
Upřesnění dotazu
Upřesnění dotazu je iterativní proces optimalizace vyhledávacích dotazů pro lepší výsledky v AI vyhledávačích. Zjistěte, jak funguje v ChatGPT, Perplexity, Goog...
11 min čtení
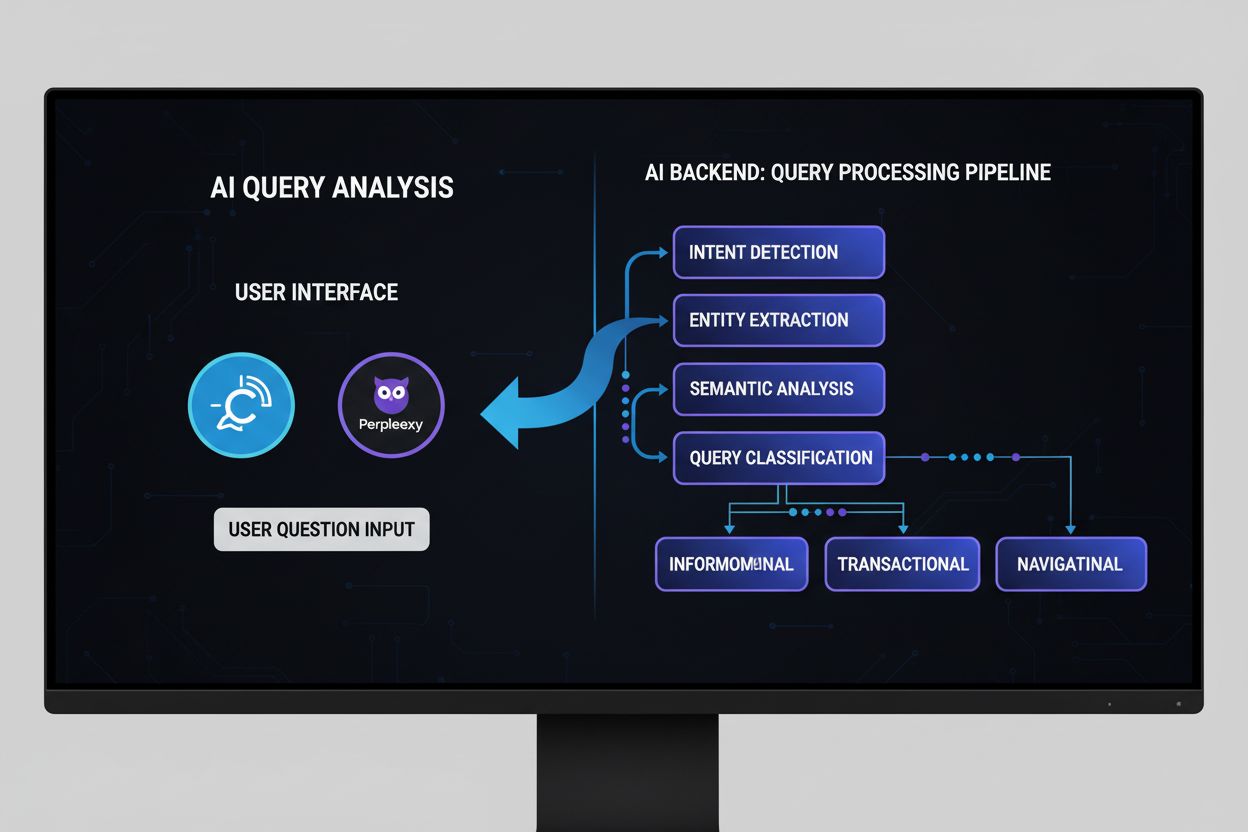
Analýza AI dotazů je proces zkoumání, interpretace a klasifikace uživatelských dotazů zadaných do AI systémů s cílem porozumět záměru, extrahovat význam a optimalizovat generování odpovědí. Zahrnuje analýzu struktury dotazu, sémantického obsahu a uživatelského záměru za účelem zlepšení vyhledávání informací a výkonnosti AI systémů napříč platformami jako ChatGPT, Perplexity a Google AI Overviews.
