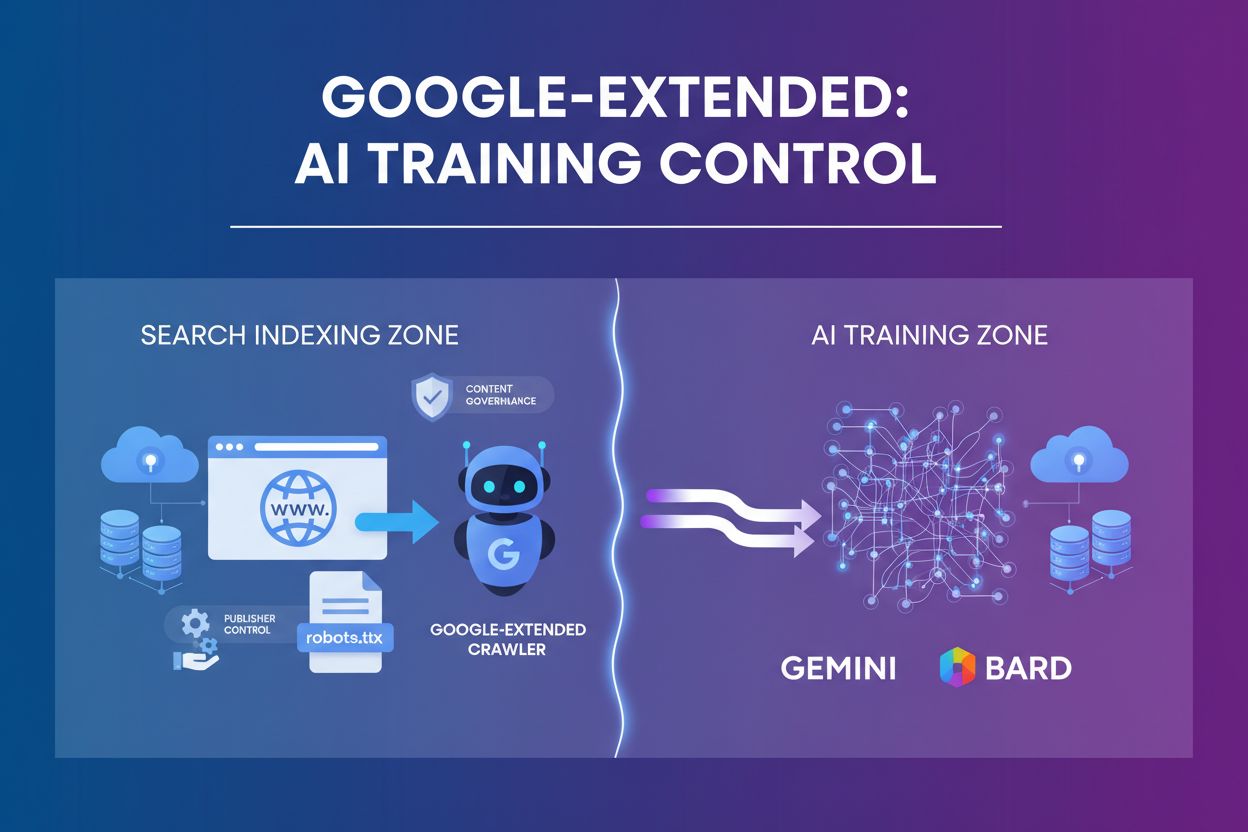
Google-Extended
了解 Google-Extended,这一用户代理标识让发布者能够控制其内容是否被用于 Gemini 和 Vertex AI 的 AI 训练。了解它与 Googlebot 的区别及如何在 robots.txt 中实现。...
