
Jak otestovat přístup AI crawlerů na váš web
Zjistěte, jak otestovat, zda mají AI crawlery jako ChatGPT, Claude a Perplexity přístup k obsahu vašeho webu. Objevte testovací metody, nástroje a osvědčené pos...
9 min čtení

Zjistěte, jak stealth crawlery obcházejí direktivy v robots.txt, jaké technické mechanismy využívají k obcházení detekce a jak ochránit svůj obsah před neoprávněným AI scrapováním.
Webové crawling se zásadně proměnilo s nástupem systémů umělé inteligence. Na rozdíl od tradičních vyhledávačů, které respektují zavedené protokoly, některé AI společnosti začaly používat stealth crawling—záměrné maskování aktivity botů s cílem obejít omezení webů a direktivy robots.txt. Tato praxe představuje výrazný odklon od spolupráce, která charakterizovala webový crawling téměř tři dekády, a vyvolává zásadní otázky o vlastnictví obsahu, etice dat a budoucnosti otevřeného internetu.

Nejvýraznějším případem je Perplexity AI, AI-powered answer engine, která byla přistižena při používání nedeclarovaných crawlerů pro přístup k obsahu výslovně blokovanému majiteli webu. Vyšetřování společnosti Cloudflare odhalilo, že Perplexity provozuje jak deklarované crawlery (kteří se poctivě identifikují), tak stealth crawlery (které se vydávají za běžné webové prohlížeče), aby obešli pokusy o blokaci. Tato strategie dvojího crawleru umožňuje Perplexity dále sklízet obsah i v případě, že web výslovně zakáže přístup v robots.txt nebo ve firewallu.
Robots.txt je od roku 1994 hlavním mechanismem internetu pro řízení chování crawlerů, kdy byl zaveden jako součást Robots Exclusion Protocol. Tento jednoduchý textový soubor, umístěný v kořenovém adresáři webu, obsahuje instrukce, které části webu smí a nesmí crawlery navštěvovat. Typický zápis v robots.txt může vypadat takto:
User-agent: GPTBot
Disallow: /
Tato instrukce říká crawleru GPTBot od OpenAI, aby na webu neprocházel žádný obsah. Robots.txt však funguje na základním principu: je zcela dobrovolný. Instrukce v robots.txt nemohou vynutit chování crawleru; je na něm, zda je bude respektovat. Zatímco Googlebot a další respektovaní crawlery tyto direktivy ctí, protokol nemá žádný vynucovací mechanismus. Crawler může robots.txt jednoduše ignorovat a technicky mu není možné v tom zabránit.
| Crawler | Deklarovaný User Agent | Respektuje robots.txt | Stav souladu |
|---|---|---|---|
| GPTBot (OpenAI) | Mozilla/5.0 (compatible; GPTBot/1.0) | Ano | V souladu |
| ChatGPT-User | Mozilla/5.0 (compatible; ChatGPT-User/1.0) | Ano | V souladu |
| ClaudeBot (Anthropic) | Mozilla/5.0 (compatible; Claude-Web/1.0) | Ano | V souladu |
| Google-Extended | Mozilla/5.0 (compatible; Google-Extended/1.0) | Ano | V souladu |
| Perplexity-User | Mozilla/5.0 (compatible; Perplexity-User/1.0) | Ne | Není v souladu |
| Nedeklarovaný stealth crawler | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) Chrome/124.0.0.0 | Ne | Stealth/Obcházející |
Rozdíl mezi poctivými a „neposlušnými“ crawlery je čím dál důležitější. Renomované AI firmy jako OpenAI a Anthropic zveřejňují své IP rozsahy, mají transparentní dokumentaci a respektují přání majitelů webů. Naproti tomu stealth crawlery cíleně skrývají svoji identitu a ignorují pokyny webů, přistupují k robots.txt spíše jako k překážce než jako k pravidlu.
Podrobné šetření Cloudflare o chování crawlerů Perplexity je dosud nejobsáhlejší dokumentací stealth crawlingu. Výzkumný tým vytvořil několik testovacích domén s jednoznačnými robots.txt direktivami zakazujícími jakýkoliv automatizovaný přístup. Přesto Perplexity i nadále poskytovala detailní informace o obsahu těchto domén po dotazu přes AI rozhraní.
