Paginace
Paginace rozděluje velké sady obsahu na zvládnutelné stránky pro lepší UX a SEO. Zjistěte, jak paginace funguje, jaký má dopad na pozice ve vyhledávačích a jaké...
9 min čtení

Zjistěte, jak stránkování ovlivňuje viditelnost v AI. Objevte, proč tradiční dělení stránek pomáhá AI systémům najít váš obsah, zatímco nekonečné scrollování ho skrývá, a jak stránkování optimalizovat pro AI generátory odpovědí.
Stránkování je praxe rozdělování velkých souborů obsahu na více propojených stránek. Ano, významně ovlivňuje AI systémy—stránkování vytváří samostatné, prohledávatelné URL adresy, které pomáhají AI vyhledávačům jako ChatGPT, Perplexity a Google SGE efektivněji objevovat a indexovat váš obsah, zatímco implementace nekonečného scrollování často skrývají obsah před AI crawlery.
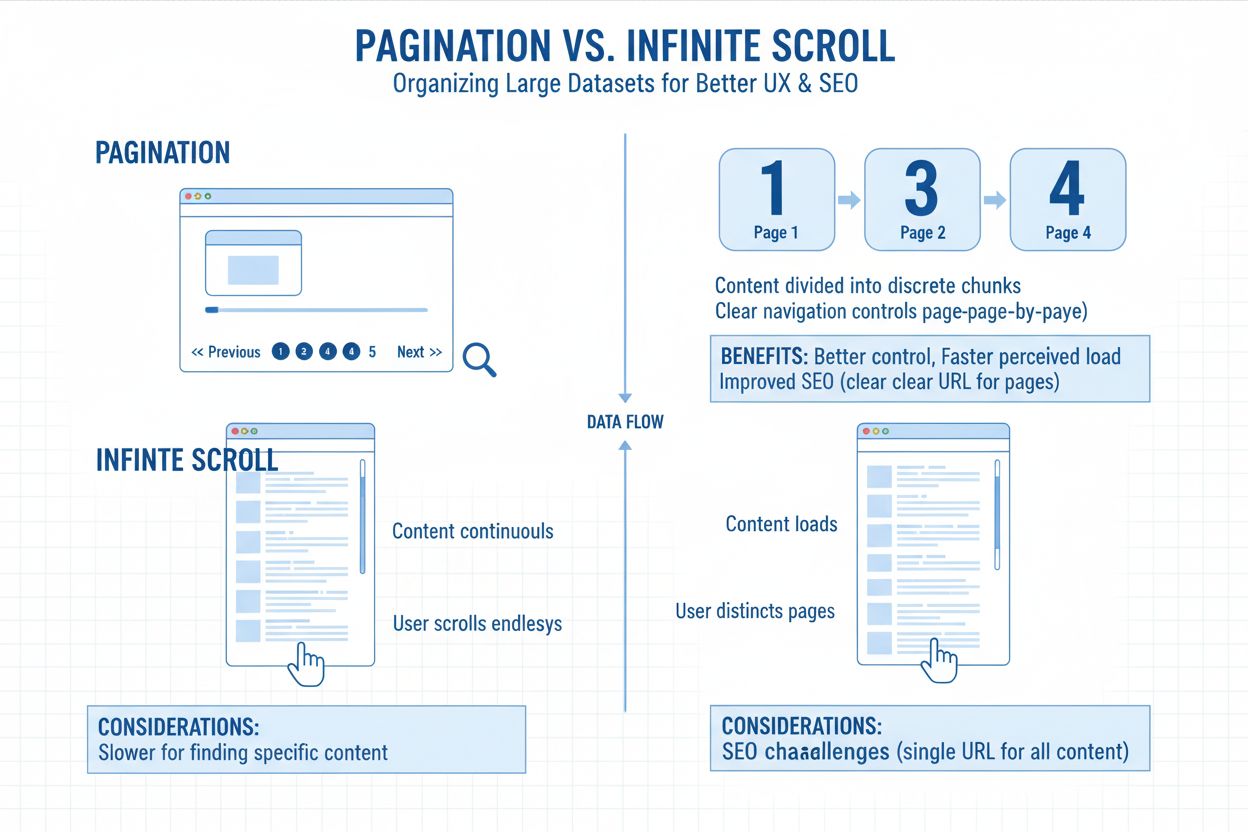
Stránkování označuje praxi rozdělování velkých souborů obsahu na více propojených stránek, místo aby se vše zobrazovalo na jedné nekonečné obrazovce. Představte si to jako kapitoly v knize—každá stránka obsahuje zvládnutelnou část celkového obsahu, propojenou číslovanými odkazy nebo tlačítky „další/předchozí“. Tento strukturální přístup najdete všude od produktových výpisů v e-shopech až po archivy blogů, vlákna diskuzí a výsledky vyhledávání. Struktura URL obvykle toto dělení odráží pomocí parametrů jako ?page=2 nebo čistých cest jako /kategorie/stranka/2/, což umožňuje uživatelům i vyhledávačům pochopit jejich pozici v rámci série obsahu. Stránkování slouží jako základní organizační nástroj, který vyvažuje uživatelský zážitek s technickými požadavky na přístupnost obsahu.
