Jak LLM vybírají, co citovat: Jak AI rozhoduje o výběru zdrojů
Zjistěte, jak velké jazykové modely vybírají a citují zdroje pomocí vážení důkazů, rozpoznávání entit a strukturovaných dat. Seznamte se se 7fázovým procesem rozhodování o citacích a optimalizujte svůj obsah pro viditelnost v AI.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
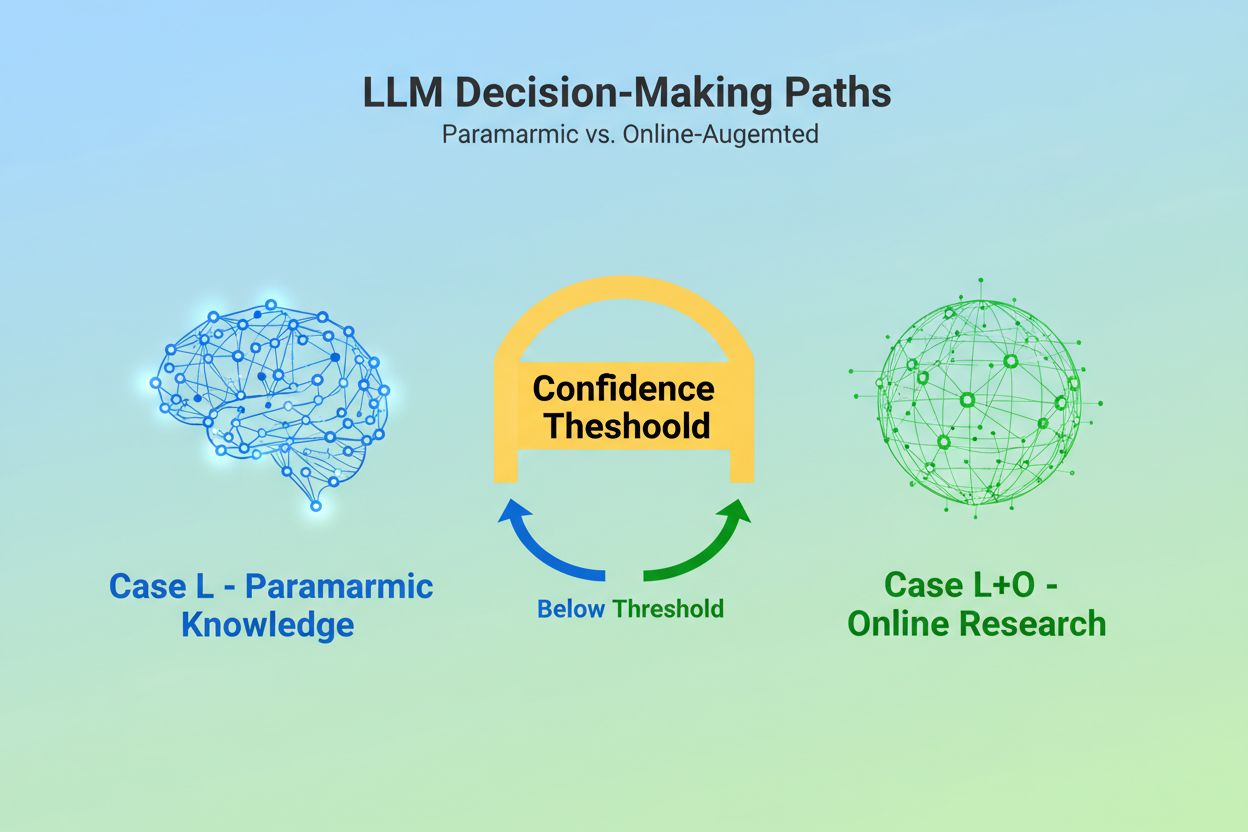
Když velký jazykový model obdrží dotaz, stojí před zásadním rozhodnutím: má se spolehnout pouze na znalosti získané během tréninku, nebo má vyhledat aktuální informace na webu? Tato binární volba – kterou výzkumníci označují jako případ L (pouze data z učení) versus případ L+O (data z učení plus online výzkum) – určuje, zda LLM bude vůbec nějaké zdroje citovat. V režimu L čerpá model výhradně ze své parametrické znalostní báze, což je zhuštěná reprezentace vzorců naučených při tréninku, která obvykle odráží informace staré několik měsíců až přes rok před vydáním modelu. V režimu L+O model aktivuje práh jistoty, který spouští externí vyhledávání a otevírá tzv. “kandidátní prostor” URL a zdrojů. Tento rozhodovací moment je pro většinu monitorovacích nástrojů neviditelný, přesto právě zde celý mechanismus citací začíná – protože bez spuštění fáze vyhledávání nelze žádné externí zdroje vyhodnotit nebo citovat.
