Jak často navštěvují AI crawleři webové stránky?
Pochopte četnost návštěv AI crawlerů, vzory procházení pro ChatGPT, Perplexity a další AI systémy. Zjistěte, jaké faktory ovlivňují, jak často AI boti procházej...
10 min čtení

Zjistěte, jak použít robots.txt k ovládání, které AI boty mají přístup k vašemu obsahu. Kompletní průvodce blokováním GPTBotu, ClaudeBota a dalších AI crawlerů s praktickými příklady a strategiemi konfigurace.
Krajina webového crawlování se za poslední dva roky zásadně změnila – posunula se za hranice známého indexování vyhledávačů do komplexního světa trénování AI modelů. Zatímco Googlebot společnosti Google byl dlouho předvídatelným návštěvníkem webů vydavatelů, nová generace crawlerů přichází s dramaticky odlišnými úmysly a vzory spotřeby. GPTBot od OpenAI vykazuje poměr crawl-to-refer přibližně 1 700 : 1, což znamená, že projde 1 700 stránek, aby vytvořil pouze jedno přesměrování zpět na váš web, zatímco ClaudeBot od Anthropic funguje s ještě extrémnějším poměrem 73 000 : 1—ostře odlišným od poměru Googlu 14 : 1, kde aktivita crawlování vede ke smysluplné návštěvnosti. Tento zásadní rozdíl vytváří pro tvůrce obsahu naléhavé obchodní rozhodnutí: umožnit těmto botům neomezený přístup znamená, že váš obsah trénuje AI modely, které konkurují vaší návštěvnosti i příjmům, zatímco vaše stránky za to dostávají minimální odměnu nebo návštěvnost. Vydavatelé se nyní musí aktivně rozhodnout, zda je pro ně přínos přístupu AI botů v souladu s jejich podnikatelským modelem, což činí konfiguraci robots.txt nejen technickou záležitostí, ale i strategickou obchodní nutností.
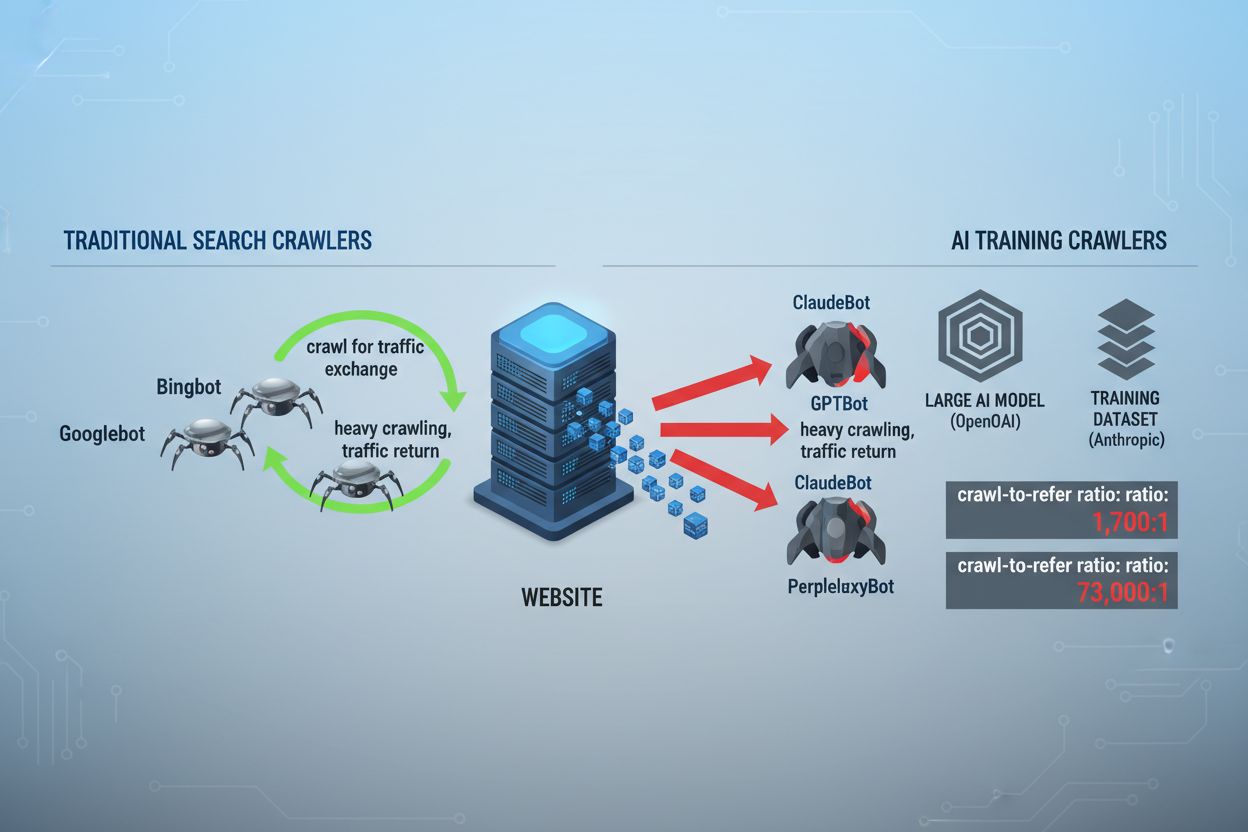
AI crawlery fungují ve třech odlišných kategoriích, z nichž každá slouží jinému účelu a vyžaduje jinou strategii blokování. Tréninkové crawlery jsou navrženy k získávání velkých objemů obsahu pro trénování základních AI modelů—patří sem GPTBot od OpenAI, ClaudeBot od Anthropic, Google-Extended od Googlu, PerplexityBot od Perplexity, Meta-ExternalAgent od Meta, Applebot-Extended od Applu a noví hráči jako Amazonbot, Bytespider a cohere-ai. Vyhledávací crawlery naopak pohánějí AI vyhledávání a obvykle vrací návštěvnost zpět vydavatelům; patří mezi ně OAI-SearchBot od OpenAI, Claude-Web od Anthropic nebo vyhledávací funkce Perplexity. Třetí kategorií jsou agenti aktivovaní uživatelem, kteří přistupují k obsahu na základě explicitního