
Jak si případové studie vedou ve výsledcích AI vyhledávání
Zjistěte, jak se případové studie umisťují ve vyhledávačích s umělou inteligencí jako ChatGPT, Perplexity a Google AI Overviews. Objevte, proč AI systémy citují...
9 min čtení

Zjistěte, jak formátovat případové studie pro AI citace. Objevte vzor pro strukturování úspěšných příběhů, které LLM cituje v AI Přehledech, ChatGPT a Perplexity.
AI systémy jako ChatGPT, Perplexity a Google AI Přehledy zásadně mění způsob, jakým B2B zákazníci objevují a ověřují případové studie – většina firem je však stále publikuje v podobách, které LLM téměř nedokážou zpracovat. Když podnikový zákazník položí AI otázku „Které SaaS platformy se nejlépe hodí pro náš případ?“, systém prohledá miliony dokumentů, aby našel relevantní důkazy, ale špatně formátované případové studie zůstávají těmto vyhledávacím systémům neviditelné. Vzniká tak kritická mezera: zatímco tradiční případové studie zvyšují úspěšnost v pozdní fázi obchodu v průměru o 21 %, AI-optimalizované případové studie mohou zvýšit pravděpodobnost citace o 28–40 %, pokud jsou správně strukturované pro modely strojového učení. Firmy, které v tomto novém prostředí vítězí, chápou, že klíčová výhoda z vlastních dat přichází z objevení AI systémy, ne pouze lidskými čtenáři. Bez záměrné optimalizace pro vyhledávání LLM zůstanou vaše nejpřesvědčivější zákaznické příběhy ve skutečnosti uzamčeny před AI systémy, které dnes ovlivňují více než 60 % podnikových nákupních rozhodnutí.
AI-ready případová studie není jen dobře napsaný příběh – jde o strategicky strukturovaný dokument, který současně slouží lidským čtenářům i modelům strojového učení. Nejefektivnější případové studie sledují konzistentní architekturu, která LLM umožňuje extrahovat klíčové informace, porozumět kontextu a citovat vaši firmu s jistotou. Níže je základní vzor, který odlišuje AI-objevitelnou případovou studii od té, která se v retrieval systémech ztratí:
| Sekce | Účel | AI optimalizace |
|---|---|---|
| TL;DR shrnutí | Okamžitý kontext pro zaneprázdněné čtenáře | Umístěno nahoře pro rychlou spotřebu tokenů; 50–75 slov |
| Zákaznický profil | Rychlá identifikace firmy | Struktura: odvětví / velikost firmy / lokalita / role |
| Obchodní kontext | Definice problému a situace na trhu | Používejte konzistentní terminologii; vyhněte se variacím žargonu |
| Cíle | Konkrétní, měřitelné cíle zákazníka | Formátujte jako očíslovaný seznam; zahrňte kvantifikované cíle |
| Řešení | Jak váš produkt/služba řešila potřebu | Explicitně popište propojení funkcí a přínosů |
| Implementace | Časový plán, proces, detaily adopce | Rozdělte do fází; zahrňte trvání a milníky |
| Výsledky | Kvantifikované výsledky a metriky dopadu | Uveďte: Metrika / Výchozí stav / Finální stav / Zlepšení v % |
| Důkazy | Data, screenshoty nebo ověření třetí stranou | Uveďte tabulky s metrikami; zřetelně citujte zdroje |
| Citace zákazníka | Autentický hlas a emoční validace | Uveďte jméno, pozici, firmu; 1–2 věty každá |
| Signály pro opětovné použití | Vnitřní prolinkování a cross-promo | Navrhněte související případové studie, webináře či zdroje |
Tato struktura zajišťuje, že každá sekce plní dvojí účel: je přirozeně čitelná pro lidi a zároveň poskytuje sémantickou jasnost pro RAG (Retrieval-Augmented Generation) systémy, které pohánějí moderní LLM. Konzistence napříč vaší knihovnou případových studií výrazně usnadňuje AI systémům extrakci srovnatelných údajů a citaci vaší firmy s jistotou.
