
Kanonické URL a AI: Prevence problémů s duplicitním obsahem
Zjistěte, jak kanonické URL předcházejí problémům s duplicitním obsahem v AI vyhledávačích. Objevte osvědčené postupy pro implementaci kanonických URL, které zl...
6 min čtení

Zjistěte, jak znovupublikování obsahu vytváří problémy s duplicitním obsahem, které poškozují viditelnost ve vyhledávání AI mnohem více než v tradičním vyhledávání. Objevte technická opatření a osvědčené postupy.
Znovupublikování obsahu napříč více kanály, platformami a formáty je legitimní a často nezbytnou strategií pro maximalizaci dosahu a zapojení. Tato praxe však vytváří zásadní napětí s tím, jak vyhledávací systémy—zejména ty poháněné AI—zpracovávají a řadí obsah. Problém není v tom, zda můžete znovupublikovat, ale zda to děláte způsobem, který neohrozí vaši viditelnost ve výsledcích AI vyhledávání. Na rozdíl od tradičních vyhledávačů, které vyvinuly sofistikované mechanismy pro detekci duplicitního obsahu během desítek let, AI systémy přistupují k duplicitnímu obsahu odlišně, což vytváří nová rizika, na která se mnoho vydavatelů ještě nepřizpůsobilo.
Podle technické dokumentace Microsoftu o Copilot a AI vyhledávání „LLMs seskupují téměř duplicitní URL do jednoho klastru a poté vybírají jednu stránku, která reprezentuje celý soubor.“ Toto seskupování je zásadně odlišné od toho, jak algoritmus PageRank od Googlu rozděluje autoritu mezi duplicitní stránky. Místo konsolidace signálů AI systémy činí binární rozhodnutí: vyberou jednu reprezentativní stránku z klastru podobného obsahu a ostatní do značné míry ignorují. Tento výběr není vždy předvídatelný nebo založený na verzi, kterou byste chtěli řadit nejvýše. Algoritmus zvažuje faktory jako aktuálnost, kvalitu obsahu, technické signály a autoritu domény—ale jaká je váha těchto faktorů, zůstává nejasné. Co činí tuto situaci obzvlášť problematickou, je to, že AI systémy mohou vybrat zastaralou verzi, pokud jsou rozdíly mezi stránkami natolik minimální, že algoritmus seskupování nezjistí významné změny.
| Aspekt | Tradiční vyhledávání | AI vyhledávání |
|---|---|---|
| Zpracování duplicit | Konsolidace autoritativních signálů | Seskupení a výběr jedné reprezentativní |
| Riziko penalizace | Možná ruční akce | Žádná penalizace, ale rozředění viditelnosti |
| Rozpoznání aktualizací | Postupné šíření signálů | Může přehlédnout aktualizace při malých rozdílech |
| Efektivita procházení | Plýtvání rozpočtem na duplicitách | Snižuje prioritu duplicitám |
| Respektování kanoniky | Dodržována, ale ne zaručena | Klíčová pro výběr klastru |
Znovupublikování bez vhodných opatření přináší tři vzájemně propojená rizika, která přímo ovlivňují AI viditelnost:
Rozředění signálu záměru: Když se stejný obsah objeví na více URL, AI systém přijímá protichůdné signály o tom, která verze nejlépe odpovídá na dotaz uživatele. Místo soustředění autority na jednu URL se vaše signály rozptylují po klastru. Toto rozředění snižuje skóre důvěry, které AI systémy přiřazují vašemu obsahu při rozhodování, zda jej zahrnout do odpovědí. Obsah, který by mohl být hlavním zdrojem, se stává vedlejší možností, protože systém není schopen s jistotou určit autoritativní verzi.
Riziko reprezentace: Výběr AI systému, která stránka reprezentuje váš obsahový klastr, nemusí odpovídat vašim obchodním cílům. Můžete například znovupublikovat blogový příspěvek na syndikační síť s očekáváním, že tato verze přivede návštěvnost, ale AI systém vybere vaši původní doménu—nebo hůř, vybere syndikovanou verzi, která neodkazuje zpět na váš web. Takové rozporování znamená, že vaše strategie znovupublikování aktivně odporuje vašim cílům místo toho, aby je posilovala.
