
Měli byste blokovat nebo povolit AI crawlery? Rozhodovací rámec
Naučte se, jak strategicky rozhodovat o blokování AI crawlerů. Vyhodnoťte typ obsahu, zdroje návštěvnosti, modely příjmů a konkurenční pozici pomocí našeho komp...
10 min čtení

Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhledávání AI.
AI crawleři jsou automatizované programy určené k systematickému procházení internetu a sběru dat z webových stránek, konkrétně pro trénink a vylepšování modelů umělé inteligence. Na rozdíl od tradičních crawlerů vyhledávačů, jako je Googlebot, kteří indexují obsah pro výsledky vyhledávání, AI crawleři sbírají surová webová data pro velké jazykové modely (LLM) jako ChatGPT, Claude a další AI systémy. Tito boti nepřetržitě operují na milionech webů, stahují stránky, analyzují obsah a extrahují informace, které pomáhají AI platformám porozumět jazykovým vzorcům, faktickým informacím a různým stylům psaní. Mezi hlavní hráče v této oblasti patří GPTBot od OpenAI, ClaudeBot od Anthropic, Meta-ExternalAgent od Meta, Amazonbot od Amazonu a PerplexityBot od Perplexity.ai, kteří slouží potřebám tréninku a provozu svých AI platforem. Pochopení toho, jak tito crawleři fungují, je nyní pro majitele webů a tvůrce obsahu zásadní, protože viditelnost v AI má přímý vliv na to, jak se vaše značka objevuje ve výsledcích a doporučeních vyhledávání poháněných AI.
Prostředí webového crawlování prošlo za poslední rok dramatickou proměnou: AI crawleři zažívají explozivní růst, zatímco tradiční crawleři vyhledávačů si drží stabilní vzorce. Mezi květnem 2024 a květnem 2025 vzrostl celkový provoz crawlerů o 18 %, ale jeho rozložení se výrazně změnilo—GPTBot vystřelil o 305 % v počtu požadavků, zatímco například ClaudeBot poklesl o 46 % a Bytespider propadl o 85 %. Toto přeskupení odráží rostoucí konkurenci mezi AI společnostmi o zajištění tréninkových dat a vylepšování modelů. Zde je podrobný přehled hlavních crawlerů a jejich aktuální pozice na trhu:
| Název crawleru | Společnost | Počet měsíčních požadavků | Meziroční růst | Hlavní účel |
|---|---|---|---|---|
| Googlebot | 4,5 miliardy | 96 % | Indexace vyhledávání & AI Overviews | |
| GPTBot | OpenAI | 569 milionů | 305 % | Trénink modelů ChatGPT & vyhledávání |
| Claude | Anthropic | 370 milionů | -46 % | Trénink modelů Claude & vyhledávání |
| Bingbot | Microsoft | ~450 milionů | 2 % | Indexace vyhledávání |
| PerplexityBot | Perplexity.ai | 24,4 milionu | 157 490 % | Indexace AI vyhledávání |
| Meta-ExternalAgent | Meta | ~380 milionů | Nový | Trénink Meta AI |
| Amazonbot | Amazon | ~210 milionů | -35 % | Vyhledávání & AI aplikace |
Data ukazují, že zatímco Googlebot si udržuje dominanci s 4,5 miliardy měsíčních požadavků, AI crawleři dohromady představují přibližně 28 % objemu Googlebotu, což z nich činí významnou sílu v internetovém provozu. Explozivní růst PerplexityBotu (nárůst o 157 490 %) ukazuje, jak rychle nové AI platformy škálují své crawlingové operace, zatímco pokles některých zavedených AI crawlerů naznačuje konsolidaci trhu okolo nejúspěšnějších AI platforem.
