Spoluvýskyt
Spoluvýskyt nastává, když se související termíny objevují společně v obsahu a signalizují sémantickou relevanci vyhledávačům a AI systémům. Zjistěte, jak tento ...
11 min čtení

Zjistěte, jak vzorce ko-výskytu pomáhají AI vyhledávačům chápat sémantické vztahy mezi pojmy, zlepšovat hodnocení obsahu a posilovat AI-generované odpovědi.
Ko-výskyt označuje, jak často se dvě nebo více slov či entit vyskytuje společně ve stejném kontextu v textu. AI vyhledávače využívají vzorce ko-výskytu k pochopení sémantických vztahů, lepšímu porozumění dotazu a určování relevance obsahu pro AI-generované odpovědi.
Ko-výskyt je základní pojem v zpracování přirozeného jazyka, který popisuje, jak často se dvě nebo více slov, frází či entit vyskytuje společně v daném kontextu, jako je věta, odstavec nebo dokument. V kontextu AI vyhledávačů jako ChatGPT, Perplexity a dalších generátorů AI odpovědí hrají vzorce ko-výskytu zásadní roli v tom, jak tyto systémy rozumí obsahu, extrahují význam a generují relevantní odpovědi. Když AI modely analyzují text, nezaměřují se pouze na jednotlivá slova izolovaně—zkoumají, která slova se vyskytují společně, protože tato blízkost odhaluje sémantické vztahy a kontextový význam, což AI pomáhá porozumět skutečnému tématu obsahu.
Význam ko-výskytu v AI vyhledávání nelze přeceňovat. Moderní jazykové modely AI jsou trénovány na obrovských datových souborech, kde se učí statistické vzorce o tom, která slova se přirozeně shlukují. Tyto vzorce jsou zabudovány do porozumění jazyka modelem, což mu umožňuje rozpoznat, že určité pojmy spolu souvisejí, i když se neobjevují ve stejné větě. Například AI vyhledávač se naučí, že „elektrická vozidla“, „dojezd baterie“ a „nabíjecí stanice“ se často vyskytují v automobilovém obsahu, což mu pomáhá pochopit, že tyto pojmy patří do stejné tematické oblasti. Toto porozumění přímo ovlivňuje, jak AI systémy řadí, vyhledávají a citují obsah při generování odpovědí na uživatelské dotazy.