Webové stránky implementují stránkování především kvůli optimalizaci výkonu a organizaci obsahu. Načítání stovek nebo tisíců položek najednou by zatěžovalo serverové zdroje a způsobovalo pomalé načítání stránek, což je zvlášť škodlivé pro výkonnostní metriky ovlivňující pozice ve vyhledávání. Uživatelé ocení možnost uložit si konkrétní stránku do záložek, přeskočit přímo na stránku 10 nebo zjistit, kolik obsahu ještě zbývá. Z technického pohledu dělení obsahu vytváří samostatné URL, které vyhledávače mohou jednotlivě indexovat, čímž zachovává rozdělení hodnoty odkazů v rámci architektury webu. Tato strukturální jasnost je stále důležitější, jak se AI systémy vyvíjejí v chápání vztahů mezi obsahem a vzorců přístupnosti.
Vztah mezi stránkováním a viditelností v AI představuje jeden z nejdůležitějších technických aspektů SEO v moderním vyhledávacím prostředí. Tradiční vyhledávače jako Google stránkování dlouhodobě chápou díky procházení odkazů a sledování sekvenčních vzorců stránky. AI-poháněné vyhledávače a generátory odpovědí však fungují zásadně odlišně, což vyžaduje nuance v organizaci obsahu. Velké jazykové modely jako ty, které pohánějí ChatGPT, Perplexity nebo Google Search Generative Experience (SGE), nemusí stránky procházet lineárně nebo následovat tradiční navigační hierarchie. Namísto toho pracují s tokenizací a sumarizací textů—často získaných z veřejných dat, API nebo strukturovaných databází, nikoli z hierarchií hloubky procházení.
Pokud je váš obsah rozptýlený na více stránkách s minimální strukturou, AI enginy mohou přeskočit hlubší položky nebo špatně pochopit jejich vztah k širšímu souboru obsahu. Pokud jsou rozdíly v metadatech malé nebo jsou slabé sémantické signály, váš stránkovaný obsah vypadá jako duplicitní—nebo je zcela vynechán. To vytváří zásadní mezeru ve viditelnosti: obsah, který dobře rankuje v tradičním Google vyhledávání, může zůstat pro AI generátory odpovědí zcela neviditelný. Toto rozlišení je důležité, protože AI systémy upřednostňují strukturovaná, úplná a snadno dohledatelná data. Neprovádějí „scrollování“ jako uživatel. Parsují kód, URL a metadata, aby obsah rychle a přesně sumarizovaly nebo citovaly. Pokud vaše stránka nezpřístupňuje obsah prostřednictvím prohledávatelných URL nebo bohatých metadat, AI enginy ho nemohou získat pro zahrnutí do generovaných odpovědí.
Volba mezi tradičním stránkováním a nekonečným scrollováním se stala určujícím faktorem pro objevitelnost obsahu v AI. Implementace nekonečného scrollování načítají obsah pomocí JavaScriptu až po interakci uživatele, což představuje zásadní problém s přístupností pro AI crawlery. Většina nastavení nekonečného scrollování nezpřístupňuje obsah přes samostatné URL—vše se načítá na jedné stránce dynamicky pomocí JavaScriptu. To znamená, že AI crawlery, které nesimulují skutečné chování uživatele jako scrollování nebo klikání, často přehlédnou vše, co je za prvním zobrazením. Pokud vaše stránka tento další obsah nezpřístupní pomocí prohledávatelných URL nebo metadat, AI enginy ho nezískají. Můžete mít 200 článků, 300 produktů nebo desítky případových studií, ale pokud jsou skryté pod událostmi načítanými JavaScriptem, AI vidí jen 12 položek. Možná.