2 分钟阅读
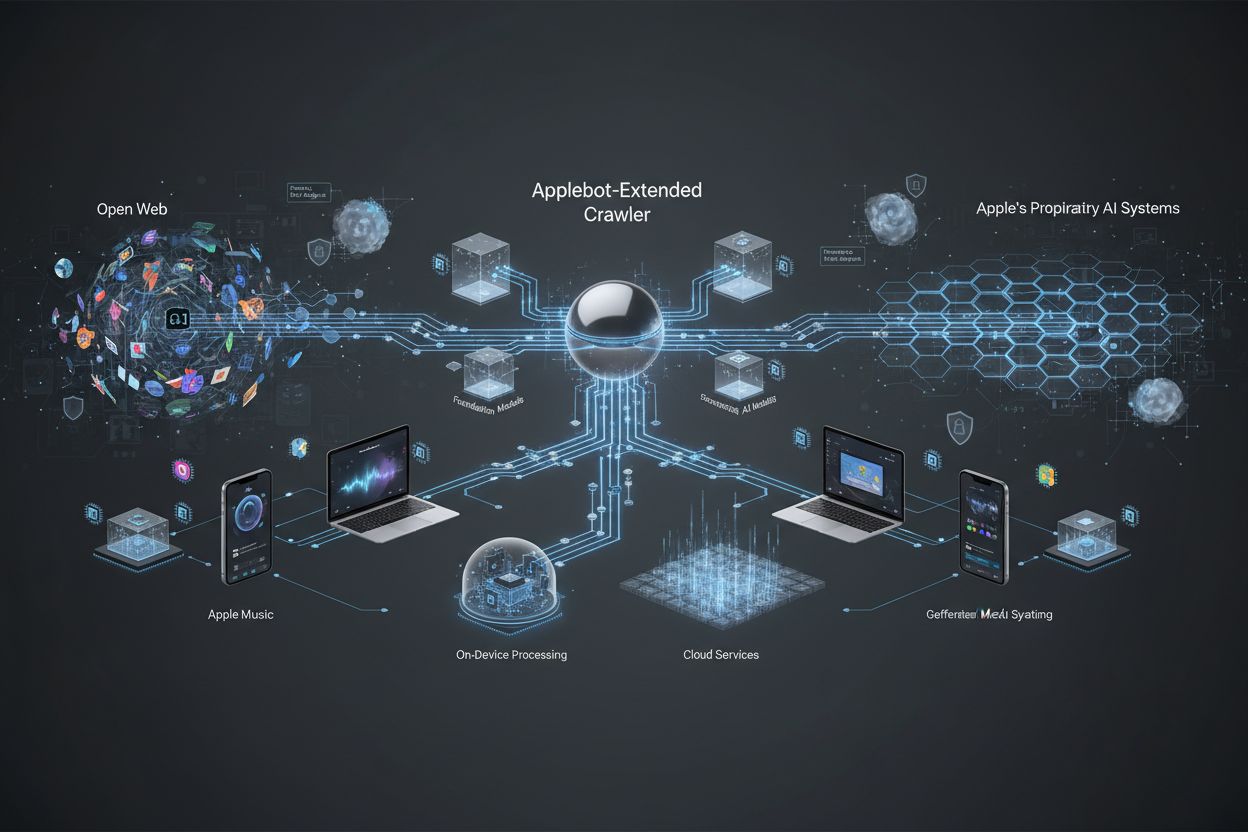
Apple 专门用于评估内容以训练 Apple Intelligence 和生成式 AI 模型的网络爬虫。它作为标准 Applebot 的二级评估机制,决定哪些公开可用的网页内容适合被纳入 Apple 的基础模型和大语言模型(LLM)。网站所有者可以通过 robots.txt 指令独立于标准 Applebot 控制其访问权限。
Apple 专门用于评估内容以训练 Apple Intelligence 和生成式 AI 模型的网络爬虫。它作为标准 Applebot 的二级评估机制,决定哪些公开可用的网页内容适合被纳入 Apple 的基础模型和大语言模型(LLM)。网站所有者可以通过 robots.txt 指令独立于标准 Applebot 控制其访问权限。
Applebot-Extended 是由 Apple 运营的专用网络爬虫,扩展了标准 Applebot 的功能,专门为训练 Apple Intelligence 系统收集和评估内容。原始 Applebot 主要服务于 Apple 的搜索和索引需求,而 Applebot-Extended 作为独立的爬虫,专注于收集可用于提升 Apple 生成式 AI 和机器学习模型的高质量内容。该爬虫体现了 Apple 致力于通过系统化识别和处理符合特定质量标准的网页内容,发展先进 AI 训练数据集 的承诺。标准 Applebot 与 Applebot-Extended 之间的区别对于网站所有者来说非常重要,因为两者用途不同,并且可通过 robots.txt 指令独立管理。
Applebot-Extended 在 两级爬取系统 中运行,先由标准 Applebot 进行初步内容发现,然后由 Applebot-Extended 进行二次评估。当 Applebot-Extended 访问网页时,会对内容进行全面的 质量评估,以确定其是否符合 Apple 纳入 AI 训练数据集的标准。该爬虫通过特定的 用户代理字符串 进行身份识别,与标准 Applebot 区分开来,便于网站管理员在服务器日志和分析平台中区分两者。Applebot-Extended 根据多项标准对内容进行评估,包括相关性、准确性、原创性和对确保只有优质内容被纳入 Apple Intelligence 系统的质量准则的遵循情况。
| 功能 | Applebot | Applebot-Extended |
|---|---|---|
| 主要用途 | 常规索引与搜索 | AI 训练数据收集 |
| 内容范围 | 所有网页内容 | 高质量、精选内容 |
| 用户代理 | Applebot | Applebot-Extended |
| 评估深度 | 标准爬取 | 高级质量评估 |
| 屏蔽方式 | robots.txt 指令 | 独立 robots.txt 规则 |

