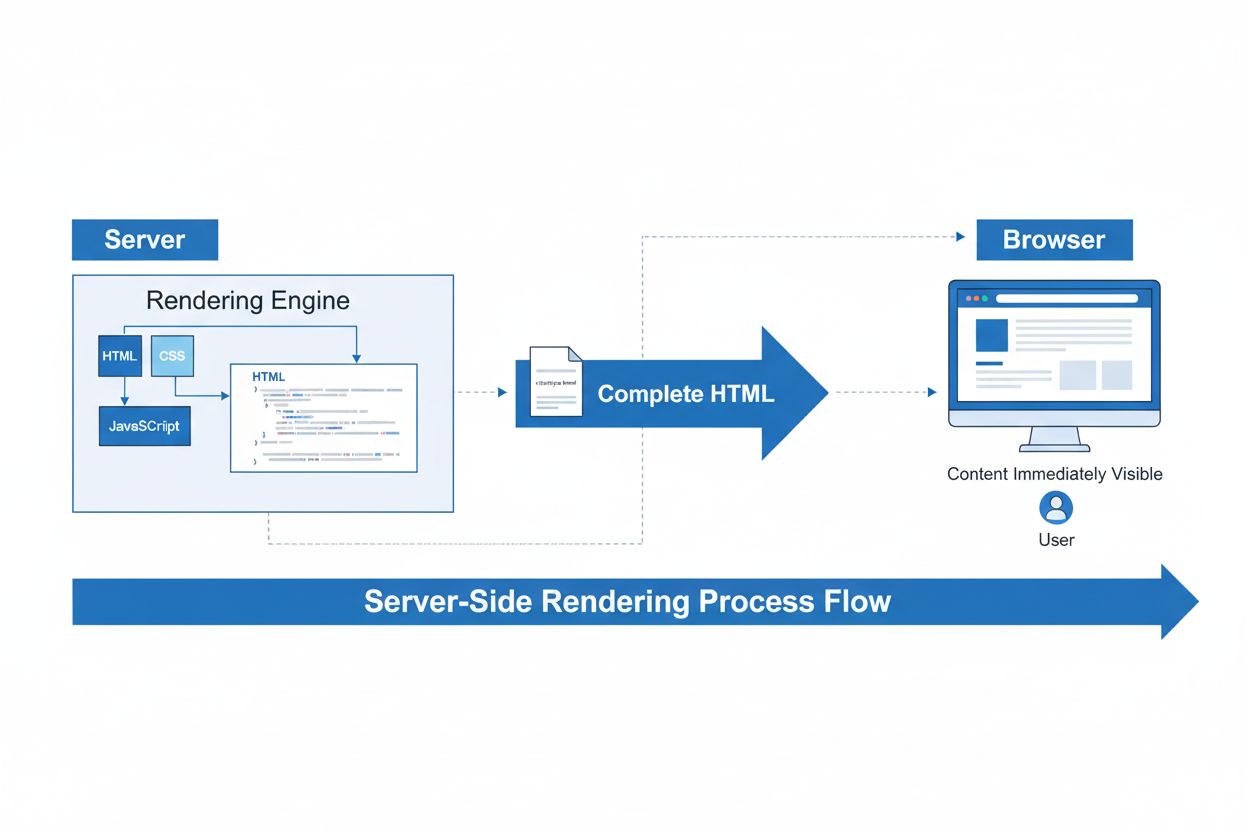
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) je webová technika, při které servery vykreslí kompletní HTML stránky před jejich odesláním do prohlížeče. Zjistěte, jak SSR zlepšuj...
10 min čtení

Zjistěte, jak server-side rendering umožňuje efektivní AI zpracování, nasazení modelů a real-time inference pro aplikace využívající AI a úlohy LLM.
Server-side rendering pro AI je architektonický přístup, kdy modely umělé inteligence a inference probíhají na serveru místo na klientských zařízeních. To umožňuje efektivní zpracování výpočetně náročných AI úloh, zajišťuje konzistentní výkon pro všechny uživatele a zjednodušuje nasazení a aktualizace modelů.
Server-side rendering pro AI označuje architektonický vzor, kdy modely umělé inteligence, inference a výpočetní úlohy probíhají na backend serverech namísto klientských zařízení, jako jsou prohlížeče nebo mobilní telefony. Tento přístup se zásadně liší od tradičního client-side renderingu, kde JavaScript běží v prohlížeči uživatele a generuje obsah. U AI aplikací znamená server-side rendering, že velké jazykové modely (LLM), inference strojového učení a AI generování obsahu vznikají centrálně na výkonné serverové infrastruktuře ještě před odesláním výsledků uživateli. Tento posun v architektuře je stále důležitější, protože možnosti AI jsou stále náročnější na výpočetní výkon a stávají se nedílnou součástí moderních webových aplikací.
