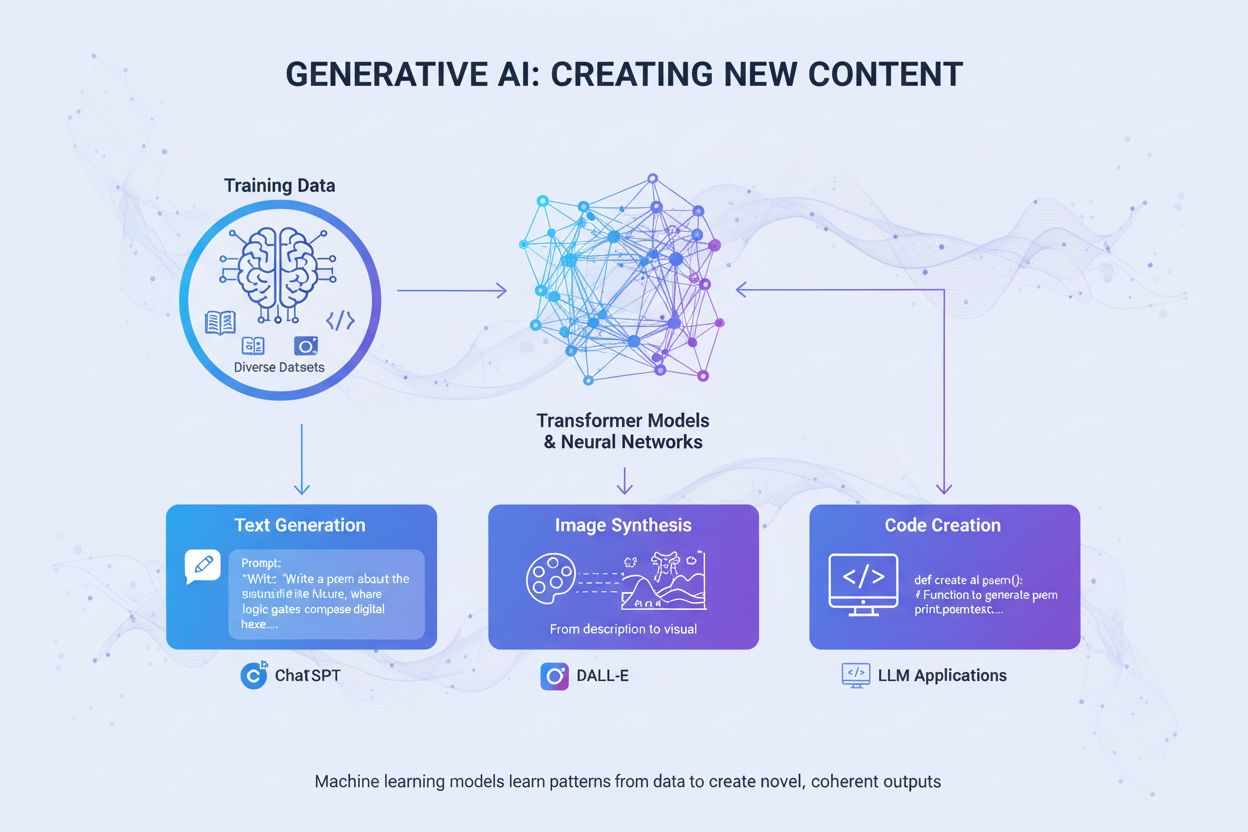
Generativní AI
Generativní AI vytváří nový obsah z trénovacích dat pomocí neuronových sítí. Zjistěte, jak funguje, její využití v ChatGPT a DALL-E a proč je pro značky důležit...
11 min čtení
AI-generovaný obrázek je digitální obraz vytvořený algoritmy umělé inteligence a modely strojového učení, nikoli lidskými umělci nebo fotografy. Tyto obrázky vznikají trénováním neuronových sítí na rozsáhlých datových sadách označených obrázků, což umožňuje AI učit se vizuální vzory a generovat originální, realistické vizuály na základě textových zadání, skic nebo jiných vstupních dat.
AI-generovaný obrázek je digitální obraz vytvořený algoritmy umělé inteligence a modely strojového učení, nikoli lidskými umělci nebo fotografy. Tyto obrázky vznikají trénováním neuronových sítí na rozsáhlých datových sadách označených obrázků, což umožňuje AI učit se vizuální vzory a generovat originální, realistické vizuály na základě textových zadání, skic nebo jiných vstupních dat.