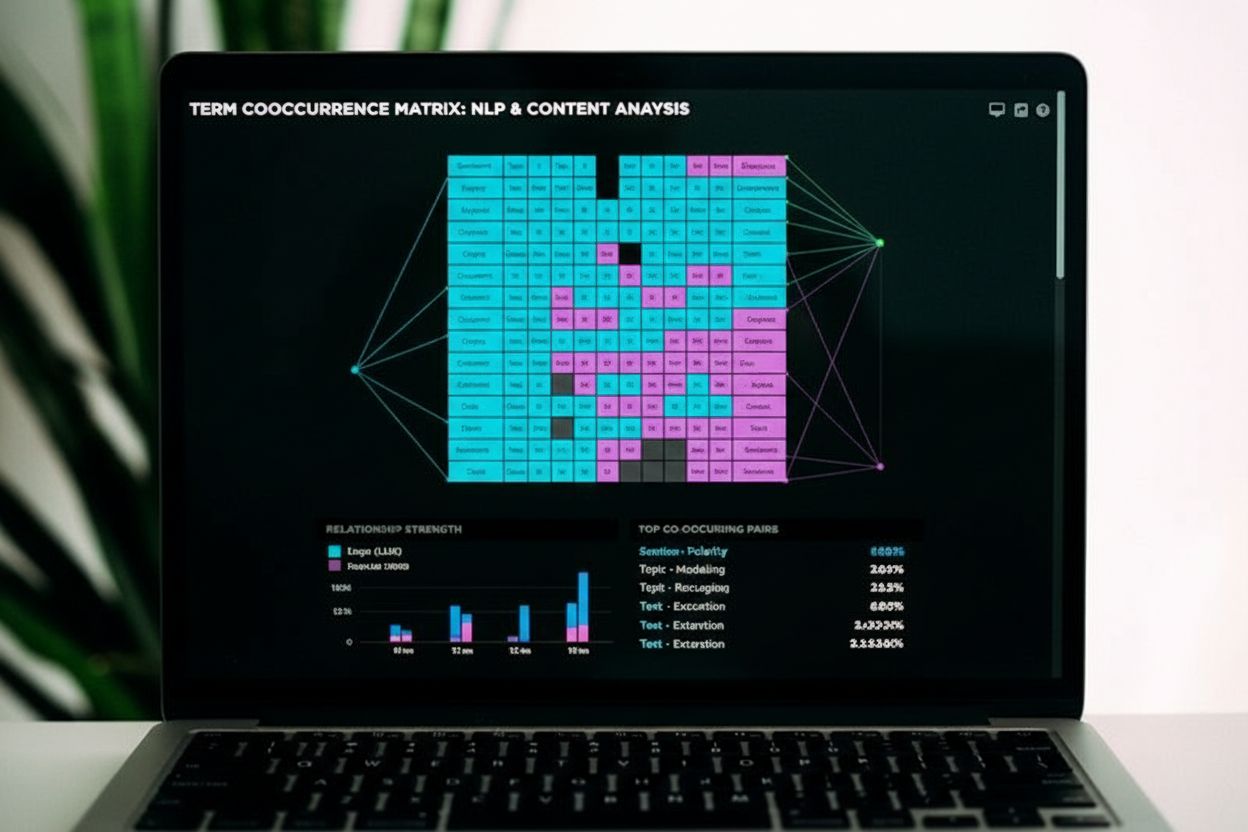
AI vyhledávače používají analýzu ko-výskytu k vytvoření statistické mapy fungování jazyka v miliardách dokumentů a konverzací. Když se model AI setká s uživatelským dotazem, neporovnává pouze klíčová slova—analyzuje sémantický prostor kolem těchto slov tím, že zkoumá, která další slova se objevují společně s nimi v kvalitním, autoritativním obsahu. Tento proces pomáhá AI přesněji pochopit uživatelský záměr a získat obsah, který skutečně odpovídá tomu, na co se uživatel ptá, místo pouhého vyhledání přesných klíčových slov. Matice ko-výskytu, což je matematické znázornění toho, jak často se slova v párech vyskytují společně, slouží jako základní nástroj, který AI systémy používají k vytváření slovních embeddingů a sémantických vektorů.
Distribuční hypotéza je základem fungování ko-výskytu v AI: „Poznáte slovo podle společnosti, ve které se vyskytuje.“ Tento princip znamená, že slova, která se objevují v podobných kontextech se stejnými partnery ko-výskytu, mají pravděpodobně příbuzný význam. Jazykové modely AI tento princip hojně využívají. Při tréninku na textových datech tyto modely budují statistiky ko-výskytu, které jim pomáhají chápat sémantickou podobnost. Například pokud se „lékař“, „doktor“ a „zdravotnický pracovník“ vyskytují s podobnou sadou slov jako „pacient“, „diagnóza“ a „léčba“, AI se naučí, že tyto pojmy jsou sémanticky ekvivalentní. Toto pochopení umožňuje AI vyhledávačům rozpoznávat synonyma a související pojmy, což je činí efektivnějšími při rozpoznávání různých způsobů, jakými uživatelé mohou položit tutéž otázku.