Tento koncept vznikl na základě rozpoznání zásadního nesouladu mezi tím, co moderní AI aplikace vyžadují, a tím, co mohou realisticky poskytnout klientská zařízení. Tradiční webové frameworky jako React, Angular a Vue.js zpopularizovaly client-side rendering v průběhu 2010. let, ale tento přístup představuje významné výzvy při aplikaci na AI náročné úlohy. Server-side rendering pro AI tyto výzvy řeší využitím specializovaného hardwaru, centralizované správy modelů a optimalizované infrastruktury, kterou klientská zařízení nemohou konkurovat. To představuje zásadní změnu v paradigmatu, jak vývojáři navrhují AI aplikace.
Výpočetní náročnost moderních AI systémů činí server-side rendering nejen výhodným, ale často nezbytným. Klientská zařízení, zejména chytré telefony a levné notebooky, nemají dostatečný výkon pro efektivní real-time AI inference. Pokud AI modely běží na klientských zařízeních, uživatelé pociťují znatelné prodlevy, vyšší spotřebu baterie a nekonzistentní výkon v závislosti na hardwaru. Server-side rendering tyto problémy odstraňuje tím, že centralizuje AI zpracování na infrastruktuře vybavené GPU, TPU a specializovanými AI akcelerátory, které poskytují výkon o několik řádů vyšší než běžná zařízení.
Kromě výkonu přináší server-side rendering pro AI zásadní výhody v managementu modelů, bezpečnosti a konzistenci. Pokud AI modely běží na serverech, vývojáři mohou okamžitě aktualizovat, doladit a nasadit nové verze bez nutnosti, aby uživatelé stahovali aktualizace nebo spravovali různé verze modelů lokálně. To je zvláště důležité u velkých jazykových modelů a systémů strojového učení, které se rychle vyvíjejí s častými vylepšeními a bezpečnostními záplatami. Navíc, pokud zůstanou AI modely na serverech, zabrání se neautorizovanému přístupu, extrakci modelů a krádeži duševního vlastnictví, které jsou při distribuci modelů na klientská zařízení možné.
| Aspekt | Client-Side AI | Server-Side AI |
|---|---|---|
| Místo zpracování | Prohlížeč nebo zařízení uživatele | Backend servery |
| Hardwarové požadavky | Omezeno schopnostmi zařízení | Specializované GPU, TPU, AI akcelerátory |
| Výkon | Proměnlivý, závislý na zařízení | Konzistentní, optimalizovaný |
| Aktualizace modelů | Vyžaduje stažení uživatelem | Okamžité nasazení |
| Bezpečnost | Modely vystaveny extrakci | Modely chráněny na serverech |
| Latence | Závisí na výkonu zařízení | Optimalizovaná infrastruktura |
| Škálovatelnost | Omezená na zařízení | Vysoce škálovatelná mezi uživateli |
| Složitost vývoje | Vysoká (fragmentace zařízení) | Nižší (centralizovaná správa) |
Síťová režie a latence představují v AI aplikacích významné výzvy. Moderní AI systémy vyžadují neustálou komunikaci se servery kvůli aktualizacím modelů, získávání trénovacích dat a hybridním scénářům zpracování. Client-side rendering ironicky zvyšuje počet síťových požadavků oproti tradičním aplikacím, což snižuje očekávané výkonnostní přínosy client-side zpracování. Server-side rendering tyto komunikace konsoliduje, snižuje zpoždění a umožňuje real-time AI funkce jako živý překlad, generování obsahu nebo zpracování počítačového vidění bez latence typické pro inference na klientu.
Složitost synchronizace nastává, když AI aplikace potřebují udržovat konzistenci stavů napříč více AI službami současně. Moderní aplikace často využívají embeddingové služby, completion modely, doladěné modely a specializované inference enginy, které musí spolupracovat. Správa tohoto distribuovaného stavu na klientských zařízeních přináší zásadní složitost a riziko nekonzistence dat, zejména u real-time kolaborativních AI funkcí. Server-side rendering centralizuje správu stavu, zajišťuje konzistentní výsledky pro všechny uživatele a eliminuje inženýrskou režii spojenou s komplexní synchronizací stavu na klientu.