AI-generovaný obrázek je digitální obraz vytvořený algoritmy umělé inteligence a modely strojového učení, nikoli lidmi – umělci nebo fotografy. Tyto obrázky vznikají pomocí sofistikovaných neuronových sítí trénovaných na rozsáhlých datových sadách označených obrázků, což umožňuje AI naučit se vizuální vzory, styly a vztahy mezi koncepty. Technologie umožňuje AI systémům generovat originální, realistické vizuály z různých vstupů – nejčastěji textových zadání, ale také ze skic, referenčních obrázků či jiných datových zdrojů. Na rozdíl od tradiční fotografie nebo ručně tvořeného umění mohou AI-generované obrázky zobrazovat cokoli představitelného, včetně nemožných scénářů, fantastických světů a abstraktních konceptů, které v reálném světě nikdy neexistovaly. Proces je mimořádně rychlý a často vytvoří kvalitní obrázek během několika vteřin, což z něj činí převratnou technologii pro kreativní odvětví, marketing, produktový design a tvorbu obsahu.
Cesta AI generování obrázků začala základním výzkumem v oblasti deep learningu a neuronových sítí, ale technologie se stala běžně používanou až na počátku 20. let 21. století. Generativní adversariální sítě (GANs), které v roce 2014 představil Ian Goodfellow, patřily mezi první úspěšné přístupy, kdy dvě soupeřící neuronové sítě generovaly realistické obrázky. Skutečný průlom však přišel s nástupem difuzních modelů a architektur založených na transformeru, které se ukázaly jako stabilnější a schopné produkovat kvalitnější výstupy. V roce 2022 byl zveřejněn Stable Diffusion jako open-source model, což demokratizovalo přístup k AI generování obrázků a nastartovalo masové přijetí. Krátce poté si DALL-E 2 od OpenAI a Midjourney získaly značnou pozornost a přivedly AI generování obrázků do povědomí širší veřejnosti. Podle aktuálních statistik je 71 % obrázků na sociálních sítích nyní generováno AI a globální trh s AI generátory obrázků měl v roce 2023 hodnotu 299,2 milionu dolarů s očekávaným růstem 17,4 % ročně do roku 2030. Tento explozivní růst odráží jak technologickou vyspělost, tak široké firemní přijetí napříč průmysly.
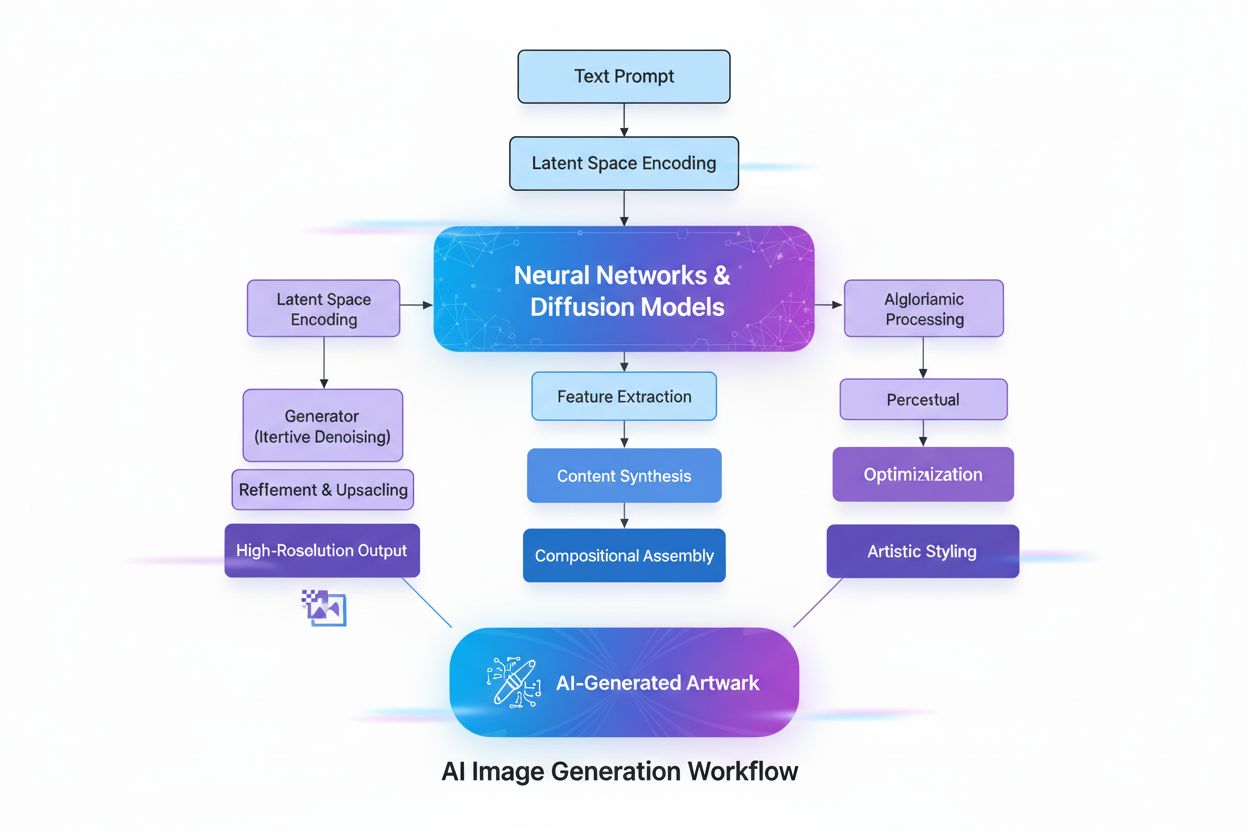
