
Jak identifikovat AI crawlery ve vašich serverových logách
Naučte se identifikovat a monitorovat AI crawlery jako GPTBot, ClaudeBot a PerplexityBot ve vašich serverových logách. Kompletní průvodce s user-agent řetězci, ...
8 min čtení

Zjistěte, jak provést audit přístupu AI crawlerů na váš web. Zjistěte, které boty vidí váš obsah a opravte blokace, které brání AI viditelnosti v ChatGPT, Perplexity a dalších AI vyhledávačích.
Krajina vyhledávání a objevování obsahu se dramaticky mění. S exponenciálním růstem AI vyhledávačů jako ChatGPT, Perplexity či Google AI Overviews je viditelnost vašeho obsahu pro AI crawlery stejně důležitá jako tradiční SEO. Pokud se AI boti nedostanou k vašemu obsahu, váš web se stává neviditelným pro miliony uživatelů, kteří tyto platformy využívají k hledání odpovědí. Rizika jsou větší než kdy dříve: zatímco Google se na váš web může vrátit, když něco selže, AI crawleři fungují jinak—a propásnutí první klíčové návštěvy může znamenat měsíce ztracené viditelnosti a příležitostí k citacím, návštěvnosti i k budování autority značky.
AI crawleři fungují podle zásadně jiných pravidel než Google a Bing boti, na které jste roky optimalizovali. Nejdůležitější rozdíl: AI crawleři nevykreslují JavaScript, takže dynamický obsah načítaný skripty na straně klienta je pro ně neviditelný—na rozdíl od pokročilých možností Google. Navíc AI crawleři stránky navštěvují mnohem častěji, někdy až 100× častěji než tradiční vyhledávače, což přináší nové příležitosti i výzvy pro serverové kapacity. Na rozdíl od Google nemají AI crawleři trvalý index, který by se obnovoval; místo toho procházejí web až v momentě, kdy uživatel zadá dotaz. To znamená, že neexistuje fronta na reindexaci, žádná Search Console k požádání o přecrawlování a žádná druhá šance při špatném prvním dojmu. Porozumění těmto rozdílům je zásadní pro optimalizaci vaší obsahové strategie.
| Funkce | AI crawleři | Tradiční boti |
|---|---|---|
| Vykreslování JavaScriptu | Ne (pouze statické HTML) | Ano (plné vykreslení) |
| Frekvence procházení | Velmi vysoká (100× častěji) | Střední (týdně/měsíčně) |
| Možnost reindexace | Žádná (pouze na vyžádání) | Ano (průběžné aktualizace) |
| Požadavky na obsah | Prosté HTML, schéma | Flexibilní (zvládá dynamický obsah) |
| Blokování podle User-Agent | Specificky na boty (GPTBot, ClaudeBot, apod.) | Obecné (Googlebot, Bingbot) |
| Strategie cachování | Krátkodobé snímky | Dlouhodobá údržba indexu |
Váš obsah může být pro AI crawlery neviditelný z důvodů, které jste nikdy nezvažovali. Zde jsou hlavní překážky, které brání AI botům v přístupu a pochopení vašeho obsahu:
Soubor robots.txt je hlavní nástroj pro řízení, kteří AI boti mohou přistupovat k vašemu obsahu, a funguje pomocí konkrétních pravidel User-Agent, která cílí na jednotlivé crawlery. Každá AI platforma používá vlastní user-agent řetězec—OpenAI GPTBot, Anthropic ClaudeBot, Perplexity PerplexityBot—a každého lze povolit či zablokovat samostatně. Tato detailní kontrola vám umožní rozhodnout, které AI systémy mohou váš obsah trénovat nebo citovat, což je klíčové pro ochranu dat nebo řešení konkurenčních obav. Mnoho webů však AI crawlery nevědomky blokuje příliš obecnými pravidly, určenými pro starší boty, nebo vůbec žádná pravidla neimplementuje.
Ukázka konfigurace robots.txt pro různé AI boty:
# Povolit OpenAI GPTBot
User-agent: GPTBot
Allow: /
# Blokovat Anthropic ClaudeBot
User-agent: ClaudeBot
Disallow: /
# Povolit Perplexity, ale omezit některé složky
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Výchozí pravidlo pro ostatní boty
User-agent: *
Allow: /
Na rozdíl od Google, který váš web průběžně prochází a reindexuje, AI crawleři fungují na principu první návštěvy—přijdou ve chvíli, kdy uživatel položí dotaz, a pokud váš obsah v tu chvíli není dostupný, příležitost je ztracena. Tento zásadní rozdíl znamená, že web musí být technicky připraven od prvního dne; není zde žádné přechodné období ani druhá šance na opravu před propadem viditelnosti. Špatná zkušenost při prvním crawlu—kvůli problémům s JavaScriptem, chybějícímu schématu nebo chybám serveru—může znamenat vyloučení vašeho obsahu z AI odpovědí na týdny či měsíce. Neexistuje manuální možnost reindexace, žádné tlačítko „Požádat o indexaci“ v konzoli, proto je proaktivní monitoring a optimalizace naprostou nutností. Tlak na to „zvládnout to správně hned napoprvé“ nikdy nebyl větší.