Fragmentace zařízení představuje zásadní vývojářskou výzvu pro client-side AI. Různá zařízení mají odlišné AI schopnosti, včetně neuronových procesorů, akcelerace GPU, podpory WebGL a paměťových omezení. Vytváření konzistentního AI zážitku v tomto fragmentovaném prostředí vyžaduje značné inženýrské úsilí, strategie pro postupnou degradaci a různé kódové větve podle schopností zařízení. Server-side rendering tuto fragmentaci zcela eliminuje tím, že všem uživatelům poskytuje přístup ke stejné optimalizované AI infrastruktuře bez ohledu na jejich zařízení.
Server-side rendering umožňuje zjednodušené a lépe udržovatelné architektury AI aplikací díky centralizaci klíčových funkcí. Místo distribuce AI modelů a inference logiky na tisíce klientských zařízení udržují vývojáři jedinou optimalizovanou implementaci na serverech. Tato centralizace přináší okamžité výhody jako rychlejší nasazení, jednodušší ladění a přímější optimalizaci výkonu. Pokud je třeba AI model vylepšit nebo opravit chybu, vývojáři ji vyřeší jednou na serveru, místo aby se snažili protlačit aktualizaci milionům klientských zařízení s různou mírou adopce.
Efektivita využití zdrojů se server-side renderingem dramaticky roste. Serverová infrastruktura umožňuje efektivní sdílení zdrojů mezi všemi uživateli – pooling spojení, caching a load balancing optimalizují využití hardwaru. Jediné GPU na serveru zvládne obsloužit inference požadavky tisíců uživatelů sekvenčně, zatímco pro stejnou schopnost na straně klienta by byly potřeba miliony GPU. Tato efektivita vede k nižším provozním nákladům, menšímu dopadu na životní prostředí a lepší škálovatelnosti s růstem aplikací.
Bezpečnost a ochrana duševního vlastnictví je se server-side renderingem výrazně jednodušší. AI modely představují velké investice do výzkumu, trénovacích dat a výpočetních zdrojů. Držení modelů na serverech předchází útokům na extrakci modelů, neautorizovanému přístupu a krádeži duševního vlastnictví, které jsou při distribuci na klienta reálné. Navíc serverové zpracování umožňuje jemnou správu přístupových práv, auditní logování a dohled nad souladem, což by na distribuovaných klientských zařízeních nešlo vynutit.
Moderní frameworky se vyvinuly tak, aby efektivně podporovaly server-side rendering pro AI úlohy. Next.js je v čele tohoto vývoje díky Server Actions, které umožňují plynulé AI zpracování přímo ze serverových komponent. Vývojáři mohou volat AI API, zpracovávat velké jazykové modely a streamovat odpovědi zpět klientovi s minimem boilerplate kódu. Framework zvládá komplexitu server-klient komunikace, takže se vývojář může soustředit na AI logiku a ne na infrastrukturu.
SvelteKit nabízí výkonově orientovaný přístup k server-side AI renderingu díky svým load funkcím, které běží na serveru před samotným renderem. To umožňuje předzpracování AI dat, generování doporučení a přípravu AI vylepšeného obsahu před odesláním HTML klientovi. Výsledné aplikace mají minimální JavaScriptové stopy a zároveň si zachovávají plné AI schopnosti, což vytváří extrémně rychlé uživatelské zážitky.
Specializované nástroje jako Vercel AI SDK abstrahují složitosti streamování AI odpovědí, správy počítání tokenů a zpracování různých AI poskytovatelů. Tyto nástroje umožňují vývojářům stavět sofistikované AI aplikace bez nutnosti hlubokých znalostí infrastruktury. Infrastrukturní volby jako Vercel Edge Functions, Cloudflare Workers a AWS Lambda poskytují globálně distribuované server-side AI zpracování, snižují latenci zpracováním požadavků blíže uživatelům a zároveň udržují centralizovanou správu modelů.
Efektivní server-side AI rendering vyžaduje propracované strategie cachování pro řízení výpočetních nákladů a latence. Redis caching uchovává často požadované AI odpovědi a uživatelské relace, čímž eliminuje opakované zpracování podobných dotazů. CDN caching globálně distribuuje statický AI-generovaný obsah, takže uživatelé dostávají odpovědi ze serverů blízko své geografické polohy. Edge caching rozmisťuje AI zpracovaný obsah napříč edge sítěmi a poskytuje ultra-nízkou latenci při zachování centralizované správy modelů.