Tvorba AI-generovaných obrázků zahrnuje několik sofistikovaných technických procesů, které společně převádějí abstraktní koncepty do vizuální reality. Proces začíná porozuměním textu pomocí zpracování přirozeného jazyka (NLP), kdy AI převádí lidský jazyk na číselné reprezentace zvané embeddingy. Modely jako CLIP (Contrastive Language-Image Pre-training) zakódují textové zadání do vektorů s vysokou dimenzí, které zachycují sémantický význam a kontext. Například při zadání “červené jablko na stromě” NLP model rozloží tento text na číselné souřadnice, které odpovídají “červená”, “jablko”, “strom” a jejich prostorovým vztahům. Tato číselná mapa pak řídí proces generování obrázku a slouží jako pravidla, která určují, jaké prvky má AI zahrnout a jak mají vzájemně interagovat.
Difuzní modely, které pohánějí většinu moderních AI generátorů obrázků včetně DALL-E 2 a Stable Diffusion, fungují prostřednictvím elegantního iterativního procesu. Model začíná s čistým náhodným šumem – v podstatě chaotickým uspořádáním pixelů – a postupně jej vylepšuje několika kroky denoisingu. Během tréninku se model učí opačný proces přidávání šumu do obrázků, tedy v podstatě “odšumovat” poškozené verze zpět do původní podoby. Při generování nových obrázků pak model aplikuje tento naučený denoising opačně: začne od šumu a postupně jej přetváří do koherentního obrázku. Textové zadání řídí tuto transformaci v každém kroku, takže výsledný obrázek odpovídá popisu uživatele. Tento krokový proces umožňuje výjimečnou kontrolu a produkci velmi detailních, kvalitních obrázků.
Generativní adversariální sítě (GANs) využívají zcela odlišný přístup založený na teorii her. GAN se skládá ze dvou soupeřících neuronových sítí: generátoru, který vytváří falešné obrázky ze vstupního šumu, a diskriminátoru, který se snaží rozpoznat skutečné obrázky od falešných. Tyto sítě spolu soupeří v adversariální hře, kdy se generátor neustále zlepšuje, aby obelstil diskriminátor, zatímco diskriminátor se zdokonaluje v odhalování falzifikátů. Tato soutěžní dynamika posouvá obě sítě k dokonalosti a nakonec produkuje obrázky téměř nerozeznatelné od skutečných fotografií. GANs jsou obzvláště efektivní při generování fotorealistických lidských tváří a převodu stylů, i když jejich trénování bývá méně stabilní než u difuzních modelů.