GPTBot je crawler společnosti OpenAI, speciálně navržený pro sběr dat k tréninku a vylepšování ChatGPT a dalších modelů OpenAI. Zatímco při svém spuštění měl v květnu 2024 pouze 5% podíl na trhu, do května 2025 se stal dominantním AI crawlerem s 30% podílem na veškerém AI crawler provozu—což představuje pozoruhodný nárůst o 305 % v počtu požadavků. Tento explozivní růst odráží agresivní strategii OpenAI zajistit, aby ChatGPT měl přístup k čerstvému a rozmanitému webovému obsahu jak pro trénink modelů, tak pro vyhledávací funkce v reálném čase prostřednictvím ChatGPT Search. GPTBot funguje podle specifického vzoru, upřednostňuje HTML obsah (57,70 % požadavků), zároveň stahuje soubory JavaScript a obrázky, ale JavaScript nespouští pro vykreslení dynamického obsahu. Chování crawleru ukazuje, že často naráží na chyby 404 (34,82 % požadavků), což naznačuje, že může sledovat zastaralé odkazy nebo se pokouší o přístup ke zdrojům, které již neexistují. Pro majitele webů znamená dominance GPTBota nutnost zajistit, aby byl váš obsah tomuto crawleru přístupný, což je zásadní pro viditelnost ve vyhledávání ChatGPT a případné zařazení do budoucího tréninku modelů.
ClaudeBot, vyvinutý společností Anthropic, je hlavní crawler pro trénink a aktualizace asistenta Claude AI a podporuje také vyhledávací a zakotvovací schopnosti modelu Claude. Zatímco v květnu 2024 byl druhým největším AI crawlerem s 27% podílem na trhu, do května 2025 zažil pokles na 21 %, přičemž počet požadavků klesl meziročně o 46 %. Tento pokles nemusí nutně znamenat problém ve strategii Anthropicu, ale spíše odráží celkové přesuny trhu směrem k dominanci OpenAI a nástupu nových konkurentů, například Meta-ExternalAgent. ClaudeBot vykazuje podobné chování jako GPTBot, upřednostňuje HTML obsah, ale věnuje vyšší procento požadavků obrázkům (35,17 %), což naznačuje, že Anthropic může trénovat Claude i na lepší porozumění vizuálnímu obsahu. Stejně jako ostatní AI crawleři ClaudeBot nespouští JavaScript, takže vidí pouze syrový HTML bez dynamicky načítaného obsahu. Pro tvůrce obsahu zůstává udržování viditelnosti s ClaudeBot důležité, aby mohl Claude přistupovat k vašemu obsahu a citovat jej, zvláště s tím, jak Anthropic dále rozvíjí schopnosti vyhledávání a uvažování modelu Claude.
Kromě GPTBota a ClaudeBota aktivně sbírají webová data pro své platformy i další významní AI crawleři:
Meta-ExternalAgent (Meta): Tento crawler společnosti Meta zaznamenal prudký vstup mezi elitní crawlery, když do května 2025 získal 19% podíl na trhu jako nováček. Shromažďuje data pro AI iniciativy společnosti Meta, včetně možného tréninku Meta AI a integrace s AI funkcemi Instagramu a Facebooku. Rychlý růst Meta naznačuje, že firma výrazně investuje do vyhledávání a doporučování poháněných AI.
PerplexityBot (Perplexity.ai): Přestože má pouze 0,2% podíl na trhu, PerplexityBot dosáhl největšího růstu—meziročně o 157 490 %. To odráží rychlé škálování Perplexity jako AI answer engine, který spoléhá na vyhledávání v reálném čase pro zakotvení svých odpovědí. Pro weby znamenají návštěvy PerplexityBot přímou příležitost být citován v AI generovaných odpovědích této platformy.
Amazonbot (Amazon): Crawler Amazonu klesl z 21 % na 11 % podílu na trhu, přičemž počet požadavků se meziročně snížil o 35 %. Amazonbot sbírá data pro vyhledávání a AI aplikace Amazonu, ale jeho klesající podíl naznačuje, že Amazon může měnit svou AI strategii nebo konsolidovat crawlingové operace.