Apple Intelligence 是 Apple 集成的 AI 功能套件,旨在通过本地设备和云端处理提升 iOS、iPadOS、macOS 及其他 Apple 平台上的用户体验。由 Applebot-Extended 数据驱动的生成式 AI 能力包括高级写作工具、图像生成、智能搜索增强和依托 基础模型 与 大语言模型(LLM) 的上下文感知助手功能,这些模型都基于精选网页内容进行训练。这些系统支持如邮件和文档写作工具、Image Playground 创作内容生成和更强大的 Siri 智能理解等功能。Apple 的方法强调隐私保护 AI,大部分智能处理在本地设备完成,而 Applebot-Extended 则确保这些系统的训练数据来自网络上的高质量、多元化来源。该爬虫对内容的精选方式直接影响了 Apple Intelligence 面向全球数百万用户的功能的智能化和可靠性。
Applebot-Extended 针对特定类别的内容,这些内容在 AI 训练上具备高信息价值和可靠性。爬虫优先考虑以下标准的内容:
该爬虫采用先进的 数据过滤机制,去除低质量内容,包括垃圾信息、重复材料及信息价值有限的内容。Apple 实施了 隐私保护评估技术,在不额外存储个人数据或敏感信息的前提下评估内容质量。选择流程包括自动化质量评分系统,评估内容来源的可信度、原创性、事实准确性及其与 Apple Intelligence 训练目标的相关性。网站所有者可通过保持高编辑标准、确保原创与权威内容、避免人为提升内容质量指标的做法,影响其内容被纳入的概率。
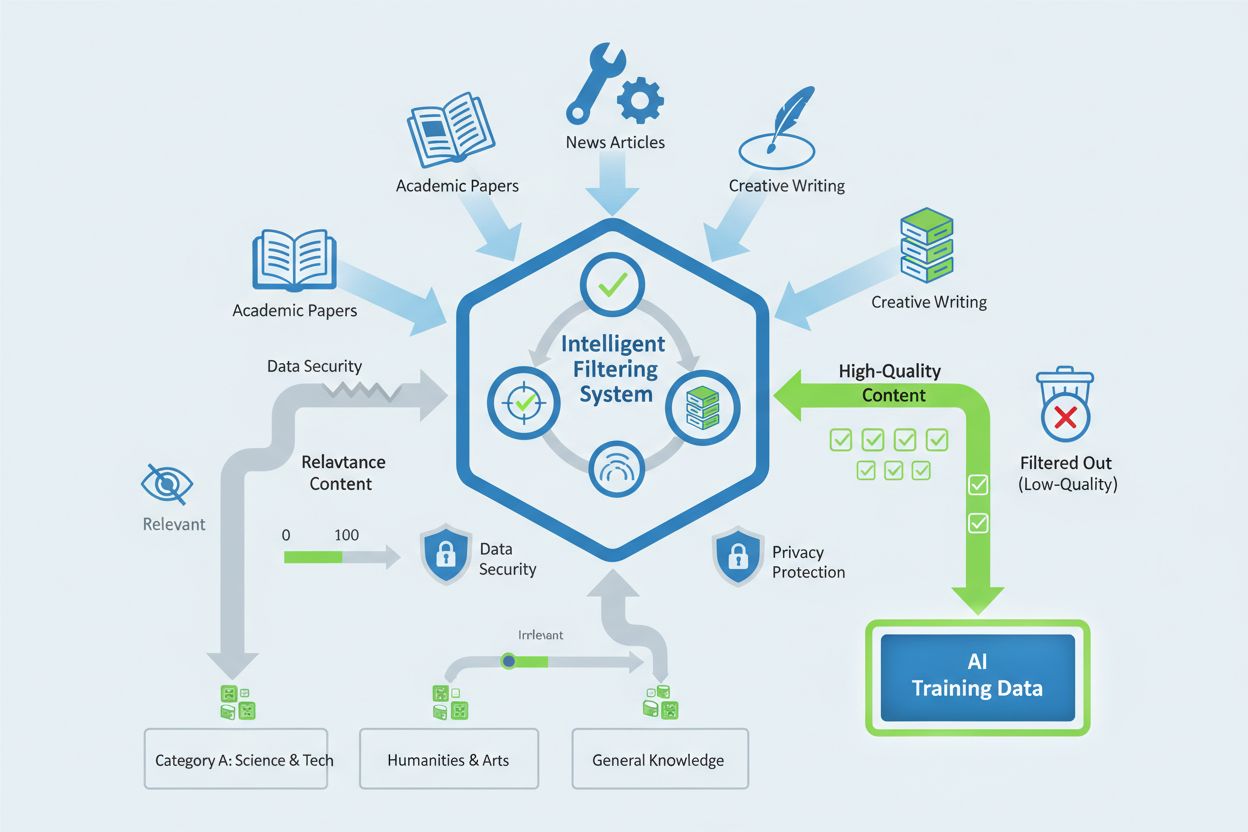
网站管理员可通过 robots.txt 指令 控制 Applebot-Extended 对内容的访问权限,这些指令可独立于标准 Applebot 限制对爬虫行为进行精细化管理。若想仅屏蔽 Applebot-Extended 而允许标准 Applebot 抓取,网站所有者可利用各自的用户代理标识符设置有针对性的规则。需要注意的是,屏蔽标准 Applebot 并不会自动屏蔽 Applebot-Extended,反之亦然——如需不同访问策略,需分别管理。屏蔽 Applebot-Extended 对 SEO 直接影响很小,因为不会影响搜索排名,但会阻止你的内容参与 Apple Intelligence 训练,可能会限制你的网站在 Apple AI 功能和服务中的可见度。
# 仅屏蔽 Applebot-Extended,允许标准 Applebot
User-agent: Applebot-Extended
Disallow: /
# 允许标准 Applebot
User-agent: Applebot
Allow: /
# 同时屏蔽 Applebot 和 Applebot-Extended
User-agent: Applebot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# 屏蔽 Applebot-Extended 访问特定目录
User-agent: Applebot-Extended