Analýza AI dotazů je proces zkoumání, interpretace a klasifikace uživatelských dotazů zadaných do AI systémů s cílem porozumět záměru, extrahovat význam a optimalizovat generování odpovědí. Zahrnuje analýzu struktury dotazu, sémantického obsahu a uživatelského záměru za účelem zlepšení vyhledávání informací a výkonnosti AI systémů napříč platformami jako ChatGPT, Perplexity a Google AI Overviews.
Analýza AI dotazů je systematický proces zkoumání, interpretace a klasifikace uživatelských dotazů zadaných do systémů umělé inteligence s cílem porozumět jejich podkladovému záměru, extrahovat sémantický význam a optimalizovat generování odpovědí. Představuje klíčovou součást toho, jak moderní AI systémy jako ChatGPT, Perplexity, Google AI Overviews a Claude zpracovávají uživatelský vstup před generováním odpovědí. Na rozdíl od tradičního vyhledávání založeného na klíčových slovech jde analýza AI dotazů za hranici povrchového párování vzorů a snaží se pochopit skutečný účel toho, na co se uživatelé ptají, jaké entity zmiňují a v jakém kontextu jejich otázka existuje. Tato sofistikovaná analýza umožňuje AI systémům získávat relevantnější informace, upřednostňovat autoritativní zdroje a strukturovat odpovědi tak, aby přímo odpovídaly potřebám uživatele. Pro značky a tvůrce obsahu se pochopení analýzy AI dotazů stalo zásadní, protože určuje, zda a jak se jejich obsah objeví v AI-generovaných odpovědích – což je klíčová otázka, když 52 % amerických dospělých nyní používá AI chatboty k vyhledávání nebo asistenci a 60 % tradičních vyhledávání končí bez jakéhokoli prokliku na web.
Koncept analýzy dotazů prošel za poslední dvě desetiletí dramatickým vývojem – od jednoduchého párování klíčových slov až po sofistikované sémantické porozumění. V počátcích vyhledávačů byly dotazy analyzovány převážně lexikální analýzou – rozkladem textu na jednotlivá slova a jejich párováním s indexovanými dokumenty. S rozvojem zpracování přirozeného jazyka a strojového učení však analýza dotazů nabyla na sofistikovanosti. Zavedení sémantické analýzy znamenalo zlom, protože umožnilo systémům pochopit, že „apple“ může označovat ovoce, technologickou firmu nebo místo podle kontextu. Dnešní analýza AI dotazů zahrnuje více vrstev porozumění: syntaktickou analýzu (gramatika a struktura věty), sémantickou analýzu (význam a vztahy), pragmatickou analýzu (kontext a záměr) a rozpoznávání entit (identifikace klíčových subjektů a objektů). Výzkum BrightEdge, který analyzoval tisíce nákupních dotazů napříč ChatGPT, Google AI Mode a AI Overviews, ukázal, že všechny tři AI nástroje upravují doporučení značek podle záměru dotazu – u srovnávacích dotazů je o 26 % více konkurenčních značek než u transakčních dotazů. To dokazuje, že moderní AI systémy jsou velmi pokročilé nejen v analýze toho, co uživatelé požadují, ale i proč se na to ptají.