Prodleva aktualizací a zastaralost: Pokud aktualizujete původní obsah, ale znovupublikované verze zůstanou nezměněné, AI systémy mohou vybrat zastaralou verzi jako reprezentativní stránku. Algoritmus seskupování ne vždy pozná, že jedna verze je novější nebo přesnější než ostatní, zejména pokud jsou změny jen dílčí, nikoli strukturální. Tím vzniká situace, kdy je váš nejaktuálnější a nejpřesnější obsah neviditelný, zatímco starší verze prezentuje vaši odbornost AI systémům.
Nejčastější chybou při znovupublikování je syndikace obsahu na platformy třetích stran bez implementace kanonických tagů. Představte si typickou situaci: B2B softwarová firma publikuje obsáhlého průvodce na svém blogu a následně ho syndikuje do oborových médií jako Medium, LinkedIn a specializované agregátory zpráv. Každá platforma hostuje totožný obsah pod různými URL. Bez kanonických tagů směřujících zpět na původní verzi považuje algoritmus seskupování AI systému všechny verze za stejně autoritativní. Syndikační platforma může mít vyšší doménovou autoritu, což vede AI systém k výběru této verze jako reprezentativní stránky. Váš původní obsah—verze, kterou jste optimalizovali, aktualizovali a budovali k ní zpětné odkazy—se stává v AI vyhledávání neviditelný. Návštěvnost a autorita proudí na syndikační platformu místo na vaše vlastní prostředky. Tento scénář se denně opakuje tisíckrát napříč vydavatelským průmyslem, kdy si vydavatelé nevědomky sabotují vlastní viditelnost tím, že neimplementují jediný HTML tag.
Obsah specifický pro kampaň vytváří zvlášť zákeřný problém duplicitního obsahu při znovupublikování napříč kanály. Marketingový tým spustí kampaňovou landing page optimalizovanou pro konkrétní akci a poté její varianty znovupublikuje do emailových newsletterů, na sociální sítě, v placených reklamách a na partnerské weby. Každá verze obsahuje mírně odlišný text, výzvy k akci nebo formátování—ale základní obsah i záměr zůstávají identické. AI systémy je rozpoznají jako téměř duplicitní a seskupí je. Problém se prohlubuje, když jsou kampaňové stránky znovupublikovány bez správné implementace kanoniky. AI systém může vybrat newsletterovou verzi (bez měření konverzí) jako reprezentativní stránku, nebo partnerskou verzi, která neprospívá vašim metrikám. Navíc, když kampaně skončí a stránky jsou archivovány nebo smazány, může už AI systém mít jako reprezentativní stránku vybranou dnes už neexistující verzi, a uživatelé tak narazí na nefunkční obsah.
Regionální znovupublikování přináší složitost kvůli nutnosti rozlišovat legitimní lokalizační potřeby v detekci duplicitního obsahu. Firma s působením ve vícero zemích může publikovat stejný hlavní obsah v různých jazycích či s regionálními variantami. Bez správné implementace tyto regionální verze soupeří mezi sebou v AI klastrech. Představte si SaaS společnost, která publikuje průvodce funkcemi v angličtině na své US doméně a poté jej znovupublikuje na UK doméně s britským pravopisem a regionálními cenami. AI systém je seskupí jako duplicitní, a může vybrat US verzi i pro uživatele z UK. Řešení spočívá v implementaci hreflang tagů, které AI systémům signalizují regionální vztahy, přestože účinnost hreflang v AI vyhledávání je méně ověřená než v tradičním vyhledávání.
