
Jak implementovat LLMs.txt: Podrobný technický průvodce
Zjistěte, jak implementovat LLMs.txt na svůj web a pomoci AI systémům lépe porozumět vašemu obsahu. Kompletní průvodce krok za krokem pro všechny platformy včet...
9 min čtení

Kritická analýza efektivity LLMs.txt. Zjistěte, zda je tento AI obsahový standard nezbytný pro váš web, nebo je to jen hype. Skutečná data o adopci, podpoře platforem a co skutečně funguje pro AI viditelnost.
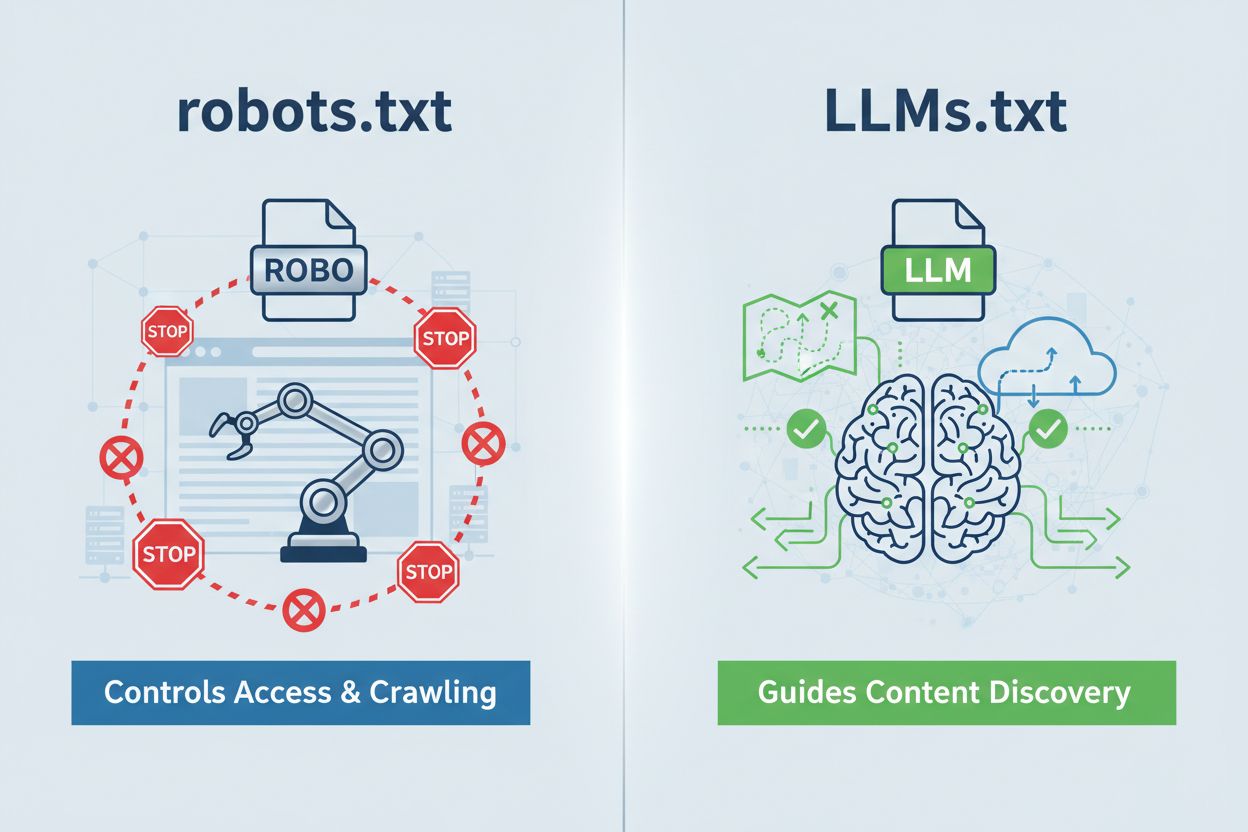
LLMs.txt je prostý textový soubor umístěný na domain.com/llms.txt, který slouží jako kurátorský průvodce pro AI systémy při objevování vašeho nejkvalitnějšího obsahu. Zásadně se liší od robots.txt—zatímco robots.txt řídí, zda k vám AI crawlery mohou přistupovat, LLMs.txt funguje při přístupu v čase inference a pomáhá AI systémům pochopit, kterým stránkám dát při generování odpovědí přednost. Je to spíše mapa s pokladem než dopravní policista: nebrání průzkumu, jen zvýrazňuje, kde je skutečná hodnota. Formát je osvěžující v jednoduchosti—prostý markdown bez složité syntaxe—díky čemuž je dostupný i pro netechnické organizace. Tento rozdíl je důležitý, protože mění celý rámec diskuse: LLMs.txt není o kontrole crawlů, ale o optimalizaci toho, jak AI systémy interpretují a upřednostňují váš AI-čitelý obsah poté, co vás už našly.