Modely založené na transformerech představují další významnou architekturu a adaptují technologii transformerů původně vyvinutou pro zpracování přirozeného jazyka. Tyto modely vynikají v pochopení složitých vztahů v textových zadáních a v mapování jazykových tokenů na vizuální atributy. Pomocí mechanismů self-attention zachycují kontext a význam, což jim umožňuje zpracovávat složitá, vícedílná zadání s výjimečnou přesností. Transformery dokážou generovat obrázky, které přesně odpovídají detailním textovým popisům, takže jsou ideální pro aplikace vyžadující precizní kontrolu nad vlastnostmi výstupu.
| Technologie | Jak funguje | Silné stránky | Slabé stránky | Nejvhodnější použití | Příklad nástrojů |
|---|---|---|---|---|---|
| Difuzní modely | Iterativní denoising náhodného šumu do strukturovaných obrázků řízených textovými zadáními | Vysoce kvalitní detailní výstupy, vynikající sladění s textem, stabilní trénování, jemná kontrola nad vylepšováním | Pomalejší generování, vyšší nároky na výpočetní výkon | Generování obrázků z textu, vysoce rozlišené umění, vědecké vizualizace | Stable Diffusion, DALL-E 2, Midjourney |
| GANs | Dvě soupeřící neuronové sítě (generátor a diskriminátor) tvoří realistické obrázky v adversariálním tréninku | Rychlé generování, vynikající pro fotorealismus, vhodné pro převod stylů a vylepšování obrázků | Nestabilní trénování, problém “mode collapse”, méně přesná kontrola textu | Fotorealistické tváře, převod stylů, zvětšování obrázků | StyleGAN, Progressive GAN, ArtSmart.ai |
| Transformery | Převádí textová zadání na obrázky pomocí self-attention a vkládání tokenů | Výjimečná syntéza textu na obrázek, zvládají složitá zadání, silné sémantické porozumění | Vyžadují značné výpočetní zdroje, novější technologie s menší optimalizací | Kreativní generování z detailního textu, design a reklama, imaginativní koncepty | DALL-E 2, Runway ML, Imagen |
| Neural Style Transfer | Kombinuje obsah jednoho obrázku s uměleckým stylem druhého | Umělecká kontrola, zachování obsahu při aplikaci stylu, srozumitelný proces | Omezeno na převod stylu, vyžaduje referenční obrázky, méně flexibilní než jiné metody | Umělecká tvorba, aplikace stylu, kreativní vylepšení | DeepDream, Prisma, Artbreeder |
Přijetí AI-generovaných obrázků napříč podnikatelskými sektory je mimořádně rychlé a transformativní. V e-commerce a maloobchodu firmy využívají AI generování obrázků k vytváření produktových fotografií ve velkém, což eliminuje potřebu drahých focení. Podle současných údajů 80 % maloobchodních manažerů očekává, že jejich firmy do roku 2025 zavedou AI automatizaci a maloobchodní společnosti utratily v roce 2023 za AI nástroje 19,71 miliardy dolarů, přičemž generování obrázků tvoří významnou část. Trh s AI úpravami obrázků má v roce 2025 hodnotu 88,7 miliardy dolarů a očekává se, že v roce 2034 dosáhne 8,9 miliardy dolarů, přičemž firemní uživatelé představují přibližně 42 % všech výdajů.
V marketingu a reklamě používá 62 % marketérů AI pro tvorbu nových obrazových assetů a firmy využívající AI pro generování obsahu na sociální sítě zaznamenávají 15-25% nárůst engagementu. Možnost rychle generovat několik kreativních variant umožňuje A/B testování v dosud nevídaném rozsahu, což marketérům dovoluje optimalizovat kampaně s datově podloženou přesností. Časopis Cosmopolitan vzbudil v červnu 2022 pozornost, když vydal obálku vytvořenou zcela pomocí DALL-E 2, což bylo poprvé, kdy hlavní periodikum použilo pro titulní stranu obrázek generovaný AI. Použité zadání znělo: “A wide angle shot from below of a female astronaut with an athletic female body walking with swagger on Mars in an infinite universe, synthwave, digital art.”
V medicínském zobrazování se AI-generované obrázky zkoumají pro diagnostiku a generování syntetických dat. Výzkum ukázal, že DALL-E 2 dokáže vytvářet realistické rentgenové snímky na základě textových zadání a dokonce rekonstruovat chybějící prvky v radiologických obrázcích. Tato schopnost má významné důsledky pro lékařské vzdělávání, sdílení dat mezi institucemi při zachování soukromí i urychlení vývoje nových diagnostických nástrojů. Trh AI poháněných sociálních médií má dosáhnout 12 miliard dolarů do roku 2031, oproti 2,1 miliardy v roce 2021, což potvrzuje klíčovou roli technologie v tvorbě obsahu na digitálních platformách.
