
PerplexityBot: Co musí vědět každý majitel webu
Kompletní průvodce crawlerem PerplexityBot – pochopte, jak funguje, spravujte přístup, sledujte citace a optimalizujte pro viditelnost v Perplexity AI. Zjistěte...
8 min čtení

Webový crawler Amazonu používaný k vylepšování produktů a služeb včetně Alexy, nákupního asistenta Rufus a AI-poháněných vyhledávacích funkcí Amazonu. Respektuje Robots Exclusion Protocol a lze jej ovládat prostřednictvím direktiv robots.txt. Může být použit pro trénink AI modelů.
Webový crawler Amazonu používaný k vylepšování produktů a služeb včetně Alexy, nákupního asistenta Rufus a AI-poháněných vyhledávacích funkcí Amazonu. Respektuje Robots Exclusion Protocol a lze jej ovládat prostřednictvím direktiv robots.txt. Může být použit pro trénink AI modelů.
Amazonbot je oficiální webový crawler Amazonu navržený k vylepšování produktů a služeb společnosti sběrem a analýzou webového obsahu. Tento sofistikovaný crawler pohání kritické funkce Amazonu včetně hlasového asistenta Alexa, AI nákupního asistenta Rufus a AI-poháněných vyhledávacích zkušeností Amazonu. Amazonbot operuje pomocí user agent stringu Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, který jej identifikuje webovým serverům. Data shromážděná Amazonbot mohou být použita k trénování AI modelů Amazonu, což z něj činí klíčovou komponentu širší AI infrastruktury a strategie vývoje produktů Amazonu.
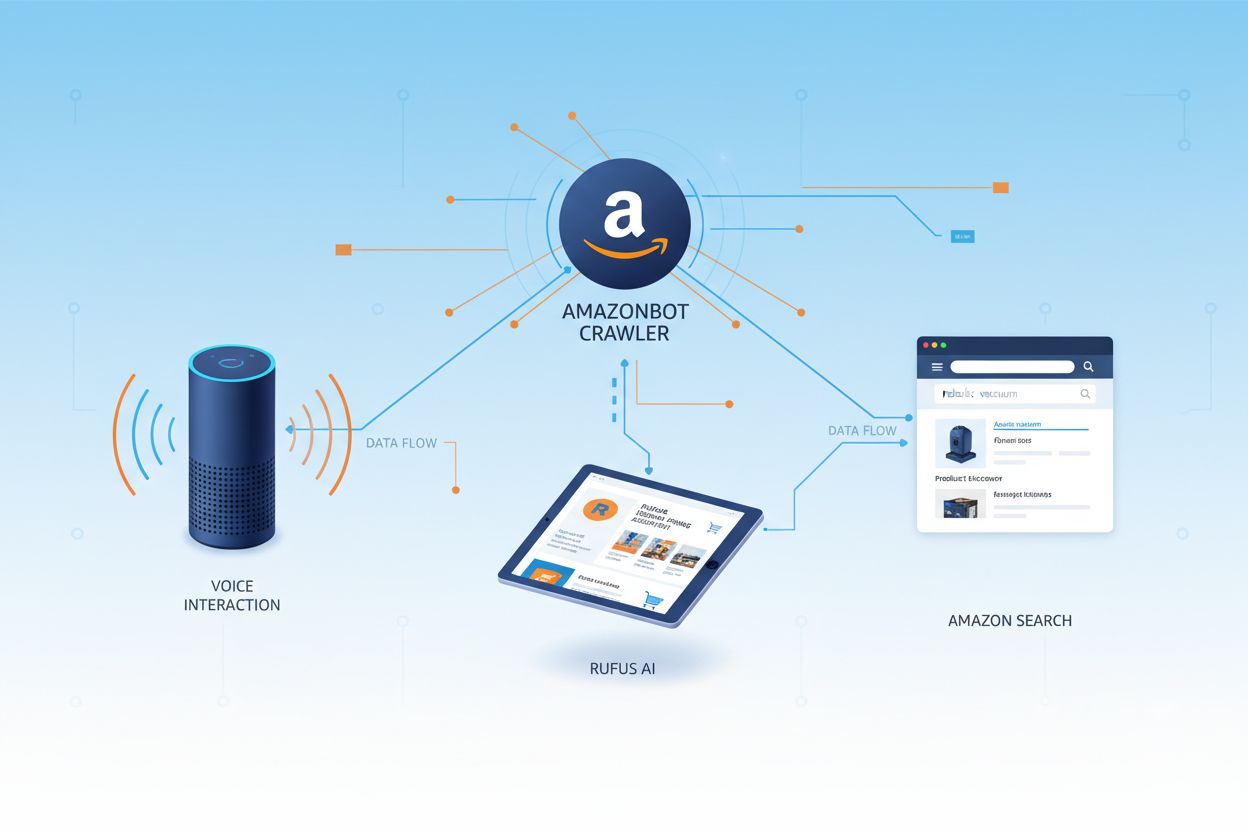
Amazon provozuje tři odlišné webové crawlery, z nichž každý slouží specifickým účelům v rámci jeho ekosystému. Amazonbot je primární crawler používaný pro obecné vylepšování produktů a služeb a může být použit pro trénink AI modelů. Amzn-SearchBot je specificky navržen k vylepšování vyhledávacích zkušeností v produktech Amazonu jako Alexa a Rufus, ale důležité je, že NECRAWLUJE obsah pro trénink generativních AI modelů. Amzn-User podporuje uživatelem iniciované akce, jako je načítání živých informací, když zákazníci pokládají Alexe otázky vyžadující aktuální webová data, a také necrawluje pro účely tréninku AI. Všechny tři crawlery respektují Robots Exclusion Protocol a dodržují direktivy robots.txt, což umožňuje majitelům webů kontrolovat jejich přístup. Amazon publikuje IP adresy pro každý crawler na svém vývojářském portálu, což umožňuje majitelům webů ověřit legitimní provoz. Navíc všechny crawlery Amazonu respektují direktivy rel=nofollow na úrovni odkazů a robots meta tagy na úrovni stránek včetně noarchive (prevence použití pro trénink modelů), noindex (prevence indexování) a none (prevence obojího).
| Název crawleru | Primární účel | Trénink AI modelů | User Agent | Klíčové případy použití |
|---|---|---|---|---|
