Optimalizace trénovacích dat vs. real-time retrieval: Strategie optimalizace
Porovnejte optimalizaci trénovacích dat a strategie real-time retrievalu pro AI. Zjistěte, kdy použít fine-tuning vs. RAG, nákladové dopady a hybridní přístupy pro optimální výkon AI.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
Optimalizace trénovacích dat a real-time retrieval představují zásadně odlišné přístupy k vybavení AI modelů znalostmi. Optimalizace trénovacích dat spočívá v zapracování znalostí přímo do parametrů modelu prostřednictvím fine-tuningu na doménově specifických datasetech, čímž vzniká statická znalost, která po dokončení tréninku zůstává neměnná. Real-time retrieval naopak ponechává znalosti externě mimo model a relevantní informace získává dynamicky během inference, což umožňuje přístup k dynamickým informacím, které se mohou mezi požadavky měnit. Klíčový rozdíl spočívá v tom, kdy jsou znalosti do modelu integrovány: optimalizace trénovacích dat probíhá před nasazením, zatímco real-time retrieval při každém inference volání. Tento základní rozdíl ovlivňuje všechny aspekty implementace, od požadavků na infrastrukturu přes charakteristiky přesnosti až po otázky souladu s předpisy. Porozumění tomuto rozdílu je zásadní pro organizace, které rozhodují, která strategie optimalizace odpovídá jejich konkrétním případům použití a omezením.
Jak funguje optimalizace trénovacích dat
Optimalizace trénovacích dat probíhá systematickým upravováním interních parametrů modelu vystavením na pečlivě vybraných doménově specifických datasetech během procesu fine-tuningu. Když se model opakovaně setkává s trénovacími příklady, postupně si vnitřně osvojuje vzorce, terminologii a doménovou odbornost prostřednictvím backpropagace a aktualizací gradientů, které mění mechanismy učení modelu. Tento proces umožňuje organizacím zakódovat specializované znalosti—například lékařskou terminologii, právní rámce či proprietární obchodní logiku—přímo do vah a biasů modelu. Výsledný model se stává vysoce specializovaným pro cílovou doménu a často dosahuje výkonu srovnatelného s mnohem většími modely; výzkum společnosti Snorkel AI ukázal, že fine-tunované menší modely mohou dosahovat výsledků srovnatelných s modely 1 400krát většími. Klíčové charakteristiky optimalizace trénovacích dat zahrnují:
