
PR řízené daty: Jak vytvářet výzkum, který AI chce citovat
Naučte se vytvářet původní výzkum a PR obsah řízený daty, který AI systémy aktivně citují. Objevte 5 atributů obsahu hodného citace a strategie pro maximalizaci...
8 min čtení

Zjistěte, jak se vlastní průzkumná data a originální statistiky stávají magnetem na citace pro LLM. Objevte strategie, jak zvýšit viditelnost v AI a získat více citací od ChatGPT, Perplexity a Google AI Overviews.
Velké jazykové modely si data nevymýšlejí – čerpají je z ověřitelných zdrojů. Pokud váš tým publikuje unikátní statistiky nebo originální metodiky, dočasně vlastníte toto poznání a dáváte LLM důvod vás citovat, aby mohly své odpovědi ověřit. Na tomto principu stojí to, co IDX označuje jako „Autoritní setrvačník“ – systém, kdy se vlastní výzkum stává nejsilnějším magnetem na citace.
Mechanismus je jednoduchý: AI modely hodnotí zdroje podle toho, zda umí tvrzení ověřit z více kanálů. Pokud zveřejníte originální výzkum, vytvoříte znalostní aktivum, které nikde jinde na webu neexistuje. Tato jedinečnost nutí LLM citovat právě váš zdroj, pokud chtějí data použít do svých odpovědí. Kampaň pro The Zebra, pojišťovací platformu, toto pravidlo skvěle ilustruje – kombinace vlastního výzkumu a digitálního PR přinesla přes 1 580 kvalitních mediálních odkazů a zvýšila organickou návštěvnost o 354 %.
Podle nedávného výzkumu označilo 48,6 % SEO expertů digitální PR za nejefektivnější taktiku na získávání odkazů pro rok 2025. Skutečná síla je ale v tom, co následuje: pokud jsou vaše vlastní data šířena napříč různými kvalitními doménami pomocí digitálního PR, potvrzujete svou autoritu v několika znalostních sítích současně. Právě tuto vícekanálovou validaci LLM vyhledávají, když rozhodují, zda vaši značku citovat.
Klíčové zjištění: vlastní data vytvářejí to, čemu výzkumníci říkají „dočasné vlastnictví znalostí“. Na rozdíl od obecného obsahu, který soupeří s tisíci podobných článků, je váš originální výzkum jediným zdrojem konkrétních dat. Pravidlo vzácnosti zvyšuje pravděpodobnost, že vás LLM ocituje, protože je to jediný způsob, jak tento údaj do odpovědi zahrnout.
Porozumění tomu, jak LLM skutečně vybírají a získávají zdroje, je zásadní pro optimalizaci pro citace. Tyto systémy nefungují jako tradiční vyhledávače. Pracují na dvou odlišných úrovních znalostí: parametrické paměti (znalosti uložené během tréninku) a získané znalosti (aktuální informace získané pomocí Retrieval-Augmented Generation, tedy RAG).
Parametrické znalosti představují vše, co LLM „vědí“ z předtrénování. Tyto znalosti jsou statické a dané časovým limitem tréninku modelu. Přibližně 60 % dotazů na ChatGPT je zodpovězeno pouze z parametrických znalostí bez jakéhokoli webového vyhledávání. Entity často zmiňované v autoritativních zdrojích během tréninku mají silnější neuronové reprezentace a jsou tedy častěji vybavovány. Wikipedia tvoří přibližně 22 % tréninkových dat hlavních LLM, což vysvětluje častý výskyt jejích citací v AI odpovědích.