Applebot (Apple): Applebot zažil pokles požadavků o 26 %, z 1,9 % na 1,2 % podílu na trhu. Primárně slouží Siri a vyhledávání Spotlight, ale může podporovat i vznikající AI iniciativy Applu. Na rozdíl od většiny AI crawlerů umí Applebot vykreslovat JavaScript, což mu dává podobné možnosti jako Googlebot.
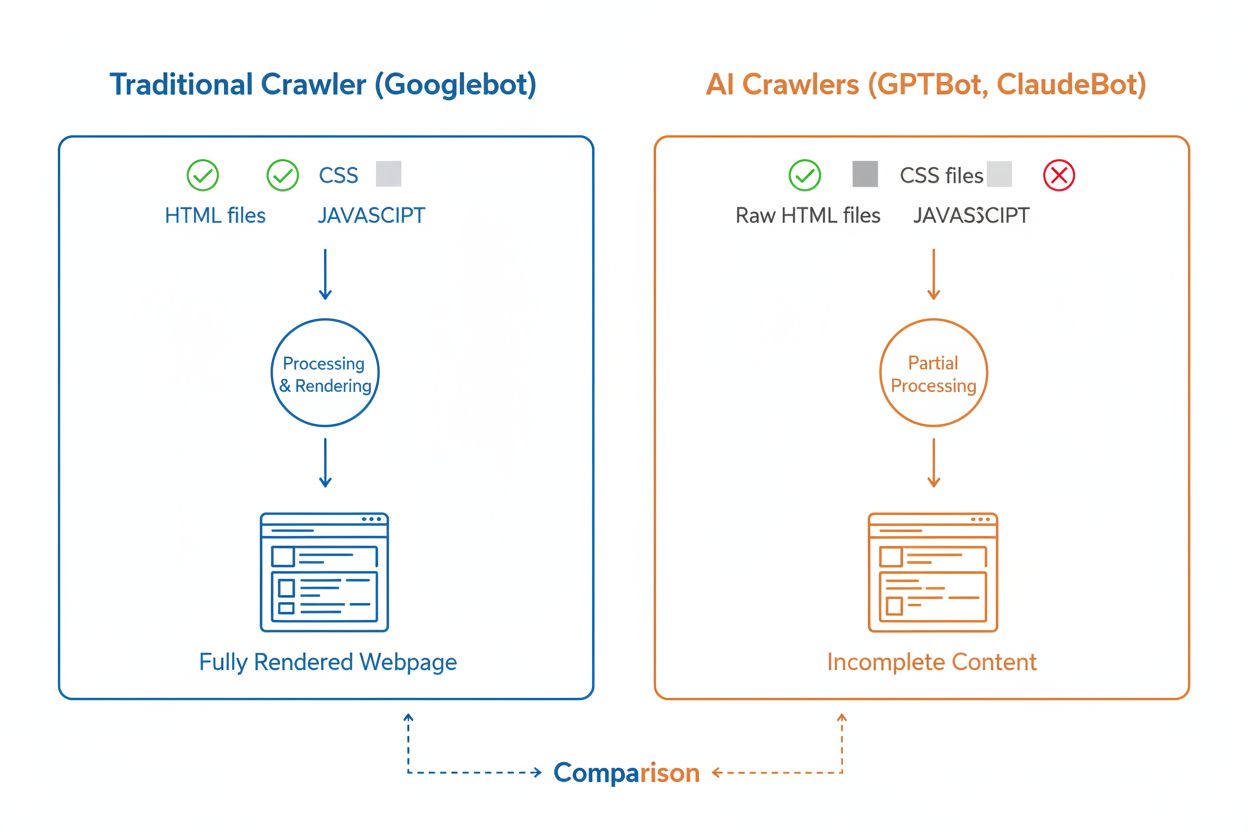
I když AI crawleři i tradiční crawleři vyhledávačů jako Googlebot systematicky procházejí web, jejich technické možnosti a chování se výrazně liší, což přímo ovlivňuje, jak je váš obsah objeven a pochopen. Nejzásadnějším rozdílem je vykreslování JavaScriptu: Googlebot dokáže po stažení stránky spustit JavaScript a vidí tak i dynamicky načítaný obsah, zatímco většina AI crawlerů (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) čte pouze syrový HTML a jakýkoli obsah závislý na JavaScriptu ignoruje. To znamená, že pokud váš web zobrazuje klíčové informace až na straně uživatele pomocí client-side renderingu, AI crawleři uvidí neúplnou verzi vašich stránek. Dále AI crawleři vykazují méně předvídatelné vzorce crawlování než systematický přístup Googlebotu—věnují 34,82 % požadavků stránkám s chybou 404 a 14,36 % přesměrováním, zatímco Googlebot je efektivnější s 8,22 % na 404 a 1,49 % na přesměrování. Liší se také frekvence crawlů: Googlebot navštěvuje stránky podle promyšleného systému crawl budgetu, zatímco AI crawleři zřejmě crawlí častěji, ale méně systematicky—a podle výzkumu mohou některé stránky navštívit i více než 100× častěji než Google. Tyto rozdíly znamenají, že tradiční SEO postupy nemusí stačit pro AI crawlery a je třeba zaměřit se na server-side rendering a čistou strukturu URL.
Jednou z nejvýznamnějších technických překážek AI crawlerů je jejich neschopnost vykreslovat JavaScript, což je dáno vysokými výpočetními náklady na spouštění JavaScriptu v masovém měřítku potřebném pro trénink velkých jazykových modelů. Když crawler stáhne vaši stránku, obdrží pouze počáteční HTML, ale veškerý obsah, který je načítán nebo měněn JavaScriptem—například informace o produktech, ceny, uživatelské recenze nebo dynamické navigační prvky—zůstává AI crawlerům neviditelný. To je zásadní problém pro moderní weby, které silně spoléhají na