Mimo strukturu mají konkrétní formátovací volby zásadní vliv na to, zda AI systémy vaše případové studie skutečně najdou a citují. LLM zpracovává dokumenty jinak než lidé – neskenuje vizuální hierarchii, ale je velmi citlivý na sémantické značky a konzistentní vzory formátování. Zde jsou formátovací prvky, které nejvíce podporují AI vyhledávání:
Tyto volby nejsou estetické – dělají vaši případovou studii strojově čitelnou, takže když LLM hledá relevantní důkazy, příběh vaší firmy je ten, který bude citován.
Nejvyspělejší přístup k AI-ready případovým studiím zahrnuje zakomponování JSON schématu přímo do dokumentu nebo do vrstvy metadat, což vytváří duální přístup: lidé čtou příběh, stroje strukturovaná data. JSON schémata dávají LLM jednoznačnou, strojově čitelnou reprezentaci klíčových údajů z vaší případové studie a výrazně zvyšují přesnost a relevantnost citací. Takto lze schéma strukturovat:
{
"@context": "https://schema.org",
"@type": "CaseStudy",
"name": "Enterprise SaaS Platform Reduces Onboarding Time by 60%",
"customer": {
"name": "TechCorp Industries",
"industry": "Financial Services",
"companySize": "500-1000 employees",
"location": "San Francisco, CA"
},
"solution": {
"productName": "Your Product Name",
"category": "Workflow Automation",
"implementationDuration": "8 weeks"
},
"results": {
"metrics": [
{"name": "Onboarding Time Reduction", "baseline": "120 days", "final": "48 days", "improvement": "60%"},
{"name": "User Adoption Rate", "baseline": "45%", "final": "89%", "improvement": "97%"},
{"name": "Support Ticket Reduction", "baseline": "450/month", "final": "120/month", "improvement": "73%"}
]
},
"datePublished": "2024-01-15",
"author": {"@type": "Organization", "name": "Your Company"}