Rychlé rozšíření AI-generovaných obrázků přineslo významné etické a právní otázky, se kterými se průmysl i regulátoři teprve vypořádávají. Otázky autorského práva a duševního vlastnictví jsou snad nejpalčivější výzvou. Většina AI generátorů obrázků je trénována na obrovských databázích obrázků získaných z internetu, z nichž mnohé jsou chráněné autorským právem a vytvořené umělci či fotografy. V lednu 2023 podali tři umělci zásadní žalobu na Stability AI, Midjourney a DeviantArt s tvrzením, že firmy použily chráněná díla k trénování AI algoritmů bez souhlasu nebo odměny. Tento případ je příkladem širšího napětí mezi technologickou inovací a právy umělců.
Otázka vlastnictví a práv k AI-generovaným obrázkům je dosud právně nejasná. Když v roce 2022 vyhrál AI-generovaný obraz na výtvarné soutěži Colorado State Fair (přihlášený Jasonem Allenem pomocí Midjourney), vyvolalo to značnou kontroverzi. Řada lidí tvrdila, že protože obraz vytvořila AI, neměl by být považován za originální lidské dílo. Americký úřad pro autorská práva naznačil, že díla vytvořená zcela AI bez lidského tvůrčího zásahu nemusí být chráněna autorským právem, i když jde o vyvíjející se právní oblast s pokračujícími spory a úpravami regulací.
Deepfaky a dezinformace jsou další kritickou oblastí. AI generátory obrázků dokážou vytvořit vysoce realistické obrázky událostí, které se nikdy nestaly, a tím umožňují šíření falešných informací. V březnu 2023 se na sociálních sítích rozšířily deepfake obrázky vytvořené AI, zobrazující falešné zatčení bývalého prezidenta Donalda Trumpa (vytvořené pomocí Midjourney). Někteří uživatelé je zpočátku považovali za skutečné, což dokládá potenciál technologie k záměrnému zneužití. Sofistikovanost moderních AI obrázků ztěžuje jejich odhalení, což představuje výzvu pro platformy sociálních sítí i mediální domy při snaze udržet autenticitu obsahu.
Zkreslení v trénovacích datech je dalším významným etickým problémem. AI modely se učí z dat, která mohou obsahovat kulturní, genderové a rasové předsudky. Projekt Gender Shades vedený Joy Buolamwini z MIT Media Lab odhalil významnou zaujatost v komerčních systémech klasifikace pohlaví pomocí AI – chybovost u žen s tmavou pletí byla výrazně vyšší než u světlých mužů. Podobná zkreslení se mohou projevit i v generování obrázků a potenciálně podporovat škodlivé stereotypy nebo nedostatečné zastoupení některých skupin. Řešení těchto zkreslení vyžaduje pečlivou správu datových sad, různorodost trénovacích dat a průběžné vyhodnocování výstupů modelů.
Kvalita AI-generovaných obrázků zásadně závisí na kvalitě a konkrétnosti zadaného promptu. Prompt engineering – tedy umění vytvářet efektivní textová zadání – se stal klíčovou dovedností pro uživatele, kteří chtějí dosáhnout optimálních výsledků. Efektivní zadání mají několik společných rysů: jsou konkrétní a detailní (ne vágní), obsahují popis stylu či média (například “digitální malba”, “akvarel” nebo “fotorealistický”), zahrnují informace o atmosféře a osvětlení (například “zlatá hodina”, “filmové osvětlení” nebo “dramatické stíny”) a jasně stanovují vztahy mezi prvky.
Například místo prostého požadavku “kočka” je mnohem účinnější zadání: “chlupatá oranžová mourovatá kočka sedící na parapetu při západu slunce, teplé zlaté světlo proudící oknem, fotorealistické, profesionální fotografie.” Tato úroveň detailu poskytuje AI konkrétní pokyny ohledně vzhledu, prostředí, osvětlení i požadované estetiky. Výzkumy ukazují, že strukturované zadání s jasně členěnými informacemi vede k konzistentnějším a uspokojivějším výstupům. Uživatelé často využívají techniky jako specifikace uměleckého stylu, přidávání popisných přídavných jmen, začlenění technických fotografických pojmů či dokonce odkazy na konkrétní umělce nebo umělecké směry, aby AI nasměrovali k požadovaným výsledkům.