Analýza AI dotazů funguje prostřednictvím několika propojených procesů, které společně transformují surový uživatelský vstup na využitelnou inteligenci pro AI systémy. Prvním komponentem je detekce záměru, která určuje, zda je dotaz informační (hledání znalostí), transakční (připravenost k nákupu či akci), nebo navigační (hledání konkrétního cíle). Tato klasifikace zásadně ovlivňuje způsob generování odpovědi AI systémem. Druhým komponentem je extrakce entit, která identifikuje klíčové subjekty, objekty a pojmy v dotazu. Například v dotazu „nejlepší nástroje pro projektové řízení pro vzdálené týmy“ systém extrahuje entity jako „projektové řízení“, „nástroje“, „vzdálené“ a „týmy“. Třetím komponentem je sémantická analýza, která určuje skutečný význam slov a frází v daném kontextu. To je klíčové, protože jazyk je přirozeně nejednoznačný – stejné slovo může podle okolního kontextu znamenat něco jiného. Čtvrtým komponentem je rozšíření a obohacení dotazu, kdy systémy přidávají kontextové informace analýzou souvisejících dotazů, historie vyhledávání a vzorců uživatelského chování. Nakonec hodnocení relevance posuzuje, které části obsahu nejlépe odpovídají analyzovanému dotazu. Podle výzkumu Averi získává obsah se správnou hierarchickou strukturou (značky H2, H3, H4) o 40 % více citací od AI systémů, což dokazuje, že struktura obsahu přímo ovlivňuje, jak AI systémy analyzují a hodnotí informace během procesu analýzy dotazu.
| Aspekt | ChatGPT | Perplexity AI | Google AI Overviews | Claude |
|---|---|---|---|---|
| Hlavní zaměření analýzy | Konverzační kontext a historie dialogu | Integrace reálného webového vyhledávání a ověřování zdrojů | Tradiční SEO signály + sémantické porozumění | Nuancované uvažování a hloubka kontextu |
| Klasifikace záměru dotazu | Implicitní z průběhu konverzace | Explicitní s upřesňujícími otázkami (Pro Search) | Na základě vzorců SERP a uživatelského chování | Odvozeno z detailního kontextu |
| Rozpoznávání entit | Udržuje entity v konverzaci | Extrahuje entity z 300+ zdrojů (Pro) | Využívá Knowledge Graph | Sleduje vztahy entit v rámci kontextu |
| Metoda sémantické analýzy | Na základě vzorů z trénovacích dat | Reálné sémantické párování s webovými zdroji | Kombinace historických vzorců a aktuálních signálů | Hluboké kontextové porozumění |
| Přístup k citacím | Omezené nebo žádné citace | Vždy cituje zdroje s odkazy | Cituje, když je to vhodné pro typ dotazu | Poskytuje kontext bez nutnosti vždy citovat |
| Rychlost odpovědi | Průměrně 2–5 sekund | 1,2 sekundy (jednoduché), 2,5 sekundy (složitější) | Liší se podle typu dotazu | 3–7 sekund u složitých analýz |
| Zpracování nejednoznačných dotazů | Pokládá upřesňující otázky v konverzaci | Ptá se na upřesnění před vyhledáváním | Odvozuje záměr z funkcí SERP | Zkoumá více interpretací |
| Vzorce zmínek o značkách | 4,7–6,5 značek na dotaz | 5,1–8,3 značek na dotaz | 1,4–3,9 značek na dotaz | Liší se dle složitosti dotazu |
Když uživatel zadá dotaz do AI systému, během milisekund proběhne složitá sekvence analytických kroků. Proces začíná tokenizací, kdy je dotaz rozdělen na jednotlivá slova nebo podslova, které může AI model zpracovat. Současně systém provádí syntaktickou analýzu, tedy gramatickou analýzu za účelem pochopení vztahů mezi slovy. Například u dotazu „Jaké jsou nejlepší postupy pro implementaci architektury mikroslužeb?“ systém rozpozná „nejlepší postupy“ jako hlavní koncept a „architektura mikroslužeb“ jako doménu. Následuje sémantické kódování, kdy systém převádí dotaz do číselných reprezentací (embeddingů), které zachycují význam. Zde vynikají moderní transformer modely jako BERT a GPT – chápou, že „nejlepší postupy“ a „doporučené přístupy“ jsou sémanticky podobné, i když používají různá slova. Poté systém provádí klasifikaci záměru, tedy přiřazení dotazu k jedné či více kategoriím záměru. Výzkum Nightwatch zjistil, že pochopení uživatelského záměru pomáhá zvýšit konverzní poměr leadů až o 30 %, pokud je správně sladěn s obsahovou strategií. Po klasifikaci záměru systém provádí propojení entit, kdy zmíněné entity spojuje s databázemi znalostí nebo referenčními materiály. Pokud například dotaz zmiňuje „Python“, systém na základě kontextu určí, zda jde o programovací jazyk, hada nebo komediální skupinu. Nakonec systém provádí hodnocení relevance, tedy posouzení, které dostupné informace nejlépe odpovídají analyzovanému dotazu. Celý tento proces probíhá v reálném čase – Perplexity AI zvládá průměrný čas odpovědi jen 1,2 sekundy u jednoduchých otázek a 2,5 sekundy u složitějších dotazů, přestože zpracovává 780 milionů dotazů měsíčně.