Spoléhat se na plánované crawly pro monitoring přístupu AI crawlerů je jako kontrolovat dům na požár jednou měsíčně—kritické chvíle, kdy nastane problém, vám uniknou. Monitoring v reálném čase odhalí problémy ve chvíli, kdy nastanou, takže můžete reagovat dříve, než se váš obsah stane pro AI systémy neviditelným. Plánované audity, prováděné týdně či měsíčně, vytvářejí nebezpečná „slepá místa“, kdy může váš web AI crawlerům selhávat celé dny bez vašeho vědomí. Řešení v reálném čase sledují chování crawlerů nepřetržitě a upozorní vás na selhání JavaScriptu, chyby schématu, blokace firewallu či serverové chyby okamžitě. Tento proaktivní přístup proměňuje audit z reaktivní kontroly v aktivní správu viditelnosti. S tím, že AI crawlerů je až 100× více než tradičních vyhledávačů, může být cena za několik hodin ztracené přístupnosti značná.
Existuje několik platforem, které nabízejí specializované nástroje pro monitoring a optimalizaci přístupu AI crawlerů. Cloudflare AI Crawl Control poskytuje správu AI botů na úrovni infrastruktury s možností limitů a zásad přístupu. Conductor nabízí komplexní dashboardy sledující interakce různých AI crawlerů s vaším obsahem. Elementive se zaměřuje na technické SEO audity s důrazem na AI crawlery. AdAmigo a MRS Digital poskytují specializované poradenství a monitoring pro AI viditelnost. Pro nepřetržitý monitoring v reálném čase však AmICited patří mezi špičku. AmICited se specializuje na sledování, které AI systémy přistupují k vašemu obsahu, jak často crawlery chodí a zda narážejí na technické překážky. Tento důraz na chování AI crawlerů—nikoliv tradiční SEO metriky—dělá z AmICited klíčový nástroj pro firmy, kterým záleží na AI viditelnosti.
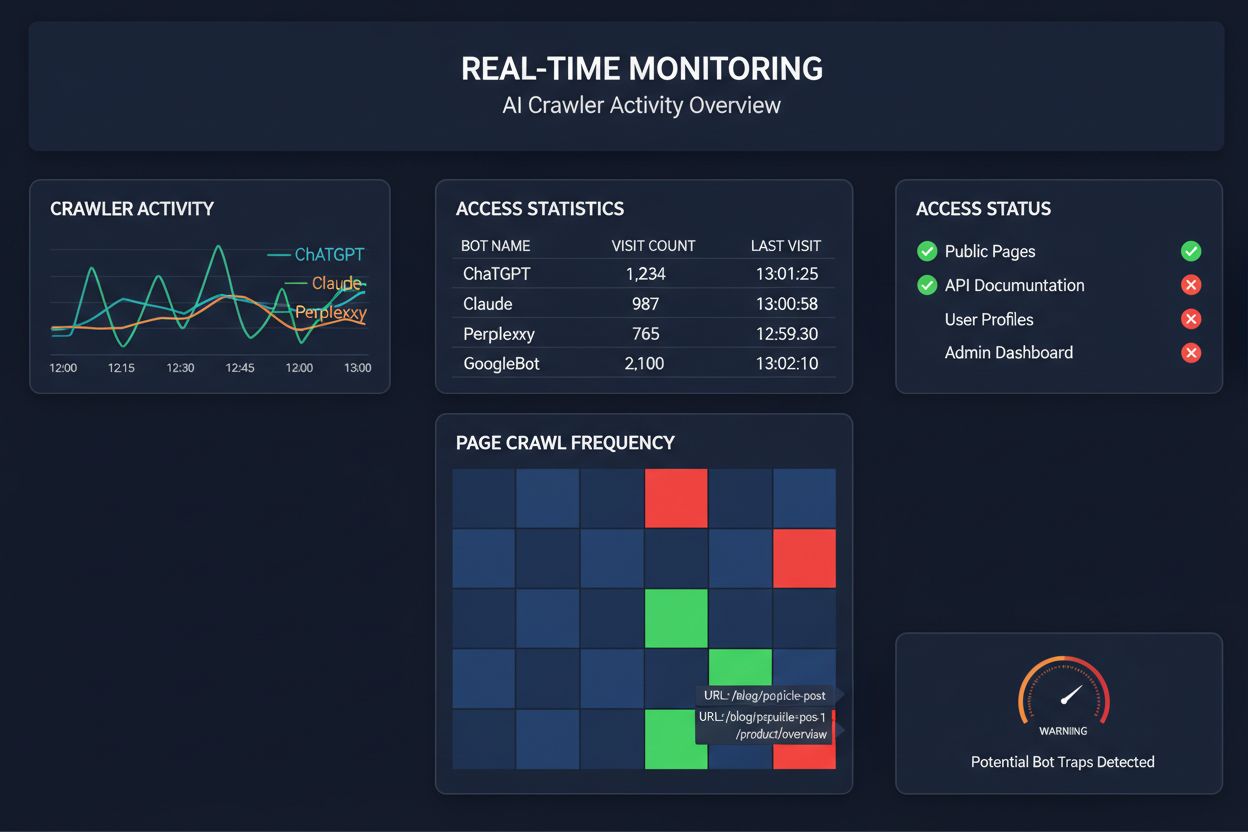
Důkladný audit AI crawlerů vyžaduje systematický přístup. Krok 1: Nastavte výchozí stav kontrolou aktuálního robots.txt a zjištěním, které AI boty povolujete nebo blokujete. Krok 2: Proveďte audit technické infrastruktury testováním přístupnosti vašeho webu pro crawlery bez JavaScriptu, ověřte rychlost serveru a ujistěte se, že klíčový obsah je ve statickém HTML. Krok 3: Implementujte a ověřte schéma napříč obsahem—ověřte, že autorství, datum publikace, typ obsahu a další metadata jsou správně strukturovaná v JSON-LD. Krok 4: Sledujte chování crawlerů pomocí nástrojů jako AmICited, které vám ukážou, kteří AI boti navštěvují váš web, jak často a zda narážejí na chyby. Krok 5: Analyzujte výsledky revizí logů, identifikací vzorců selhání a prioritizací oprav podle dopadu. Krok 6: Proveďte opravy počínaje nejzásadnějšími problémy (JavaScript, schéma), následně sekundární optimalizace. Krok 7: Zaveďte průběžný monitoring s upozorněními na selhání crawlu či blokace.