Získané znalosti fungují jinak. Pokud LLM potřebuje aktuální informaci, využije RAG systémy, které kombinují sémantické vyhledávání (husté vektory) s klíčovým slovem (BM25) pomocí Reciprocal Rank Fusion. Výzkum ukazuje, že hybridní vyhledávání zlepšuje výsledky o 48 % oproti jednotlivým metodám. Systém poté přeřadí výsledky pomocí cross-encoder modelů a nejlepších 5–10 fragmentů vloží do promptu LLM jako kontext.
| Signál | Priorita v tradičním SEO | Priorita pro citace LLM | Proč je důležitý |
|---|---|---|---|
| Autorita domény | Vysoká (klíčový faktor) | Slabá/Neutrální | LLM preferují strukturu obsahu před silou domény |
| Počet zpětných odkazů | Vysoký (hlavní signál) | Slabý/Neutrální | LLM hodnotí důvěryhodnost jinak |
| Struktura obsahu | Střední | Kritická | Jasné nadpisy a odpovědní bloky jsou zásadní pro extrakci |
| Vlastní data | Nízká | Velmi vysoká | Unikátní informace nutí k citaci |
| Vyhledávanost značky | Nízká | Nejvyšší (korel. 0,334) | Signalizuje autoritu a poptávku |
| Čerstvost | Střední | Vysoká | LLM preferují aktuálně aktualizovaný obsah |
| E-E-A-T signály | Střední | Vysoká | Odbornost autora a transparentnost jsou podstatné |
Zásadní rozdíl: LLM neřadí stránky, ale extrahují sémantické bloky. Stránka s nízkými tradičními SEO metrikami, ale s jasnou strukturou a vlastními daty může překonat autoritativní stránku s vágní prezentací. Citace tedy závisí spíš na čitelnosti pro stroj a jasnosti obsahu než na tradičních SEO ukazatelích.
Metriky důležité pro viditelnost v AI se zásadně liší od tradičních SEO signálů. Dvacet let určovaly úspěch autorita domény, počet odkazů a pozice na klíčová slova. V roce 2025 tyto metriky pro citace LLM ztrácejí význam a vzniká nová hierarchie podle toho, jak AI skutečně hodnotí a vybírá zdroje.
Vyhledávanost značky je dnes nejsilnějším prediktorem citací v LLM, s korelačním koeficientem 0,334 – výrazně vyšším než jakákoli tradiční SEO metrika. Dává to smysl: pokud miliony lidí hledají vaši značku, signalizuje to skutečnou autoritu a poptávku. LLM tento signál rozpoznají a při rozhodování o citaci mu dávají velkou váhu. Naopak zpětné odkazy vykazují slabou nebo neutrální korelaci s AI citacemi, což odporuje letům SEO dogmat.
Tento posun se týká i hodnocení obsahu. Přidání statistik do obsahu zvyšuje AI viditelnost o 22 %. Zařazení citací zvyšuje viditelnost o 37 %. Originální výzkum je citován 3× častěji než obecný obsah. Nej nejde o marginální zlepšení, ale o zásadní změnu, jak LLM hodnotí kvalitu zdroje.
| Metrika | Staré zaměření (před 2024) | Nové zaměření (2025+) | Dopad na citace LLM |
|---|---|---|---|
| Kvalita odkazů | Skóre autority domény (DA/DR) | Tématická relevance & redakční kontext | Ukotvení a rozmanitost zdrojů |
| Strategie anchor textu | Přesné klíčové slovo | Značkové zmínky/entity | Rozpoznání entity a konzistence |
| Typ obsahu | Guest posty (objem) | Originální výzkum/data žurnalistika | 3× vyšší pravděpodobnost citace |
| Měření cíle | Zvýšení pozic ve vyhledávači | Míra citací v AI přehledech | Důvěra a ověření autority |
| Přístup k oslovení | Získávání odkazů | Budování vztahů/přinášení hodnoty | Vyšší redakční kvalita |
Tato matice odhaluje zásadní poznatek: značky, které vítězí v AI viditelnosti, nemusí mít nejvíc zpětných odkazů nebo nejvyšší autoritu domény. Jsou to značky vytvářející původní výzkum, konzistentní značkové signály a obsah strukturovaný pro strojovou extrakci. Konkurenční výhoda se přesunula od kvantity odkazů ke kvalitě a jedinečnosti obsahu.
Vlastní průzkumná data hrají v AI strategii specifickou roli. Na rozdíl od obecných průmyslových zpráv, které LLM najdou z více zdrojů, lze vaše originální průzkumná data citovat pouze z vašeho webu. To vytváří výhodu v citacích, kterou konkurence se silnými zpětnými odkazy nemůže překonat.