Tradiční stránkování stále jednoznačně vítězí v AI indexaci, protože vytváří čisté, prohledávatelné URL (např. /blog/stranka/4), což umožňuje enginům plně přistupovat k vašemu obsahu a segmentovat ho. Signalizuje tematickou strukturu pomocí interního prolinkování a používá standardizované odkazy jako „Další stránka“ nebo „Předchozí stránka“, což pomáhá enginům pochopit, jak obsah souvisí. Stránkování omezuje závislost na JavaScriptu a zajišťuje načtení obsahu pro crawlery bez ohledu na způsob interakce uživatele se stránkou. Tato strukturální jasnost se přímo promítá do lepší AI viditelnosti—když ChatGPT nebo Perplexity crawlují váš web, dokáží stránkovaný obsah objevit a indexovat mnohem efektivněji než obsah skrytý za nekonečným scrollováním.
| Aspekt | Stránkování | Nekonečné scrollování |
|---|---|---|
| Přístupnost procházení | Unikátní URL umožňují hlubokou indexaci | Obsah často skrytý za JS načítáním |
| Objevitelnost v AI | Více stránek může rankovat nezávisle | Typicky je indexována jen jedna stránka |
| Strukturovaná data | Snadno přiřaditelná jednotlivým stránkám | Často chybí nebo jsou rozředěná |
| Přímé odkazování | Snadné odkazování na konkrétní obsah | Obtížné směřovat deep linky |
| Kompatibilita se sitemapou | Kompatibilní a úplná | Často opomíjí hluboký obsah |
| Struktura URL | Jasné, odlišné URL pro každou stránku | Jedna URL s dynamickým načítáním |
| Viditelnost obsahu | Veškerý obsah přístupný crawlerům | Obsah vyžaduje JS vykonání |
Technická architektura nekonečného scrollování vytváří zásadní bariéry pro objevitelnost obsahu v AI. Pokud se obsah načítá pouze pomocí JavaScriptu a žádné URL tuto novou část neodráží, AI enginy ji nikdy neuvidí. Pro crawler zbytek vašeho seznamu jednoduše neexistuje. Není to omezení AI systémů—je to důsledek toho, jak je nekonečné scrollování obvykle implementováno. Většina implementací nekonečného scrollování dává přednost uživatelskému zážitku před technickou přístupností, načítá obsah dynamicky bez vytváření odpovídajících URL nebo metadat, která by AI systémy mohly zpracovat.
Představte si reálný scénář: globální módní prodejce redesignoval svůj web s atraktivním rozhraním nekonečného scrollování. Rychlost webu se zlepšila, metriky zapojení vypadaly dobře, ale návštěvnost z AI shrnutí dramaticky poklesla. Jejich SKU se v konverzačních vyhledávacích nástrojích ztratily. Po auditu architektury bylo jasno: celý katalog byl skrytý za nekonečným scrollováním bez prohledávatelných záloh. Žádné sekundární URL stránek. Žádné doplňkové odkazy. Jen jeden dlouhý, neviditelný seznam produktů. Google SGE a ChatGPT nemohly získat nic za prvních pár produktů v každé kategorii. Ačkoli web vypadal krásně, jeho objevitelnost pro AI systémy byla rozbitá.
Správná implementace stránkování vyžaduje pozornost k několika technickým faktorům, které společně určují, zda AI systémy dokážou váš obsah objevit a citovat. Základem je čistá, logická struktura URL jasně indikující sekvenční vztahy. Ať už použijete parametry dotazu (?page=2) nebo strukturu založenou na cestách (/stranka/2/), důležitější než konkrétní formát je konzistence. Oba přístupy fungují pro AI systémy stejně dobře při správné implementaci. Podstatné je, aby každá stránkovaná URL načítala samostatný obsah a byla dostupná přes standardní HTML odkazy, které nevyžadují JavaScript k vykonání.
Samo-referenční kanonické tagy představují klíčové rozhodnutí ve stránkovací strategii. Každá stránkovaná stránka by měla obsahovat kanonickou značku odkazující na sebe sama, což signalizuje, že každá stránka je preferovanou verzí sebe sama. Tento přístup zachovává nezávislost sekvenčních URL, takže každá může soutěžit o pozice na základě svého konkrétního obsahu a relevance k různým dotazům. Vyhněte se zastaralé praxi kanonizovat všechny stránkované stránky na stránku jedna—tím sice konsolidujete signály, ale znemožníte jednotlivým stránkám samostatné rankování v AI systémech. Pokud vše kanonizujete na stránku jedna, explicitně tím říkáte AI enginům, aby ignorovaly potenciálně hodnotné stránky s unikátními produkty, obsahem nebo informacemi.