požadavku uživatele, například ChatGPT-User nebo Claude-Web při přímém zadání uživatelem. Pochopení této taxonomie je klíčové, protože vaše strategie blokování by měla odrážet vaše obchodní priority—můžete vítat vyhledávací crawlery, které přivádějí návštěvníky, ale blokovat tréninkové crawlery, které konzumují obsah bez kompenzace. Každá velká AI společnost provozuje vlastní flotilu specializovaných crawlerů a rozdíl mezi nimi často spočívá ve specifickém uživatelském agentovi (user agent string), což činí přesnou identifikaci a cílené blokování nezbytnými pro efektivní konfiguraci robots.txt.
| Společnost | Tréninkový crawler | Vyhledávací crawler | Agent aktivovaný uživatelem |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Používá standardní Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Udržování přesného a aktuálního seznamu user agentů AI botů je zásadní pro efektivní konfiguraci robots.txt, přičemž tato oblast se rychle vyvíjí s přibývajícími modely a změnami strategií společností. Hlavními tréninkovými crawlery jsou GPTBot (primární tréninkový crawler OpenAI), ClaudeBot (tréninkový crawler Anthropic), anthropic-ai (alternativní identifikátor Anthropic), Google-Extended (AI token Googlu), PerplexityBot (crawler společnosti Perplexity), Meta-ExternalAgent (tréninkový crawler Meta), Applebot-Extended (AI varianta Applu), CCBot (bot Common Crawl), Amazonbot (crawler Amazonu), Bytespider (crawler ByteDance), cohere-ai (tréninkový bot Cohere), DuckAssistBot (crawler AI asistenta DuckDuckGo) a YouBot (crawler You.com). Na vyhledávání zaměřené crawlery, které typicky vrací návštěvnost, patří OAI-SearchBot, Claude-Web a PerplexityBot v režimu vyhledávání. Kritickým problémem je, že tento seznam není statický—pravidelně vznikají nové AI společnosti, existující firmy zavádějí nové crawlery pro nové produkty a user agenti se občas mění nebo rozšiřují. Vydavatelé by měli robots.txt vnímat jako živý dokument, který potřebuje minimálně čtvrtletní revizi a aktualizace, případně odebírat průmyslové sledovací zdroje nebo sledovat serverové logy kvůli neznámým user agentům, které mohou signalizovat nové AI crawlery na webu. Opomenutí pravidelné aktualizace znamená buď nechtěné povolení nových tréninkových crawlerů, které jste chtěli blokovat, nebo zbytečné blokování legitimních vyhledávacích crawlerů, kteří by mohli přinášet cennou návštěvnost.
