Stack Overflow a citace v AI: Viditelnost technické komunity
Zjistěte, jak obsah Stack Overflow ovlivňuje odpovědi AI a naučte se strategie, jak maximalizovat svou vývojářskou viditelnost v ChatGPT, Gemini a na dalších AI platformách.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
50 milionů otázek a odpovědí ze Stack Overflow se stalo základním stavebním kamenem při vývoji velkých jazykových modelů. Klíčové AI společnosti včetně OpenAI, Google a Meta začlenily data ze Stack Overflow do svých trénovacích datasetů, protože znalosti vývojářů představují jeden z nejkvalitnějších, komunitně ověřených technických obsahů dostupných na internetu. Vývoj pokročilých AI systémů stojí stovky milionů dolarů a velká část těchto nákladů je spojena se získáváním a zpracováním trénovacích dat. Historicky AI společnosti tato data stahovaly zdarma, ale CEO Stack Overflow Prashanth Chandrasekar v roce 2023 oznámil, že platforma začne velkým AI vývojářům za přístup ke svému obsahu účtovat poplatky, protože uznává, že znalosti vytvářené komunitou by měly být odměněny. Tento posun odráží širší trend v odvětví, kdy platformy s hodnotnými daty požadují spravedlivou kompenzaci od společností, které na jejich obsahu vydělávají.
Přiřazení zdrojů a licence Creative Commons
Obsah Stack Overflow je licencován pod Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), což právně vyžaduje, aby kdokoli, kdo obsah využívá, uvedl původního autora. Tento licenční rámec je pro Stack Overflow nevyjednatelný, protože platforma věří, že přiřazení zdrojů je základem důvěry vývojářů v AI generovaný obsah. Když AI společnosti trénují modely na datech ze Stack Overflow bez správného přiřazení zdrojů, technicky porušují licenci Creative Commons, což je důvod, proč nyní Stack Overflow vyžaduje, aby všichni API partneři zahrnuli požadavky na přiřazení do svých smluv. Význam tohoto kroku nelze podcenit: podle Stack Overflow Developer Survey 2024 považuje 65 % vývojářů chybějící či nesprávné přiřazení za jednu z hlavních etických obav u AI nástrojů.
Aspekt
Požadavek
Dopad
Typ licence
CC BY-SA 4.0
Povinné přiřazení
Důvěra vývojářů
72% příznivě
Klíčové pro přijetí
Soulad AI
Implementace RAG
Zajišťuje zdrojování
Míra citací
65% obava
Hlavní etický problém
Vlastnictví obsahu
Zachováno uživateli
Ochrana komunity
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Přístup Stack Overflow k licencování pro AI rozlišuje mezi bezplatným a komerčním použitím. Platforma nadále nabízí bezplatný přístup k API a datovým dumpům pro nekomerční účely, vzdělávání a open-source projekty, čímž zachovává svůj závazek vůči vývojářské komunitě. Společnosti, které však vyvíjejí velké jazykové modely pro komerční účely, musí sjednat licenční dohody se Stack Overflow, přičemž cena závisí na faktorech jako velikost modelu, objem použití a vygenerované příjmy. CEO Stack Overflow Chandrasekar zdůraznil, že společnost usiluje o kompenzace pouze od organizací vyvíjejících LLM pro „velké, komerční účely“, nikoli od jednotlivých vývojářů či malých projektů. Tento duální licenční model umožňuje Stack Overflow generovat nové zdroje příjmů a zároveň chránit zájmy členů své komunity, z nichž mnozí přispívají bez nároku na přímou odměnu. Společnost se také zavázala reinvestovat licenční příjmy zpět do komunitních nástrojů a funkcí, čímž vytváří udržitelný model, kde příspěvky vývojářů přímo financují vylepšování platformy.