Disallow: /private/
Disallow: /admin/
Allow: /public/
Apple 对 Applebot-Extended 的操作始终坚持 隐私优先原则,强调 AI 训练内容收集须遵守全球各地的数据保护法规。公司通过技术和组织措施确保在爬取与评估过程中不会无必要地收集或保存个人数据,内容评估聚焦于信息价值而非个人信息提取。网站所有者和内容创作者保留对其数据的 个人隐私权,包括有权请求内容被如何使用的信息,并根据 GDPR、CCPA 等隐私法行使删除权。Apple 提供了 Apple Intelligence 隐私咨询表格,用户可通过这一正式渠道提交关于内容或个人数据在 Apple Intelligence 系统中处理的疑问、关切或请求。这种结构化的隐私保护方式保障了先进 AI 能力的益处与个人数据保护和用户自主权之间的平衡。
网站所有者可通过监控服务器日志与分析用户代理字符串(其中会显示 “Applebot-Extended”)检测 Applebot-Extended 的访问。如 Dark Visitors 和 UseHall 等专业 分析工具 可增强对 AI 爬虫流量的可视性,帮助管理员追踪 Applebot-Extended 的爬取模式、频率与资源消耗。这些监测方案有助于网站主了解 AI 爬虫对服务器资源及带宽的影响,从而优化爬虫访问策略和性能。通过实施完善的 流量检测与日志机制,管理员能够将 Applebot-Extended 活动与其他爬虫及真人用户行为区分开来,为内容如何参与 Apple AI 训练基础设施提供有价值的洞察。
Applebot-Extended 运行于更广泛的 AI 专用网络爬虫生态系统中,这些爬虫各自服务于不同目的,并遵循其所属公司的数据采集和 AI 开发政策。Googlebot 主要用于 Google 的搜索索引与排名,另有 Googlebot-Extended 专门为 Google 的 AI 系统评估内容,其功能与 Apple 的两级机制类似,但规模更大。Bingbot(微软)同样服务于搜索索引和 Copilot 等生成式 AI 服务的训练,评估标准和隐私框架有所不同。ChatGPT 爬虫(OpenAI 运营)则专注于为大语言模型收集内容,采用明确的退出机制和不同于 Apple 的数据使用协议。与部分竞争对手不同,Applebot-Extended 以 Apple 对本地处理和隐私保护的重视为特色,限制云端数据保留,并通过 robots.txt 和正式隐私咨询流程提供更明确的退出机制。比较来看,尽管各大科技公司均采用 AI 爬虫,但其 评估标准、数据保留政策和用户控制机制 差异显著,反映了各自对 AI 发展、隐私与内容创作者权益的理念不同。网站所有者在决定爬虫访问策略时应了解这些差异,因为每种爬虫对内容在 AI 系统中的使用影响和政策各不相同。