Průzkumná data fungují proto, že poskytují LLM tzv. „grounding“ – ověřitelný důkaz potvrzující tvrzení. Pokud uvedete, že „78 % marketingových lídrů upřednostňuje AI viditelnost“, LLM může vaši studii uvést jako důkaz. Pokud byste tato data neměli, šlo by o spekulaci a LLM by buď tvrzení přeskočilo, nebo ocitovalo konkurenční výzkum.
Nejúčinnější průzkumná data odpovídají konkrétním otázkám cílové skupiny:
Dopad je měřitelný. Výzkumy ukazují, že přidání statistik zvyšuje AI viditelnost o 22 %, citace o 37 %. Originální výzkum je citován 3× častěji než obecný obsah. Tyto multiplikátory se násobí, pokud v jednom obsahu zkombinujete více typů vlastních dat.
Klíčem je transparentnost. LLM hodnotí metodiku stejně přísně jako výsledky. Pokud je metodika průzkumu kvalitní, velikost vzorku dostatečná a zjištění prezentováno poctivě (včetně omezení), LLM vás ocitují s důvěrou. Pokud je metodika nejasná nebo jsou výsledky účelově vybrané, LLM váš zdroj znevýhodní ve prospěch transparentnější konkurence.
Zveřejnění vlastních dat je jen polovina úspěchu. Druhou polovinou je jejich strukturování tak, aby je LLM dokázaly snadno extrahovat a citovat. Architektura obsahu je stejně důležitá jako data samotná.
Začněte přímými odpověďmi. LLM preferují obsah, který začíná odpovědí, ne popisem cesty. Místo „Provedli jsme průzkum, abychom zjistili priority v marketingu, a zde jsou výsledky“ napište „78 % marketingových lídrů nyní řadí AI viditelnost mezi hlavní priority pro rok 2025.“ Tato přímá struktura usnadňuje extrakci a zvyšuje pravděpodobnost citace.
Optimální délka odstavce pro LLM extrakci je 40–60 slov. Tato délka umožňuje LLM vytáhnout celý smysluplný blok bez ztráty kontextu. Delší odstavce jsou rozsekány a může dojít ke ztrátě významu. Kratší odstavce nemusí obsahovat dostatečné informace.
Na formátu obsahu záleží. Srovnávací seznamy tvoří 32,5 % všech AI citací – jde o nejvyšší podíl ze všech formátů. FAQ sekce jsou extrémně účinné, protože odpovídají způsobu, jakým uživatelé kladou dotazy AI. Výborně fungují také návody, případové studie a výzkumné zprávy, ale seznamy mají dlouhodobě největší úspěch.
Strukturovat obsah s jasnou hierarchií nadpisů. Používejte H2 nadpisy, které odpovídají pravděpodobným dotazům. Pod každý H2 dávejte H3 pro dílčí témata. Tato struktura pomáhá LLM pochopit obsah a extrahovat relevantní části.
Implementujte signály E-E-A-T napříč obsahem. Zařaďte biografie autorů s odborností a skutečnými zkušenostmi. Odkazujte na ověření třetími stranami. Buďte transparentní v metodice. Uvádějte zdroje. Tyto signály říkají LLM, že váš obsah je důvěryhodný a hodný citace.

Používejte sémantické HTML. Strukturovat data pomocí správných <table>, <ul> a <ol> tagů místo vizuálních divů s CSS. To usnadňuje AI zpracování a sumarizaci obsahu. Přidejte schéma (Article, FAQPage, HowTo) pro poskytnutí dodatečného kontextu.
A nakonec: obsah pravidelně aktualizujte. LLM preferují čerstvá data, zvlášť u časově citlivých údajů. Pokud je váš průzkum z roku 2024, aktualizujte jej v roce 2025. Přidávejte časová razítka „Naposledy aktualizováno“, aby bylo zřejmé, že se o obsah staráte. Signalizujete tím LLM, že vaše data jsou aktuální a důvěryhodná.