Trvalá integrace znalostí: Po natrénování jsou znalosti součástí modelu a není nutné externí vyhledávání
Snížená latence inference: Žádná režie retrievalu během predikce, což umožňuje rychlejší odpovědi
Konzistentní styl a formátování: Modely se učí doménové komunikační vzory a konvence
Schopnost offline provozu: Modely fungují nezávisle bez externích datových zdrojů
Vysoké počáteční výpočetní náklady: Vyžaduje významné GPU zdroje a přípravu anotovaných trénovacích dat
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
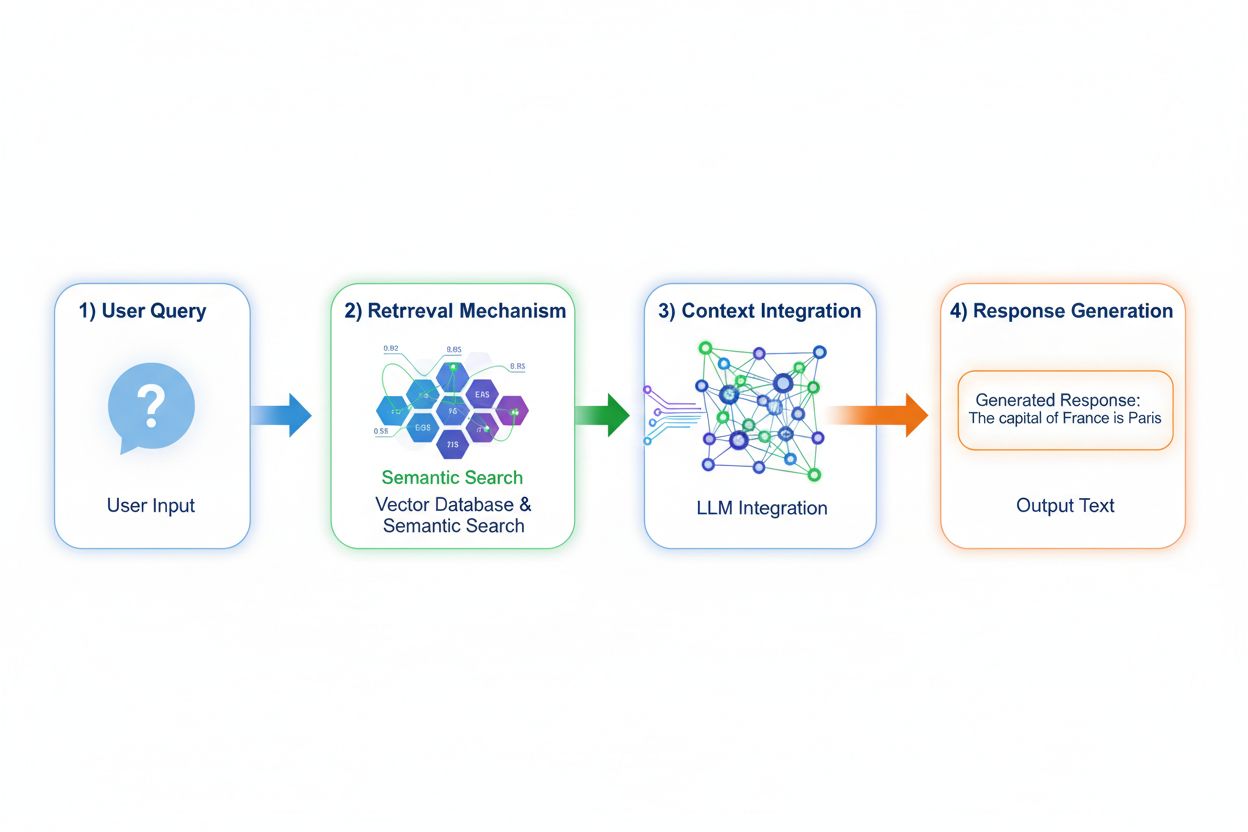
Retrieval Augmented Generation (RAG) zásadně mění způsob, jakým modely přistupují ke znalostem, implementací čtyřstupňového procesu: kódování dotazu, sémantické vyhledávání, hodnocení kontextu a generování s ukotvením. Když uživatel zadá dotaz, RAG jej nejprve převede do husté vektorové reprezentace pomocí embedding modelů, poté prohledá vektorovou databázi obsahující indexované dokumenty nebo znalostní zdroje. Fáze retrievalu využívá sémantické vyhledávání pro nalezení kontextově relevantních pasáží místo pouhého porovnávání klíčových slov, přičemž výsledky řadí podle skóre relevance. Model následně generuje odpovědi s explicitními odkazy na získané zdroje a zakládá svůj výstup na skutečných datech, nikoli pouze na naučených parametrech. Tato architektura umožňuje modelům přístup k informacím, které při trénování ještě neexistovaly, což činí RAG mimořádně užitečným pro aplikace vyžadující aktuální informace, proprietární data nebo často aktualizované znalostní báze. Mechanismus RAG v podstatě proměňuje model ze statického úložiště znalostí v dynamického syntetizátora informací, který může začleňovat nová data bez nutnosti retrénování.