Klasifikace záměru dotazu je zřejmě nejkritičtější aspekt analýzy AI dotazů, protože zásadně určuje, jaký typ odpovědi AI systém vygeneruje. Tři hlavní kategorie záměru, které stanovil výzkumník Andrei Broder v roce 2002, tvoří dodnes základ moderní analýzy dotazů. Informační dotazy hledají znalosti nebo odpovědi na otázky – například „Jak ovlivňují běžecké boty výkon?“ nebo „Co je strojové učení?“. Tyto dotazy obvykle dostávají vzdělávací obsah, vysvětlení a doplňující informace. Transakční dotazy naznačují, že jsou uživatelé připraveni provést akci, například nakoupit, stáhnout nebo se registrovat. Patří sem například „Koupit iPhone 15 online“ nebo „Stáhnout Photoshop zkušební verzi“. Tyto dotazy dostávají obsah zaměřený na umožnění požadované akce. Navigační dotazy značí, že uživatelé hledají konkrétní web nebo cíl, například „Facebook přihlášení“ nebo „Netflix účet“. Tyto dotazy dostávají obsah, který přímo vede k cíli. Moderní analýza AI dotazů je však mnohem nuancovanější a rozpoznává, že mnoho dotazů obsahuje více záměrů současně. Dotaz „nejlepší běžecké boty“ může být informační (zjišťování typů), komerční (průzkum možností) i transakční (připravenost ke koupi). Podle analýzy nákupních dotazů od BrightEdge průměrně Google AI Mode uvádí 8,3 značek u srovnávacích dotazů (fáze průzkumu), ale jen 6,6 značek u transakčních dotazů, což ukazuje, že AI systémy upravují strategii odpovědí podle zjištěného záměru. Tato adaptace podle záměru je důvodem, proč značky potřebují chápat nejen to, zda se v odpovědích AI objevují, ale i pro které typy záměru je jejich obsah citován.
Technickým základem analýzy AI dotazů je zpracování přirozeného jazyka (NLP) a pokročilé modely strojového učení. Syntaktická analýza, také zvaná parsing, zkoumá gramatickou stavbu dotazů s cílem pochopit vztahy mezi slovy a frázemi. To zahrnuje identifikaci slovních druhů, rozpoznávání jmenných frází a pochopení vztahů sloves a objektů. Sémantická analýza jde ještě dál a určuje skutečný význam slov a frází v daném kontextu. Zde je klíčová disambiguace významu slov – proces určování, který význam slova je zamýšlen v případě více možností. Například slovo „banka“ může označovat finanční instituci, břeh řeky nebo náklon letadla. Systém využívá kontextové indicie k určení správného významu. Důležitou roli zde hraje lexikální sémantika – umožňuje strojům chápat vztahy mezi lexikálními jednotkami prostřednictvím technik jako stemming (redukování slov na kořen) a lemmatizace (převod slova na základní tvar). Moderní analýza AI dotazů se stále více opírá o deep learning modely, zejména transformer architektury jako BERT a GPT, které dokážou zachytit složité sémantické vztahy a kontextové nuance. Tyto modely jsou trénovány na obrovských objemech textových dat, takže se učí vzorce v používání jazyka a významy různých dotazů. Podle výzkumu citovaného Ethinos je obsah s explicitními signály aktualizace jako „Naposledy aktualizováno“ a odkazy na aktuální roky výrazně častěji vybírán AI systémy oproti staršímu obsahu konkurence, což dokazuje, že AI systémy analyzují nejen sémantický obsah, ale i časové signály aktuálnosti a relevance.