Vyšetřování odhalilo sofistikovanou dvouproudou strategii. Deklarovaný crawler Perplexity-User provádí 20–25 milionů žádostí denně a poctivě se identifikuje. Pokud však narazí na síťový blok nebo omezení v robots.txt, Perplexity nasazuje nedeklarovaný stealth crawler, který dělá dalších 3–6 milionů žádostí denně a vydává se za legitimní prohlížeč Chrome na macOS. Tento stealth crawler používá obecný user agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36.
Stealth crawler využívá více technik obcházení najednou. Rotuje IP adresy, které nejsou uvedeny v oficiální dokumentaci Perplexity, takže majitelé webů nemohou blokovat podle známé infrastruktury. Dále mění zdrojová čísla autonomních systémů (ASN), tedy identifikátory poskytovatelů sítě, aby ještě více ztížil dohledání původu. Aktivita byla pozorována na desítkách tisíc domén, kde generovala miliony požadavků denně.
V přímém kontrastu Cloudflare provedl stejné testy s ChatGPT a zaznamenal zcela odlišné chování. ChatGPT-User stáhl robots.txt, rozpoznal zákaz a ihned přestal s crawlingem. Při blokaci na síťové úrovni ChatGPT neprováděl žádné alternativní pokusy s jiným user agentem ani z jiné IP adresy. To dokazuje, že dodržování pravidel je technicky možné a firmy, které robots.txt ignorují, tak činí na základě obchodního rozhodnutí, nikoliv kvůli technickým omezením.
Stealth crawlery využívají sofistikovaný arzenál technik, kterými obcházejí detekci a překonávají omezení webů. Porozumění těmto mechanismům je zásadní pro tvorbu účinné obrany:
Spoofování user agentu: Crawlery se vydávají za legitimní prohlížeče tím, že používají realistické user agent stringy odpovídající skutečným prohlížečům Chrome, Safari či Firefox. Na první pohled jsou tak nerozeznatelné od lidských návštěvníků.
Rotace IP adres a proxy sítě: Místo crawlů z jediné IP adresy nebo známého datacentra rozkládají stealth crawlery požadavky mezi stovky až tisíce různých IP, často přes rezidenční proxy sítě, které směrují provoz přes skutečná domácí připojení.
Rotace ASN: Změnou čísla autonomního systému (identifikátoru poskytovatele připojení) se crawlery tváří, že pocházejí od různých poskytovatelů, což znesnadňuje blokaci na úrovni IP.
Simulace headless prohlížeče: Moderní stealth crawlery spouštějí skutečné prohlížečové jádro (Chrome Headless, Puppeteer, Playwright), vykonávají JavaScript, spravují cookies a simulují lidské interakce včetně pohybů myši a náhodných prodlev.
Manipulace s rychlostí: Místo rychlého sekvenčního stahování, které by spustilo detekci, zavádí pokročilé crawlery proměnlivé prodlevy mezi požadavky a napodobují přirozené lidské procházení.
Randomizace fingerprintu: Crawlery mění fingerprint prohlížeče—vlastnosti jako rozlišení obrazovky, časové pásmo, nainstalované fonty nebo podpis TLS handshake—aby se vyhnuly detekci systémem device fingerprinting.
Tyto techniky používají v kombinaci, čímž vytvářejí vícevrstvou strategii, která překonává tradiční metody detekce. Crawler může současně použít podvržený user agent, rezidenční proxy, náhodné prodlevy a randomizovaný fingerprint, takže je prakticky nerozeznatelný od legitimního provozu.
Rozhodnutí nasadit stealth crawlery je poháněno hladem po datech. Trénování špičkových velkých jazykových modelů vyžaduje obrovské množství kvalitních textových dat. Nejhodnotnější obsah—autorské výzkumy, články za paywallem, exkluzivní diskuse na fórech či odborné znalostní báze—je často výslovně omezen majiteli webů. Firmy pak stojí před volbou: respektovat pravidla webu a spokojit se s méně kvalitními daty, nebo omezení obejít a získat prémiový obsah.
Konkurenční tlak je obrovský. AI firmy investují miliardy dolarů do vývoje modelů a věří, že lepší trénovací data znamenají lepší modely, což přináší výhodu na trhu. Pokud konkurence neváhá scrapovat omezený obsah, respektování robots.txt se stává konkurenční nevýhodou. Výsledkem je spirála dolů, kdy je etické chování „trestáno“ trhem.