Srovnání výkonu a přesnosti
Přesnost a profil halucinací se u těchto přístupů významně liší a ovlivňuje nasazení v praxi. Optimalizace trénovacích dat vytváří modely s hlubokým porozuměním doméně, ale omezenou schopností uznat hranice znalostí; pokud se fine-tunovaný model setká s dotazem mimo svůj trénovací rozsah, může sebevědomě generovat věrohodně znějící, ale nesprávné informace. RAG výrazně snižuje halucinace tím, že odpovědi zakládá na získaných dokumentech—model nemůže tvrdit informace, které v jeho zdrojovém materiálu nejsou, což přirozeně omezuje možnosti fabulace. RAG však přináší jiné riziko přesnosti: pokud retrieval fáze selže v nalezení relevantních zdrojů nebo špatně zařadí irelevantní dokumenty, model generuje odpovědi na základě chybného kontextu. Aktuálnost dat je u systémů RAG kritická; optimalizace trénovacích dat zachytí statický stav znalostí k okamžiku tréninku, zatímco RAG průběžně odráží aktuální stav zdrojových dokumentů. Atribuce zdrojů je dalším rozdílem: RAG přirozeně umožňuje citace a ověření tvrzení, zatímco fine-tunované modely nemohou ukázat konkrétní zdroje svých znalostí, což komplikuje fact-checking a ověřování souladu s předpisy.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Náklady a dopady na infrastrukturu
Ekonomické profily těchto přístupů vytvářejí odlišné nákladové struktury, které musí organizace důkladně zhodnotit. Optimalizace trénovacích dat vyžaduje vysoké výpočetní náklady na začátku: GPU clustery běžící dny či týdny pro fine-tuning modelů, služby pro anotaci dat pro tvorbu trénovacích datasetů a ML inženýry pro návrh efektivních trénovacích pipeline. Po natrénování zůstávají náklady na provoz relativně nízké, protože inference vyžaduje pouze standardní infrastrukturu bez externího retrievalu. Systémy RAG tuto strukturu obracejí: nižší počáteční náklady, protože neprobíhá fine-tuning, ale průběžné náklady na infrastrukturu—správa vektorových databází, embedding modelů, retrieval služeb a pipeline pro indexaci dokumentů. Klíčové nákladové faktory jsou:
Fine-tuning: GPU hodiny (10 000–100 000+ USD na model), anotace dat (0,50–5 USD za příklad), inženýrský čas
RAG infrastruktura: Licence vektorových databází, provoz embedding modelů, ukládání a indexace dokumentů, optimalizace latence retrievalu
Škálovatelnost: Fine-tunované modely škálují lineárně s objemem inference; RAG systémy s objemem inference i velikostí znalostní báze
Údržba: Fine-tuning vyžaduje periodické retrénování; RAG vyžaduje průběžné aktualizace dokumentů a údržbu indexů
Bezpečnostní a compliance aspekty
Bezpečnostní a compliance dopady se u těchto přístupů zásadně liší a ovlivňují zejména organizace v regulovaných odvětvích. Fine-tunované modely představují výzvy v ochraně dat, protože trénovací data jsou zakódována do vah modelu; získání či auditování toho, co model obsahuje, vyžaduje sofistikované techniky a vznikají obavy o soukromí, pokud chování modelu ovlivňují citlivá trénovací data. Soulad s předpisy jako GDPR je složitý, protože model si „pamatuje“ trénovací data způsoby, které odolávají smazání či úpravě. Systémy RAG nabízejí jiný bezpečnostní profil: znalosti zůstávají v externích, auditovatelných zdrojích místo v parametrech modelu, což umožňuje jednoduché bezpečnostní kontroly a omezení přístupů. Organizace mohou nastavit detailní oprávnění retrievalu, auditovat, které dokumenty model použil pro odpověď, a rychle odstranit citlivé informace aktualizací zdrojových dokumentů bez nutnosti model retrénovat. RAG však přináší i bezpečnostní rizika—ochrana vektorových databází, bezpečnost embedding modelů a zajištění, že získané dokumenty neuniknou citlivé informace. Organizace podléhající HIPAA či GDPR často upřednostňují transparentnost a auditovatelnost RAG, zatímco organizace požadující přenositelnost modelu a offline provoz preferují fine-tuning díky jeho uzavřenosti.