}
Implementací JSON struktur kompatibilních se schema.org v podstatě dáváte LLM standardizovaný způsob, jak pochopit a citovat vaši případovou studii. Tento přístup se beze švů integruje s RAG systémy a umožňuje AI modelům přesně extrahovat metriky, chápat zákaznický kontext a správně přiřazovat citace vaší společnosti. Firmy využívající případové studie ve formátu JSON dosahují 3–4× vyšší přesnosti citací v AI odpovědích oproti čistě narativním formátům.
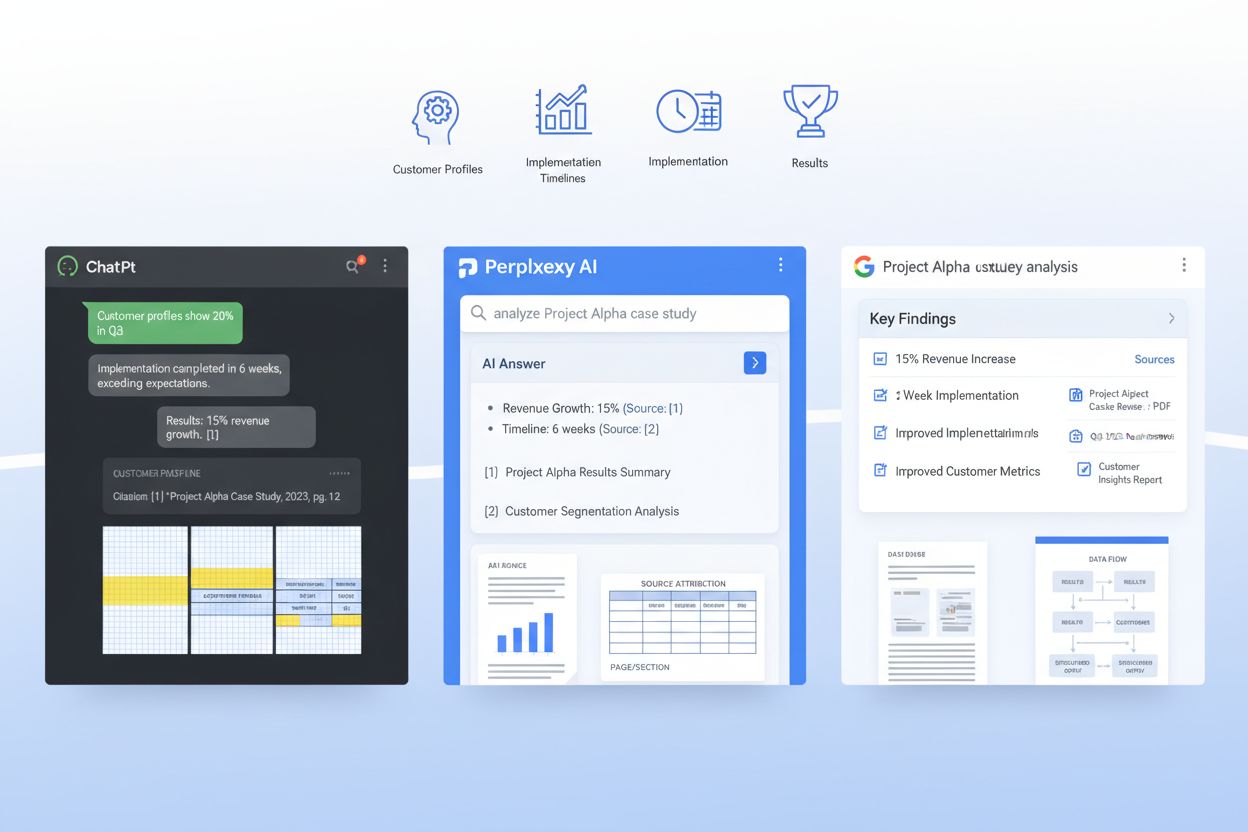
RAG systémy nezpracovávají vaši případovou studii jako jeden velký blok – rozdělují ji do sémantických částí, které se vejdou do kontextového okna LLM, a způsob, jak dokument strukturuje, přímo ovlivňuje, zda jsou tyto části užitečné, nebo roztříštěné. Efektivní chunking znamená organizovat případovou studii tak, aby přirozené sémantické hranice odpovídaly segmentaci obsahu RAG systémy. To vyžaduje záměrnou velikost odstavců: každý odstavec by měl obsahovat jednu myšlenku nebo údaj (obvykle 100–150 slov), takže když systém extrahuje chunk, obsahuje kompletní a soudržnou informaci místo osamocených vět. Oddělení vyprávění je klíčové – používejte jasné sekce mezi problémem, popisem řešení a výsledky, aby LLM mohlo extrahovat „sekci výsledků“ jako souvislý celek a nemíchalo ji s detaily implementace. Efektivita tokenů je navíc důležitá: používáním tabulek pro metriky místo vyprávění snižujete počet tokenů nutných k předání stejné informace, takže LLM může do odpovědi zahrnout více z vaší případové studie, aniž by narazilo na limit kontextového okna. Cílem je udělat z případové studie „RAG-friendly“ dokument, kde každý chunk, který AI systém vytáhne, je samostatně hodnotný a správně zasazený do kontextu.