Unikátní metadata pro každou stránku jsou pro AI viditelnost nezbytná. Nepoužívejte generické titulky typu „Stránka 2“ nebo duplicitní popisy napříč sekvencí. Naopak, pište pro každou stránku specifická, klíčovými slovy bohatá metadata, která odráží její zaměření. Například místo „Produkty – Stránka 2“ použijte „Dámské sportovní boty do 2 500 Kč – Stránka 2“ nebo „AI trendy v retailu – knihovna případů (Stránka 2)“. Tato jasnost zvyšuje viditelnost, protože AI systémy rozumí kontextu a dokáží lépe určit, kdy je váš obsah relevantní pro konkrétní dotazy. Každá sada metadat musí být jasná, unikátní a v souladu s klíčovými slovy. Cílem je, aby účel každé stránky byl zřejmý jak AI systémům, tak lidským čtenářům.
Architektura interního prolinkování určuje, zda AI systémy dokážou objevit a efektivně procházet sekvenční stránky. Lineární struktura (stránka 1 → 2 → 3) vytváří dlouhé cesty procházení, kde hlubší stránky jsou mnoho kliků od hlavní stránky a cenný obsah může zůstat neobjeven. Chytrá implementace zahrnuje doplňkové odkazy, jako jsou možnosti „Zobrazit vše“ nebo kategorické rozcestníky, které vedou přímo na klíčové stránky, což zkracuje hloubku procházení a rovnoměrněji rozděluje hodnotu odkazů. Vztah mezi fasetovým filtrováním a sekvenčními stránkami přidává složitost, protože kombinace filtrů mohou generovat tisíce URL variant. Správné interní prolinkování zajistí, že prioritní stránky získají dostatečnou pozornost crawlerů, zatímco méně důležité varianty budou potlačeny pomocí noindex tagů nebo kanonických signálů.
Strategické interní prolinkovací řetězce od hlavního obsahu ke konkrétním stránkovaným stránkám vedou AI systémy vaší strukturou obsahu. Z hlavní kategorie odkazujte přímo na konkrétní stránkované stránky pomocí anchor textu, který napomáhá pochopení AI. Například: „Prozkoumejte další úspěšné ecommerce příběhy v naší sérii případových studií – stránka 3.“ Učiňte signál smysluplný a snadno nalezitelný. Tento přístup učí AI systémy, jak váš obsah drží pohromadě a jak by měl být objevován. Když AI crawlery narazí na tyto kontextové odkazy, chápou vztahy mezi stránkami a dokáží lépe určit, který obsah je nejrelevantnější pro konkrétní dotazy.
Problémy s duplicitním obsahem vznikají, když více URL zobrazuje identický nebo velmi podobný obsah bez řádného odlišení. To nastává, když sekvenční stránky postrádají unikátní prvky kromě uvedených položek, nebo když parametry URL vytvářejí více cest ke stejnému obsahu. Vyhledávače a AI systémy mají problém určit, kterou verzi rankovat, což může fragmentovat viditelnost mezi více URL. Pokud stránkované stránky obsahují pouze šablonovitý text, záhlaví a zápatí s minimem unikátního obsahu, mohou být vnímány jako „tenké“ stránky s malou hodnotou. Řešení spočívá v pečlivém použití kanonických tagů, unikátních meta popisů pro každou stránku a zajištění, že každá stránka nabízí dostatek jedinečné hodnoty nad rámec navigačních prvků a šablon.
Implementace pouze pomocí JavaScriptu jsou možná nejčastější chybou, která skrývá obsah před AI systémy. Pokud váš web využívá frameworky jako React nebo Angular k vykreslování ovládacích prvků stránek pouze na straně klienta bez server-side renderingu, AI crawlery nemusí nikdy objevit obsah za první stránkou. Zajistěte, aby navigační odkazy existovaly v počátečním HTML, které AI systémy obdrží, a nebyly generovány výhradně JavaScriptem po načtení stránky. Používejte progresivní vylepšení—základní HTML odkazy, které JavaScript může obohatit hladší interakcí a animacemi. Testujte implementaci pomocí nástrojů, které ukazují přesně to, co vidí crawlery oproti tomu, co zobrazuje JS-podporovaný prohlížeč. Tak odhalíte mezery v prohledávatelnosti, které by vás mohly připravit o AI viditelnost.