<!-- Na US verzi (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Na UK verzi (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
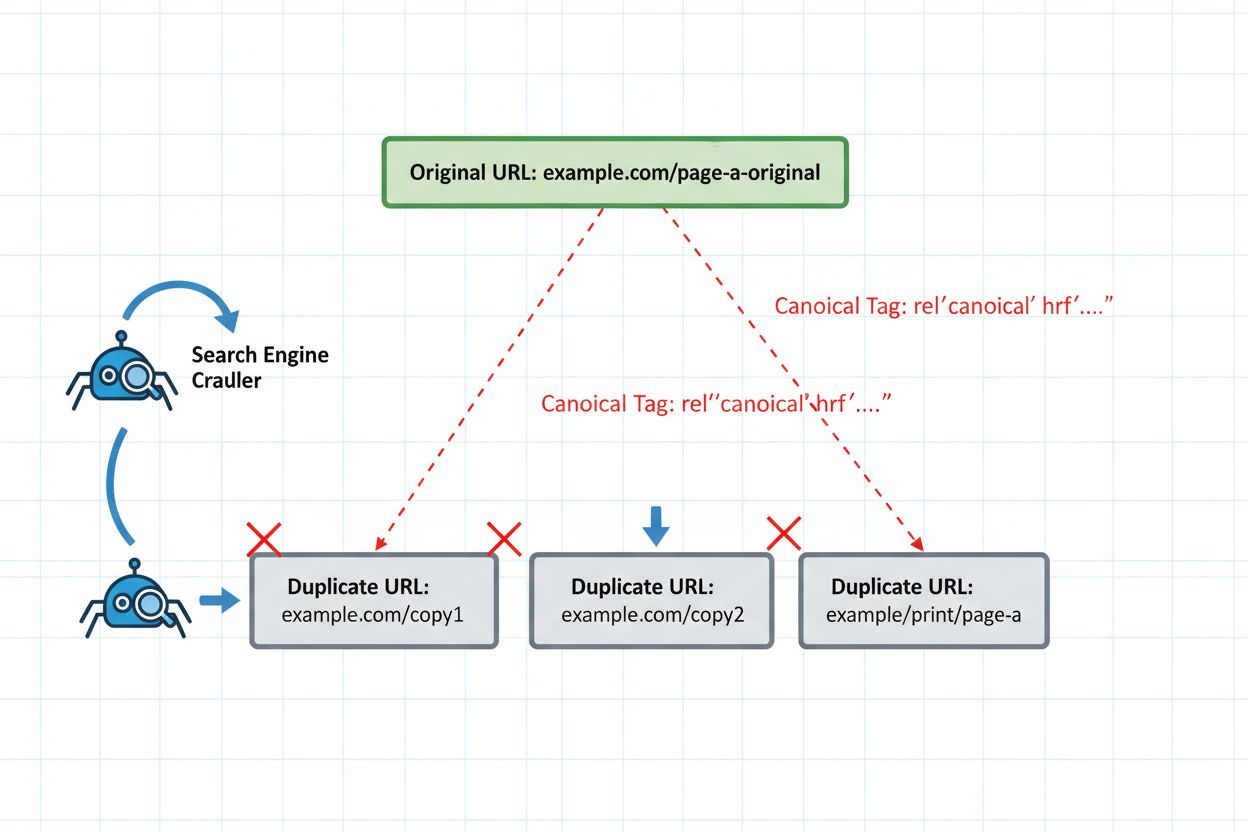
Implementace správných technických opatření je nevyhnutelná pro bezpečné znovupublikování. Kanonický tag je vaše hlavní obrana, která AI systémům jednoznačně říká, která verze má reprezentovat váš obsahový klastr. Umístěte kanonický tag do sekce <head> každé znovupublikované verze a směřujte jej na preferovanou, autoritativní verzi. U syndikovaného obsahu to zpravidla znamená odkazování zpět na vaši původní doménu.
<!-- Na syndikované verzi (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
Pro obsah, který by nikdy neměl soutěžit s jinými verzemi, implementujte na vedlejší verze noindex. Tím je zcela vyjmete z AI indexace a zajistíte, že nemohou být vybrány jako reprezentativní stránky. Tento přístup používejte pro interní duplicitní stránky, testovací verze nebo syndikovaný obsah, kde nechcete žádnou AI viditelnost.