Publikace případových studií pro AI systémy vyžaduje vyvážení konkrétnosti, která jim dává věrohodnost, s důvěrností, kterou dlužíte svým zákazníkům. Mnoho firem váhá s publikací detailních studií kvůli obavám z odhalení citlivých informací, ale strategické začerňování a anonymizace umožní udržet transparentnost i důvěru. Nejosvědčenější přístup zahrnuje tvorbu více verzí každé studie: interní plně detailní verzi se jmény, přesnými metrikami a proprietárními detaily a veřejnou AI-optimalizovanou verzi, kde je zákazník anonymizován, ale kvantifikovaný dopad a strategické poznatky zůstávají. Místo „TechCorp Industries ušetřila 2,3 milionu USD ročně“ tak zveřejníte „Středně velká finanční firma snížila provozní náklady o 34 %“ – metrika je dostatečně konkrétní pro citaci LLM, ale identita zákazníka chráněná. Verzování a sledování souladu je zásadní: mějte jasno, co a proč bylo začerněno a kdy, aby byla knihovna případových studií vždy připravena na audit. Tento přístup ke správě dat posiluje vaši AI citační strategii, protože umožňuje publikovat více studií častěji bez právních komplikací, což LLM poskytuje více důkazních bodů k objevení a citaci.
Před zveřejněním případové studie ověřte, že skutečně dobře funguje při zpracování LLM a RAG systémy – nepředpokládejte, že dobré formátování automaticky znamená dobrou AI výkonnost. Testování vašich studií na reálných AI systémech odhalí, zda struktura, metadata a obsah skutečně umožňují přesné citace a vyhledávání. Zde je pět zásadních testů:
Tyto testy provádějte čtvrtletně, jak se chování LLM vyvíjí, a výsledky využijte k úpravám formátování a struktury případových studií.
Měření dopadu AI-optimalizovaných případových studií vyžaduje sledovat AI metriky (jak často vaše studie cituje LLM) i lidské metriky (jak tyto citace ovlivňují reálné obchody). Na straně AI použijte AmICited.com ke sledování četnosti citací v ChatGPT, Perplexity i Google AI Přehledech – sledujte, jak často se vaše firma objevuje v AI generovaných odpovědích na relevantní dotazy, a měřte, zda četnost citací stoupá po publikaci nových AI-ready případových studií. Změřte současnou míru citací a stanovte si cíl zvýšit ji o 40–60 % během šesti měsíců po implementaci AI formátování. Na lidské straně propojujte nárůsty AI citací s downstream metrikami: sledujte, kolik obchodů zmínilo „našli jsme vás v AI vyhledávání“ nebo „AI doporučila vaši případovou studii“, měřte zlepšení úspěšnosti v obchodech, kde vaši studii citoval AI systém (cíl: o 28–40 % oproti výchozím 21 %) a sledujte zkrácení prodejního cyklu u účtů, kde se zákazník s vaší studií setkal díky AI. Sledujte i SEO metriky – AI-optimalizované případové studie s řádným schématem často lépe rankují i v tradičním vyhledávání. Důležitá je i kvalitativní zpětná vazba od obchodu: ptejte se, zda přicházejí zákazníci s hlubší znalostí produktu a zda citace případových studií zkracují čas na vyvracení námitek. Konečná KPI je příjem: sledujte přírůstkový ARR díky obchodům ovlivněným AI-citovanými případovými studiemi a získáte jasné ROI pro další investice do tohoto formátu.
Optimalizace případových studií pro AI citace přináší návratnost investice pouze tehdy, když se proces stane součástí opakovaného a provozně zvládnutého workflow, ne jednorázovým projektem. Začněte tím, že kodifikujete AI-ready šablonu případové studie do standardizovaného formátu, který marketing a obchod používají pro každý nový zákaznický příběh – tím zajistíte konzistenci v celé knihovně a zkrátíte čas potřebný pro publikaci nové studie. Integrujte tuto šablonu do CMS, aby publikace nové studie automaticky generovala JSON schéma, metadata a formátovací prvky bez ruční práce. Zařaďte tvorbu případových studií do čtvrtletního nebo měsíčního cyklu, ne pouze jednou ročně, protože LLM častěji objevují a citují firmy s hlubší a novější knihovnou studií. Učiňte případové studie jádrem širší strategie revenue enablementu: měly by se promítat do prodejních materiálů, produktového marketingu, kampaní na generaci poptávky a playbooků zákaznického úspěchu. Nakonec nastavte cyklus kontinuálního zlepšování, kde sledujete, které studie generují nejvíce AI citací, které metriky rezonují s LLM a které segmenty zákazníků jsou nejčastěji citovány – a tyto poznatky použijte pro další generaci případových studií. Firmy, které v AI éře vítězí, nepíší jen lepší případové studie; považují je za strategický tržní asset, který vyžaduje průběžnou optimalizaci, měření a vylepšování.