Zveřejnit vlastní data na webu je nutné, ale nestačí to. LLM objevují obsah skrze více kanálů a vaše strategie distribuce rozhoduje, kolik z nich vaše data zachytí.
Nejúčinnějším distribučním kanálem pro vlastní data je digitální PR. Pokud se váš výzkum objeví v odvětvových médiích, zpravodajství a autoritativních blozích, vzniká mnoho příležitostí k citaci. LLM indexují tato třetí strana zmínky a využívají je k validaci vašeho původního zdroje. Značka, která je zmíněna na 4+ platformách, má 2,8× vyšší šanci být citována v ChatGPT než značky s omezenou přítomností.
Efektivní distribuční kanály jsou například:
Každý kanál má svůj smysl. Tiskové zprávy tvoří první vlnu povědomí. Odborné publikace dodávají kredibilitu a oslovují rozhodovatele. LinkedIn oslovuje odborníky ve velkém. Reddit ukazuje důvěru komunity. Recenzní platformy poskytují strukturovaná data snadno zpracovatelná LLM.
Násobící efekt je výrazný. Pokud se vaše data objeví v několika autoritativních zdrojích, LLM vidí konzistentní signály napříč webem. Tato konzistence zvyšuje důvěru a citace jsou pravděpodobnější. Zmínka jen na vašem webu může být přehlédnuta. Pokud jsou data na webu, v tiskové zprávě, odborném médiu i recenzní platformě, jsou pro LLM nepřehlédnutelná.
Na načasování záleží. Distribuujte vlastní data strategicky. Nejprve je zveřejněte na webu a současně v tiskové zprávě. Následují publikace v oboru. Poté zesilte přes sociální sítě a komunity. Tento rozfázovaný přístup vytvoří vlnu viditelnosti místo jednorázového výkyvu.
Publikovat vlastní data bez měření jejich dopadu je jako spouštět reklamu bez sledování konverzí. Potřebujete vidět, zda vaše data skutečně získávají citace a zvyšují AI viditelnost.
Začněte sledováním frekvence citací. Určete 20–50 nejhodnotnějších zákaznických otázek, na které vaše data odpovídají. Každý měsíc zadávejte tyto dotazy v hlavních AI platformách (ChatGPT, Perplexity, Claude, Google AI Overviews). Zaznamenávejte, zda se vaše značka objeví, na jaké pozici a jestli je citace s odkazem na váš web.
Spočítejte frekvenci citací v procentech: (Počet dotazů, kde jste zmíněni) / (Celkový počet dotazů) × 100. Cílem je 30 %+ citací pro klíčové dotazy ve vašem segmentu. Špičkové značky v konkurenčních odvětvích dosahují 50 %+.
Sledujte AI Share of Voice (AI SOV) – spusťte stejné dotazy a spočítejte svůj podíl na všech zmínkách značek. Pokud se vaše značka objeví ve 3 z 10 odpovědí a konkurence ve 2, máte AI SOV 30 %. V konkurenčních segmentech usilujte o AI SOV vyšší než váš tradiční tržní podíl o 10–20 %.
Monitorujte sentiment analýzu. Nesledujte jen zmínky, ale i to, zda AI popisuje vaši značku pozitivně, neutrálně, či negativně. Využijte nástroje jako Profound AI, které detekují „halucinace“ – tedy nepravdivé či zastaralé informace. Cílem je 70 %+ pozitivní sentiment napříč AI platformami.
Nastavte dashboard Knowledge-Based Indicator (KBI), který sleduje:
Měřte tyto metriky měsíčně. Sledujte trendy, ne jednotlivé výkyvy. Jeden měsíc nízkých citací může být náhoda. Tři měsíce poklesu signalizují problém, který je třeba řešit.
Ruční sledování citací vlastních dat je časově náročné a náchylné k chybám. AmICited.com poskytuje infrastrukturu pro monitoring AI viditelnosti ve velkém, speciálně pro značky využívající vlastní data jako součást strategie citací.