Navíc mechanismy prosazování téměř neexistují. Majitelé webů nemohou technicky zabránit odhodlanému crawleru v přístupu k jejich obsahu. Právní kroky jsou pomalé, drahé a nejisté. Pokud web nepodnikne formální právní kroky—což vyžaduje prostředky, které většina organizací nemá—hrozí rogue crawleru minimální riziko. Poměr rizika a odměny výrazně nahrává ignorování robots.txt.
Právní prostředí je navíc nejasné. I když porušení robots.txt může znamenat porušení podmínek služby, právní status scrapování veřejně dostupných informací se liší podle jurisdikce. Některé soudy rozhodly, že scrapování veřejných dat je legální, jiné se odvolaly na zákon o počítačových podvodech a zneužití. Tato nejistota povzbuzuje firmy ochotné pohybovat se v šedé zóně.
Důsledky stealth crawlingu jdou daleko za rámec technických nepříjemností. Reddit zjistil, že jeho uživatelský obsah byl používán k trénování AI modelů bez souhlasu či kompenzace. Reakcí bylo dramatické zvýšení cen API, aby si AI firmy musely za data zaplatit, přičemž CEO Steve Huffman explicitně vyzval Microsoft, OpenAI, Anthropic a Perplexity za „bezplatné využívání dat Redditu“.
Twitter/X zvolil ještě razantnější postup: dočasně zablokoval veškerý nepřihlášený přístup k tweetům a zavedl přísné limity i pro autentizované uživatele. Elon Musk prohlásil, že jde o nouzové opatření proti „stovkám organizací“ scrapujících data z Twitteru, což zhoršovalo uživatelský zážitek a spotřebovávalo obrovské serverové zdroje.
Vydavatelé zpráv jsou obzvlášť hlasití. New York Times, CNN, Reuters i The Guardian aktualizovali své robots.txt tak, aby blokovali GPTBot od OpenAI. Někteří vydavatelé přistoupili k právním krokům—New York Times podal žalobu na OpenAI za porušení autorských práv. Associated Press zvolil jiný přístup a vyjednal licenční smlouvu s OpenAI o poskytování vybraného zpravodajského obsahu výměnou za přístup k AI technologiím—jeden z prvních takových komerčních případů.
Stack Overflow čelil koordinovaným scrapovacím operacím, kdy útočníci vytvářeli tisíce účtů, používali pokročilé techniky maskování, aby splynuli s běžnými uživateli, a hromadně získávali příklady kódu. Tým platformy dokumentoval, jak scrapery používají identické TLS fingerprinty napříč mnoha spojeními, udržují trvalé sessiony a dokonce platí za prémiové účty, aby nebyli odhaleni.
Společným jmenovatelem všech těchto případů je ztráta kontroly. Tvůrci obsahu už nemohou rozhodovat, jak je jejich práce využívána, kdo z ní těží nebo zda za ni dostanou zaplaceno. To představuje zásadní změnu v mocenské dynamice internetu.
Naštěstí vznikají pokročilé nástroje pro detekci a blokování stealth crawlerů. Cloudflare AI Crawl Control (dříve AI Audit) poskytuje přehled o tom, které AI služby přistupují k vašemu obsahu a zda respektují pravidla robots.txt. Nová funkce Robotcop jde dál a automaticky převádí direktivy robots.txt do pravidel Web Application Firewallu (WAF), která vymáhají soulad na síťové úrovni.