Čísla ukazují skutečný zájem: k říjnu 2025 implementovalo LLMs.txt přes 844 000 webů, přičemž adopce je soustředěna u firem, které chápou roli AI ve své budoucnosti. Hráči jako Anthropic, Cloudflare, Stripe, Vercel a Supabase standard zavedli, což signalizuje, že vážné infrastrukturní firmy v experimentu vidí hodnotu. Rozhodnutí Mintlify umožnit automatické generování pro tisíce dokumentačních webů v listopadu 2024 způsobilo výrazný skok v adopci a ukázalo, že podpora v nástrojích urychluje implementaci. Tři komunitní adresáře nyní evidují implementace, s 788+ ověřenými weby napříč nimi. Vzor adopce však ukazuje důležité zjištění: implementace je silně koncentrovaná u vývojářských nástrojů a dokumentačních platforem—tedy v sektorech, které zviditelnění v AI nejvíce využijí. Takto vypadá skutečná adopce:
| Společnost/Platforma | Implementace | Počet tokenů | Stav |
|---|---|---|---|
| Anthropic | Ano | ~2 000 | Aktivní |
| Cloudflare | Ano | ~5 000 | Aktivní |
| Stripe | Ano | ~8 000 | Aktivní |
| Vercel | Ano | ~3 500 | Aktivní |
| Supabase | Ano | ~4 200 | Aktivní |
| Mintlify (auto-generováno) | Ano | Různé | Aktivní |
Tady se skepticismu dostává opodstatnění: ANI JEDNA hlavní AI platforma oficiálně nepotvrdila, že by LLMs.txt používala ve svých retrieval systémech. John Mueller z Googlu jasně řekl: „Žádný AI systém v současnosti llms.txt nepoužívá,“ což mělo debatu uzavřít, ale nestalo se. OpenAI, Anthropic, Google, Microsoft i Perplexity zatím mlčí—žádná dokumentace, žádné potvrzení, žádné veřejné plány. Existují důkazy, že některé platformy soubory stahují (boty Microsoftu a OpenAI byly při stahování LLMs.txt pozorovány), ale crawling a skutečné využití jsou odlišné věci. Optimistický výklad předpokládá, že platformy tiše testují před zveřejněním; skeptický říká, že to nikdy nepřijmou, protože jim to neřeší skutečný problém. Ticho je jádrem argumentu o „přehnaném očekávání“: 18 měsíců po rozšíření návrhu máme masivní implementaci, ale nulovou oficiální podporu platforem. To není standard, to je naděje.
Skeptická pozice stojí na jednoduchém základě: není žádný důkaz, že by LLMs.txt zlepšoval AI retrieval, zvyšoval návštěvnost nebo zlepšoval viditelnost obsahu. Problém s důvěrou je hlubší—odděleným souborem můžete nabídnout jiný obsah, než je v HTML, což umožňuje manipulaci. Studie chování LLM ukazují, že jsou 2,5× náchylnější doporučit obsah, který je speciálně zvýrazněn či cílen, což vytváří motivaci k „gamingu“. Organizace může do LLMs.txt dát jen svůj nejlepší obsah a slabší skrýt, nebo dokonce uvést obsah, který na webu vůbec není. SEO nástroje tlak ještě zvyšují tím, že hlásí chybějící LLMs.txt jako příležitost k optimalizaci—Rank Math, SEMrush aj. vytvářejí smyčku, kdy weby standard zavádějí ne proto, že funguje, ale protože jim nástroje říkají, že jim něco chybí. To je skutečný problém: 18 měsíců tlaku na implementaci bez jediné doložené měřitelné hodnoty. Je to digitální obdoba toho, když si všichni koupí los, protože firma na losy pořád inzeruje.
Tábor pro-LLMs.txt argumentuje jinak, sází na nevyhnutelnou změnu spíše než na současné důkazy. Carolyn Shelby z Yoastu to shrnula přesně: „Umístění už není cenou, cenou je zahrnutí.“ Windsurf, AI editor kódu, uvedl, že LLMs.txt šetří čas a tokeny při parsování dokumentace, což by znamenalo skutečný přínos pro AI systémy, které ho využívají. Anthropic dokonce přímo požádal Mintlify o implementaci LLMs.txt do dokumentace, což naznačuje interní hodnotu, i když ji veřejně nepotvrdil. Google zahrnul LLMs.txt do svého protokolu A2A (Agents to Agents), což naznačuje, že firma ho vnímá jako součást budoucí AI infrastruktury. Implementace zabere 1–4 hodiny a nemá žádné prokázané negativní dopady—nic nerozbijete, SEO neublížíte, prostě jen vytvoříte soubor. Poznámka Jeremyho Howarda vystihuje podstatu logiky zastánců: „99,9 % pozornosti bude brzy pozornost LLM, ne lidí,“ což znamená, že optimalizace pro AI systémy není volitelná, ale nevyhnutelná. Springs Apps hlásí po implementaci 20% nárůst search visibility, i když to není ověřeno a může jít jen o korelaci.