Applebot 是 Apple 主要用于搜索索引及 Spotlight 和 Siri 搜索功能的网络爬虫。Applebot-Extended 是一个次级爬虫,会评估已被 Applebot 索引的内容,用以判断其是否适合用于训练 Apple 的生成式 AI 模型。两者服务于不同目的,并可通过 robots.txt 独立管理。
你可以通过在 robots.txt 文件中添加特定规则来阻止 Applebot-Extended。例如使用 'User-agent: Applebot-Extended' 后跟 'Disallow: /' 可屏蔽整个站点,或指定特定目录。这样可防止你的内容被用于 Apple Intelligence 训练,同时允许标准 Applebot 继续为搜索目的索引网站。
屏蔽 Applebot-Extended 对 SEO 影响很小,因为它不会影响搜索引擎排名。但这样会阻止你的内容参与 Apple Intelligence 训练,未来可能会降低你在 Apple AI 驱动功能和服务中的可见度。
Applebot-Extended 主要面向高质量内容,包括学术文章、技术文档、专业新闻报道、原创写作和专家内容。爬虫会根据可信度、原创性、事实准确性和与 AI 训练目标的相关性等多个标准进行评估。
不会。Apple 明确表示不会在训练 Apple Intelligence 的基础模型时使用用户的私人个人数据或用户交互。公司只使用公开可用的网页内容、授权材料和合成数据。Apple 实施了隐私保护措施以移除训练数据集中的个人信息。
你可以通过监控服务器日志中的 'Applebot-Extended' 用户代理字符串来检测其访问。像 Dark Visitors 和 UseHall 这样的专业分析工具可以增强对 AI 爬虫流量的可见性,让你追踪爬取模式、频率和资源消耗。
Apple Intelligence 是 Apple 融合于 iOS、iPadOS、macOS 等平台的 AI 功能套件。Applebot-Extended 收集高质量网页内容,用于训练支撑 Apple Intelligence 功能(如写作工具、Image Playground 和增强版 Siri)的基础模型和大语言模型。
可以。Apple 提供了 Apple Intelligence 隐私咨询表格,个人可提交关于其内容或个人数据在 Apple Intelligence 系统中处理方式的请求。你也可以通过标准 robots.txt 指令选择退出 Applebot-Extended 的抓取。
了解 Google-Extended,这一用户代理标识让发布者能够控制其内容是否被用于 Gemini 和 Vertex AI 的 AI 训练。了解它与 Googlebot 的区别及如何在 robots.txt 中实现。...

了解 Google-Extended 是什么、如何运作,以及你是否应该在 robots.txt 中屏蔽它。了解 AI 训练控制与 AI 概览之间的区别。

了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.