站和内容创作者如今也在服务条款或元数据中加入明确的选择退出声明,声明其内容不得用于AI模型训练。但这些机制的有效性取决于爬虫的合规性:尽管OpenAI、Google、Anthropic等主流公司已公开表示会尊重robots.txt指令及选择退出声明,但由于缺乏统一的强制机制,是否真正遵守选择退出请求仍需持续监控和验证。
尽管已存在多种选择退出机制,但其有效性受多方面挑战限制:
对于需要比robots.txt更强保护的组织,还可以采用多种技术手段。用户代理过滤可在服务器或防火墙层面直接拦截特定爬虫标识的请求,尽管这一方式仍易被伪造。IP地址屏蔽可针对主流AI企业公布的爬虫IP段,但坚决的抓取者可通过代理网络轻松规避。请求速率限制与节流可通过降低单IP每秒可访问次数,令抓取成本大幅提升,但复杂的机器人可多IP分布式绕过。身份认证和付费墙为内容加上访问门槛,仅允许授权用户或付费用户浏览,有效阻止自动抓取。设备指纹识别与行为分析可通过分析浏览器API、TLS握手、交互模式等差异识别机器人。部分组织甚至部署了蜜罐和陷阱——仅有机器人会点击的隐藏链接或无限循环链接迷宫,从而浪费爬虫资源,甚至向其训练数据注入无用信息。
AI公司与内容创作者间的博弈已催生多起高调事件,反映出选择退出执行的实际挑战。Reddit于2023年大幅提高API访问价格,专门针对AI企业收费,有效遏制了未经授权的抓取,迫使OpenAI、Anthropic等公司不得不协商授权协议。Twitter/X采取更极端措施,短时间内屏蔽所有未登录用户对推文的访问,并限制登录用户可读推文数量,明确打击消耗资源的数据抓取。Stack Overflow曾因担忧用户贡献代码的授权问题,在robots.txt中屏蔽OpenAI的GPTBot,后又取消屏蔽——可能表明已与OpenAI达成某种协议。新闻媒体集体行动:2023年已有50%以上主流新闻网站屏蔽AI爬虫,纽约时报、CNN、路透社、卫报等均将GPTBot加入禁止名单。部分新闻机构选择法律诉讼,如纽约时报对OpenAI提起版权侵权诉讼,另一些如美联社则与AI公司签订内容授权协议。这些案例说明,选择退出机制虽已存在,但其效果取决于技术实施与违规后是否有意愿追究法律责任。
部署选择退出机制仅是第一步,验证其实际效果需持续监测和测试。多种工具可帮助您验证配置:Google Search Console提供针对Googlebot的robots.txt测试工具,Merkle的robots.txt Tester和TechnicalSEO.com工具可针对特定用户代理测试爬虫行为。若需全面监测AI公司是否实际遵守您的选择退出指令,AmICited.com等平台可专门跟踪AI系统在GPTs、Perplexity、Google AI Overviews等平台上如何引用您的品牌与内容。这类监测尤为重要,因为它不仅揭示爬虫是否访问了您的站点,还能显示您的内容是否实际出现在AI生成的回复中,反映选择退出在实践中的有效性。定期分析服务器日志也能发现哪些爬虫正在尝试访问您的网站及其是否遵守robots.txt,但这通常需要一定的技术能力进行解读。
如欲有效保护您的内容免遭未经授权的AI训练使用,建议采用技术与法律相结合的多层防护。首先,为所有主流AI训练爬虫(GPTBot、ClaudeBot、Google-Extended、PerplexityBot、CCBot等)设置robots.txt指令,认识到这为合规公司提供基础防护。第二,在网站服务条款和元数据中加入明确的选择退出声明,清楚表明您的内容不得用于AI模型训练——若发生违规,这将强化您的法律地位。第三,定期使用测试工具与服务器日志监控您的配置,确保爬虫确实遵循您的指令,并每季度更新robots.txt,因新的AI爬虫不断涌现。第四,如具备技术资源,可考虑用户代理过滤或速率限制等进阶措施,以增强对复杂抓取者的防护。最后,务必详细记录您的选择退出措施,如需对无视指令的公司采取法律行动时,这些记录尤为关键。请牢记,选择退出并非一次性配置,而是需要持续关注与应变的动态过程,伴随着AI行业不断演进。
robots.txt是一种技术性、自愿的标准,指示爬虫跳过您的内容,而法律选择退出涉及向版权机构提交正式保留声明或在服务条款中加入合同条款。robots.txt易于实施但缺乏强制力,而法律选择退出提供更强的法律保护,但需要更为正式的程序。
像OpenAI、Google、Anthropic和Perplexity等主流AI公司已公开声明会遵守robots.txt指令。但robots.txt属于自愿标准,没有强制机制,因此不合规的爬虫和恶意抓取者可以完全无视您的指令。
不会。屏蔽GPTBot和ClaudeBot等AI训练爬虫不会影响您在Google或Bing的搜索排名,因为传统搜索引擎使用的是不同的爬虫(Googlebot、Bingbot),它们彼此独立运行。只有当您希望完全从搜索结果中消失时才需要屏蔽这些爬虫。
欧盟AI法案要求AI开发者必须合法访问内容,并尊重版权所有者的选择退出保留权。版权所有者可为其作品提交选择退出声明,从而有效阻止其被用于AI训练,除非获得明确许可。这为保护内容免遭未经授权的训练使用建立了正式法律机制。
这取决于具体机制。屏蔽所有AI爬虫确实会阻止您的内容出现在AI搜索结果中,但这也意味着您将完全从AI驱动的搜索平台消失。有些发布者倾向于选择性屏蔽——允许以搜索为主的爬虫访问,同时屏蔽以训练为主的爬虫,以便既能在AI搜索中保持可见性,又能保护内容不被用于模型训练。
如果AI公司无视您的选择退出指令,您可通过版权侵权申诉或合同违约起诉等法律途径维权,具体取决于您的司法管辖区和具体情况。但法律行动成本高、周期长,且结果不确定。因此,监测和记录您的选择退出措施尤为重要。
至少每季度审查并更新一次您的robots.txt配置。新的AI爬虫不断涌现,各公司也频繁推出新的爬虫用户代理。例如,Anthropic已将'anthropic-ai'和'Claude-Web'融合为'ClaudeBot',使得未及时更新规则的网站对新爬虫暂时开放了访问权。
选择退出对遵守robots.txt和法律框架的合规、知名AI公司有效。但对于恶意爬虫和不合规的抓取者,其效果有限,这些爬虫常游走于法律灰色地带。robots.txt大约能阻止40-60%的AI爬虫,因此建议采取多层次的技术和法律措施相结合的方法。
全面指南,教你如何在 ChatGPT、Perplexity、LinkedIn 及其他平台选择退出 AI 训练数据收集。一步步了解如何保护您的数据不被用于 AI 模型训练。...

了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...

Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.