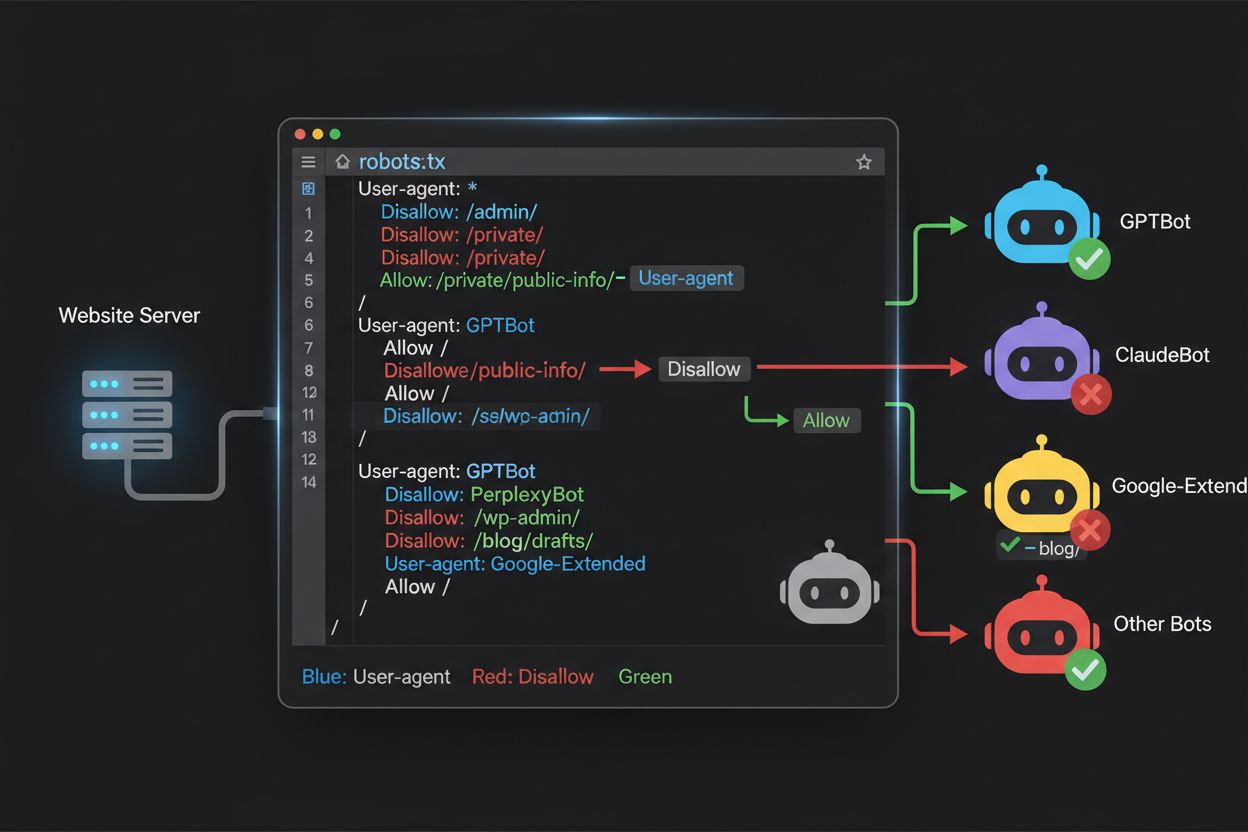
Soubor robots.txt, umístěný v kořeni vaší domény (vasadomena.cz/robots.txt), využívá jednoduchou syntaxi k předání preferencí ohledně crawlování botům, které protokol respektují. Každé pravidlo začíná direktivou User-Agent, která určuje, kterého bota se pravidlo týká, a následuje jedna nebo více direktiv Disallow, které určují, ke kterým cestám bot nemá přístup. Pro zablokování všech hlavních tréninkových AI crawlerů při zachování přístupu pro tradiční vyhledávače vytvoříte samostatné bloky User-Agent pro každý tréninkový crawler, kterého chcete vyloučit: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended a další, každý s direktivou “Disallow: /”, která jim zabrání v crawlování jakéhokoli obsahu vašeho webu. Zároveň zajistíte, že legitimní vyhledávací crawlery jako Googlebot, Bingbot a vyhledávací varianty jako OAI-SearchBot zůstanou povoleny, takže mohou nadále indexovat váš obsah a přivádět návštěvníky. Správně nakonfigurovaný robots.txt by měl obsahovat také referenci na Sitemapu (XML sitemap), což pomáhá vyhledávačům efektivně objevovat a indexovat váš obsah. Správná konfigurace je naprosto zásadní—jediná chyba v syntaxi, špatně zadaný znak nebo nesprávný user agent může celou strategii zablokování znehodnotit a umožnit nežádoucím crawlerům přístup k obsahu, případně zablokovat legitimní zdroje návštěvnosti. Testování konfigurace před nasazením proto není volitelné, ale nezbytné, abyste zajistili, že robots.txt dosáhne zamýšleného efektu.
# Blokace AI tréninkových crawlerů
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Povolení tradičních vyhledávačů