Ko-výskyt se měří pomocí několika statistických metod, které jdou nad rámec prostého počítání četnosti. Nejjednodušší přístup je surové počítání četnosti—prostě zaznamenávat, kolikrát se dvě slova vyskytují společně v definovaném kontextovém okně. Surové počty však mohou být zavádějící, protože velmi běžná slova se přirozeně vyskytují společně často pouze kvůli své četnosti v jazyce, nikoli kvůli smysluplnému vztahu. Aby bylo toto omezení překonáno, AI systémy používají sofistikovanější metriky jako Pointwise Mutual Information (PMI), která měří, o kolik častěji se dvě slova vyskytují společně oproti tomu, co by bylo očekáváno náhodou.
| Měřící metoda | Popis | Použití |
|---|---|---|
| Surová četnost | Jednoduchý počet ko-výskytů | Základní analýza, rychlé hodnocení |
| Pointwise Mutual Information (PMI) | Porovnává pozorovaný vs. očekávaný ko-výskyt | Identifikace smysluplných sémantických vztahů |
| Log-Likelihood Ratio (LLR) | Test statistické významnosti asociací | Filtrování šumu z velkých datových sad |
| Chi-kvadrát test | Testuje nezávislost mezi dvojicemi slov | Zjištění statistické významnosti |
| Dice koeficient | Měří podobnost rozložení slov | Skórování sémantické podobnosti |
PMI je obzvláště cenné v AI vyhledávání, protože filtruje náhodné asociace. Vysoké skóre PMI znamená, že dvě slova se vyskytují společně mnohem častěji, než by předpokládala náhoda, což naznačuje skutečný sémantický vztah. Naopak pokud se dvě běžná slova vyskytují společně často, ale ne více, než by bylo statisticky očekáváno, PMI přiřadí nízkou nebo zápornou hodnotu. Toto rozlišení je pro AI systémy zásadní, protože jim pomáhá odlišit smysluplné sémantické vztahy od náhodných ko-výskytů. Moderní jazykové modely AI tyto asociační míry využívají k vážení důležitosti různých vzorců ko-výskytu, což jim umožňuje zaměřit se při chápání a generování obsahu na sémanticky nejvýznamnější vztahy.
Když AI vyhledávače generují odpovědi na uživatelské dotazy, vzorce ko-výskytu přímo ovlivňují, jaký obsah je vyhledán a citován. AI systém analyzuje váš dotaz a hledá dokumenty, kde se dotazovaná slova a sémanticky příbuzné pojmy vyskytují smysluplným způsobem společně. Pokud váš obsah obsahuje hlavní klíčová slova, která uživatel hledal, ale tato slova se nevyskytují společně s příbuznými pojmy, které se obvykle objevují v autoritativním obsahu na dané téma, může AI váš obsah zařadit níže nebo ho zcela přeskočit. Naopak pokud váš obsah vykazuje bohaté vzorce ko-výskytu—hlavní téma se objevuje spolu s relevantními podtématy, příbuznými entitami a podpůrnými pojmy—AI to rozpozná jako známku komplexního, autoritativního pokrytí.
To má zásadní důsledky pro to, jak se obsah objevuje v AI-generovaných odpovědích. Uživatel se například zeptá: „Jaké jsou výhody obnovitelných zdrojů energie?“ AI vyhledávač bude hledat obsah, kde se „obnovitelné zdroje energie“ vyskytují společně s pojmy jako „solární energie“, „větrná energie“, „snížení emisí uhlíku“, „udržitelnost“ a „úspora nákladů“. Obsah, který zmiňuje obnovitelné zdroje energie, ale chybí mu tyto související ko-výskyty, může být přehlédnut, i když je technicky relevantní. AI chápe bohaté vzorce ko-výskytu jako důkaz, že obsah komplexně pokrývá téma z více úhlů. Proto je sémantická relevance—soulad mezi vaším obsahem a úplným sémantickým kontextem tématu—v AI vyhledávání důležitější než pouhé párování klíčových slov.