Pochopení vážení důkazů
Ve chvíli, kdy se LLM rozhodne vyhledat externí zdroje, vstupuje do nejkritičtější fáze výběru citací: vážení důkazů. Právě zde se rozhoduje, zda půjde jen o zmínku, nebo o autoritativní doporučení. Model prostě nespočítá, kolikrát se zdroj objeví, ani nezohledňuje pouze jeho pozici ve výsledcích vyhledávání; hodnotí strukturální integritu samotných důkazů. Posuzuje architekturu dokumentů – zda obsahují jasné datové vztahy, opakující se identifikátory a odkazy – a tyto prvky interpretuje jako znaky důvěryhodnosti. Model vytváří tzv. “graf důkazů”, kde uzly představují entity a hrany vztahy mezi dokumenty. Každý zdroj je vážen nejen podle relevance obsahu, ale také podle toho, jak konzistentně jsou fakta potvrzována v různých dokumentech, jak tematicky relevantní informace jsou a jak autoritativně doména působí. Toto vícerozměrné hodnocení vytváří tzv. matici důkazů – komplexní posouzení, které určuje, které zdroje jsou dostatečně spolehlivé na to, aby byly citovány. Klíčové je, že tato fáze probíhá v uvažovací vrstvě LLM, takže je neviditelná pro běžné GEO monitorovací nástroje, které sledují pouze signály vyhledávání.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Strukturovaná data – zejména JSON-LD, Schema.org nebo RDFa – působí jako multiplikátor ve vážení důkazů. Zdroje, které správně implementují strukturovaná data, získávají v matici důkazů 2–3krát vyšší váhu než nestrukturovaný obsah. Není to proto, že by LLM preferovaly formátovaná data esteticky; strukturovaná data umožňují propojování entit – tedy propojení zmínek napříč dokumenty pomocí strojově čitelných identifikátorů typu @id, sameAs a Q-ID (identifikátorů Wikidata). Když LLM narazí na zdroj s Q-ID pro organizaci, může tuto entitu okamžitě ověřit v několika dokumentech, což výzkumníci označují jako “koreferenci entit napříč dokumenty”. Tento ověřovací proces dramaticky zvyšuje důvěru ve spolehlivost zdroje.
Formát dat
Přesnost citací
Propojování entit
Ověření napříč dokumenty
Nestrukturovaný text
62 %
Žádné
Manuální odhadování
Základní HTML značky
71 %
Omezené
Částečné párování
RDFa/Mikrodata
81 %
Dobré
Na základě vzorů
JSON-LD s Q-ID
94 %
Výborné
Ověřené odkazy
Formát znalostního grafu
97 %
Perfektní
Automatické ověření
Dopad strukturovaných dat působí na dvou časových osách. Krátkodobě LLM při online vyhledávání načítá JSON-LD a Schema.org v reálném čase a ihned začleňuje tuto strukturu do vážení důkazů pro aktuální odpověď. Dlouhodobě se konzistentní strukturovaná data stávají součástí parametrické znalostní báze modelu při dalším trénování, což ovlivňuje, jak model rozpoznává a hodnotí entity i bez online vyhledávání. Tento dvojí mechanismus znamená, že značky správně implementující strukturovaná data si zajišťují jak okamžitou viditelnost v citacích, tak dlouhodobou autoritu v interním znalostním prostoru modelu.