Není nutné kompletně předělávat web, abyste zlepšili přístup AI crawlerů—několik zásadních změn lze provést rychle. Zásadní obsah servírujte v čistém HTML místo spoléhání na JavaScript; pokud musíte použít JavaScript, zajistěte, aby důležitý text a metadata byly součástí původního HTML. Přidejte komplexní schéma v JSON-LD: článek, autor, datum publikace, vztahy obsahu—pomáhá AI crawlerům pochopit kontext a správně přiřadit zdroj. Zajistěte jasné informace o autorství ve schématu i v bylinech, protože AI systémy stále více upřednostňují citace autoritativních zdrojů. Sledujte a optimalizujte Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), protože pomalu se načítající stránky crawlerům často utečou. Zkontrolujte a aktualizujte robots.txt, abyste omylem neblokovali AI boty, které chcete vpustit. Opravte technické chyby jako přesměrování, rozbité odkazy a serverové chyby, které mohou způsobit, že crawleři web během procházení opustí.
Ne všichni AI crawleři mají stejný účel a pochopení těchto rozdílů vám pomůže lépe nastavovat pravidla přístupu. GPTBot (OpenAI) slouží hlavně pro sběr trénovacích dat a zlepšování modelu, takže je důležitý, pokud chcete, aby váš obsah ovlivnil odpovědi ChatGPT. OAI-SearchBot (OpenAI) je určen speciálně pro citování ve vyhledávání, tedy zahrnuje váš obsah do výsledků ChatGPT s integrovaným vyhledáváním. ClaudeBot (Anthropic) má podobnou roli pro asistenta Claude. PerplexityBot (Perplexity) prochází web pro citace ve vyhledávači Perplexity, který je pro mnohé vydavatele významným zdrojem návštěvnosti. Každý bot má jiné vzorce procházení, frekvenci i účel—některé sbírají trénovací data, jiné slouží pro citace v reálném čase. Rozhodnutí, které boty povolit nebo blokovat, by mělo odpovídat vaší obsahové strategii: chcete-li být citováni ve výsledcích AI vyhledávání, povolte vyhledávací boty; pokud vám vadí použití obsahu pro trénování, můžete blokovat „datové“ boty a povolit pouze ty pro vyhledávání. Tento promyšlený přístup je mnohem efektivnější než tradiční „povolit vše“ nebo „blokovat vše“.