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Reference na sitemapu
Sitemap: https://yoursite.com/sitemap.xml
Mnoho vydavatelů stojí před složitým rozhodnutím: chtějí zůstat viditelní ve výsledcích AI vyhledávání a získávat návštěvnost z těchto platforem, ale zároveň chtějí zabránit tomu, aby jejich obsah byl využíván pro trénink základních AI modelů, které konkurují jejich podnikání. Tato strategie selektivního blokování vyžaduje rozlišování mezi vyhledávacími a tréninkovými crawlery od stejné společnosti—například povolit OAI-SearchBot od OpenAI (který pohání vyhledávání v ChatGPT a vrací návštěvnost), ale zablokovat GPTBot (který trénuje základní model). Podobně můžete povolit vyhledávací crawler PerplexityBot, ale blokovat jeho tréninkové operace, nebo povolit Claude-Web pro vyhledávání na vyžádání uživatelem, ale blokovat tréninkové aktivity ClaudeBota. Obchodní důvod je přesvědčivý: vyhledávací crawlery mají obvykle mnohem nižší poměr crawl-to-refer, protože jsou navrženy pro přivádění návštěvnosti, zatímco tréninkové crawlery konzumují obsah ve velkém s minimálním přínosem pro vás. Tento přístup vyžaduje pečlivé nastavení a průběžné sledování, protože společnosti občas mění strategie crawlerů nebo zavádějí nové user agenty, které rozostřují hranici mezi vyhledáváním a tréninkem. Vydavatelé by měli pravidelně kontrolovat serverové logy, aby ověřili, že zamýšlené crawlery mají přístup, zatímco blokovaní jsou úspěšně vyloučeni, a podle vývoje AI prostředí a příchodu nových hráčů upravovat robots.txt.