Viditelnost vývojářů ve výsledcích AI vyhledávání
Obsah Stack Overflow se nyní výrazně objevuje v AI generovaných odpovědích na hlavních platformách jako ChatGPT, Google Gemini, Perplexity a Microsoft Copilot. Google Gemini Cloud Assist výslovně uvádí při poskytování kódovacích řešení odpovědi ze Stack Overflow, zobrazuje původní otázku, odpověď i informace o autorovi přímo v AI odpovědi. ChatGPT od OpenAI zobrazuje odkazy na Stack Overflow v konverzacích o programování a SearchGPT—prototyp vyhledávání od OpenAI—zahrnuje výsledky ze Stack Overflow jak v konverzačních odpovědích, tak ve výsledcích vyhledávání. Tato viditelnost je pro vývojáře klíčová, protože přivádí návštěvnost zpět k jejich odpovědím a posiluje jejich pozici uznávaných expertů v oboru. Ne všechny AI platformy však uvádějí přiřazení stejně a vývojáři často obtížně zjišťují, které jejich odpovědi jsou citovány, jak často a v jakém kontextu napříč různými AI systémy.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Krize důvěry v AI generovaný obsah
Podle průzkumu Stack Overflow Developer Survey 2024 se prohlubuje propast mezi adopcí AI a důvěrou v ni: zatímco 76 % vývojářů používá nebo plánuje použít AI nástroje (oproti 70 % v roce 2023), hodnocení oblíbenosti AI kleslo ze 77 % na 72 %. Pouze 43 % vývojářů důvěřuje přesnosti AI nástrojů a průzkum identifikoval tři hlavní etické obavy, které vývojáři upřednostňují:
Riziko dezinformací: 79 % vývojářů se obává možnosti šíření dezinformací AI
Přiřazení a uznání: 65 % se obává chybějícího nebo nesprávného přiřazení zdrojů dat
Zaujatost a reprezentace: 50 % se obává zaujatosti, která nereprezentuje různorodé názory
Tento deficit důvěry přímo ovlivňuje, jak AI společnosti přistupují k získávání dat a trénování modelů. Vývojáři stále více požadují, aby AI systémy uváděly své zdroje, uznávaly komunitní příspěvky a zachovávaly standardy přesnosti odpovídající komunitně ověřenému obsahu Stack Overflow. Tlak na budování důvěryhodných AI systémů zvyšuje poptávku po vysoce kvalitních trénovacích datech, což činí ověřené, komunitně spravované znalosti Stack Overflow cennějšími než kdy dříve.
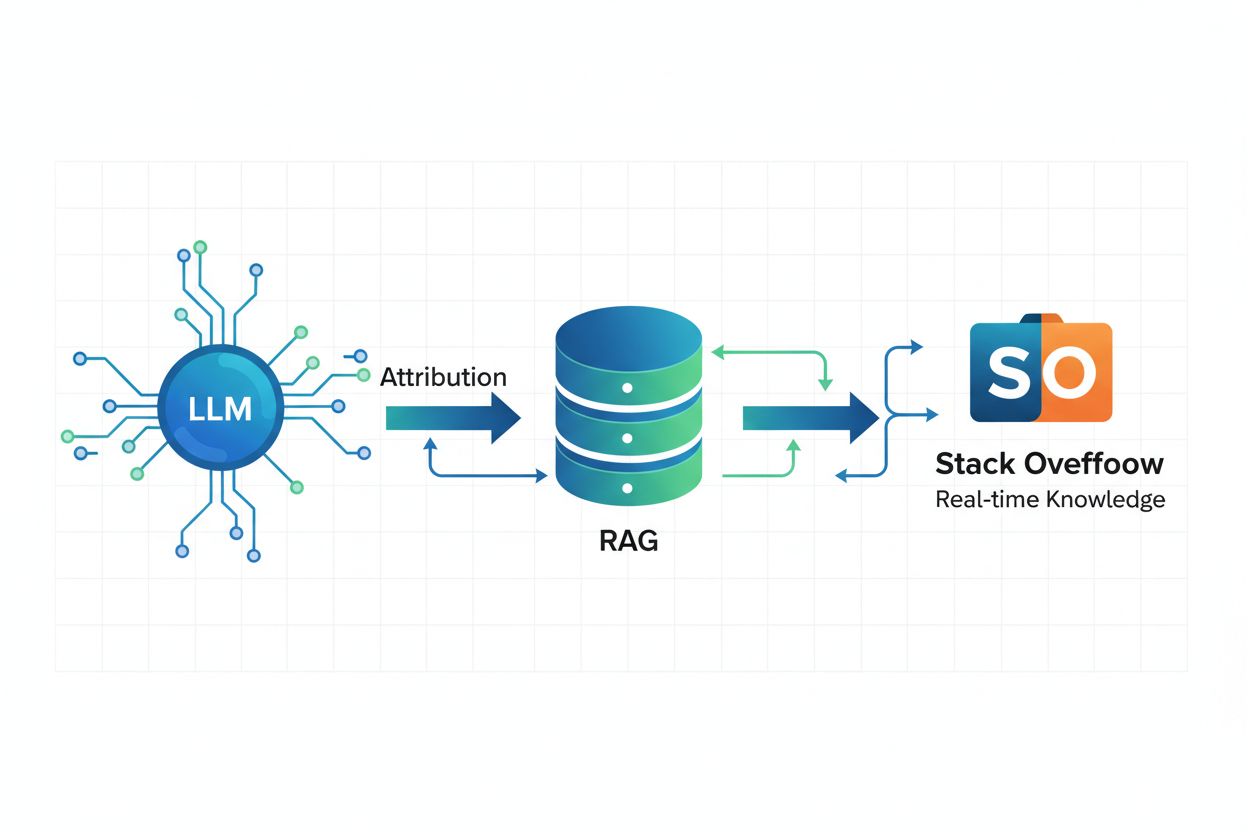
Retrieval Augmented Generation (RAG) a přiřazení zdrojů
Retrieval Augmented Generation (RAG) je AI rámec, který kombinuje velké jazykové modely s tradičními systémy vyhledávání informací, aby poskytoval aktuální, přesné a správně citované odpovědi. Namísto spoléhání se pouze na trénovací data „zmrazená“ v určitém čase umožňuje RAG AI systémům získávat v reálném čase informace z externích zdrojů, jako je Stack Overflow, takže odpovědi odrážejí nejnovější znalosti a osvědčené postupy. Všichni partneři OverflowAPI Stack Overflow implementovali RAG, aby umožnili správné přiřazení, což znamená, že když AI systém vygeneruje odpověď pomocí obsahu Stack Overflow, dokáže identifikovat a citovat konkrétní příspěvky, které odpověď ovlivnily. Tato technologie je obzvlášť silná v doménově specifických znalostech, kde záleží na přesnosti a aktuálnosti—for example, pokud AI systém generuje C# kód na základě konkrétních příkladů z vašeho kódu, zajistí, že vygenerovaný kód dodržuje standardy a konvence vašeho týmu. RAG snižuje riziko halucinací tím, že zakládá odpovědi AI na důvěryhodných, ověřených faktech, která uživatelé explicitně označí, a stává se tak technickým základem zodpovědného vývoje AI.