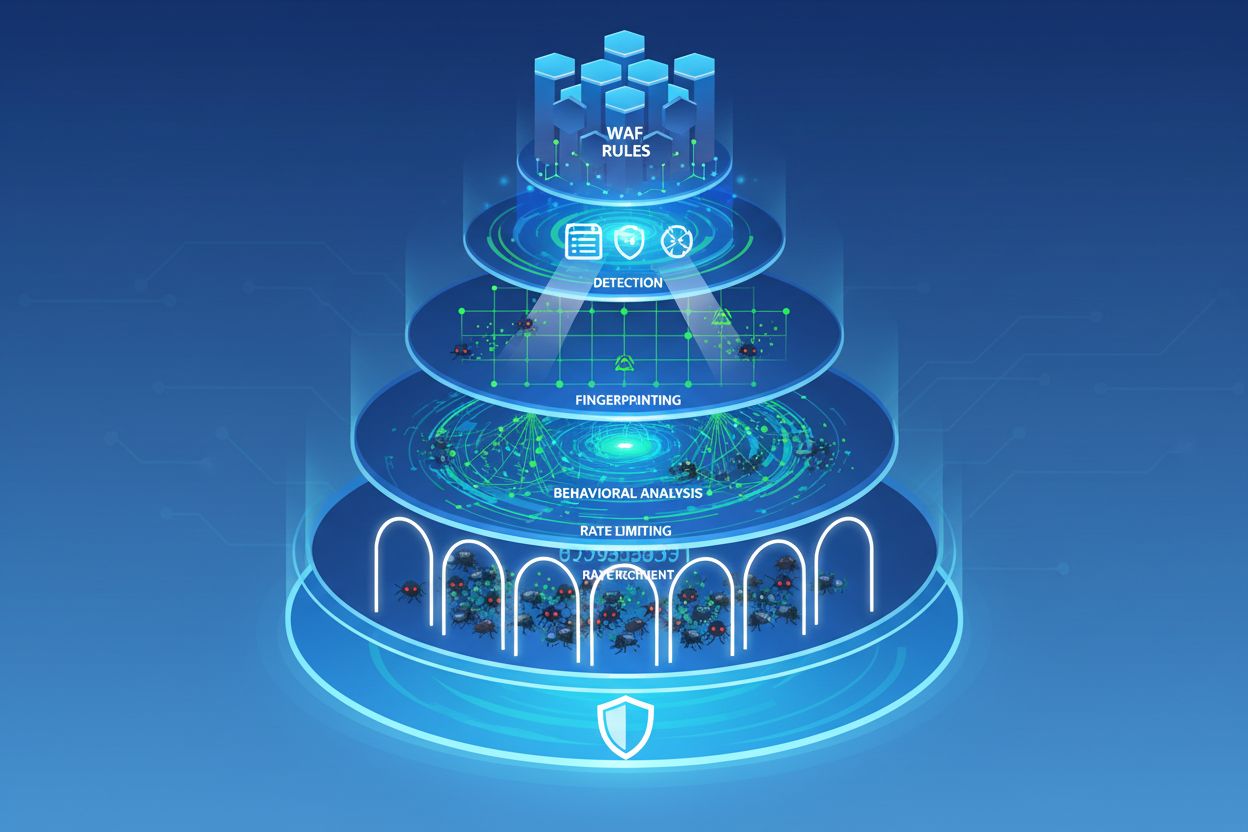
Device fingerprinting představuje silnou techniku detekce. Analýzou desítek signálů—verze prohlížeče, rozlišení obrazovky, operačního systému, nainstalovaných fontů, podpisů TLS handshake a chování—mohou bezpečnostní systémy odhalit nesrovnalosti, které prozrazují botí aktivitu. Crawler, který se vydává za Chrome na macOS, může mít TLS fingerprint neodpovídající skutečnému Chromu nebo mu mohou chybět některá API, která reálný prohlížeč vystavuje.
Behaviorální analýza zkoumá, jak se návštěvníci na webu chovají. Skuteční uživatelé mají přirozené vzorce: čtou obsah, logicky procházejí stránky, dělají chyby a opravují je. Boti často vykazují typické znaky: procházejí stránky v nenormálních sekvencích, načítají zdroje v neobvyklém pořadí, nikdy neinteragují s interaktivními prvky nebo přistupují k mnoha stránkám v nemožných intervalech.
Rate limiting zůstává účinný, pokud je kombinován s dalšími metodami. Přísné limity požadavků na IP adresu, session nebo uživatelský účet mohou scrapery natolik zpomalit, že se operace stane neekonomickou. Exponenciální backoff—kdy každé porušení prodlužuje čekací dobu—dál odrazuje automatizované útoky.
AmICited řeší zásadní mezeru: přehled o tom, které AI systémy skutečně citují vaši značku a obsah. Zatímco nástroje jako Cloudflare AI Crawl Control ukazují, kteří crawlery přistupují na váš web, AmICited jde dál a sleduje, které AI systémy—ChatGPT, Perplexity, Google Gemini, Claude a další—vaše informace skutečně citují ve svých odpovědích.
Tento rozdíl je klíčový. Přístup crawleru na váš web ještě neznamená, že bude váš obsah citován. Naopak může být vaše práce citována i AI systémy, které k ní přistoupily nepřímo (např. přes Common Crawl datasety), nikoliv přímým crawlingem. AmICited přináší chybějící důkaz: že váš obsah je skutečně využíván AI systémy, včetně detailních informací o tom, jak je citován.