Rozpoznávání a rozlišení entit
Dříve než LLM může citovat nějaký zdroj, musí nejprve pochopit, o čem zdroj je a koho reprezentuje. To je úkolem rozpoznávání entit – procesu, který převádí vágní lidský jazyk na strojově čitelné entity. Pokud dokument zmiňuje „Apple“, LLM musí určit, zda jde o Apple Inc., ovoce nebo něco úplně jiného. Model to řeší naučenými vzory entit z Wikipedie, Wikidaty a Common Crawl, v kombinaci s kontextovou analýzou okolního textu. V režimu L+O je tento proces ještě sofistikovanější: model ověřuje entity podle externích strukturovaných dat, kontroluje atributy @id, odkazy sameAs a Q-ID, které poskytují jasnou identifikaci. Tento krok je klíčový, protože nejednoznačné nebo nekonzistentní odkazy na entity se v modelovém uvažování ztrácejí. Značka, která používá nekonzistentní pojmenování, nevyužívá jasné identifikátory entit nebo neimplementuje Schema.org, je pro stroj sémanticky nejasná – vystupuje jako několik různých entit místo jedné soudržné. Naopak organizace se stabilními, konzistentně odkazovanými entitami napříč dokumenty jsou rozpoznávány jako spolehlivé uzly v znalostním grafu LLM, což výrazně zvyšuje pravděpodobnost citace.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Proces rozhodování o citaci
Cesta od dotazu k citaci sleduje strukturovaný sedmifázový proces, který výzkumníci zmapovali analýzou chování LLM. Fáze 0: Analýza záměru začíná tokenizací uživatelského vstupu, sémantickou analýzou a vytvořením vektoru záměru – abstraktní reprezentace toho, na co se uživatel skutečně ptá. Tato fáze určuje, jaká témata, entity a vztahy se mají vůbec zvažovat. Fáze 1: Interní získání znalostí přistupuje k parametrické znalosti modelu a vypočítává skóre jistoty. Pokud překročí práh, model zůstává v režimu L; pokud ne, pokračuje k externímu vyhledávání. Fáze 2: Generování fan-out dotazů (pouze L+O) vytváří několik sémanticky různých vyhledávacích dotazů – obvykle 1–6 tokenů – s cílem co nejvíce otevřít kandidátní prostor. Fáze 3: Extrakce důkazů získává URL a úryvky z výsledků vyhledávání, parsuje HTML a extrahuje JSON-LD, RDFa a mikrodata. Právě zde se strukturovaná data poprvé dostávají do citací. Fáze 4: Propojování entit identifikuje entity v získaných dokumentech a ověřuje je podle externích identifikátorů, čímž vytváří dočasný znalostní graf vztahů. Fáze 5: Vážení důkazů hodnotí sílu důkazů ze všech zdrojů s ohledem na architekturu dokumentů, rozmanitost zdrojů, četnost potvrzení a soudržnost napříč zdroji. Fáze 6: Uvažování a syntéza kombinuje interní a externí důkazy, řeší rozpory a rozhoduje, zda si zdroj zaslouží zmínku nebo doporučení. Fáze 7: Konstrukce finální odpovědi převádí vážené důkazy do přirozeného jazyka a integruje citace, kde je to vhodné. Každá fáze navazuje na předchozí, s možností zpětné vazby, která umožňuje modelu upravit vyhledávání či přehodnotit důkazy, pokud se objeví nesrovnalosti.
Retrieval-Augmented Generation (RAG)
Moderní LLM stále více využívají Retrieval-Augmented Generation (RAG), techniku, která zásadně mění způsob výběru a odůvodnění citací. Namísto spoléhání pouze na parametrické znalosti systémy RAG aktivně vyhledávají relevantní dokumenty, extrahují důkazy a zakládají odpovědi na konkrétních zdrojích. Tento přístup mění citace z implicitního vedlejšího produktu tréninku na explicitní a dohledatelný proces. Implementace RAG typicky využívá hybridní vyhledávání, které kombinuje získání podle klíčových slov s vektorovým vyhledáváním podobnosti pro maximalizaci záchytu. Jakmile jsou kandidátní dokumenty získány, sémantické řazení znovu hodnotí výsledky podle významu, nikoli jen shody klíčových slov, aby nejrelevantnější zdroje vystoupily do popředí. Tento explicitní mechanismus činí proces citování transparentnějším a auditovatelným – každý citovaný zdroj lze vystopovat ke konkrétním pasážím, které jeho zařazení odůvodnily. Pro organizace sledující svou AI viditelnost jsou systémy založené na RAG obzvlášť důležité, protože vytvářejí měřitelné vzory citací. Nástroje jako AmICited sledují, jak systémy RAG odkazují na vaši značku napříč různými AI platformami a přinášejí pohled na to, zda vystupujete jako citovaný zdroj, nebo jen jako podkladový materiál v procesu získávání důkazů.