Platforma sleduje, jak AI systémy citují váš výzkum napříč ChatGPT, Perplexity, Google AI Overviews, Claude, Gemini a dalšími vznikajícími AI platformami. Místo ručního zadávání dotazů každý měsíc AmICited proces automatizuje – vaše dotazy běží nepřetržitě a platforma v reálném čase zaznamenává vzorce citací.
Klíčové funkce:
Platforma se integruje s vaším stávajícím analytickým stackem a přenáší data o AI citacích do marketingových dashboardů vedle tradičních SEO metrik. Tento jednotný pohled vám umožní pochopit skutečný dopad strategie vlastních dat na viditelnost značky i tvorbu poptávky.
Pro značky, které to s AI viditelností myslí vážně, AmICited poskytuje měřicí infrastrukturu umožňující optimalizaci. Nelze zlepšit to, co neměříte, a tradiční analytické nástroje na LLM citace nebyly stavěné. AmICited tuto mezeru vyplňuje a dává vám přehled pro maximalizaci návratnosti investic do vlastních dat.
I dobře míněné strategie s vlastními daty často selhávají kvůli chybám, kterým lze předejít. Poznání těchto pastí vám umožní se jim vyhnout.
Nejčastější chybou je schovávání dat za formulář „Kontaktujte obchodní oddělení“. LLM nemají přístup k uzamčenému obsahu, proto budou pracovat s neúplnými nebo spekulativními informacemi z fór. Pokud jsou vaše průzkumná zjištění skrytá, LLM raději citují diskusi na Redditu než váš oficiální výzkum. Zveřejněte hlavní zjištění veřejně a metodiku transparentně. Podrobné reporty můžete chránit, ale souhrnná data a poznatky ponechte volně přístupné.
Nekonzistentní terminologie napříč platformami mate AI. Pokud váš web označuje produkt jako „marketingovou automatizační platformu“ a na LinkedIn je to „CRM software“, LLM mají problém utvořit si jasnou představu o vašem byznysu. Používejte konzistentní jazyk všude. Definujte si terminologii a uplatňujte ji na webu, LinkedInu, Crunchbase i jinde.
Chybějící údaje o autorech podkopávají důvěru. LLM pečlivě hodnotí signály E-E-A-T. Pokud průzkum postrádá biografie autorů s reálnými zkušenostmi, LLM ho znevýhodní. Uveďte podrobné biografie autorů s praxí, certifikacemi a předchozími publikacemi. Odkazujte na jejich profily na LinkedIn a dalších místech.
Zastaralé statistiky oslabují důvěryhodnost. Pokud je váš průzkum z roku 2023 a citujete ho v roce 2025, LLM si toho všimne. Průběžně výzkum aktualizujte. Přidávejte razítka „Naposledy aktualizováno“. Každý rok dělejte nové průzkumy, aby data byla čerstvá. LLM preferují aktuální údaje, zejména u časově citlivých témat.
Nejasná metodika snižuje pravděpodobnost citace. Pokud metodiku průzkumu nepopíšete transparentně, LLM zpochybní platnost zjištění. Zveřejněte metodiku otevřeně. Popište velikost vzorku, způsob výběru, období sběru dat i omezení. Transparentnost buduje důvěru.
Přehnané používání klíčových slov v obsahu s vlastními daty v AI funguje hůř než v tradičním vyhledávání. LLM detekují a penalizují umělý jazyk. Pište přirozeně. Soustřeďte se na jasnost a přesnost, ne hustotu klíčových slov. Vlastní data mají působit jako skutečný výzkum, ne reklamní text.
Povrchní obsah kolem vlastních dat je penalizován. Jeden odstavec se zmínkou o průzkumu nestačí. Vytvořte komplexní obsah, který vysvětluje důsledky, poskytuje kontext a odpovídá na doplňující otázky. Směřujte k 2 000+ slovům s hutným obsahem kolem každého důležitého vlastního datového aktiva.
Skutečné příklady ukazují sílu vlastních dat pro AI viditelnost. Tyto značky investovaly do originálního výzkumu a dosáhly měřitelných výsledků.