Praktický rozhodovací rámec
Výběr mezi těmito přístupy vyžaduje zhodnocení konkrétních omezení organizace a charakteristik případů použití. Organizace by měly upřednostnit fine-tuning, pokud jsou znalosti stabilní a málo měnitelné, pokud je kritická latence inference, pokud modely musí fungovat offline či v izolovaném prostředí, nebo pokud je zásadní konzistentní styl a doménové formátování. Real-time retrieval je vhodnější, pokud se znalosti často mění, pokud jsou důležité atribuce zdrojů a auditovatelnost kvůli souladu s předpisy, pokud je znalostní báze příliš rozsáhlá na efektivní zakódování do parametrů modelu nebo pokud je třeba aktualizovat informace bez retrénování modelu. Konkrétní případy použití ukazují tyto rozdíly:
Fine-tuning: Chatboti zákaznické podpory pro stabilní produktové informace, specializovaní lékařští asistenti, analýza právních dokumentů s ustálenou judikaturou
RAG: Systémy sumarizace novinek vyžadující aktuální události, zákaznická podpora s často aktualizovanými katalogy, asistenti výzkumu přistupující k dynamické vědecké literatuře
Rozhodovací rámec: Vyhodnoťte stabilitu znalostí, požadavky na compliance, limity latence, frekvenci aktualizací a možnosti infrastruktury
Hybridní přístupy a kombinované strategie
Hybridní přístupy kombinují fine-tuning a RAG, aby využily výhody obou strategií a zmírnily jejich individuální omezení. Organizace mohou modely fine-tunovat na základy domény a komunikační vzory, zatímco RAG použijí pro přístup k aktuálním, detailním informacím—model se naučí jak o doméně uvažovat a současně získává jaké konkrétní fakta zařadit. Tato kombinovaná strategie se výborně hodí pro aplikace vyžadující jak specializovanou odbornost, tak aktuální informace: například finanční poradenský bot fine-tunovaný na investiční principy a terminologii může pomocí RAG získávat aktuální tržní data a finanční výsledky společností. Reálné hybridní implementace zahrnují zdravotnické systémy, které fine-tunují na lékařské znalosti a protokoly a současně získávají pacientově specifická data přes RAG, nebo právní platformy trénované na právní argumentaci s retrievalem aktuální judikatury. Synergické výhody zahrnují snížení halucinací (zakotvení v získaných zdrojích), lepší porozumění doméně (z fine-tuningu), rychlejší inference u běžných dotazů (cacheované znalosti modelu) a flexibilitu aktualizací specializovaných informací bez retrénování. Organizace tento optimalizační přístup stále častěji zavádějí s rostoucí dostupností výpočetních zdrojů a s tím, jak složitost reálných aplikací vyžaduje jak hloubku, tak aktuálnost znalostí.
Monitoring AI odpovědí a sledování citací
Schopnost monitorovat AI odpovědi v reálném čase je stále kritičtější, jak organizace nasazují tyto optimalizační strategie ve větším měřítku, zejména pro zjištění, který přístup přináší lepší výsledky v konkrétních případech použití. AI monitoring systémy sledují výstupy modelů, kvalitu retrievalu a metriky spokojenosti uživatelů, což organizacím umožňuje měřit, zda jejich aplikacím lépe slouží fine-tunované modely, nebo RAG systémy. Sledování citací odhaluje zásadní rozdíly mezi přístupy: RAG systémy přirozeně generují citace a odkazy na zdroje, čímž vytvářejí auditní stopu dokumentů, které ovlivnily každou odpověď, zatímco fine-tunované modely neposkytují žádný inherentní mechanismus pro monitoring odpovědí nebo atribuci. Tento rozdíl je zásadní pro bezpečnost značky a konkurenční zpravodajství—organizace potřebují vědět, jak AI systémy citují jejich konkurenty, zmiňují jejich produkty nebo připisují informace konkrétním zdrojům. Nástroje jako AmICited.com tento nedostatek řeší monitorováním, jak AI systémy citují značky a firmy napříč různými optimalizačními strategiemi, a poskytují sledování citací v reálném čase včetně identifikace vzorců a frekvence. Díky komplexnímu monitoringu mohou organizace měřit, zda jejich zvolená optimalizační strategie (fine-tuning, RAG či hybrid) skutečně zlepšuje přesnost citací, snižuje halucinace o konkurenci a udržuje správnou atribuci k autoritativním zdrojům. Tento datově řízený přístup k monitoringu umožňuje průběžné vylepšování strategií optimalizace na základě skutečného výkonu, nikoli pouze teoretických očekávání.