Ko-výskyt entit rozšiřuje pojem ko-výskytu za hranice jednotlivých slov na pojmenované entity, jako jsou osoby, organizace, místa a produkty. Když se dvě entity v textu často vyskytují společně, AI systémy usuzují, že pravděpodobně existuje vztah i ve skutečném světě. Například pokud se „Apple Inc.“ a „Tim Cook“ trvale vyskytují v podnikatelských a technologických článcích, AI se naučí je spojovat a chápe, že Tim Cook je spojen s firmou Apple. Tato analýza ko-výskytu na úrovni entit pomáhá AI systémům budovat a udržovat znalostní grafy—strukturované reprezentace toho, jak spolu různé pojmy a entity souvisejí.
Pro značky a organizace je pochopení ko-výskytu entit klíčové pro viditelnost v AI vyhledávání. Pokud se vaše značka často vyskytuje společně s konkrétními produkty, službami či oborovými pojmy, AI systémy se naučí vaši značku s těmito pojmy spojovat. To ovlivňuje, jak je váš obsah vyhledáván a citován, když uživatelé kladou otázky z těchto oblastí. Pokud se vaše značka s relevantními pojmy nebo jmény konkurence vyskytuje jen zřídka, AI systémy nemusí váš obsah rozpoznat jako relevantní pro dotazy ve vašem oboru. Proto je monitorování vzorců ko-výskytu vaší značky napříč AI vyhledávači zásadní—odhaluje, jak AI systémy kategorizují a chápou vaše podnikání a zda je váš obsah správně umístěn v sémantickém prostředí vašeho oboru.
Abyste zvýšili svou viditelnost v AI-generovaných odpovědích, musíte porozumět vzorcům ko-výskytu a optimalizovat pro ně. Prvním krokem je identifikace pojmů, které by měly ko-výskytovat s vašimi hlavními klíčovými slovy. Prozkoumejte, jaké koncepty, příbuzné pojmy a podpůrné myšlenky se objevují v nejlépe hodnoceném obsahu pro vaše cílové dotazy. Pokud píšete o „udržitelném balení“, měli byste zjistit, která související slova—jako „biologicky rozložitelné materiály“, „dopad na životní prostředí“, „nákladová efektivita“ a „dodavatelský řetězec“—se v autoritativním obsahu na toto téma pravidelně vyskytují. Váš obsah by měl tato související slova přirozeně obsahovat, čímž vytvoří bohaté vzorce ko-výskytu, které signalizují AI systémům, že jste téma komplexně pokryli.
Je však důležité mít na paměti, že optimalizace pro ko-výskyt musí působit přirozeně a autenticky. AI systémy jsou dostatečně sofistikované na to, aby rozpoznaly umělé vkládání klíčových slov či nucené použití pojmů. Cílem je psát obsah, který skutečně pokrývá téma z různých úhlů, což přirozeně vede k bohatým vzorcům ko-výskytu. To znamená strukturovat obsah tak, aby zahrnoval související podtémata, relevantní příklady, odpovídal na běžné otázky a zkoumal různé dimenze hlavního tématu. Pokud to uděláte autenticky, vzorce ko-výskytu vzniknou přirozeně a AI systémy váš obsah rozpoznají jako autoritativní a komplexní. Navíc použití jasných nadpisů a podnadpisů pomáhá organizovat obsah způsobem, který činí vzorce ko-výskytu pro AI systémy lépe viditelnými, protože tyto struktury pomáhají AI pochopit, které pojmy spolu souvisejí a jak zapadají do celkového tématu.
Ačkoli je ko-výskyt mocným nástrojem pro porozumění AI, má důležitá omezení, která by si tvůrci obsahu měli uvědomovat. Samotný ko-výskyt nezaručuje sémantický vztah—dvě slova se mohou vyskytovat společně často kvůli náhodě, sdílenému kontextu nebo širokému překryvu tématu, nikoli kvůli skutečnému sémantickému propojení. Například pokud se „pondělí“ a „prezident“ často vyskytují ve zpravodajských článcích prostě proto, že tiskové konference bývají v pondělí, neznamená to smysluplný vztah mezi těmito pojmy. Moderní AI systémy to řeší tím, že kombinují analýzu ko-výskytu s dalšími signály, jako je jazykový kontext, sémantické rolové označování a informace ze znalostních bází, aby určily, zda je vztah skutečný.