Audit AI crawlerů je komplexní posouzení přístupnosti vašeho webu pro AI boty jako ChatGPT, Claude a Perplexity. Identifikuje technické překážky, problémy s vykreslením JavaScriptu, chybějící schéma a další faktory, které brání AI crawlerům v přístupu a pochopení vašeho obsahu. Audit poskytuje konkrétní doporučení pro zlepšení vaší viditelnosti v AI vyhledávání a odpovědních enginách.
Doporučujeme provádět komplexní audit alespoň čtvrtletně, nebo kdykoliv provedete zásadní změny v technické infrastruktuře webu, struktuře obsahu nebo souboru robots.txt. Ideální je však průběžné monitorování v reálném čase, které umožní okamžitě zachytit problémy při jejich vzniku. Mnoho organizací používá automatizované nástroje, které je v reálném čase upozorní na selhání procházení, a to doplňují čtvrtletními hloubkovými audity.
Povolení AI crawlerů znamená, že váš obsah může být přístupný, analyzovaný a případně citovaný AI systémy, což může zvýšit vaši viditelnost v AI generovaných odpovědích a doporučeních. Blokování AI crawlerů jim brání v přístupu k vašemu obsahu, chrání citlivé informace, ale může snížit vaši viditelnost ve výsledcích AI vyhledávání. Správné rozhodnutí závisí na vašich obchodních cílech, citlivosti obsahu a konkurenčním postavení.
Ano, rozhodně. Soubor robots.txt umožňuje detailní kontrolu pomocí pravidel User-Agent. Můžete blokovat GPTBot a zároveň povolit PerplexityBot, nebo například povolit bota zaměřeného na vyhledávání (OAI-SearchBot) a blokovat bota pro sběr dat (GPTBot). Tento promyšlený přístup vám umožní optimalizovat obsahovou strategii podle toho, na kterých AI platformách vám záleží.
Pokud AI crawleři nemohou přistupovat k vašemu obsahu, znamená to, že váš web je pro AI vyhledávače a odpovědní platformy fakticky neviditelný. Váš obsah nebude citován, doporučován ani zahrnut do AI generovaných odpovědí, i když je velmi relevantní. To může vést ke ztrátě návštěvnosti, snížení viditelnosti značky a promarněným příležitostem k budování autority ve výsledcích AI vyhledávání.
Můžete zkontrolovat serverové logy na User-Agent řetězce známých AI crawlerů (GPTBot, ClaudeBot, PerplexityBot apod.), nebo použít specializované monitorovací nástroje jako AmICited, které sledují aktivitu AI crawlerů v reálném čase. Tyto nástroje vám ukážou, které boty přistupují na váš web, jak často procházejí, které stránky navštěvují a zda narážejí na chyby nebo blokace.
Záleží na vaší konkrétní situaci. Pokud je váš obsah proprietární, citlivý, nebo máte obavy z využití dat pro trénování modelů, blokování může být vhodné. Pokud však chcete být viditelní ve výsledcích AI vyhledávání a být citováni AI systémy, je povolení crawlerů zásadní. Mnoho organizací volí kompromis: povolují boty zaměřené na vyhledávání, které přinášejí citace, a blokují boty pro sběr dat.
AI crawleři nevykreslují JavaScript, což znamená, že jakýkoliv obsah načítaný dynamicky pomocí skriptů na straně klienta je pro ně neviditelný. Pokud váš web výrazně spoléhá na JavaScript pro klíčový obsah, navigaci nebo strukturovaná data, AI crawleři uvidí pouze syrové HTML a přijdou o důležité informace. To může zásadně ovlivnit, jak je váš obsah pochopen a prezentován v AI odpovědích. Zásadní je poskytovat klíčový obsah ve statickém HTML pro zajištění crawlability AI.
Získejte přehled v reálném čase o tom, které AI boty přistupují k vašemu obsahu a jak váš web vidí. Začněte dnes zdarma audit a zajistěte, že vaše značka bude viditelná napříč všemi AI vyhledávacími platformami.
Naučte se identifikovat a monitorovat AI crawlery jako GPTBot, ClaudeBot a PerplexityBot ve vašich serverových logách. Kompletní průvodce s user-agent řetězci, ...

Naučte se, jak blokovat nebo povolovat AI crawlery jako GPTBot a ClaudeBot pomocí robots.txt, blokování na úrovni serveru a pokročilých metod ochrany. Kompletní...

Zjistěte, jak otestovat, zda mají AI crawlery jako ChatGPT, Claude a Perplexity přístup k obsahu vašeho webu. Objevte testovací metody, nástroje a osvědčené pos...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.