Budoucí trendy a nastupující vzorce
Odvětví směřuje k sofistikovanějším hybridním a adaptivním přístupům, které dynamicky volí optimalizační strategii podle charakteru dotazu a požadavků na znalosti. Nastupující best practices zahrnují retrieval-augmented fine-tuning, kdy jsou modely fine-tunovány na efektivní využívání získaných informací, místo pouhého memorování faktů, a adaptivní směrovací systémy, které dotazy posílají k fine-tunovaným modelům pro stabilní znalosti a k RAG systémům pro dynamické informace. Trendy ukazují rostoucí adopci specializovaných embedding modelů a vektorových databází optimalizovaných pro konkrétní domény, což umožňuje přesnější sémantické vyhledávání a omezuje šum při retrievalu. Organizace vytvářejí vzorce pro kontinuální vylepšování modelů, které kombinují periodické aktualizace fine-tuningu s real-time RAG augmentací, čímž vznikají systémy, které se postupně zlepšují a zároveň si zachovávají přístup k aktuálním informacím. Evoluce optimalizačních strategií odráží širší uznání v oboru, že žádný přístup není optimální pro všechny případy; budoucí systémy pravděpodobně implementují inteligentní mechanismy výběru mezi fine-tuningem, RAG a hybridními přístupy dynamicky podle kontextu dotazu, stability znalostí, požadavků na latenci a compliance. S dozráváním těchto technologií se konkurenční výhoda přesune od volby jednoho přístupu k odborné implementaci adaptivních systémů, které využívají silné stránky každé strategie.
Často kladené otázky
Jaký je hlavní rozdíl mezi optimalizací trénovacích dat a real-time retrievalem?
Optimalizace trénovacích dat zapracovává znalosti přímo do parametrů modelu prostřednictvím fine-tuningu, čímž vzniká statická znalost, která po trénování zůstává neměnná. Real-time retrieval naopak ponechává znalosti externě a získává relevantní informace dynamicky při inferenci, což umožňuje přístup k aktuálním informacím, které se mohou mezi požadavky měnit. Klíčový rozdíl spočívá v okamžiku integrace znalostí: optimalizace trénovacích dat probíhá před nasazením, zatímco real-time retrieval během každého inference volání.
Kdy mám použít fine-tuning místo RAG?
Fine-tuning použijte, pokud jsou znalosti stabilní a pravděpodobně se často nemění, pokud je rozhodující latence inference, pokud musí modely fungovat offline, nebo pokud je zásadní konzistentní styl a formátování specifické pro doménu. Fine-tuning je ideální pro specializované úlohy, jako je lékařská diagnostika, analýza právních dokumentů nebo zákaznický servis se stabilními produktovými informacemi. Fine-tuning však vyžaduje značné počáteční výpočetní zdroje a stává se nepraktickým, pokud se informace často mění.
Mohu kombinovat optimalizaci trénovacích dat s real-time retrievalem?
Ano, hybridní přístupy kombinují fine-tuning a RAG, aby využily výhody obou strategií. Organizace mohou modely fine-tunovat na základy domény a současně využívat RAG pro přístup k aktuálním a detailním informacím. Tento přístup je zvláště efektivní pro aplikace vyžadující jak specializované znalosti, tak aktuální informace, například finanční poradenské boty nebo zdravotnické systémy, které potřebují jak lékařské znalosti, tak data o konkrétním pacientovi.
Jak RAG snižuje halucinace ve srovnání s fine-tuningem?