client-side rendering frameworky jako React, Vue nebo Angular bez server-side renderingu (SSR) nebo generování statických stránek (SSG). Například e-shop, který načítá informace o produktech přes JavaScript, se AI crawlerům jeví jako prázdná stránka bez detailů produktů, což znemožňuje AI systémům tento obsah pochopit či citovat. Řešením je zajistit, aby veškerý klíčový obsah byl předán již v počátečním HTML prostřednictvím server-side renderingu, tedy generováním kompletního HTML na serveru před odesláním do prohlížeče. Tím docílíte, že jak lidští návštěvníci, tak AI crawleři obdrží stejný obsahově bohatý zážitek. Weby využívající moderní frameworky jako Next.js se SSR, generátory statických stránek jako Hugo nebo Gatsby, případně tradiční serverové platformy jako WordPress jsou pro AI crawlery přirozeně přístupné, zatímco weby založené výhradně na client-side renderingu čelí zásadním problémům s viditelností ve vyhledávání AI.
AI crawleři vykazují specifické vzorce frekvence procházení, které se od chování Googlebotu zásadně liší a mají důsledky pro to, jak rychle se váš obsah dostane do AI systémů. Výzkumy ukazují, že AI crawleři jako ChatGPT a Perplexity často navštěvují stránky krátce po publikaci častěji než Google—a někdy až 8× častěji v prvních dnech. Tento rychlý úvodní crawl naznačuje, že AI platformy dávají prioritu rychlému objevení a indexování nového obsahu, aby jejich modely a vyhledávací funkce měly přístup k nejnovějším informacím. Agresivní úvodní crawl je však následován vzorcem, kdy se AI crawleři nemusí vracet, pokud obsah nesplňuje kvalitativní standardy, takže první dojem je naprosto klíčový. Na rozdíl od Googlebotu, který pravidelně navštěvuje stránky na základě frekvence aktualizací a důležitosti, AI crawleři jako by učinili rozhodnutí, zda má smysl se na stránku vracet. Pokud AI crawler při návštěvě stránky najde nekvalitní obsah, technické chyby nebo špatné uživatelské signály, může trvat dlouho, než se vrátí—nebo se už nevrátí vůbec. Z toho plyne jasný závěr pro tvůrce obsahu: nemůžete spoléhat na druhou šanci optimalizovat obsah pro AI crawlery tak, jako je to možné u tradičních vyhledávačů, a je nezbytné klást důraz na kvalitu ještě před publikací.