Tyto cachingové přístupy spolupracují na vytvoření efektivních AI systémů škálovatelných pro miliony uživatelů bez úměrného růstu výpočetních nákladů. Díky cachování AI odpovědí na více úrovních mohou aplikace obsloužit většinu požadavků z cache a nové odpovědi počítat jen pro skutečně nové dotazy. To výrazně snižuje infrastrukturní náklady a zároveň zlepšuje uživatelský zážitek rychlejšími odezvami.
Vývoj směrem k server-side renderingu představuje dospívání webových praktik v reakci na požadavky AI. Jak se AI stává ústředním bodem webových aplikací, požadavky na výpočetní výkon si vynucují architektury orientované na server. Budoucnost přinese sofistikované hybridní přístupy, které automaticky rozhodují, kde renderovat podle typu obsahu, schopností zařízení, síťových podmínek a AI potřeb. Frameworky budou postupně vylepšovat aplikace AI možnostmi, aby základní funkce fungovaly univerzálně a zážitky byly co nejlepší, kde je to možné.
Tento posun v paradigmatu čerpá poučení z éry Single Page Application a zároveň řeší výzvy AI-native aplikací. Nástroje a frameworky jsou připraveny, aby vývojáři mohli využívat výhod server-side renderingu v AI éře a umožnit tak nové generaci inteligentních, responzivních a efektivních webových aplikací.
Sledujte, jak se váš web a značka zobrazují v AI-generovaných odpovědích napříč ChatGPT, Perplexity a dalšími AI vyhledávači. Získejte okamžitý přehled o své AI viditelnosti.
Server-Side Rendering (SSR) je webová technika, při které servery vykreslí kompletní HTML stránky před jejich odesláním do prohlížeče. Zjistěte, jak SSR zlepšuj...
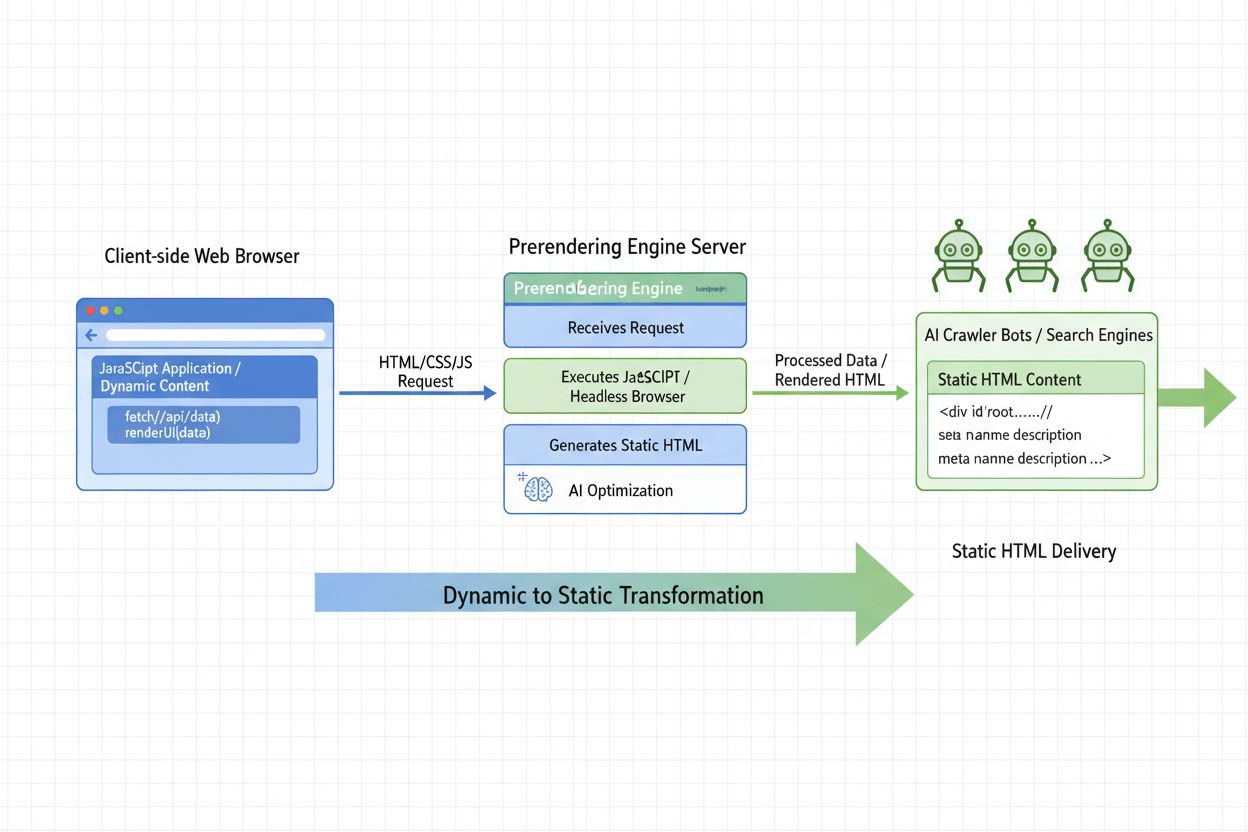
Zjistěte, co je AI Prerendering a jak strategie serverového renderování optimalizují váš web pro viditelnost AI crawlerů. Objevte implementační strategie pro Ch...