# Povolit AI vyhledávací crawlery
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blokovat tréninkové crawlery
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
I zkušení správci webů často dělají chyby v nastavení, které zcela podkopávají jejich strategii robots.txt a nechávají obsah vystavený crawlerům, které chtěli blokovat. První častou chybou je vytvoření samostatných řádků User-Agent bez odpovídající direktivy Disallow—například napsat “User-Agent: GPTBot” a ihned začít novým pravidlem bez určení, co má být zakázáno, což bota zcela nezablokuje. Druhou chybou je nesprávné umístění souboru, název nebo velikost písmen; soubor musí být přesně “robots.txt” (malými písmeny), v kořenovém adresáři domény a vracet HTTP kód 200—umístění v podadresáři nebo pojmenování jako “Robots.txt” či “robots.TXT” způsobí, že ho crawlery neuvidí. Třetí chybou je vkládání prázdných řádků do bloku pravidel, což mnoho parserů robots.txt interpretuje jako konec pravidla, takže následující direktivy jsou ignorovány nebo špatně použity. Čtvrtou chybou je chyba v rozlišování velikosti písmen v cestách URL; jména user agentů nejsou na velikosti písmen závislá, ale cesty v Disallow ano, takže “Disallow: /Admin” neblokuje “/admin” ani “/ADMIN”. Pátou chybou je špatné použití zástupných znaků—asterisk (*) nahrazuje jakoukoli sekvenci znaků, ale mnozí vydavatelé ho používají chybně, například “Disallow: .pdf” místo správného “Disallow: /.pdf” nebo “Disallow: /*pdf” pro blokaci koncovek souborů. Někteří vydavatelé také vytvářejí příliš složitá pravidla s několika Disallow, která si vzájemně odporují, nebo opomíjejí URL parametry a query stringy, což může způsobit blokaci legitimního obsahu nebo ponechání nechtěného obsahu volně přístupného. Testování konfigurace pomocí dedikovaných validatorů robots.txt před nasazením pomůže tyto chyby odhalit dříve, než ovlivní procházení vašeho webu.
Časté chyby, kterým se vyhnout:
Google-Extended představuje v robots.txt výjimečný případ, protože funguje jako kontrolní token, nikoli tradiční crawler, a pochopení tohoto rozdílu je zásadní pro informované rozhodnutí o blokování. Na rozdíl od Googlebota, který prochází váš web kvůli indexaci do vyhledávače, je Google-Extended signálem pro to, zda váš obsah může být použit pro trénink AI modelů Gemini a pro generování AI Přehledů (AI Overviews) ve výsledcích vyhledávání. Blokování Google-Extended zabraňuje použití vašeho obsahu pro trénink Gemini a generování AI Overviews, ale nemá vliv na vaši viditelnost v tradičních výsledcích Google Search—Googlebot bude váš obsah dál indexovat. Tento kompromis je významný: blokace Google-Extended znamená, že váš obsah se neobjeví v AI Přehledech, které jsou čím dál viditelnější ve výsledcích vyhledávání a mohou přinášet velkou návštěvnost, ale chrání váš obsah před použitím pro trénink konkurenčního AI modelu. Naopak povolení Google-Extended znamená, že váš obsah může být v AI Přehledech (a přinášet návštěvnost), ale zároveň slouží jako tréninková data pro Gemini, který může časem konkurovat vašemu obsahu či obchodnímu modelu. Vydavatelé by měli pečlivě zvážit svou konkrétní situaci—zpravodajské weby a tvůrci závislí na přímé návštěvnosti mohou mít prospěch z blokace Google-Extended, zatímco jiní mohou uvítat viditelnost a návštěvnost z AI Přehledů. Toto rozhodnutí by mělo být učiněno vědomě, nikoli automaticky, protože má zásadní dopad na dlouhodobou viditelnost a návštěvnost ve vyhledávači Google.