Úspěch The Zebra v digitálním PR: The Zebra, srovnávač pojištění, spojil vlastní výzkum s digitálním PR a získal přes 1 580 kvalitních mediálních odkazů a zvýšil organickou návštěvnost o 354 %. Publikováním originálních dat z pojišťovacího trhu a jejich šířením v médiích se The Zebra stal hlavním zdrojem pojišťovacích informací. LLM dnes citují výzkum The Zebra při odpovědích na otázky o trendech a cenách pojištění.
Tally a strategie komunitního zapojení: Tally, online nástroj na tvorbu formulářů, zvýšil AI viditelnost aktivním zapojením do komunitních fór a sdílením roadmapy produktu. Neomezil se na publikování výzkumu, ale stal se důvěryhodným hlasem v komunitách svých uživatelů. Toto autentické zapojení udělalo z ChatGPT hlavní zdroj doporučení, což přineslo výrazný nárůst registrací. Díky důkladnému ukotvení v kontextových důkazech zvýšil Tally faktickou přesnost GPT-4 z 56 % na 89 %.
HubSpot a kontinuální výzkumný program: HubSpot pravidelně publikuje výzkumy o marketingových trendech, úspěšnosti prodeje a zákaznické péči. Jejich zprávy se staly oborovým standardem, který LLM často citují. HubSpot díky kontinuálnímu výzkumu získal pověst zdroje marketingových dat a poznatků. P
Nemusíte mít obrovské datové sady. I cílený průzkum se 100–500 respondenty může poskytnout cenné vlastní poznatky, které LLM budou citovat. Klíčové je, aby byla data originální, metodika transparentní a zjištění akceschopná. Kvalita a jedinečnost jsou důležitější než kvantita.
Průzkumy spokojenosti zákazníků, výzkum trendů v odvětví, konkurenční analýzy, studie uživatelského chování a výzkum velikosti trhu mají skvělé výsledky. Nejlepší data odpovídají na konkrétní otázky vaší cílové skupiny a přinášejí poznatky, které konkurence nemá.
Platformy v reálném čase jako Perplexity mohou citovat nová data během několika týdnů. ChatGPT a další modely s méně častými aktualizacemi potřebují 2–3 měsíce. Konzistentní, kvalitní vlastní data typicky přinášejí měřitelné zvýšení citací během 3–6 měsíců.
Ne. LLM nemají přístup k uzamčenému obsahu, proto budou čerpat neúplné nebo spekulativní informace z fór. Zveřejněte klíčová zjištění veřejně s transparentní metodikou. Podrobné zprávy můžete zpřístupnit na vyžádání, ale souhrnná data a poznatky ponechte veřejně.
Používejte jasnou a konzistentní terminologii napříč všemi platformami. Uveďte transparentní metodiku ve svém výzkumu. Přidejte údaje o autorech a certifikace. Odkazujte na ověření třetími stranami. Použijte schémata pro strukturování dat. Sledujte citace měsíčně a rychle opravujte nepřesnosti.
Ano. Originální výzkumy obvykle získávají zpětné odkazy a mediální pokrytí, což zlepšuje tradiční pozice ve vyhledávání. Navíc vlastní data tvoří obsáhlejší a autoritativnější obsah, což pomáhá jak v tradičním SEO, tak v AI viditelnosti.
Vlastní data jsou originální výzkum, který provádíte sami. Obecné zprávy jsou volně dostupné. LLM preferují vlastní data, protože jsou jedinečná a lze je citovat pouze z vašeho zdroje. To vytváří výhodu v citacích, kterou konkurence těžko napodobí.
Sledujte frekvenci citací, AI Share of Voice, objem vyhledávání vaší značky a návštěvnost z AI platforem. Porovnejte tyto metriky před a po zveřejnění vlastních dat. Určete hodnotu návštěvnosti z AI (obvykle 4,4× vyšší konverzní poměr než tradiční organická návštěvnost) pro výpočet ROI.
Sledujte, jak AI systémy citují vaše vlastní data napříč ChatGPT, Perplexity, Google AI Overviews a dalšími. Získejte okamžité poznatky o své AI viditelnosti a konkurenčním postavení.