Pro značky a tvůrce obsahu je porozumění tomu, jak analýza AI dotazů funguje, jen polovinou úspěchu – druhou polovinou je monitoring toho, jak si jejich obsah v tomto analytickém rámci vede. Monitoring analýzy AI dotazů znamená sledovat, které dotazy vyvolávají zmínky o vaší značce, rozumět záměru těchto dotazů a měřit, jak často je váš obsah citován ve srovnání s konkurencí. AmICited a podobné platformy pro sledování AI viditelnosti fungují tak, že automaticky zadávají dotazy do AI systémů jako ChatGPT, Perplexity, Google AI Overviews a Claude, a poté analyzují odpovědi za účelem zjištění zmínek a citací značky. Tento monitoring odhaluje klíčové poznatky: v jakých dotazech se značka objevuje, na jaké pozici je obsah v AI odpovědích, jaká je viditelnost ve srovnání s konkurencí a jak se výkon mění v čase. Podle nejnovějších statistik Perplexity platforma v květnu 2025 zpracovala 780 milionů vyhledávacích dotazů, což je nárůst z 230 milionů v polovině roku 2024 – 240% růst za méně než rok. Tento explozivní nárůst objemu AI dotazů činí monitoring nezbytným pro značky, které chtějí udržet svou viditelnost. Proces monitoringu obvykle zahrnuje vytvoření knihovny promptů – standardizovaného souboru 50–100 oborově relevantních otázek, které odrážejí skutečný způsob dotazování na AI systémy. Testováním těchto promptů měsíčně napříč více AI platformami mohou značky sledovat svůj podíl AI hlasu (procento citací jejich obsahu vůči konkurenci) a identifikovat trendy ve viditelnosti. Výzkum BrightEdge ukázal, že srovnávací dotazy (fáze průzkumu) vykazují o 26 % více konkurenčních značek než transakční dotazy, což znamená, že značky potřebují různé strategie pro různé typy záměru.
Porozumění analýze AI dotazů umožňuje značkám optimalizovat svůj obsah pro lepší viditelnost v AI-generovaných odpovědích. Prvním nejlepším postupem je vytváření obsahových struktur na základě otázek, které přímo odpovídají způsobu, jakým se uživatelé ptají AI systémů. Namísto tradičních článků strukturovat obsah kolem konkrétních otázek uživatelů s přímými odpověďmi v úvodních větách. Výzkum Princeton citovaný SEO.ai zjistil, že obsah s jasnými otázkami a přímými odpověďmi byl o 40 % pravděpodobněji přeformulován nástroji typu ChatGPT. Druhým postupem je implementace správné obsahové hierarchie s popisnými značkami H2, H3 a H4, které signalizují změnu tématu. AI systémy potřebují jasné signály o začátku a konci informací pro extrakci relevantních pasáží. Třetím postupem je začlenění konkrétních, citovaných statistik a důkazů. Podle výzkumu Cornell University citovaného Ethinos „GEO metody s konkrétními statistikami zvyšují skóre imprese v průměru o 28 %.“ To znamená, že obsah plný ověřitelných dat, aktuálních statistik a správné atribuce významně zvyšuje šanci na citaci od AI. Čtvrtým postupem je udržování konzistentních informací o entitě napříč všemi webovými vlastnostmi. Pokud je název značky, popis a kontaktní údaje identické na webu, sociálních sítích, firemních katalozích i oborových databázích, AI systémy snáze rozpoznají a přiřadí značku k relevantním dotazům. Pátým postupem je implementace schema značky, zejména FAQ schema, Article schema a HowTo schema, které AI systémům explicitně říkají, jakou strukturu má váš obsah. Šestým postupem je zajištění dostupnosti obsahu pro AI crawlery tím, že klíčové informace budou v HTML, ne ukryté v obrázcích nebo JavaScriptu. Nakonec přidání signálů aktuálnosti jako „Naposledy aktualizováno“ a odkazy na aktuální rok pomáhají AI systémům určit, že vaše informace jsou aktuální a důvěryhodné.