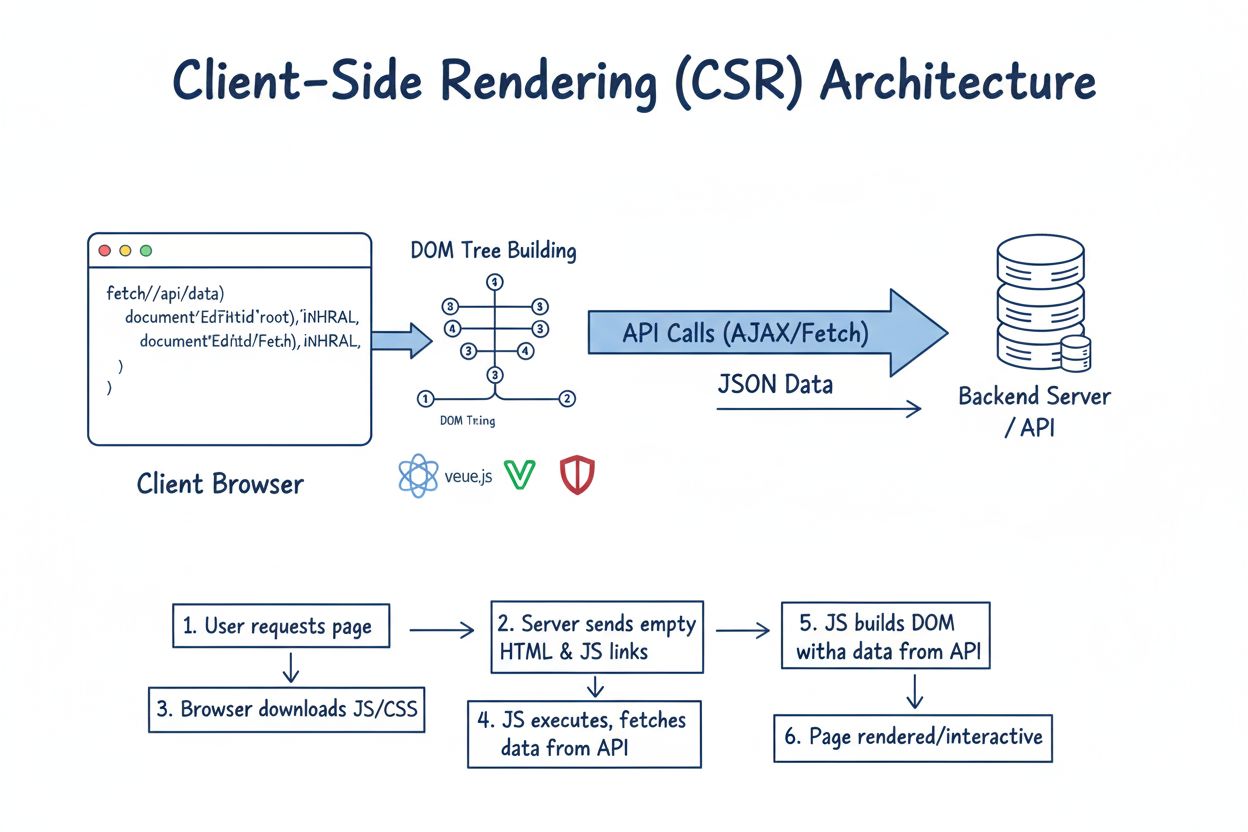
Zjistěte, co je Client-Side Rendering (CSR), jak funguje, jeho výhody a nevýhody a jaký má dopad na SEO, indexaci AI a výkon webových aplikací v roce 2024....
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.