Platforma odhaluje stealth crawlery přistupující k vašemu obsahu analýzou provozních vzorců, user agentů a behaviorálních signálů. Pokud AmICited detekuje podezřelou crawler aktivitu—zejména nedeklarované crawlery s podvrženým user agentem—označí to jako potenciální stealth crawling. Majitelé webů tak mohou reagovat na nepoctivé crawlery a zároveň si zachovat přehled o legitimním AI přístupu.
Upozornění v reálném čase vás informují při detekci stealth crawlerů, což umožňuje rychlou reakci. Integrace s vašimi SEO a bezpečnostními pracovními postupy znamená, že můžete data z AmICited využít i v širší obsahové strategii a bezpečnostní politice. Pro organizace, které řeší využití svého obsahu v éře AI, přináší AmICited klíčové informace.
Ochrana obsahu před stealth crawlery vyžaduje vícevrstvý přístup:
Nastavte jasná pravidla v robots.txt: Přestože stealth crawlery mohou robots.txt ignorovat, poctivé crawlery ho budou respektovat. Výslovně zakažte crawlery, které nechcete na svém webu. Přidejte direktivy pro známé AI crawlery jako GPTBot, ClaudeBot a Google-Extended.
Používejte WAF pravidla: Využijte pravidla Web Application Firewallu k vynucení politiky robots.txt na síťové úrovni. Nástroje jako Cloudflare Robotcop mohou tato pravidla generovat automaticky z vašeho robots.txt.
Pravidelně sledujte chování crawlerů: Využijte nástroje jako AmICited a Cloudflare AI Crawl Control ke sledování, kteří crawlery přistupují na váš web a zda respektují vaše pravidla. Pravidelné monitorování vám umožní včas odhalit stealth crawlery.
Implementujte device fingerprinting: Zavádějte řešení device fingerprintingu, která analyzují vlastnosti prohlížeče a chování návštěvníků a odhalí boty vydávající se za běžné uživatele.
Pro citlivý obsah zvažte autentizaci: Pro nejcennější obsah zvažte vyžadování přihlášení nebo paywall. Zabráníte tak přístupu legitimních i stealth crawlerů k omezenému obsahu.
Sledujte nové taktiky crawlerů: Techniky obcházení crawlerů se neustále vyvíjejí. Odebírejte bezpečnostní bulletiny, sledujte výzkum v oboru a aktualizujte obranu podle nových trendů.
Současný stav—kdy některé AI firmy robots.txt otevřeně ignorují, zatímco jiné jej respektují—je neudržitelný. Již vznikají první průmyslové i regulatorní reakce. Internet Engineering Task Force (IETF) pracuje na rozšířeních robots.txt, která umožní detailnější řízení nad AI trénováním a využitím dat. Tato rozšíření by umožnila majitelům webů nastavit odlišné politiky pro vyhledávače, AI trénink i další účely.
Web Bot Auth, nově navržený otevřený standard, umožňuje crawlerům kryptograficky podepisovat své požadavky a prokázat tak svoji identitu a legitimitu. OpenAI ChatGPT Agent už tento standard implementuje, což dokazuje, že transparentní a ověřitelné identifikace crawlerů jsou technicky možné.
Regulační změny jsou pravděpodobné. Přístup Evropské unie ke správě AI, spolu s rostoucím tlakem tvůrců obsahu a vydavatelů, naznačuje, že budoucí legislativa může přinést právní povinnost souladu crawlerů. Firmy ignorující robots.txt mohou čelit nejen poškození reputace, ale i postihům.
Odvětví směřuje k modelu, kde se transparentnost a soulad stávají konkurenční výhodou místo přítěže. Firmy, které respektují přání majitelů webů, jasně identifikují své crawlery a poskytují tvůrcům hodnotu, si budují důvěru a udržitelné vztahy. Ty spoléhající na stealth taktiky čelí rostoucím technickým, právním i reputačním rizikům.
Pro majitele webů je zpráva jasná: proaktivní monitoring a prosazování jsou nezbytné. Implementací výše uvedených nástrojů a postupů můžete udržet kontrolu nad využitím svého obsahu v AI éře a zároveň podpořit rozvoj odpovědných AI systémů, které respektují základní principy otevřeného internetu.