<!-- Na vedlejší verzi, která nemá být indexována -->
<meta name="robots" content="noindex, follow" />
301 přesměrování poskytuje nejsilnější signál pro konsolidaci autority, ale používejte jej pouze tehdy, pokud vedlejší verze už nikdy nebude samostatně aktualizována. Přesměrování AI systému sděluje, že stará URL se trvale přesunula, a všechny signály konsoliduje na nové místo. Pokud ale potřebujete, aby obě verze zůstaly živé (jako u syndikace), přesměrování je problematické, protože naruší URL strukturu na syndikační platformě.
# V .htaccess nebo serverové konfiguraci
Redirect 301 /old-article https://yoursite.com/new-article
U redakčních systémů implementujte rel=“canonical” dynamicky, abyste pokryli stránkování, varianty s parametry a URL založené na relaci, které vytvářejí nechtěné duplicity. Mnoho CMS generuje pro stejný obsah více URL přes různé navigace—kanonické tagy je automaticky konsolidují.
IndexNow urychluje objevení kanonických signálů a konsolidace duplicit, což zkracuje proces z týdnů na dny. Když implementujete kanonické tagy na znovupublikovaný obsah, IndexNow okamžitě oznámí vyhledávacím systémům, že tyto URL mají být seskupeny dohromady. Místo čekání, až roboty při běžném procházení objeví kanonický vztah, IndexNow tuto informaci přímo předá indexu Microsoftu a dalším zapojeným systémům. To je zvlášť přínosné, když zpětně opravujete chyby v znovupublikování—můžete implementovat kanonické tagy a IndexNow okamžitě signalizovat změnu, místo čekání na opětovnou návštěvu robotů. Pro vydavatele, kteří spravují obsah napříč mnoha platformami, se IndexNow stává klíčovým nástrojem pro udržení kontroly nad tím, která verze reprezentuje jejich obsahový klastr. API integrace umožňuje hromadné odesílání URL, což je praktické při správě stovek či tisíců znovupublikovaných stránek.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Sledování, kterou verzi vašeho znovupublikovaného obsahu vybírají AI systémy, vyžaduje monitoring nad rámec tradiční analytiky. Nastavte sledování pro identifikaci toho, kdy AI systémy citují nebo odkazují na váš obsah, a zaznamenávejte, která URL se objevuje ve výsledcích AI vyhledávání. Nástroje jako Semrush, Ahrefs a Moz začínají přidávat metriky AI viditelnosti, byť tyto jsou zatím méně rozvinuté než tradiční měření. Na syndikované verze implementujte UTM parametry pro sledování atribuce návštěvnosti, ale počítejte s tím, že AI systémy tyto parametry nemusí zachovat, což přímou atribuci komplikuje. Sledujte svůj Search Console (nebo ekvivalentní nástroje jiných systémů) na vzorce procházení—pokud jsou vedlejší verze procházeny častěji než vaše kanonická, znamená to, že AI možná vybrala nesprávnou reprezentativní stránku. Nastavte upozornění na zmínky o vašem obsahu na syndikačních platformách a porovnávejte je s AI viditelností, abyste odhalili nesoulad mezi tím, kde se váš obsah objevuje a odkud ho AI systémy vybírají.
Před znovupublikováním obsahu použijte tento kontrolní seznam, abyste si udrželi kontrolu nad AI viditelností:
Před znovupublikováním určete svou kanonickou verzi—URL, kterou chcete prezentovat v AI vyhledávání. Typicky by to měla být vaše vlastní doména, nikoli syndikační platforma. Implementujte kanonické tagy na každou znovupublikovanou verzi směřující na vaši kanonickou URL, i když znovupublikujete na vlastních webech (různé domény, subdomény nebo varianty s parametry). Použijte IndexNow pro okamžité oznámení vyhledávacím systémům o kanonickém vztahu, místo čekání na objevení během procházení. Vyhněte se znovupublikování na vysoce autoritativní platformy bez podpory kanonických tagů—některé platformy kanonické tagy odstraňují nebo je neumožňují, a proto jsou pro znovupublikování nevhodné, pokud nechcete riskovat ztrátu viditelnosti. Sledujte prvních 48 hodin po znovupublikování, abyste ověřili, že AI systémy vybírají vaši zamýšlenou kanonickou verzi, ne alternativní. Aktualizujte všechny verze současně při změnách obsahu—pokud aktualizujete jen kanonickou verzi, algoritmus seskupování nemusí rozpoznat změnu napříč všemi verzemi, což může způsobit, že AI systém vybere zastaralou verzi. Zaveďte plán znovupublikování, který zabrání zastarávání obsahu na vedlejších platformách; zastaralý syndikovaný obsah zvyšuje riziko, že AI systémy jej zvolí jako reprezentativní, pokud vaše kanonická verze nebyla nedávno aktualizována.