Majitelé webů mohou využít soubor robots.txt k vyjádření svých preferencí ohledně přístupu AI crawlerů, avšak účinnost a vynutitelnost těchto pravidel se mezi jednotlivými crawlery výrazně liší. Podle nedávných dat má přibližně 14 % z top 10 000 webů v robots.txt specifická pravidla pro povolení nebo zákaz přístupu AI botům. GPTBot je nejčastěji blokovaný crawler—312 domén (250 plně, 62 částečně) mu výslovně zakazuje přístup, ale zároveň je i nejčastěji explicitně povoleným crawlerem se 61 doménami, které jej výslovně povolují. Mezi další často blokované crawlery patří CCBot (Common Crawl) a Google-Extended (AI token Google). Problém s robots.txt spočívá v tom, že jeho dodržování je dobrovolné—crawleři pravidla respektují jen pokud jejich provozovatelé tuto funkcionalitu zavedou, přičemž někteří noví nebo méně transparentní crawleři nemusí direktivy robots.txt dodržovat vůbec. Navíc direktivy jako “Google-Extended” neodpovídají přímo uživatelským agentům (user-agent) ve HTTP požadavcích; místo toho signalizují účel crawlování a nelze vždy ověřit jejich dodržování v serverových logách. Pro silnější kontrolu proto stále více majitelů webů využívá firewall pravidla a Web Application Firewally (WAF), které umožňují aktivní blokování konkrétních user-agentů crawlerů a poskytují spolehlivější ochranu než samotný robots.txt. Tento posun směrem k aktivním blokovacím mechanismům odráží rostoucí důraz na práva k obsahu a potřebu vynutitelné kontroly nad přístupem AI crawlerů.
Sledování aktivity AI crawlerů na vašem webu je zásadní pro pochopení vaší viditelnosti ve vyhledávání AI, avšak přináší specifické výzvy oproti monitoringu tradičních vyhledávačů. Tradiční analytické nástroje jako Google Analytics spoléhají na JavaScript, který AI crawleři nespouštějí, takže tyto nástroje neposkytují žádný přehled o návštěvách AI botů. Obdobně nefunguje ani pixelové sledování, protože většina AI crawlerů zpracovává pouze text a obrázky ignoruje. Jediným spolehlivým způsobem, jak sledovat aktivitu AI crawlerů, je monitorování na straně serveru—analýza HTTP hlaviček požadavků a serverových logů pro identifikaci user-agentů crawlerů ještě před odesláním stránky. To vyžaduje buď manuální analýzu logů, nebo specializované nástroje určené přímo ke sledování AI trafficu. Monitoring v reálném čase je zvlášť důležitý, protože AI crawleři fungují v nepředvídatelných intervalech a nemusí se na stránky vracet, pokud narazí na problém, takže týdenní nebo měsíční audit může důležité chyby minout. Pokud AI crawler navštíví váš web a narazí na technickou chybu či nekvalitní obsah, nemusíte dostat další šanci udělat dobrý dojem. Zavedení 24/7 monitorovacích řešení, která vás okamžitě upozorní na chyby AI crawlerů—například 404, pomalé načítání stránek nebo chybějící schéma—vám umožňuje řešit problémy dříve, než ovlivní vaši viditelnost ve vyhledávání AI. Tento přístup v reálném čase znamená zásadní změnu oproti tradičnímu SEO monitoringu a odráží rychlost a nepředvídatelnost chování AI crawlerů.