Testování robots.txt před nasazením do produkce je naprosto zásadní, protože chyby mohou mít dalekosáhlé následky jak pro vaši viditelnost ve vyhledávačích, tak pro ochranu obsahu. Google Search Console nabízí vestavěný tester robots.txt, který vám umožní ověřit, zda konkrétní user agent může přistupovat ke konkrétním URL na vašem webu—můžete zadat user agent jako “GPTBot” a cestu na webu a Google vám sdělí, zda by bot podle současné konfigurace měl přístup, nebo ne. Merkle Robots.txt Tester nabízí podobné funkce s uživatelsky přívětivým rozhraním a podrobným vysvětlením, jak jsou pravidla interpretována. TechnicalSEO.com poskytuje další bezplatný nástroj na validaci syntaxe robots.txt a ukáže přesně, jak by s vašimi pravidly naložili různí boti. Pro komplexní monitoring nabízí Knowatoa AI Search Console specializované nástroje pro sledování AI crawlerů a validaci vaší konfigurace proti konkrétním botům, které chcete blokovat. Vaše ověřovací workflow by mělo zahrnovat nahrání robots.txt nejprve do testovacího prostředí, ověření, že klíčové stránky, které mají zůstat dostupné, nejsou omylem blokovány, potvrzení, že AI boti, které chcete blokovat, jsou skutečně vyloučeni, a sledování serverových logů kvůli neočekávané aktivitě crawlerů. Tato fáze testování by měla zahrnovat i kontrolu správnosti odkazu na sitemapu a ověření, že vyhledávače mají k vašemu obsahu běžný přístup—chcete blokovat AI tréninkové crawlery, aniž byste omylem blokovali legitimní návštěvnost z vyhledávačů. Teprve po důkladném otestování nasazujte konfiguraci do produkce a i pak alespoň první týden sledujte logy pro případné nečekané problémy.
Nástroje pro testování:
Ačkoli robots.txt je užitečnou první obrannou linií, je důležité si uvědomit, že funguje na principu cti—boti, kteří protokol respektují, se jím budou řídit, ale škodlivé nebo špatně navržené crawlery jej mohou zcela ignorovat a k obsahu se stejně dostanou. Odhaduje se, že robots.txt úspěšně zastaví asi 40–60 % nežádoucího crawlerového provozu, což znamená, že 40–60 % botů buď protokol ignoruje, nebo je navržen tak, aby jej obcházel. Pro vydavatele vyžadující robustnější ochranu jsou nutné další vrstvy obrany. Web Application Firewall (WAF) od Cloudflare umožňuje vytvářet pravidla blokující provoz podle user agentů, IP adres nebo vzorců chování, což chrání před boty ignorujícími robots.txt. Serverové nástroje jako .htaccess (na serverech Apache) nebo ekvivalentní konfigurace na Nginx umožňují blokovat konkrétní user agenty či IP rozsahy dříve, než se požadavek dostane k aplikaci. Blokování IP může být účinné, pokud znáte IP rozsahy konkrétních crawlerů, ale vyžaduje průběžnou údržbu, protože infrastruktura crawlerů se mění. Nástroje jako Fail2ban dokáží automaticky blokovat IP adresy vykazující podezřelé chování, například příliš rychlé nebo opakované požadavky na citlivé cesty. Implementace těchto ochran však vyžaduje pečlivé nastavení—příliš agresivní blokování může nechtěně vyloučit legitimní provoz, například uživatele přistupující přes VPN nebo firemní proxy sdílející IP s crawlery. Nejefektivnější je kombinovat robots.txt jako zdvořilou žádost, blokování user agentů na úrovni serveru pro boty ignorující robots.txt a monitorování chování k zachycení sofistikovaných crawlerů, které maskují user agenta nebo využívají distribuované IP. Vydavatelé by měli tyto vrstvy zavádět postupně a každou důkladně testovat, aby neblokovali legitimní provoz a přitom dosáhli požadované ochrany obsahu.
Porozumět tomu, co skutečně přistupuje na váš web, je zásadní pro ověření, že robots.txt funguje dle očekávání, a pro odhalení nových crawlerů, které mohou vyžadovat blokaci. Hlavní metodou je analýza serverových logů—logy vašeho webserveru (Apache access logy, Nginx logy nebo ekvivalent) obsahují detailní záznamy o každém požadavku na web, včetně user agenta, IP adresy, času a požadovaného zdroje. Pomocí příkazových nástrojů jako grep můžete prohledávat logy podle konkrétních user agentů; například „grep ‘GPTBot’ /var/log/apache2/access.log“ zobrazí všechny požadavky od GPTBotu a umožní ověřit, jestli blokace funguje. Složitější analýza může zahrnovat zjištění četnosti procházení jednotlivých botů, konkrétních navštěvovaných stránek a ověření, zda respektují robots.txt. Automatizovaná monitorovací řešení mohou logy analyzovat průběžně a upozornit vás na nové nebo nečekané crawlery, což je zvlášť cenné vzhledem k rychlé evoluci AI crawlerů. Někteří vydavatelé využívají platformy pro agregaci logů jako ELK Stack, Splunk nebo cloudová řešení pro centralizovanou analýzu aktivity crawlerů napříč servery. Rychle se měnící prostředí AI crawlerů znamená, že monitorování není jednorázový úkol, ale průběžná povinnost—pravidelně vznikají noví boti, existující mění user agenty a chování crawlerů se mění dle strategií firem. Zavedení pravidelného monitoringu (týdenní nebo měsíční revize logů) vám umožní reagovat včas a upravovat robots.txt proaktivně, nikoliv až po vzniku škod.