Kanonické tagy nezabrání penalizaci, protože duplicitní obsah sám o sobě penalizaci nevyvolává. Kanonické tagy jsou však zásadní pro AI vyhledávání, protože určují, která verze by měla reprezentovat váš obsahový klastr. Bez kanonických tagů může AI systém vybrat jako autoritativní zdroj nechtěnou verzi, což snižuje vaši viditelnost.
Sledujte, které URL se objevují ve výsledcích AI vyhledávání a citacích vašeho obsahu. Nástroje jako Semrush a Ahrefs přidávají metriky AI viditelnosti. Zkontrolujte svůj Search Console na vzorce procházení – pokud jsou vedlejší verze procházeny častěji než vaše kanonická verze, mohl AI systém vybrat nesprávnou stránku.
Technicky ano, ale není to doporučeno. Bez kanonických tagů AI systémy seskupí váš obsah a vyberou jednu verzi jako reprezentativní – ale nebudete kontrolovat, kterou. Syndikační platforma může mít vyšší autoritu, což vede AI k výběru této verze místo vaší původní domény.
Znovupublikování obvykle znamená distribuci obsahu napříč více kanály, které ovládáte nebo s nimi spolupracujete. Syndikace obsahu je specifická forma znovupublikování, kdy váš obsah s vaším svolením znovupublikuje třetí strana. Obojí vytváří problémy s duplicitním obsahem, pokud nejsou správně spravovány kanonickými tagy.
Kanonické tagy jsou obvykle rozpoznány během 24–48 hodin, pokud použijete IndexNow k okamžitému oznámení vyhledávacím systémům. Bez IndexNow to může trvat týdny, než roboty objeví kanonický vztah. Proto je IndexNow zásadní pro správu znovupublikovaného obsahu – výrazně urychluje celý proces.
301 přesměrování použijte pouze tehdy, když chcete trvale sloučit URL a vedlejší verze se nikdy nebude samostatně aktualizovat. Kanonické tagy použijte, když potřebujete, aby obě verze zůstaly živé (například u syndikace). Přesměrování jsou silnější signál, ale naruší funkčnost vedlejší URL.
Ano, pokud není správně spravováno. Znovupublikování bez kanonických tagů rozptyluje vaše autoritativní signály mezi více URL. AI systém může vybrat syndikovanou verzi místo vaší původní, což snižuje viditelnost na vaší doméně. Správná implementace kanonických tagů tomu zabrání.
Na každou znovupublikovanou verzi implementujte kanonické tagy směřující na vaši původní doménu. Použijte IndexNow pro okamžité oznámení vyhledávacím systémům o kanonickém vztahu. Vyhněte se znovupublikování na platformy, které nepodporují kanonické tagy. Sledujte, kterou verzi AI systémy vyberou během prvních 48 hodin, a v případě potřeby upravte nastavení.
Sledujte, jak AI systémy citují a odkazují na váš znovupublikovaný obsah napříč všemi platformami. Získejte okamžité přehledy o tom, kterou verzi AI zvolí jako váš autoritativní zdroj.
Zjistěte, jak kanonické URL předcházejí problémům s duplicitním obsahem v AI vyhledávačích. Objevte osvědčené postupy pro implementaci kanonických URL, které zl...

Naučte se, jak spravovat a předcházet duplicitnímu obsahu při použití AI nástrojů. Objevte kanonické tagy, přesměrování, nástroje na detekci a osvědčené postupy...
Diskuze komunity o tom, jak AI systémy zacházejí s duplicitním obsahem odlišně než tradiční vyhledávače. SEO profesionálové sdílí postřehy k jedinečnosti obsahu...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.