Další významnou výzvou je velikost kontextového okna. Definice „společného výskytu“ je velmi důležitá. Má se ko-výskyt měřit na úrovni věty, odstavce nebo celého dokumentu? Menší okno zachytí konkrétnější, přímé vztahy, ale může přehlédnout širší sémantické souvislosti. Větší okno zachytí více vztahů, ale přináší šum a falešné asociace. Různé AI systémy volí různě velká okna, což ovlivňuje, jak interpretují vzorce ko-výskytu ve vašem obsahu. Navíc mnohoznačnost—tj. když jedno slovo má více významů—může v analýze ko-výskytu způsobit zmatek. Slovo „Merkur“ může ko-výskytovat se „planetou“, „chemickým prvkem“ nebo „římskou mytologií“ podle kontextu, a bez správného rozlišení entit může AI tyto významy zaměňovat. Porozumění těmto omezením vám pomůže pochopit, že ačkoli je ko-výskyt důležitý, je jen jedním z mnoha signálů, které AI systémy používají k pochopení a řazení obsahu.
Pro organizace využívající AI monitorovací platformy jako AmICited poskytuje sledování vzorců ko-výskytu cenné poznatky o tom, jak AI systémy chápou a kategorizují váš obsah. Sledováním, která slova ko-výskytují s názvem vaší značky, produkty nebo klíčovými tématy napříč různými AI vyhledávači, můžete identifikovat mezery ve své obsahové strategii a příležitosti ke zlepšení viditelnosti ve vyhledávání AI. Pokud zjistíte, že vaše značka ko-výskytuje jen zřídka s důležitými pojmy oboru nebo jmény konkurence, znamená to, že AI systémy nemusí váš obsah rozpoznávat jako relevantní pro dotazy ve vašem oboru. Naopak pokud vidíte silné vzorce ko-výskytu mezi vaší značkou a relevantními koncepty, znamená to, že AI systémy váš obsah správně umisťují do sémantického prostředí vašeho odvětví.
Tato schopnost monitoringu je zvláště cenná, protože vzorce ko-výskytu se mezi různými AI systémy liší. ChatGPT, Perplexity, Google AI Overviews a další generátory AI odpovědí mohly být trénovány na různých datech a využívají různé algoritmy, což vede k odlišným vzorcům ko-výskytu a různému chování při vyhledávání obsahu. Sledováním, jak se váš obsah zobrazuje napříč různými AI vyhledávači, získáte komplexní pohled na to, jak různé AI systémy interpretují váš obsah a které vzorce ko-výskytu nejvíce ovlivňují vaši viditelnost. Tyto informace vám umožní upřesnit vaši obsahovou strategii tak, abyste optimalizovali pro konkrétní vzorce ko-výskytu, které jsou nejdůležitější pro vaši cílovou skupinu a obchodní cíle, a zajistili tak, že váš obsah bude v AI vyhledávání objevitelný a citovatelný.
Sledujte, jak se váš obsah zobrazuje v AI-generovaných odpovědích napříč ChatGPT, Perplexity a dalšími AI vyhledávači. Pochopte vzorce ko-výskytu, které ovlivňují vaši viditelnost.
Spoluvýskyt nastává, když se související termíny objevují společně v obsahu a signalizují sémantickou relevanci vyhledávačům a AI systémům. Zjistěte, jak tento ...

Poznejte ověřené strategie, jak udržet a zlepšit viditelnost svého obsahu v AI-generovaných odpovědích napříč ChatGPT, Perplexity a Google AI Overviews. Zjistět...
Zjistěte, jak strategická obsahová partnerství zvyšují viditelnost vaší značky v AI. Objevte strategie spolupráce mezi PR a SEO týmy pro budování autority značk...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.