Proč může LLMs.txt selhat, pochopíme lépe, když se podíváme, proč jiné standardy uspěly. Robots.txt fungoval, protože nabídl oboustranný prospěch za minimální náklady a získal oficiální RFC podporu (RFC 9309)—vyhledávače chtěly efektivně crawlovat, weby chtěly kontrolovat crawling a řešení bylo natolik jednoduché, že adopce byla bezproblémová. Schema.org uspěl díky multi-partnerství Googlu, Microsoftu, Yahoo a Yandexu hned od začátku—žádná firma nemohla standard vlastnit, což budovalo důvěru. Sitemap.xml získal podporu platforem před masovou adopcí, ne až po ní. LLMs.txt postrádá všechny tři úspěšné faktory: žádné zapojení W3C, žádné konsorcium, žádná oficiální podpora platforem a žádná doložená hodnota v návštěvnosti, zlepšení pozic nebo přesnosti. Co dělá standard skutečně funkčním, je zapojení více stran, jasné a měřitelné přínosy a nízký potenciál manipulace. LLMs.txt má naději. Má adopci u prvních nadšenců. Má nástrojovou podporu. Ale nemá základní prvky, které z předchozích standardů udělaly infrastrukturu.
Pokud je LLMs.txt stále neprokázaný, co opravdu posouvá AI viditelnost a AI citace? Odpověď je prostší než nový formát souboru:
Tyto postupy fungují, protože odpovídají způsobu, jakým AI systémy skutečně zpracovávají informace, ne proto, že jsou optimalizované pro konkrétní soubor.

Debata kolem LLMs.txt odráží hlubší proměnu v tom, jak online obsah uspívá: konvergenci lidského UX a AI optimalizace. Výzkum Generative Engine Optimization (GEO) ukazuje, že obsah, který vítězí v AI-generovaných odpovědích, má jasné vlastnosti—přehlednost, strukturu, autoritu a konkrétnost. Vercel hlásí, že 10 % jejich registrací nyní přichází přímo ze zmínek v ChatGPT, nikoli z tradičního vyhledávání—to by před pěti lety nebylo možné. Úspěch znamená čím dál více objevení v AI odpovědích, nejen pořadí v organických výsledcích—to jsou odlišné cíle s různými požadavky. Nástrojová krajina se posunula: SEMrush AIO, Profound GEO tracking i Ahrefs Brand Radar nyní sledují AI viditelnost vedle klasických pozic. Zásadní posun je tento: být citován je důležitější než být řazen, být odkazován je důležitější než být indexován. To vysvětluje, proč se LLMs.txt rozšířil navzdory absenci oficiální podpory—představuje pokus optimalizovat pro novou ekonomiku pozornosti, kde jsou AI systémy hlavním distribučním kanálem.
Pokud se rozhodnete implementovat, udělejte to správně. Soubor musí být na domain.com/llms.txt (pozor: množné číslo), ve formátu prostého textového markdownu, nikoliv XML nebo JSON. Začněte H1 nadpisem s názvem webu, volitelně přidejte blokové shrnutí účelu webu. Čleňte obsah do H2 sekcí, pokud web má různé oblasti (Dokumentace, Blog, API Reference apod.), s popisy, co každá sekce obsahuje. Jednotlivé stránky pište ve formátu [Název](URL): Popis, popis krátký, ale výstižný. Zahrnout: stále aktuální obsah, dobře strukturované stránky, články, které prokazují odbornost. Vyhnout se: hlavní stránce (obvykle není samostatně cenná), všem URL webu (kvalita nad kvantitou), stránkám, které bez okolního kontextu nedávají smysl. Příklad základní struktury:
# Název firmy
> Stručný popis činnosti firmy a proč by AI systémy měly váš obsah znát
## Dokumentace
[Začínáme](https://example.com/docs/getting-started): Průvodce pro nové uživatele krok za krokem
[API Reference](https://example.com/docs/api): Kompletní API dokumentace s příklady
[Osvědčené postupy](https://example.com/docs/best-practices): Prověřené vzory pro použití naší platformy
## Blog
[Proč jsme to vytvořili](https://example.com/blog/why-we-built-this): Řešený problém a naše cesta
Volitelně můžete přidat sekci s URL, které mají být vynechány, pokud je potřeba kratší kontext, většina implementací to ale nevyžaduje.