Sledování efektivity stránkování vyžaduje monitorování toho, jak AI systémy interagují s vaším vícestránkovým obsahem. Na rozdíl od tradičního SEO, kde Google Search Console nabízí přímé přehledy, vyžaduje monitorování AI viditelnosti jiné přístupy. Nástroje jako Screaming Frog SEO Spider mohou crawl váš web podobně, jako by k němu přistupovaly AI systémy, mapují struktury stránek a identifikují osiřelé stránky nebo problémy s hloubkou procházení. DeepCrawl a Sitebulk nabízejí pokročilou analýzu s vizualizací vztahů mezi stránkami. Google Search Console poskytuje pohled z pohledu Google, ukazuje, které stránkované URL jsou indexovány a vzory frekvence procházení.
Klíčové indikátory výkonnosti pro stránkovaný obsah zahrnují, zda se hluboké stránky objevují v odpovědích generovaných AI, jak často AI systémy citují váš stránkovaný obsah a zda různé stránky rankují pro různé „long-tail“ dotazy. Sledujte zmínky o vaší značce v AI odpovědích—pokud AI systémy konzistentně citují pouze vaši stránku jedna, ale nikdy nezmíní hlubší stránky, vaše stránkovací struktura možná potřebuje optimalizaci. Sledujte, které stránkované stránky přivádějí nejvíce návštěvnosti z AI zdrojů. Tato data odhalují, zda vaše strategie stránkování efektivně zpřístupňuje obsah AI systémům, nebo zda je třeba restrukturalizace. Pravidelné audity odhalí problémy dříve, než ovlivní viditelnost, zejména po aktualizacích webu nebo změně frameworku.
Prostředí AI-poháněného vyhledávání se rychle vyvíjí, s novými systémy a schopnostmi vznikajícími pravidelně. Strategie stránkování, které fungují dnes, by měly zůstat účinné i s dalším vývojem AI systémů, ale udržet si náskok vyžaduje sledovat nové trendy. Algoritmy AI vyhledávání jsou stále sofistikovanější v chápání vztahů mezi obsahem a určování, které stránkované stránky si zaslouží indexační prioritu. Google neural matching a pochopení založené na BERT pomáhají vyhledávačům rozpoznat, že stránka dvě kategorie nabízí jiné produkty než stránka jedna, i když okolní text je podobný. Toto vylepšené pochopení znamená, že dobře strukturované dělení stránek s podstatnými rozdíly mezi stránkami těží z nezávislé indexace více než kdy dřív.
AI však zároveň lépe odhaluje opravdu „tenký“ nebo duplicitní obsah na stránkovaných stránkách, což ztěžuje „obcházení“ systému s málo odlišenými stránkami. Algoritmy strojového učení přesněji předpovídají záměr uživatele a mohou zobrazit hluboké stránkování pro specifické „long-tail“ dotazy, pokud tyto stránky nejlépe odpovídají hledanému záměru. V praxi to znamená zajistit, aby každá stránkovaná stránka nabízela skutečnou unikátní hodnotu—odlišné produkty, jiný obsah nebo významné variace—a ne jen mechanické dělení totožných informací. Jak se AI systémy dále vyvíjejí, základní principy zůstávají konstantní: odlišné URL, prohledávatelné odkazy, unikátní hodnota na stránku a jasná metadata budou nadále určovat efektivitu stránkování pro AI viditelnost.
Sledujte, jak se váš obsah objevuje v odpovědích generovaných AI napříč ChatGPT, Perplexity a dalšími AI vyhledávači. Zajistěte, aby byla vaše značka citována, když AI systémy odpovídají na otázky z vašeho oboru.
Paginace rozděluje velké sady obsahu na zvládnutelné stránky pro lepší UX a SEO. Zjistěte, jak paginace funguje, jaký má dopad na pozice ve vyhledávačích a jaké...
Stránky na relaci měří průměrný počet zobrazených stránek na návštěvu. Zjistěte, jak tento ukazatel angažovanosti ovlivňuje chování uživatelů, konverzní poměry ...

Zjistěte, jak lazy loading ovlivňuje AI crawlery a odpovědní enginy. Objevte nejlepší postupy, jak zajistit, aby váš obsah zůstal viditelný pro AI systémy a zár...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.