Oblast analýzy AI dotazů se rychle vyvíjí a několik nových trendů zásadně ovlivňuje, jak budou AI systémy v příštích letech rozumět a reagovat na uživatelské dotazy. Multimodální analýza dotazů představuje významnou hranici, protože AI systémy čím dál více zpracovávají nejen text, ale i obrázky, zvuk a video. To znamená, že analýza dotazu bude muset chápat, jak různé modalitiy společně vyjadřují uživatelský záměr. Například uživatel může poslat fotku boty spolu s dotazem „Jaká je to značka a kde ji koupím?“, což vyžaduje současnou analýzu vizuálních i textových informací. Personalizace v analýze dotazů je dalším trendem – AI systémy budou stále více upravovat svou analýzu podle historie uživatele, jeho preferencí a kontextu. Systémy tak nebudou analyzovat každý dotaz izolovaně, ale v návaznosti na předchozí dotazy a vzorce chování. Evoluce záměru v reálném čase je další oblastí, protože AI systémy se stále lépe učí detekovat změnu uživatelského záměru během konverzace – uživatel může začít informačním dotazem a postupně se přesunout k transakčnímu záměru. Multilingválnost a kulturní kontext v analýze dotazů se rozšiřuje: systémy jako Perplexity nyní podporují 46 jazyků a rozumí kulturním nuancím ve formulaci dotazů. Nové protokoly jako LLMs.txt (navrhovaný standard podobný robots.txt, ale pro AI systémy) mohou standardizovat způsob, jakým tvůrci obsahu komunikují s AI crawlery o svém obsahu. Podle projekcí Gartner citovaných Penfriend se očekává pokles organické návštěvnosti SERP o 50 % do roku 2028 v důsledku adopce AI vyhledávání, což činí optimalizaci pro analýzu dotazů stále důležitější pro viditelnost značky. Nakonec narůstá význam vysvětlitelnosti analýzy dotazů – výzkumn
Analýza dotazů je širší proces zkoumání a pochopení všech aspektů uživatelského vyhledávacího vstupu, včetně syntaxe, sémantiky a kontextu. Klasifikace dotazů je konkrétní součástí analýzy dotazů, která přiřazuje dotazy do předem definovaných kategorií na základě záměru (informační, transakční, navigační) nebo tématu. Každá klasifikace zahrnuje analýzu, ale ne každá analýza vede k formální klasifikaci. Analýza dotazů poskytuje základ, který umožňuje přesnou klasifikaci.
AI systémy využívají analýzu dotazů k pochopení toho, co uživatelé skutečně chtějí, ještě před generováním odpovědí. Analýzou záměru, extrakcí klíčových entit a pochopením sémantických vztahů mohou AI systémy získat relevantnější informace, upřednostnit autoritativní zdroje a vhodně strukturovat odpovědi. Například informační dotaz obdrží vzdělávací obsah, zatímco transakční dotaz obdrží produktové stránky. Tento cílený přístup výrazně zvyšuje relevanci odpovědí a spokojenost uživatelů.