Monitorování vaší vývojářské viditelnosti
Vývojáři, kteří přispívají na Stack Overflow, by měli aktivně sledovat, jak se jejich obsah objevuje v AI generovaných odpovědích na různých platformách. Nástroje jako AmICited.com, XFunnel, Profound a další dnes nabízejí monitorování viditelnosti speciálně navržené pro vývojáře, aby zjistili, kde jsou jejich odpovědi citovány, jak často a v jakém kontextu napříč ChatGPT, Gemini, Perplexity a dalšími AI systémy. Klíčové metriky ke sledování zahrnují četnost citací (jak často je váš obsah zmiňován), sentiment (zda jsou zmínky pozitivní nebo neutrální), rozdělení podle platforem (které AI systémy vás citují nejvíce) a přiřazení zdrojů (zda je uvedeno správné uznání). Sledováním těchto metrik mohou vývojáři zjistit, které jejich odpovědi mají pro AI systémy nejvyšší hodnotu, rozpoznat nejžádanější témata a upravit svou strategii přispívání. Kromě toho sledování viditelnosti pomáhá vývojářům odhalit nepřesné nebo neúplné citace, což jim umožňuje aktualizovat své původní odpovědi nebo kontaktovat AI společnosti se žádostí o opravu. Tento proaktivní přístup mění pasivní přispívání obsahu ve strategii budování autority a vlivu v AI informačním ekosystému.
Osvědčené postupy pro komunitní přítomnost
Abyste maximalizovali viditelnost ve výsledcích AI vyhledávání a zajistili správné citování svých příspěvků ze Stack Overflow, zaměřte se na vytváření komplexních, dobře zdokumentovaných odpovědí, které řeší celý dotaz s jasným vysvětlením a funkčními ukázkami kódu. Pravidelně své odpovědi revidujte a aktualizujte podle vývoje technologií, protože AI systémy upřednostňují novější obsah—v průměru je obsah citovaný ve výsledcích AI o 25,7 % aktuálnější než to, co se umisťuje ve výsledcích Google. Budujte autoritu tím, že budete konzistentně poskytovat kvalitní odpovědi na více souvisejících témat, jelikož vývojáři v top 25 % podle webových zmínek mají 10x více AI citací než ostatní. Zapojte se do širší vývojářské komunity účastí v diskusích, odpovídáním na doplňující otázky a pomáhejte dalším členům zlepšovat jejich příspěvky. Nakonec zvažte, jak mohou vaše odpovědi využít AI systémy: strukturovaně odpovídejte s jasnými nadpisy, vkládejte relevantní úryvky kódu a poskytujte kontext, kdy a proč je konkrétní přístup vhodný, aby byl váš obsah užitečný jak pro lidské čtenáře, tak pro AI systémy, které potřebují informace přesně vytahovat a citovat.
Často kladené otázky
Jak jsou data ze Stack Overflow využívána při trénování AI?
50 milionů otázek a odpovědí ze Stack Overflow je zahrnuto do velkých jazykových modelů, protože představují kvalitní, komunitou ověřený technický obsah. AI společnosti jako OpenAI, Google a Meta tato data využívají k trénování svých modelů, aby lépe rozuměly a generovaly kód i technická řešení. Historicky byla tato data stahována zdarma, ale Stack Overflow nyní vyžaduje po komerčních AI vývojářích licencování dat prostřednictvím placených dohod.