Naučte se vytvářet původní výzkum a PR obsah řízený daty, který AI systémy aktivně citují. Objevte 5 atributů obsahu hodného citace a strategie pro maximalizaci...

Naučte se ověřené strategie citování zdrojů, aby byl váš obsah důvěryhodný pro LLM. Objevte, jak získat AI citace od ChatGPT, Perplexity a Google AI Overviews p...
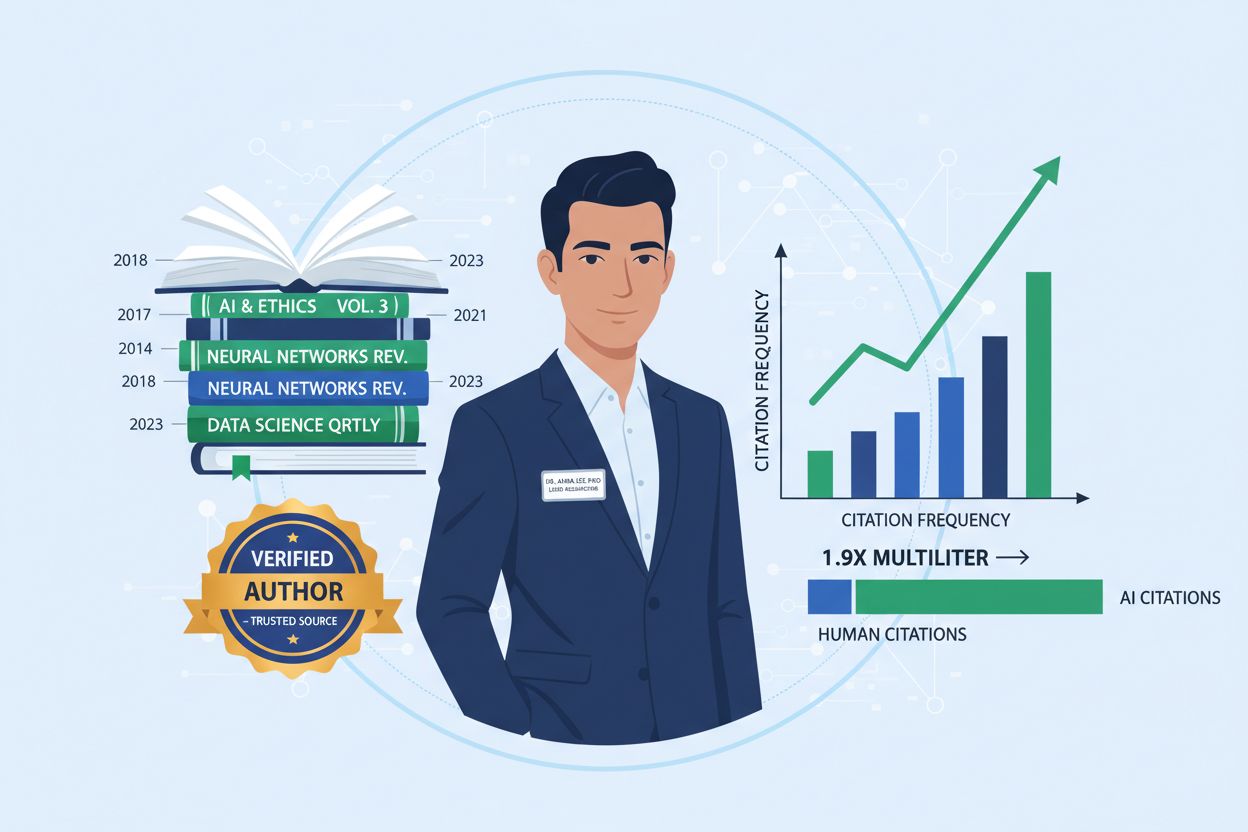
Zjistěte, jak titulky s autorem ovlivňují citace AI. Zjistěte, proč pojmenované autorství získává 1,9x více citací z ChatGPT a Perplexity a jak optimalizovat ti...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.