Ano, LLMs.txt byste měli implementovat. Ne proto, že je prokazatelně funkční, ale protože riziko je nulové a potenciální přínos skutečný. Pokud ho AI platformy nikdy oficiálně nepřijmou, soubor na serveru prostě jen zůstane—žádná SEO penalizace, žádná ztráta návštěvnosti, žádné rozbité funkce. Implementace zabere malému webu asi 10 minut, velkým maximálně hodinu. Mezitím se návštěvnost rozpadá mezi více AI systémy: ChatGPT, Perplexity, Claude a další dohromady řeší stovky milionů dotazů měsíčně. Pro AI systémy už jste viditelní—LLMs.txt jim jen pomáhá najít váš nejlepší obsah místo náhodných stránek. I kdyby se LLMs.txt nikdy nestal oficiálním standardem, trénujete AI systémy, aby lépe chápaly strukturu a priority vašeho webu, což má hodnotu samo o sobě. Skutečný poznatek: pojistěte si budoucnost zdarma. Implementujte standard, optimalizujte obsah pro AI viditelnost osvědčenými postupy a sledujte, co vám přináší návštěvnost z AI systémů. Za 12 měsíců budete mít reálná data o tom, zda LLMs.txt má pro váš byznys smysl—a to je nesrovnatelně cennější než spekulace.
LLMs.txt je prostý textový soubor, který navádí AI systémy k vašemu nejlepšímu obsahu pro přístup v čase inference, zatímco robots.txt řídí přístup crawlerů a indexaci. LLMs.txt nic neomezuje – pouze kurátorsky zvýrazňuje vaše nejhodnotnější stránky pro lepší pochopení AI. Představte si robots.txt jako dopravního policistu a LLMs.txt jako mapu s pokladem.
Oficiálně ne. Přestože ho implementovalo přes 844 000 webů, žádná hlavní AI platforma nepotvrdila, že by LLMs.txt využívala pro generování odpovědí. Existují důkazy o crawlingu ze strany botů OpenAI a Microsoftu, ale žádné potvrzení o využití k inference nebo citacím. To je jádro argumentu o „přehnaném očekávání“.
Ano. Implementace zabere 10–30 minut a nemá žádná negativa. Pokud ho platformy přijmou, jste připraveni. Pokud ne, soubor ničemu neškodí. Je to nízkorizikový krok s potenciální odměnou pro AI viditelnost. V podstatě sázíte na budoucnost objevování obsahu AI.
Zahrňte stále aktuální, dobře strukturovaný obsah, který odpovídá na konkrétní otázky: návody, FAQ, API dokumentaci, pilířový obsah a autoritativní články. Vyhněte se úvodní stránce, všem URL vašeho webu a stránkám, které nedávají smysl vytržené z kontextu. Kvalita je důležitější než kvantita.
Ano, to je oprávněná obava. Do LLMs.txt můžete dát jiný obsah než je na vašich skutečných stránkách, což narušuje důvěru. Proto jsou někteří odborníci vůči této normě skeptičtí a platformy ji přijímají opatrně.
llms.txt obsahuje kurátorsky vybrané odkazy na vaše nejlepší stránky s popisy. llms-full.txt je komplexní verze se všemi vašimi dokumentacemi v jednom obrovském souboru (někdy 400 000+ slov). llms-full.txt použijte, pokud chcete AI systémům nabídnout vše najednou bez nutnosti sledovat odkazy.
LLMs.txt je nástroj v rámci širší GEO strategie. GEO se zaměřuje na to, aby byl váš obsah objevitelný a citovatelný AI systémy díky jasné struktuře, citacím, datům a odbornosti. LLMs.txt pomáhá AI systémům najít váš GEO-optimalizovaný obsah.
Ano. Každý web těží z toho, když AI systémy lépe chápou a citují váš obsah. Blogy, lokální firmy, e-shopy i komunitní weby získávají návštěvnost z AI vyhledávání. LLMs.txt je jednoduchý způsob, jak zlepšit svoji viditelnost na ChatGPT, Claude, Perplexity a dalších AI platformách.
Sledujte, jak systémy jako ChatGPT, Claude a Perplexity odkazují na váš obsah. Získejte okamžité informace o AI citacích a viditelnosti napříč AI platformami.
Zjistěte, jak implementovat LLMs.txt na svůj web a pomoci AI systémům lépe porozumět vašemu obsahu. Kompletní průvodce krok za krokem pro všechny platformy včet...

Zjistěte, co jsou soubory LLMs.txt, jak se liší od robots.txt a proč jsou nezbytné pro viditelnost a citace v ChatGPT, Perplexity a Google AI Overviews. Komplet...

Zjistěte, co je LLMs.txt, jestli skutečně funguje a zda byste ho měli nasadit na svůj web. Poctivá analýza tohoto nově vznikajícího AI SEO standardu.
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.