Vaše konfigurace robots.txt pro AI crawlery je ve své podstatě finančním rozhodnutím a zasluhuje stejnou strategickou pozornost, jakou byste věnovali jakémukoli obchodnímu rozhodnutí s výrazným ekonomickým dopadem. Povolení neomezeného přístupu tréninkovým crawlerům znamená, že AI modely vyškolené na vašich datech vám mohou časem konkurovat v návštěvnosti i příjmech—pokud váš obchodní model závisí na přímé návštěvnosti, viditelnosti ve vyhledávačích nebo reklamních příjmech, v podstatě poskytujete zdarma tréninková data firmám, které staví konkurenční produkty. Naopak zablokováním všech AI crawlerů přicházíte o možnou viditelnost ve výsledcích AI vyhledávání a návštěvnost z AI asistentů, což je rostoucí způsob, jak uživatelé objevují obsah. Optimální strategie závisí na vašem konkrétním modelu: vydavatelé financovaní z reklamy mohou těžit z povolení vyhledávacích crawlerů (které přivádějí návštěvníky a zobrazení reklam) při současném blokování tréninkových crawlerů (které návštěvnost nepřináší). Vydavatelé s předplatným mohou volit agresivnější postup a blokovat většinu AI crawlerů kvůli ochraně obsahu před sumarizací nebo replikací AI systémy. Vydavatelé zaměření na budování značky a autority mohou naopak AI vyhledávání vítat jako formu distribuce. Klíčové je rozhodovat se vědomě, nikoli automaticky—mnoho vydavatelů nikdy robots.txt pro AI crawlery nenakonfigurovalo, čímž de facto umožnili přístup všem botům, což znamená, že pasivně poskytli obsah pro trénink AI bez vlastního rozhodnutí. Zvažte také implementaci schema markup pro správné připisování, když je váš obsah použit AI systémy, což může napomoci zachování návštěvnosti a uznání zdroje i při citacích AI asistenty. Vaše robots.txt by mělo odrážet vaši vědomou obchodní strategii a být pravidelně revidováno podle vývoje AI prostředí a vašich priorit.
Krajina AI crawlerů se vyvíjí nebývalým tempem—vznikají nové firmy, stávající zavádějí nové crawlery a user agenty se mění či rozšiřují. Vaše robots.txt by neměl být souborem typu „nastavit a zapomenout“, ale živým dokumentem, který minimálně čtvrtletně revidujete a aktualizujete. Zaveďte proces sledování novinek ohledně AI crawlerů, přihlaste se k newsletterům nebo blogům, které tyto změny mapují, a pravidelně kontrolujte serverové logy pro identifikaci neznámých user agentů, které mohou signalizovat nové crawlery na vašem webu. Když objevíte nové crawlery, zjistěte, jaký mají účel a obchodní model, a rozhodněte, zda zapadají do vaší strategie ochrany obsahu, a podle toho aktualizujte robots.txt. Sledujte také efektivitu svého nastavení—monitorujte objem provozu crawlerů, poměr požadavků crawlerů vůči uživatelské návštěvnosti a případné změny v organické viditelnosti nebo návštěvnosti z AI vyhledávání. Někteří vydavatelé zjistí, že jejich původní strategie blokování potřebuje po několika měsících úpravu—možná zjistíte, že blokace konkrétního crawleru měla nečekané důsledky, nebo že povolení některých crawlerů přináší větší hodnotu, než jste čekali. Buďte připraveni strategii upravit na základě skutečných dat, ne domněnek. Nakonec komunikujte strategii robots.txt relevantním členům týmu—váš SEO tým, obsahový tým i vedení by měli rozumět, proč jsou některé crawlery blokovány či povoleny, aby rozhodnutí zůstala konzistentní a vědomá i při vývoji organizace. Toto průběžné řízení crawlerů zajistí, že vaše strategie ochrany obsahu zůstane účinná a v souladu s obchodními cíli i při dalším vývoji AI prostředí.