Zmínka vs doporučení
Ne všechny citace jsou stejné. LLM může zmínit zdroj jako kontext, zatímco jiný doporučí jako autoritativní důkaz – a toto rozlišení je dáno výhradně vážením důkazů, nikoli úspěchem vyhledání. Zdroj se může objevit v kandidátním prostoru (fáze 2–3), ale nedosáhne statusu doporučení, pokud jeho skóre důkazů nestačí. Právě toto rozlišení mezi zmínkou a doporučením je slabinou tradičních GEO metrik. Běžné monitorovací nástroje sledují fan-out – zda se váš obsah objevuje ve výsledcích vyhledávání –, ale neměří, zda jej LLM skutečně považuje za důvěryhodný k doporučení. Zmínka může znít jako “Některé zdroje uvádějí…”, zatímco doporučení jako “Podle [zdroj] důkazy ukazují…”. Rozdíl spočívá ve skóre matice důkazů z fáze 5. Zdroje s konzistentními Q-ID, dobře strukturovanou architekturou dokumentu a potvrzením napříč nezávislými zdroji dosahují statusu doporučení. Zdroje s nejasnými odkazy na entity, slabou strukturální soudržností nebo izolovanými tvrzeními zůstávají jen zmínkami. Pro značky je toto rozlišení zásadní: být získán ještě neznamená být citován jako autorita. Cesta od získání k doporučení vyžaduje sémantickou jasnost, strukturální integritu a hustotu důkazů – faktory, které tradiční SEO neřeší.
Praktické důsledky pro tvůrce obsahu
Pochopení, jak LLM vybírají zdroje, má okamžitě využitelné dopady na obsahovou strategii. Za prvé, důsledně implementujte Schema.org na svém webu, zejména u informací o organizaci, článcích a klíčových entitách. Použijte formát JSON-LD s vhodnými atributy @id a odkazy sameAs na Wikidata, Wikipedii či jiné autoritativní zdroje. Tato strukturovaná data přímo zvyšují vaši váhu v matici důkazů ve fázi 5. Za druhé, vytvořte jasné identifikátory entit pro vaši organizaci, produkty a klíčové pojmy. Používejte konzistentní pojmenování, vyhněte se zkratkám, které vedou k nejasnostem, a propojujte související entity hierarchickými vztahy (isPartOf, about, mentions). Za třetí, publikujte strojově čitelné důkazy o svých tvrzeních, referencích a vztazích. Nestačí napsat „Jsme přední poskytovatel X“ – tuto informaci strukturovaně podložte daty, citacemi a ověřitelnými vztahy. Za čtvrté, udržujte obsahovou konzistenci napříč platformami a časem. LLM hodnotí hustotu důkazů tím, že ověřují, zda tvrzení potvrzují nezávislé zdroje; izolovaná tvrzení na jedné platformě mají menší váhu. Za páté, tradiční SEO metriky nepředpovídají AI citace. Vysoké pozice ve vyhledávání nezaručují doporučení LLM; zaměřte se na sémantickou jasnost a strukturální integritu. Za šesté, sledujte své vzory citací pomocí nástrojů jako AmICited, které zobrazují, jak různé AI systémy odkazují na vaši značku. To odhalí, zda dosahujete statusu zmínky či doporučení a jaký typ obsahu citace spouští. A nakonec, AI viditelnost je dlouhodobá investice. Strukturovaná data, která zavedete dnes, ovlivní jak okamžitou pravděpodobnost citace (krátkodobě), tak znalostní bázi modelu v budoucích trénovacích cyklech (dlouhodobě).
Budoucnost AI citací
S vývojem LLM jsou mechanismy citací stále sofistikovanější a transparentnější. Budoucí modely pravděpodobně zavedou grafy citací – explicitní mapy ukazující nejen, které zdroje byly citovány, ale i jak ovlivnily konkrétní tvrzení v odpovědi. Některé pokročilé systémy již experimentují s pravděpodobnostními skóre u citací, která vyjadřují, jak moc si je model jistý relevancí a spolehlivostí zdroje. Dalším trendem je ověření s účastí člověka, kdy uživatelé mohou citace zpochybnit a poskytnout zpětnou vazbu, která zpřesňuje vážení důkazů pro budoucí dotazy. Integrace strukturovaných dat do trénovacích cyklů znamená, že organizace, které dnes zavedou správnou sémantickou infrastrukturu, si v podstatě budují dlouhodobou autoritu v AI systémech. Na rozdíl od výsledků vyhledávání, které se mohou měnit podle algoritmů, přináší dlouhodobý efekt strukturovaných dat stabilnější základ pro AI viditelnost. Tento posun od tradiční viditelnosti (být nalezen) k sémantické autoritě (být důvěryhodný) znamená zásadní změnu v přístupu značek ke komunikaci online. Vítězi v této nové krajině nebudou ti s největším objemem obsahu nebo nejvyššími pozicemi ve vyhledávání, ale ti, kdo své informace strukturovali tak, aby jim stroje mohly spolehlivě porozumět, ověřit je a doporučit.