Optimalizace webu pro AI crawlery vyžaduje odlišný přístup než tradiční SEO a zaměřuje se na technické faktory, které přímo ovlivňují, jak mohou AI systémy přistupovat k vašemu obsahu a rozumět mu. První prioritou je server-side rendering: zajistěte, aby veškerý klíčový obsah—nadpisy, hlavní text, metadata, strukturovaná data—byl zahrnut již v počátečním HTML místo dynamického načítání přes JavaScript. To platí pro domovskou stránku, klíčové landing pages i jakýkoli obsah, který chcete, aby AI systémy citovaly nebo odkazovaly. Dále implementujte strukturovaná data (Schema.org) na svých důležitých stránkách—včetně schématu článku pro blogy, produktového schématu pro e-shopy a schématu autora pro budování odbornosti a autority. AI crawleři využívají strukturovaná data pro rychlé pochopení hierarchie a kontextu obsahu, což jim výrazně usnadňuje jeho zpracování a citování. Třetím krokem je udržovat vysoký standard kvality obsahu napříč všemi stránkami, protože AI crawleři zřejmě rychle rozhodují, zda má smysl obsah indexovat a citovat. To znamená, že obsah musí být originální, dobře zpracovaný, fakticky správný a přinášet čtenářům skutečnou hodnotu. Dále sledujte a optimalizujte Core Web Vitals a celkový výkon stránek, protože pomalé načítání signalizuje špatný uživatelský zážitek a může AI crawlery odradit od opětovné návštěvy. Nakonec udržujte čistou a konzistentní strukturu URL, aktuální XML sitemapu a správně nakonfigurovaný robots.txt, který navede crawlery k vašemu nejdůležitějšímu obsahu. Tyto technické optimalizace vytváří základ, díky kterému je váš obsah pro AI systémy nalezitelný, srozumitelný a citovatelný.
Prostředí AI crawlerů se bude i nadále rychle vyvíjet s tím, jak sílí konkurence mezi AI společnostmi a technologie dozrává. Jasným trendem je konsolidace podílu na trhu okolo nejúspěšnějších platforem—GPTBot od OpenAI se stal dominantní silou, zatímco noví hráči jako Meta-ExternalAgent rychle škálují, což naznačuje, že trh se pravděpodobně ustálí okolo několika klíčových hráčů. S dozráváním AI crawlerů lze očekávat zlepšení jejich technických schopností, zejména v oblasti vykreslování JavaScriptu a efektivnějších vzorců crawlování, které sníží počet zbytečných požadavků na 404 stránky a zastaralý obsah. Odvětví zároveň směřuje k větší standardizaci komunikace, například prostřednictvím vznikajícího standardu llms.txt, který umožní webům explicitně sdělovat svou strukturu a preference crawlování AI systémům. Kromě toho se zpřísňují také mechanismy pro kontrolu přístupu AI crawlerů—například platformy typu Cloudflare nyní nabízejí automatické blokování AI botů pro trénink ve výchozím nastavení, což dává majitelům webů detailnější kontrolu nad svým obsahem. Pro tvůrce obsahu a majitele webů to znamená nutnost neustále sledovat aktivitu AI crawlerů, udržovat technickou infrastrukturu v souladu s požadavky AI a přizpůsobovat obsahovou strategii realitě, že AI systémy dnes představují významnou část návštěvnosti webu a klíčový kanál pro zviditelnění značky. Budoucnost patří těm, kteří porozumí a optimalizují pro tento nový crawler ekosystém.
AI crawleři jsou automatizované programy, které sbírají webová data specificky pro trénink a vylepšování modelů umělé inteligence jako ChatGPT a Claude. Na rozdíl od tradičních crawlerů vyhledávačů, jako je Googlebot, které indexují obsah pro výsledky vyhledávání, AI crawleři shromažďují surová webová data pro velké jazykové modely. Oba typy crawlerů systematicky procházejí internet, ale slouží jiným účelům a mají jiné technické možnosti.