Ne. Blokování crawlerů pro trénink AI jako jsou GPTBot, ClaudeBot a CCBot nemá vliv na vaše pozice ve vyhledávačích Google nebo Bing. Tradiční vyhledávače používají jiné crawlery (Googlebot, Bingbot), které fungují nezávisle. Tyto blokujte pouze v případě, že chcete zcela zmizet z výsledků vyhledávání.
Hlavní crawlery od OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) a Perplexity (PerplexityBot) oficiálně uvádějí, že respektují direktivy robots.txt. Menší nebo méně transparentní boti ale mohou vaše nastavení ignorovat, proto existují i vícevrstvé ochranné strategie.
Záleží na vaší strategii. Blokování pouze tréninkových crawlerů (GPTBot, ClaudeBot, CCBot) ochrání váš obsah před použitím pro trénink modelů, přičemž vyhledávací crawlery necháte, aby vám pomáhaly objevovat se ve výsledcích AI vyhledávání. Kompletní blokace vás z AI ekosystémů zcela odstraní.
Zkontrolujte své nastavení alespoň čtvrtletně. AI společnosti pravidelně zavádějí nové crawlery. Anthropic například sloučil své boty 'anthropic-ai' a 'Claude-Web' do 'ClaudeBot', čímž nový bot dočasně získal neomezený přístup na weby, které neaktualizovaly svá pravidla.
Robots.txt je soubor v kořenovém adresáři vaší domény, který platí pro všechny stránky, zatímco meta robots tagy jsou HTML direktivy na jednotlivých stránkách. Robots.txt je kontrolován jako první a může zabránit crawlerům v přístupu k stránce, zatímco meta tagy jsou čteny jen při návštěvě stránky. Pro komplexní kontrolu používejte obojí.
Ano. Můžete využít pravidla Disallow pro konkrétní cesty v robots.txt (např. 'Disallow: /premium/' pro blokaci pouze prémiového obsahu) nebo použít meta robots tagy na jednotlivých stránkách. Tak ochráníte citlivý obsah, zatímco crawlerům umožníte přístup do jiných sekcí.
Pokud bot robots.txt ignoruje, potřebujete další ochranné metody jako blokování na úrovni serveru (.htaccess), blokování IP nebo pravidla WAF. Robots.txt zastaví asi 40–60 % nežádoucích crawlerů, proto je vícevrstvá ochrana důležitá pro komplexní obranu.
Použijte testovací nástroje, například robots.txt tester v Google Search Console, Merkle Robots.txt Tester nebo TechnicalSEO.com k ověření své konfigurace. Sledujte serverové logy kvůli aktivitě crawlerů, abyste ověřili, že blokovaní boti jsou vyloučeni a povolení boti mají přístup k vašemu obsahu.
Robots.txt je jen první krok. Použijte AmICited ke sledování, které AI systémy citují váš obsah, jak často vás zmiňují a zajistěte správné připisování napříč GPTs, Perplexity, Google AI Přehledy a dalšími.
Pochopte četnost návštěv AI crawlerů, vzory procházení pro ChatGPT, Perplexity a další AI systémy. Zjistěte, jaké faktory ovlivňují, jak často AI boti procházej...
Zjistěte, jak otestovat, zda mají AI crawlery jako ChatGPT, Claude a Perplexity přístup k obsahu vašeho webu. Objevte testovací metody, nástroje a osvědčené pos...
Zjistěte, co znamená crawl budget pro AI, jak se liší od tradičních vyhledávačů a proč je důležitý pro viditelnost vaší značky v odpovědích generovaných AI a AI...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.