Stealth crawler úmyslně maskuje svou identitu tím, že se vydává za legitimní webový prohlížeč a skrývá svůj skutečný původ. Na rozdíl od běžných crawlerů, kteří se identifikují unikátním user agentem a respektují robots.txt, stealth crawlery používají podvržené user agenty, rotují IP adresy a využívají techniky obcházení, aby překonaly omezení webů a získaly obsah, ke kterému byl přístup výslovně zakázán.
AI firmy ignorují robots.txt především kvůli hladu po datech pro trénování velkých jazykových modelů. Nejhodnotnější obsah bývá často omezen majiteli webů, což vytváří konkurenční motivaci omezení obejít. Navíc mechanismy prosazování prakticky neexistují—majitelé webů nemohou technicky zabránit odhodlaným crawlerům a právní postupy jsou pomalé a drahé, což z pohledu rizika a odměny nahrává ignorování robots.txt.
I když nemůžete zcela zabránit všem stealth crawlerům, můžete výrazně omezit neoprávněný přístup pomocí vícevrstvých obran. Zaveďte jasná pravidla v robots.txt, nastavte WAF pravidla, použijte device fingerprinting, monitorujte chování crawlerů pomocí nástrojů jako AmICited a pro citlivý obsah zvažte autentizaci. Klíčem je kombinace více technik, ne spoléhání pouze na jedno řešení.
Spoofování user agentu znamená, že crawler se vydává za legitimní webový prohlížeč tím, že použije realistický user agent string (např. Chrome nebo Safari). Díky tomu vypadá crawler jako lidský návštěvník a ne bot. Stealth crawlery tuto techniku využívají k obcházení blokace založené na user agentu a k vyhnutí se detekci bezpečnostními systémy, které hledají botí identifikátory.
Stealth crawlery můžete odhalit analýzou vzorců provozu pro podezřelé chování: žádosti z neobvyklých IP adres, nemožné sekvence navigace, chybějící vzory lidské interakce nebo žádosti, které neodpovídají otisku legitimního prohlížeče. Nástroje jako AmICited, Cloudflare AI Crawl Control a řešení pro device fingerprinting mohou tuto detekci automatizovat analýzou desítek signálů najednou.
Právní status obcházení crawlerů se liší podle jurisdikce. I když porušení robots.txt může znamenat porušení podmínek služby, právní status scrapingu veřejně dostupných informací je nejasný. Některé soudy rozhodly, že scraping je legální, jiné shledaly porušení zákona o počítačových podvodech a zneužití. Tato právní nejistota povzbuzuje firmy, které chtějí působit v šedé zóně, i když se objevují nové regulatorní změny.
AmICited poskytuje přehled o tom, které AI systémy skutečně citují vaši značku a obsah, a jde tak dál než jen sledování přístupujících crawlerů. Platforma odhaluje stealth crawlery analýzou provozních vzorců a signálů, zasílá upozornění v reálném čase při detekci podezřelé aktivity a integruje se s vašimi SEO i bezpečnostními procesy, abyste měli kontrolu nad využitím svého obsahu.
Deklarované crawlery se otevřeně identifikují unikátním user agentem, zveřejňují své IP rozsahy a obvykle respektují robots.txt. Patří sem například OpenAI GPTBot a Anthropic ClaudeBot. Nedeclarované crawlery skrývají svou identitu tím, že se vydávají za prohlížeče, používají podvržené user agenty a úmyslně ignorují omezení webu. Výrazným příkladem nedeclarovaného crawleru je stealth crawler společnosti Perplexity.
Zjistěte, které AI systémy citují vaši značku a detekujte stealth crawlery přistupující k vašemu obsahu díky pokročilé monitorovací platformě AmICited.
Zjistěte, jak otestovat, zda mají AI crawlery jako ChatGPT, Claude a Perplexity přístup k obsahu vašeho webu. Objevte testovací metody, nástroje a osvědčené pos...

Naučte se, jak strategicky rozhodovat o blokování AI crawlerů. Vyhodnoťte typ obsahu, zdroje návštěvnosti, modely příjmů a konkurenční pozici pomocí našeho komp...

Zjistěte, jak Web Application Firewall poskytuje pokročilou kontrolu nad AI crawlery nad rámec robots.txt. Implementujte WAF pravidla na ochranu svého obsahu př...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.