| Amazonbot | Obecné vylepšování produktů/služeb | Ano | Amazonbot/0.1 | Celkové vylepšení služeb Amazonu, trénink AI |
| Amzn-SearchBot | Vylepšování vyhledávacích zkušeností | Ne | Amzn-SearchBot/0.1 | Vyhledávání Alexy, indexování nákupního asistenta Rufus |
| Amzn-User | Uživatelem iniciované načítání živých dat | Ne | Amzn-User/0.1 | Real-time dotazy Alexy, požadavky na aktuální informace |
Amazon respektuje průmyslově standardní Robots Exclusion Protocol (RFC 9309), což znamená, že majitelé webů mohou ovládat přístup Amazonbot prostřednictvím svého souboru robots.txt. Amazon načítá soubory robots.txt na úrovni hostitele z kořenového adresáře vaší domény (např. example.com/robots.txt) a použije kopii z cache z posledních 30 dnů, pokud soubor nelze načíst. Změny vašeho souboru robots.txt se typicky projeví přibližně do 24 hodin v systémech Amazonu. Protokol podporuje standardní direktivy user-agent a allow/disallow, což umožňuje granulární kontrolu nad tím, které crawlery mohou přistupovat ke specifickým adresářům nebo souborům. Nicméně je důležité poznamenat, že crawlery Amazonu NEPODPORUJÍ direktivu crawl-delay, takže tento parametr bude ignorován, pokud jej zahrnete do robots.txt.
Zde je příklad, jak ovládat přístup Amazonbot:
# Blokovat Amazonbot z crawlování celého webu
User-agent: Amazonbot
Disallow: /
# Povolit Amzn-SearchBot pro viditelnost ve vyhledávání
User-agent: Amzn-SearchBot
Allow: /
# Blokovat specifický adresář pro Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Povolit všechny ostatní crawlery
User-agent: *
Disallow: /admin/
Majitelé webů znepokojení bot provozem by měli ověřit, že crawlery tvrdící, že jsou Amazonbot, jsou skutečně legitimní crawlery Amazonu. Amazon poskytuje ověřovací proces pomocí DNS lookupů k potvrzení autentického provozu Amazonbot. K ověření legitimity crawleru nejprve najděte přistupující IP adresu ze serverových logů, poté proveďte reverzní DNS lookup na této IP adrese pomocí příkazu host. Získaný název domény by měl být subdoménou crawl.amazonbot.amazon. Dále proveďte forward DNS lookup na získaném názvu domény k ověření, že se překládá zpět na původní IP adresu. Tento obousměrný ověřovací proces pomáhá předcházet spoofing útokům, protože záškodníci by potenciálně mohli nastavit reverzní DNS záznamy k napodobení Amazonbot. Amazon publikuje ověřené IP adresy pro všechny své crawlery na vývojářském portálu na developer.amazon.com/amazonbot/ip-addresses/, poskytující další referenční bod pro ověření.
Příklad ověřovacího procesu:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Pokud máte otázky ohledně Amazonbot nebo potřebujete nahlásit podezřelou aktivitu, kontaktujte Amazon přímo na amazonbot@amazon.com a uveďte relevantní názvy domén ve vaší zprávě.