AI crawleři přistupují na váš web, aby sbírali data pro trénink AI modelů, vylepšovali vyhledávací funkce a zakotvili odpovědi AI v aktuálních informacích. Když AI systémy jako ChatGPT nebo Perplexity odpovídají na dotazy uživatelů, často potřebují v reálném čase získat váš obsah, aby poskytly přesné a citované informace. Umožněním přístupu AI crawlerům zvyšujete šanci, že vaše značka bude zmiňována a citována v odpovědích generovaných AI.
Ano, můžete použít soubor robots.txt k zamezení konkrétním AI crawlerům tím, že určíte jejich user-agent jména. Dodržování robots.txt je však dobrovolné a ne všichni crawleři tato pravidla respektují. Pro silnější vynucení můžete použít firewall pravidla a webové aplikační firewally (WAF) k aktivnímu blokování konkrétních user-agent crawlerů. To vám dává spolehlivější kontrolu nad tím, kteří AI crawleři mohou přistupovat k vašemu obsahu.
Ne, většina AI crawlerů (GPTBot, ClaudeBot, Meta-ExternalAgent) JavaScript nespouští. Čtou pouze syrový HTML vašich stránek, což znamená, že veškerý obsah načítaný dynamicky pomocí JavaScriptu je pro ně neviditelný. Proto je server-side rendering pro AI crawlery zásadní. Pokud váš web spoléhá na client-side rendering, AI crawleři uvidí neúplnou verzi vašich stránek.
AI crawleři navštěvují weby v krátkodobém horizontu po publikaci obsahu častěji než tradiční vyhledávače. Výzkum ukazuje, že mohou stránky navštívit 8–100× častěji než Google v prvních dnech. Pokud však obsah nesplňuje kvalitativní standardy, nemusí se vrátit. První dojem je proto zásadní—nemusíte mít druhou šanci optimalizovat obsah pro AI crawlery.
Klíčové optimalizace jsou: (1) Používejte server-side rendering, aby byl důležitý obsah již v počátečním HTML, (2) Přidejte strukturovaná data (Schema), která pomohou AI porozumět vašemu obsahu, (3) Udržujte vysokou kvalitu a aktuálnost obsahu, (4) Sledujte Core Web Vitals pro dobrý uživatelský zážitek a (5) Mějte čistou strukturu URL a aktuální sitemapu. Tyto technické optimalizace tvoří základ pro to, aby byl váš obsah pro AI systémy nalezitelný a citovatelný.
GPTBot od OpenAI je v současnosti dominantní AI crawler, který tvoří 30 % veškerého AI crawler provozu a roste meziročně o 305 %. Měli byste však optimalizovat pro všechny hlavní crawlery včetně ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) a další. Různé AI platformy mají různou uživatelskou základnu, takže viditelnost napříč více crawlery maximalizuje přítomnost vaší značky ve vyhledávání AI.
Tradiční analytické nástroje jako Google Analytics nezachytí aktivitu AI crawlerů, protože spoléhají na sledování přes JavaScript. Potřebujete proto server-side monitoring, který analyzuje HTTP hlavičky požadavků a serverové logy k identifikaci user-agentů crawlerů. Specializované nástroje určené pro sledování AI crawlerů poskytují v reálném čase přehled o tom, které stránky jsou crawlery navštěvovány, jak často a zda se crawleři potýkají s technickými problémy.
Sledujte, jak AI crawleři jako GPTBot a ClaudeBot přistupují k vašemu obsahu a citují jej. Získejte v reálném čase přehled o své viditelnosti ve vyhledávání AI s AmICited.
Naučte se, jak strategicky rozhodovat o blokování AI crawlerů. Vyhodnoťte typ obsahu, zdroje návštěvnosti, modely příjmů a konkurenční pozici pomocí našeho komp...

Zjistěte, které AI crawlery povolit nebo blokovat ve vašem robots.txt. Komplexní průvodce zahrnující GPTBot, ClaudeBot, PerplexityBot a 25+ AI crawlerů s ukázka...
Naučte se, jak identifikovat a monitorovat AI crawlery jako GPTBot, PerplexityBot a ClaudeBot ve vašich serverových logách. Objevte user-agent řetězce, metody o...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.