Sémantická analýza určuje skutečný význam slov a frází v jejich konkrétním kontextu a jde nad rámec prostého párování klíčových slov. Pomáhá AI systémům pochopit, že 'apple' může znamenat ovoce nebo technologickou firmu v závislosti na okolním kontextu. Sémantická analýza využívá techniky jako rozlišení významu slov a lexikální sémantiku pro řešení nejednoznačnosti, což umožňuje AI systémům poskytovat kontextově vhodné odpovědi místo obecných výsledků založených pouze na klíčových slovech.
Analýza dotazů přímo ovlivňuje viditelnost značky, protože AI systémy ji využívají k určení, který obsah nejlépe odpovídá konkrétním uživatelským dotazům. Když AI systém analyzuje dotaz a klasifikuje jej jako hledající porovnání produktů, vybere obsah, který tomuto záměru odpovídá. Značky, které rozumí tomu, jak jsou jejich cílové dotazy analyzovány, mohou optimalizovat strukturu, srozumitelnost a důkaznost obsahu tak, aby odpovídal způsobu, jakým AI systémy zpracovávají a hodnotí informace, a tím zvyšují pravděpodobnost citace.
Mezi hlavní výzvy patří nejednoznačnost dotazů (krátké dotazy s více možnými významy), nedostatek kontextu (omezené informace v krátkých vyhledáváních), vyvíjející se jazyk a slang, překlepy a potřeba zpracování v reálném čase ve velkém měřítku. Kromě toho může být uživatelský záměr mnohovrstevnatý nebo implicitní namísto explicitního. Perplexity AI zpracovává 780 milionů dotazů měsíčně, což vyžaduje systémy schopné zvládat tyto výzvy ve velkém rozsahu při zachování přesnosti a rychlosti.
Různé AI platformy kladou důraz na různé aspekty analýzy dotazů v závislosti na své architektuře a cílech. ChatGPT se zaměřuje na konverzační kontext a historii dialogu. Perplexity zdůrazňuje integraci reálného webového vyhledávání a citace zdrojů. Google AI Overviews upřednostňují tradiční SEO signály spolu se sémantickým porozuměním. Claude se zaměřuje na nuancované uvažování a kontext. Tyto rozdíly znamenají, že stejný dotaz může být analyzován a zodpovězen různě na různých platformách, což ovlivňuje, který obsah bude citován.
Záměr dotazu je základní cíl nebo účel za uživatelským vyhledáváním. Tři hlavní záměry jsou informační (hledání znalostí), transakční (připravenost k akci) a navigační (hledání konkrétního cíle). Pochopení záměru je důležité pro monitoring AI, protože určuje, jaký typ obsahu budou AI systémy upřednostňovat. Značky musí sledovat nejen to, zda se objevují v AI odpovědích, ale i pro které typy záměru, což odhaluje, kde je jejich obsah pro uživatele nejcennější.
Značky mohou optimalizovat pro AI analýzu dotazů vytvářením jasného, dobře strukturovaného obsahu, který přímo odpovídá na konkrétní otázky. Používejte nadpisy s otázkami, poskytujte přímé odpovědi v úvodních větách, zahrnujte konkrétní statistiky s daty, citujte autoritativní zdroje a udržujte konzistentní informace o entitách napříč platformami. Implementujte správné schema značky (FAQ, Article, HowTo), zajistěte snadnou extrahovatelnost pro AI systémy a zaměřte se na sémantickou jasnost místo hustoty klíčových slov. Výzkumy ukazují, že obsah se správnou hierarchickou strukturou získává o 40 % více AI citací.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Upřesnění dotazu je iterativní proces optimalizace vyhledávacích dotazů pro lepší výsledky v AI vyhledávačích. Zjistěte, jak funguje v ChatGPT, Perplexity, Goog...
Zjistěte, jak identifikovat dotazy, ve kterých konkurenti vynikají v AI citacích. Ovládněte analýzu konkurenčních dotazů pro ChatGPT, Perplexity a Google AI Ove...
Zjistěte více o vzorech AI dotazů – opakujících se strukturách a formulacích, které uživatelé používají při pokládání otázek AI asistentům. Objevte, jak tyto vz...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.