Existuje kritické rozlišení mezi crawlery Amazonu ohledně tréninku AI modelů. Amazonbot může být použit k trénování umělé inteligence Amazonu, což je relevantní pro tvůrce obsahu znepokojené tím, že jejich práce bude použita pro účely tréninku AI. Naproti tomu Amzn-SearchBot a Amzn-User explicitně NECRAWLUJÍ obsah pro trénink generativních AI modelů, zaměřujíc se výhradně na vylepšování vyhledávacích zkušeností a podporu uživatelských dotazů. Pokud chcete zabránit použití vašeho obsahu pro trénink AI modelů, můžete použít robots meta tag noarchive v HTML hlavičce vaší stránky, který instruuje Amazonbot, aby nepoužíval stránku pro účely tréninku modelů. Toto rozlišení je důležité pro vydavatele, tvůrce a majitele webů, kteří chtějí udržet kontrolu nad tím, jak je jejich obsah používán v pipeline tréninku AI, zatímco stále umožňují, aby se jejich obsah objevoval ve výsledcích vyhledávání Amazonu a doporučeních Rufus.
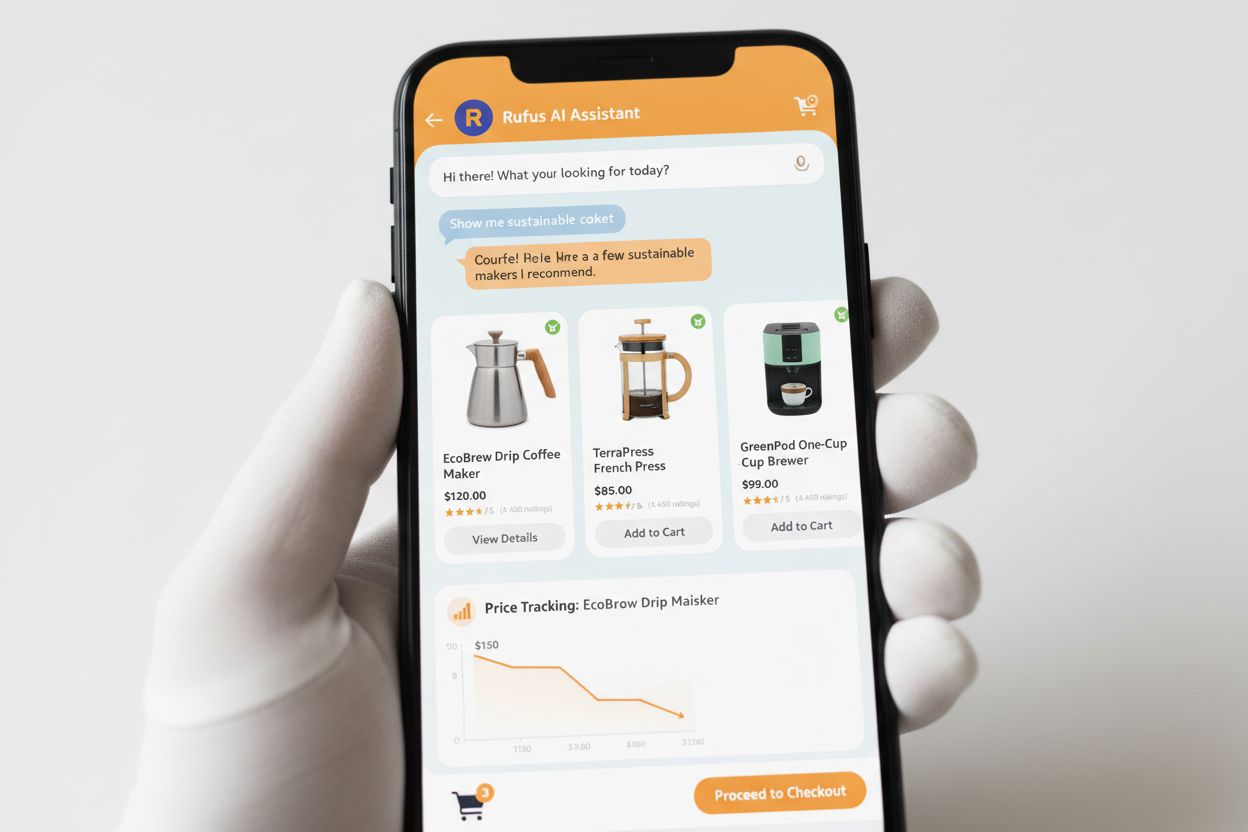
Rufus je pokročilý AI nákupní asistent Amazonu, který využívá webové crawlování a AI technologii k poskytování personalizovaných nákupních doporučení a asistence. Zatímco Amazonbot přispívá k celkové AI infrastruktuře Amazonu, Rufus specificky používá Amzn-SearchBot pro indexování produktových informací a webového obsahu relevantního pro nákupní dotazy. Rufus je postaven na Amazon Bedrock a využívá pokročilé velké jazykové modely včetně Anthropic Claude Sonnet a Amazon Nova, kombinované s vlastním modelem trénovaným na rozsáhlém katalogu produktů Amazonu, zákaznických recenzích, komunitních Q&A a webových informacích. Nákupní asistent pomáhá zákazníkům zkoumat produkty, porovnávat možnosti, sledovat ceny, nacházet nabídky a dokonce automaticky nakupovat položky, když dosáhnou cílových cen. Od svého spuštění se Rufus stal mimořádně populárním, více než 250 milionů zákazníků jej používá, měsíční aktivní uživatelé vzrostli o 149 % a interakce se zvýšily o 210 % meziročně. Zákazníci, kteří používají Rufus při nakupování, mají o více než 60 % vyšší pravděpodobnost nákupu během této nákupní session, což demonstruje významný dopad AI-poháněné nákupní asistence na spotřebitelské chování.