RAG výrazně snižuje halucinace tím, že odpovědi zakládá na získaných dokumentech—model nemůže tvrdit informace, které se v jeho zdrojovém materiálu nenacházejí, což přirozeně omezuje možnost fabulací. Fine-tunované modely naopak mohou sebevědomě generovat věrohodně znějící, ale nesprávné informace při dotazech mimo svůj trénovací rozsah. Díky citacím umožňuje RAG také ověření tvrzení, zatímco fine-tunované modely nemohou ukázat konkrétní zdroje svých znalostí.
Jaké jsou nákladové dopady jednotlivých přístupů?
Fine-tuning vyžaduje vysoké počáteční náklady: GPU hodiny (10 000–100 000+ USD na model), anotaci dat (0,50–5 USD za příklad) a inženýrský čas. Po natrénování zůstávají provozní náklady relativně nízké. Systémy RAG mají nižší počáteční náklady, ale průběžné náklady na infrastrukturu – vektorové databáze, embedding modely a retrieval služby. Fine-tunované modely škálují lineárně s objemem inference, zatímco systémy RAG škálují s objemem inference i velikostí znalostní báze.
Jak real-time retrieval pomáhá se sledováním citací AI?
Systémy RAG přirozeně generují citace a odkazy na zdroje, čímž vytvářejí auditní stopu dokumentů, které ovlivnily každou odpověď. To je zásadní pro bezpečnost značky a konkurenční zpravodajství—organizace mohou sledovat, jak AI systémy citují jejich konkurenty a zmiňují jejich produkty. Nástroje jako AmICited.com monitorují, jak AI systémy citují značky v různých optimalizačních strategiích, a poskytují sledování citací v reálném čase, včetně vzorců a frekvence.
Který přístup je lepší pro vysoce regulované obory?
RAG je obecně vhodnější pro vysoce regulované obory, jako je zdravotnictví a finance. Znalosti zůstávají v externích, auditovatelných datových zdrojích namísto v parametrech modelu, což umožňuje jednoduchou správu bezpečnostních oprávnění a přístupových omezení. Organizace mohou zavést detailní oprávnění, auditovat, ke kterým dokumentům měl model přístup, a rychle odstranit citlivé informace bez nutnosti model znovu trénovat. Organizace podléhající HIPAA nebo GDPR často upřednostňují transparentnost a auditovatelnost RAG.
Jak mám sledovat efektivitu zvolené optimalizační strategie?
Implementujte AI monitorovací systémy, které sledují výstupy modelu, kvalitu retrievalu a metriky spokojenosti uživatelů. U systémů RAG sledujte přesnost retrievalu a kvalitu citací. U fine-tunovaných modelů sledujte přesnost na úlohách domény a míru halucinací. Využijte nástroje jako AmICited.com pro sledování, jak vaše AI systémy citují informace, a porovnávejte výkon napříč různými optimalizačními strategiemi podle skutečných výsledků.
Sledujte, jak AI systémy citují vaši značku
Sledujte citace v reálném čase napříč GPTs, Perplexity a Google AI Overviews. Zjistěte, jaké optimalizační strategie používají vaši konkurenti a jak jsou zmiňováni v AI odpovědích.
Trénovací data vs. živé vyhledávání: Jak AI systémy přistupují k informacím
Pochopte rozdíl mezi trénovacími daty AI a živým vyhledáváním. Zjistěte, jak uzávěrky znalostí, RAG a vyhledávání v reálném čase ovlivňují viditelnost v AI a va...
Jak optimalizovat svůj obsah pro trénovací data AI a AI vyhledávače
Zjistěte, jak optimalizovat svůj obsah pro zařazení do trénovacích dat AI. Objevte osvědčené postupy, jak učinit svůj web dohledatelný pro ChatGPT, Gemini, Perp...
Tréninková data vs. živé vyhledávání v AI – na co bych se měl/a vlastně zaměřit při optimalizaci?
Diskuze komunity o rozdílu mezi tréninkovými daty AI a živým vyhledáváním (RAG). Praktické strategie pro optimalizaci obsahu jak pro statická tréninková data, t...
7 min čtení
Discussion
Training Data
+1
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.