Jaký je rozdíl mezi bezplatným a placeným přístupem k API Stack Overflow?
Stack Overflow nabízí bezplatný přístup k API pro nekomerční účely, vzdělávání a open-source projekty. Firmy vyvíjející velké jazykové modely pro komerční účely však musí sjednat placené licenční smlouvy. Cena závisí na faktorech jako je velikost modelu, objem využití a generované příjmy, což zajišťuje spravedlivé odměňování komunitních příspěvků.
Jak zajistím, aby mé odpovědi ze Stack Overflow citovala AI?
Vytvářejte komplexní, dobře zdokumentované odpovědi s jasným vysvětlením a funkčními příklady kódu. Průběžně své odpovědi aktualizujte dle vývoje technologií, protože AI systémy upřednostňují aktuálnější obsah. Budujte autoritu pravidelným poskytováním kvalitních odpovědí na více témat a strukturovaně odpovídejte s jasnými nadpisy a relevantními úryvky kódu, které AI systémy snadno vytáhnou a citují.
Co je RAG a proč je důležitý pro přiřazení zdrojů?
Retrieval Augmented Generation (RAG) je AI rámec, který kombinuje jazykové modely se systémy pro vyhledávání informací, aby poskytoval aktuální, přesné a správně citované odpovědi. RAG umožňuje AI systémům čerpat informace v reálném čase ze zdrojů jako Stack Overflow a citovat konkrétní příspěvky, které odpověď ovlivnily, což zajišťuje správné přiřazení a snižuje riziko halucinací.
Jak mohu sledovat svou viditelnost ve výsledcích AI vyhledávání?
Nástroje jako AmICited.com, XFunnel, Profound a další nabízejí monitorování viditelnosti, které je navrženo tak, aby vývojářům ukázalo, kde jsou jejich odpovědi citovány napříč ChatGPT, Gemini, Perplexity a dalšími AI systémy. Tyto nástroje sledují četnost citací, sentiment, zastoupení na platformách a přiřazení zdrojů, což vám pomůže pochopit, které vaše odpovědi mají pro AI systémy nejvyšší hodnotu.
Jaké jsou etické obavy ohledně využívání komunitního obsahu AI?
Podle průzkumu Stack Overflow Developer Survey 2024 mají vývojáři tři hlavní etické obavy: riziko dezinformací (79 % znepokojených), chybějící či nesprávné přiřazení zdrojů (65 %) a zaujatost, která nereprezentuje různorodé pohledy (50 %). Tyto obavy vyžadují správné licencování, požadavky na přiřazení zdrojů a kvalitní trénovací data z ověřených zdrojů jako Stack Overflow.
Jak licence Stack Overflow chrání vývojáře?
Obsah Stack Overflow je licencován pod Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), což právně vyžaduje, aby kdokoli, kdo obsah využívá, uvedl původního autora. Stack Overflow nyní vyžaduje, aby všichni API partneři zahrnuli požadavky na přiřazení zdrojů do svých smluv, což zajišťuje, že vývojáři obdrží zasloužené uznání, pokud jsou jejich odpovědi využity AI systémy.
Jaké nástroje mohu použít ke sledování AI citací mého obsahu?
Existuje několik nástrojů pro sledování AI citací, včetně AmICited.com (specializovaný na AI monitoring), XFunnel (podnikové monitorování LLM), Profound (pokročilé GEO sledování), Semrush AI Toolkit, BrightEdge a další. Tyto nástroje vám pomohou zjistit, která AI platforma vás cituje, jak často, v jakém kontextu a zda je uvedeno správné přiřazení.
Monitorujte svou viditelnost Stack Overflow ve vyhledávání AI
Sledujte, jak je vaše technická odbornost citována napříč ChatGPT, Gemini, Perplexity a dalšími AI platformami. Získejte okamžité přehledy o své vývojářské viditelnosti a optimalizujte svou komunitní přítomnost.
Role Wikipedie v trénovacích datech pro AI: Kvalita, dopad a licencování
Zjistěte, jak Wikipedie slouží jako klíčový dataset pro trénování AI, jaký má vliv na přesnost modelů, licenční ujednání a proč na ní firmy vyvíjející umělou in...
Můžete skutečně ovlivnit, co se AI naučí o vaší značce během tréninku? Je to vůbec možné?
Diskuze komunity o ovlivňování tréninkových dat AI týkajících se vaší značky. Skutečné postřehy o tom, jak tvorba obsahu ovlivňuje, co se AI systémy naučí a zap...
Jak se odhlásit z AI tréninku na hlavních platformách
Kompletní průvodce odhlášením ze shromažďování dat pro AI trénink na ChatGPT, Perplexity, LinkedIn a dalších platformách. Naučte se krok za krokem chránit svá d...
8 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.