Majitelé webů by měli vyvinout strategický přístup k řízení crawlerů Amazonu na základě svých specifických obchodních cílů a politik obsahu:
noarchive robots meta tag nebo jej zcela zablokujte přes robots.txtamazonbot@amazon.com s informacemi o vaší doméně pro personalizované poradenství, pokud máte specifické obavy nebo otázky ohledně interakce crawlerů Amazonu s vaším webemAmazonbot je univerzální crawler Amazonu používaný k vylepšování produktů a služeb a může být použit pro trénink AI modelů. Amzn-SearchBot je specificky navržen pro vyhledávací zkušenosti v Alexe a Rufus a explicitně NECRAWLUJE pro trénink AI modelů. Pokud chcete zabránit použití pro trénink AI, blokujte Amazonbot, ale povolte Amzn-SearchBot pro viditelnost ve vyhledávání.
Přidejte následující řádky do souboru robots.txt v kořenovém adresáři vaší domény: User-agent: Amazonbot následované Disallow: /. To zabrání Amazonbot crawlovat celý váš web. Můžete také použít Disallow: /specific-path/ k blokování pouze určitých adresářů.
Ano, Amazonbot může být použit k trénování umělé inteligence Amazonu. Pokud tomu chcete zabránit, použijte robots meta tag v HTML hlavičce vaší stránky, který instruuje Amazonbot, aby nepoužíval stránku pro trénink modelů.
Proveďte reverzní DNS lookup na IP adrese crawleru a ověřte, že doména je subdoménou crawl.amazonbot.amazon. Poté proveďte forward DNS lookup k potvrzení, že doména se překládá zpět na původní IP. Můžete také zkontrolovat publikované IP adresy Amazonu na developer.amazon.com/amazonbot/ip-addresses/.
Použijte standardní syntaxi robots.txt: User-agent: Amazonbot pro cílení crawleru, následované Disallow: / pro blokování veškerého přístupu nebo Disallow: /path/ pro blokování specifických adresářů. Můžete také použít Allow: / pro explicitní povolení přístupu.
Amazon typicky reflektuje změny robots.txt přibližně do 24 hodin. Amazon pravidelně načítá váš soubor robots.txt a udržuje jeho kopii v cache až 30 dní, takže změny mohou trvat celý den, než se propagují jejich systémy.
Ano, absolutně. Můžete vytvořit samostatná pravidla pro každý crawler v souboru robots.txt. Například povolte Amzn-SearchBot pomocí User-agent: Amzn-SearchBot a Allow: /, zatímco blokujete Amazonbot pomocí User-agent: Amazonbot a Disallow: /.
Kontaktujte Amazon přímo na amazonbot@amazon.com. Vždy uveďte název vaší domény a jakékoli relevantní detaily o vašem problému ve vaší zprávě. Tým podpory Amazonu může poskytnout personalizované poradenství pro vaši konkrétní situaci.
Sledujte zmínky o vaší značce napříč AI systémy jako Alexa, Rufus a Google AI Overviews s AmICited - přední platformou pro monitorování AI odpovědí.
Kompletní průvodce crawlerem PerplexityBot – pochopte, jak funguje, spravujte přístup, sledujte citace a optimalizujte pro viditelnost v Perplexity AI. Zjistěte...

Zjistěte více o Amazon Rufus, AI nákupním asistentovi, který odpovídá na otázky o produktech, porovnává položky a poskytuje personalizovaná doporučení. Objevte,...

Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhl...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.