Začněte extrakcí textu ze svých PDF a mapováním obsahu do standardního schématu s poli jako zákaznický profil, výzva, řešení a výsledky. Poté vytvořte jednoduchou HTML nebo CMS verzi každého příběhu s jasnými nadpisy a metadaty a původní PDF ponechte jako stažitelný doplněk, nikoli jako hlavní zdroj pro AI vyhledávání.
Za vyprávění obvykle zodpovídá marketing nebo produktový marketing, ale prodej, technické řešení a zákaznický úspěch by měly dodat surová data, detaily implementace a validaci. Právní, privacy a RevOps týmy pomáhají zajistit správné řízení, začernění a sladění s existujícími systémy jako CRM a platformy pro podporu prodeje.
Ideální je headless CMS nebo strukturovaná platforma pro obsah pro ukládání schémat a metadat, zatímco CRM nebo nástroj pro podporu prodeje může zobrazit správné příběhy v rámci workflow. Pro AI vyhledávání obvykle kombinujete vektorovou databázi s vrstvou orchestrací LLM jako LangChain nebo LlamaIndex.
Přepisujte video reference a webináře, potom připojte k přepisům stejná pole a sekce jako u psaných případových studií, aby je AI mohla citovat. U grafiky a schémat přidejte krátký alt-text nebo popis, který vystihne hlavní poznatek, aby modely vyhledávání mohly propojit vizuální prvky s konkrétními otázkami.
Globálně udržujte své hlavní schéma a ID konzistentní, poté vytvořte překlady, které lokalizují jazyk, měnu a regulatorní kontext při zachování původních metrik. Lokálně specifické verze ukládejte jako samostatné, ale propojené objekty, aby AI systémy mohly upřednostnit odpovědi v jazyce uživatele bez tříštění datového modelu.
Klíčové případové studie revidujte alespoň jednou ročně, nebo dříve, pokud dojde k zásadním produktovým změnám, novým metrikám nebo změně zákaznického kontextu. Používejte jednoduchý workflow verzování s datem poslední revize a stavovým příznakem, aby bylo jasné pro AI systémy i lidi, které příběhy jsou aktuální.
Integrujte vyhledávání případových studií přímo do nástrojů, které obchodníci už používají, a vytvořte konkrétní playbooky, jak asistenta vyzvat k nalezení relevantních důkazů. Podporujte využívání sdílením úspěšných příběhů, kdy personalizované případové studie zobrazené AI pomohly rychleji uzavřít obchod nebo otevřít nové kontakty.
Tradiční případové studie jsou psané pro lidské čtenáře s důrazem na příběh a vizuální design. AI-optimalizované studie si zachovávají příběh, ale přidávají strukturovaná metadata, jednotné formátování, JSON schémata a sémantickou jasnost, která umožňuje LLM extrahovat, chápat a citovat konkrétní informace s přesností přes 96 %.
Sledujte, jak AI systémy citují vaši značku v ChatGPT, Perplexity a Google AI Přehledech. Získejte přehled o své AI viditelnosti a optimalizujte svou obsahovou strategii.
Zjistěte, jak se případové studie umisťují ve vyhledávačích s umělou inteligencí jako ChatGPT, Perplexity a Google AI Overviews. Objevte, proč AI systémy citují...
Diskuze komunity o tom, jak si případové studie vedou ve výsledcích vyhledávání AI. Skutečné zkušenosti marketérů, kteří sledují citace případových studií v Cha...
Zjistěte, jak Smart Rent získal o 345 % více leadů díky AI citacím. Skutečná případová studie ukazující strategii generování B2B leadů, výsledky a implementační...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.