Různé platformy pro AI generování obrázků mají své specifické vlastnosti, přednosti i vhodné oblasti použití. DALL-E 2 vyvinutý OpenAI generuje detailní obrázky z textových zadání a nabízí pokročilé možnosti inpaintingu a editace. Funguje na principu kreditů, kdy si uživatelé kupují kredity na jednotlivé generování obrázků. DALL-E 2 je známý svou všestranností a schopností zpracovat složitá, nuancovaná zadání, což ho činí oblíbeným mezi profesionály i kreativci.
Midjourney se zaměřuje na uměleckou a stylizovanou tvorbu obrázků a je oblíbený mezi designéry a umělci pro svůj jedinečný estetický cit. Platforma funguje přes Discord bota, kde uživatelé zadávají prompt přes příkaz /imagine. Midjourney je známý zejména pro vizuálně atraktivní, malířské obrázky s doplňkovými barvami, vyváženým světlem a ostrými detaily. Nabízí tarif od 10 do 120 dolarů měsíčně, přičemž vyšší tarify umožňují více generovaných obrázků měsíčně.
Stable Diffusion, vyvinutý ve spolupráci Stability AI, EleutherAI a LAION, je open-source model, který demokratizuje generování obrázků pomocí AI. Jeho open-source povaha umožňuje vývojářům a výzkumníkům model upravovat a nasazovat, což je ideální pro experimentální projekty i firemní implementace. Stable Diffusion využívá architekturu latentních difuzních modelů a umožňuje efektivní generování i na běžných grafických kartách. Platforma má konkurenceschopnou cenu 0,0023 dolaru za obrázek, přičemž nováčkům nabízí bezplatné zkušební období.
Google Imagen je dalším významným hráčem a nabízí text-to-image difuzní modely s bezprecedentní fotorealističností a hlubokým jazykovým porozuměním. Tyto platformy dohromady demonstrují rozmanitost přístupů a obchodních modelů v oblasti AI generování obrázků, přičemž každá slouží různým uživatelským potřebám a případům použití.
Oblast AI generování obrázků se rychle vyvíjí a několik zásadních trendů formuje budoucnost této technologie. Zlepšování modelů a efektivity pokračuje závratným tempem – nové modely produkují výstupy s vyšším rozlišením, lepším sladěním s textem a rychlejším generováním. Trh s AI generátory obrázků má růst o 17,4 % ročně až do roku 2030, což ukazuje na trvalé investice i inovace. Mezi nové trendy patří generování videa z textu, kdy AI rozšiřuje schopnosti generování obrázků na tvorbu krátkých videí; generování 3D modelů, kdy AI přímo vytváří trojrozměrná aktiva; a generování v reálném čase, které zkracuje latenci a umožňuje interaktivní kreativní workflow.
Regulační rámce se začínají objevovat po celém světě, kdy vlády i profesní organizace vyvíjejí standardy pro transparentnost, ochranu autorských práv i etické použití. NO FAKES Act a podobná legislativa navrhují povinné označování AI-generovaného obsahu a informování o použití AI při jeho tvorbě. 62 % světových marketérů věří, že povinné označování AI-generovaného obsahu by mělo pozitivní vliv na výkon na sociálních sítích, což naznačuje uznání významu transparentnosti v oboru.
Integrace s dalšími AI systémy se zrychluje a generování obrázků se stává součástí širších AI platforem a workflow. Multimodální AI systémy, které kombinují generování textu, obrázků, zvuku a videa, jsou stále sofistikovanější. Technologie se také posouvá směrem k personalizaci a customizaci, kdy lze AI modely ladit na specifické umělecké styly, firemní vizuály nebo individuální preference. Jak se AI-generované obrázky stávají běžnou součástí digitálních platforem, roste význam monitoringu značky a sledování citací v AI odpovědích – nástroje, které sledují, jak se značka objevuje v AI generovaném obsahu, jsou stále cennější pro firmy, které chtějí udržet viditelnost i autoritu v době generativní AI.
AI-generované obrázky jsou zcela vytvořeny algoritmy strojového učení na základě textových zadání nebo jiných vstupů, zatímco tradiční fotografie zachycuje reálné scény objektivem fotoaparátu. AI obrázky mohou zobrazovat cokoli představitelného, včetně nemožných scénářů, zatímco fotografie je omezena na to, co existuje nebo lze fyzicky naaranžovat. Generování AI je obvykle rychlejší a nákladově efektivnější než organizování fotografických focení, což je ideální pro rychlou tvorbu obsahu a prototypování.