Často kladené otázky
Jaký je rozdíl mezi případem L a L+O v citacích LLM?
Případ L využívá pouze tréninková data z parametrické znalostní báze modelu, zatímco případ L+O je doplněn o aktuální výzkum na webu. O tom, kterou cestou se model vydá, rozhoduje jeho práh jistoty. Tento rozdíl je zásadní, protože určuje, zda lze externí zdroje vůbec vyhodnocovat a citovat.
Proč jsou některé zdroje citovány a jiné jen zmíněny?
Toto rozlišení určuje vážení důkazů. Zdroje se strukturovanými daty, konzistentními identifikátory a potvrzením napříč dokumenty jsou povýšeny na 'doporučení' namísto pouhých zmínek. Zdroje se mohou objevit ve výsledcích vyhledávání, ale nemusí dosáhnout statusu doporučení, pokud jejich skóre důkazů nestačí.
Jak strukturovaná data jako Schema.org ovlivňují výběr citací?
Strukturovaná data (JSON-LD, @id, sameAs, Q-ID) dostávají v matici důkazů 2-3x vyšší váhu. Toto označení umožňuje propojení entit a ověření napříč dokumenty, což dramaticky zvyšuje skóre spolehlivosti zdroje. Zdroje se správně implementovanou Schema.org jsou výrazně pravděpodobněji citovány jako autoritativní.
Co je rozpoznávání entit a proč je důležité pro citace?
Rozpoznávání entit je způsob, jakým LLM identifikují a rozlišují různé entity (organizace, osoby, pojmy). Jasná identifikace entit prostřednictvím konzistentního pojmenování a strukturovaných identifikátorů zamezuje záměnám a zvyšuje pravděpodobnost citace. Nejednoznačné odkazy na entity se v procesu uvažování modelu ztrácejí.
Jak mění RAG (Retrieval-Augmented Generation) praxi citací?
Systémy RAG aktivně vyhledávají a řadí zdroje v reálném čase, čímž je výběr citací transparentnější a více založený na důkazech než čistě parametrické znalosti. Tento explicitní mechanismus vyhledávání vytváří měřitelné vzory citací, které lze sledovat a analyzovat pomocí nástrojů jako AmICited.
Mohu optimalizovat svůj obsah, aby jej LLM citovaly?
Ano. Implementujte důsledně Schema.org, nastavte jasné identifikátory entit, vytvářejte strojově čitelné důkazy, udržujte konzistenci obsahu napříč platformami a sledujte své vzory citací. Tyto faktory přímo ovlivňují, zda váš obsah dosáhne statusu zmínky nebo doporučení v odpovědích LLM.
Jaký je rozdíl mezi AI viditelností a tradiční vyhledávací viditelností?
Tradiční viditelnost měří dosah a pozici ve výsledcích vyhledávání. AI viditelnost měří, zda je váš obsah rozpoznán jako autoritativní důkaz v uvažovacích procesech LLM. Být získán není totéž jako být citován jako důvěryhodný – to druhé vyžaduje sémantickou jasnost a strukturální integritu.
Jak AmICited pomáhá sledovat citace LLM?
AmICited sleduje, jak AI systémy odkazují na vaši značku v GPT, Perplexity a Google AI Overviews. Odhaluje, zda dosahujete statusu zmínky nebo doporučení, které typy obsahu spouštějí citace a jak se vaše vzory citací liší napříč AI platformami.
Sledujte své AI citace již dnes
Zjistěte, jak LLM zmiňují vaši značku v ChatGPT, Perplexity a Google AI Overviews. Sledujte vzory citací a optimalizujte svou AI viditelnost s AmICited.
Průzkumná data pro viditelnost v AI: Jak vlastní statistiky zvyšují počet citací
Zjistěte, jak se vlastní průzkumná data a originální statistiky stávají magnetem na citace pro LLM. Objevte strategie, jak zvýšit viditelnost v AI a získat více...
Strategie citování zdrojů: Jak učinit váš obsah důvěryhodným pro LLM
Naučte se ověřené strategie citování zdrojů, aby byl váš obsah důvěryhodný pro LLM. Objevte, jak získat AI citace od ChatGPT, Perplexity a Google AI Overviews p...
Zjistěte, co jsou LLM Meta Odpovědi a jak optimalizovat svůj obsah pro viditelnost v AI-generovaných odpovědích z ChatGPT, Perplexity a Google AI Overviews. Obj...
10 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.