Difuzní modely pracují tak, že začínají s čistým náhodným šumem a postupně ho vylepšují opakovanými kroky denoisingu. Textové zadání je převedeno na číselné vektory, které řídí tento proces denoisingu a postupně přetvářejí šum v koherentní obrázek odpovídající popisu. Tento krok za krokem přístup umožňuje přesnou kontrolu a produkuje vysoce kvalitní, detailní výstupy s vynikajícím sladěním s vloženým textem.
Tři hlavní technologie jsou Generativní Adversariální Sítě (GANs), které využívají soupeřící neuronové sítě k tvorbě realistických obrázků; Difuzní modely, které z náhodného šumu postupně tvoří strukturované obrázky; a Transformery, které převádějí textová zadání na obrázky pomocí mechanismů self-attention. Každá architektura má své silné stránky: GANs vynikají ve fotorealismu, difuzní modely produkují vysoce detailní výstupy a transformery zvládají komplexní převod textu na obrázek výjimečně dobře.
Vlastnictví autorských práv k AI-generovaným obrázkům je právně nejasné a liší se podle jurisdikce. V mnoha případech mohou autorská práva náležet osobě, která vytvořila zadání, vývojáři AI modelu, nebo případně nikomu, pokud AI funguje zcela autonomně. Americký úřad pro autorská práva naznačil, že díla vytvořená zcela AI bez lidského tvůrčího vkladu nemusí být chráněna autorským právem, ačkoli jde o vyvíjející se právní oblast s probíhajícími spory a vývojem regulace.
AI-generované obrázky jsou široce využívány v e-commerce pro produktovou fotografii, v marketingu pro tvorbu vizuálů kampaní a obsahu na sociální sítě, ve vývoji her pro tvorbu postav a assetů, v medicínském zobrazování pro diagnostické vizualizace a v reklamě pro rychlé testování konceptů. Podle aktuálních údajů používá 62 % marketérů AI pro tvorbu nových obrazových assetů a trh s AI úpravami obrázků má v roce 2025 hodnotu 88,7 miliardy dolarů, což ukazuje výrazné firemní přijetí napříč odvětvími.
Současné AI generátory obrázků mají potíže s generováním anatomicky správných lidských rukou a obličejů, často vytvářejí nepřirozené rysy jako přebytečné prsty nebo nesymetrické prvky obličeje. Jsou také silně závislé na kvalitě trénovacích dat, což může vést ke zkreslení a omezené rozmanitosti výstupů. Dosažení specifických detailů vyžaduje pečlivé sestavení zadání a technologie někdy produkuje výsledky, které postrádají přirozený vzhled nebo nezachycují jemný tvůrčí záměr.
Většina AI generátorů obrázků je trénována na obrovských datových sadách obrázků získaných z internetu, z nichž mnohé jsou chráněny autorským právem. To vedlo k významným právním sporům, kdy umělci podali žaloby proti společnostem jako Stability AI a Midjourney za použití chráněných obrázků bez povolení nebo odměny. Některé platformy jako Getty Images a Shutterstock zakázaly nahrávání AI-generovaných obrázků kvůli nevyřešeným otázkám autorských práv a regulační rámce se stále vyvíjejí s cílem řešit transparentnost dat a spravedlivé odměňování.
Globální trh s AI generátory obrázků měl v roce 2023 hodnotu 299,2 milionu dolarů a očekává se růst o 17,4 % ročně až do roku 2030. Širší trh s úpravami obrázků pomocí AI má v roce 2025 hodnotu 88,7 miliardy dolarů a očekává se, že v roce 2034 dosáhne 8,9 miliardy dolarů. Navíc 71 % obrázků na sociálních sítích je nyní generováno AI a trh AI poháněných sociálních médií má dosáhnout 12 miliard dolarů do roku 2031, což dokládá explozivní růst a všeobecné rozšíření.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Generativní AI vytváří nový obsah z trénovacích dat pomocí neuronových sítí. Zjistěte, jak funguje, její využití v ChatGPT a DALL-E a proč je pro značky důležit...

Zjistěte, co jsou vlastní obrázky a originální vizuální obsah, jejich důležitost pro identitu značky, SEO a viditelnost ve vyhledávání AI. Objevte rozdíly mezi ...
Zjistěte, co je generování obsahu pomocí AI, jak funguje, jaké má výhody a výzvy, a seznamte se s osvědčenými postupy pro používání AI nástrojů k tvorbě marketi...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.