
Co je to kontextové okno v AI modelech
Zjistěte, co jsou kontextová okna v jazykových modelech AI, jak fungují, jaký mají dopad na výkon modelu a proč jsou důležitá pro AI aplikace a monitoring....
8 min čtení
Kontextové uzávorkování je technika optimalizace obsahu, která stanovuje jasné hranice kolem informací, aby zabránila mylné interpretaci a halucinacím AI. Využívá explicitní ohraničovače a kontextové značky k tomu, aby modely AI přesně pochopily, kde relevantní informace začínají a končí, a tím zabránily generování odpovědí na základě domněnek nebo smyšlených údajů.
Kontextové uzávorkování je technika optimalizace obsahu, která stanovuje jasné hranice kolem informací, aby zabránila mylné interpretaci a halucinacím AI. Využívá explicitní ohraničovače a kontextové značky k tomu, aby modely AI přesně pochopily, kde relevantní informace začínají a končí, a tím zabránily generování odpovědí na základě domněnek nebo smyšlených údajů.
Kontextové uzávorkování je technika optimalizace obsahu, která stanovuje jasné hranice kolem informací, aby zabránila mylné interpretaci a halucinacím AI. Tato metoda zahrnuje použití explicitních ohraničovačů—například XML tagů, markdown nadpisů nebo speciálních znaků—k označení začátku a konce konkrétních informačních bloků, čímž vzniká tzv. „kontextová hranice“. Strukturováním promptů a dat těmito jasnými značkami vývojáři zajišťují, že AI modely přesně chápou, kde relevantní informace začínají a končí, a tím zabraňují generování odpovědí na základě domněnek nebo smyšlených detailů. Kontextové uzávorkování představuje posun od tradičního prompt engineeringu k širší disciplíně kontextového inženýrství, která se zaměřuje na optimalizaci všech informací poskytovaných LLM k dosažení požadovaných výsledků. Tato technika je zvláště cenná v produkčním prostředí, kde je klíčová přesnost a konzistence, protože poskytuje matematické a strukturální mantinely, které řídí chování AI bez nutnosti složité podmínkové logiky.
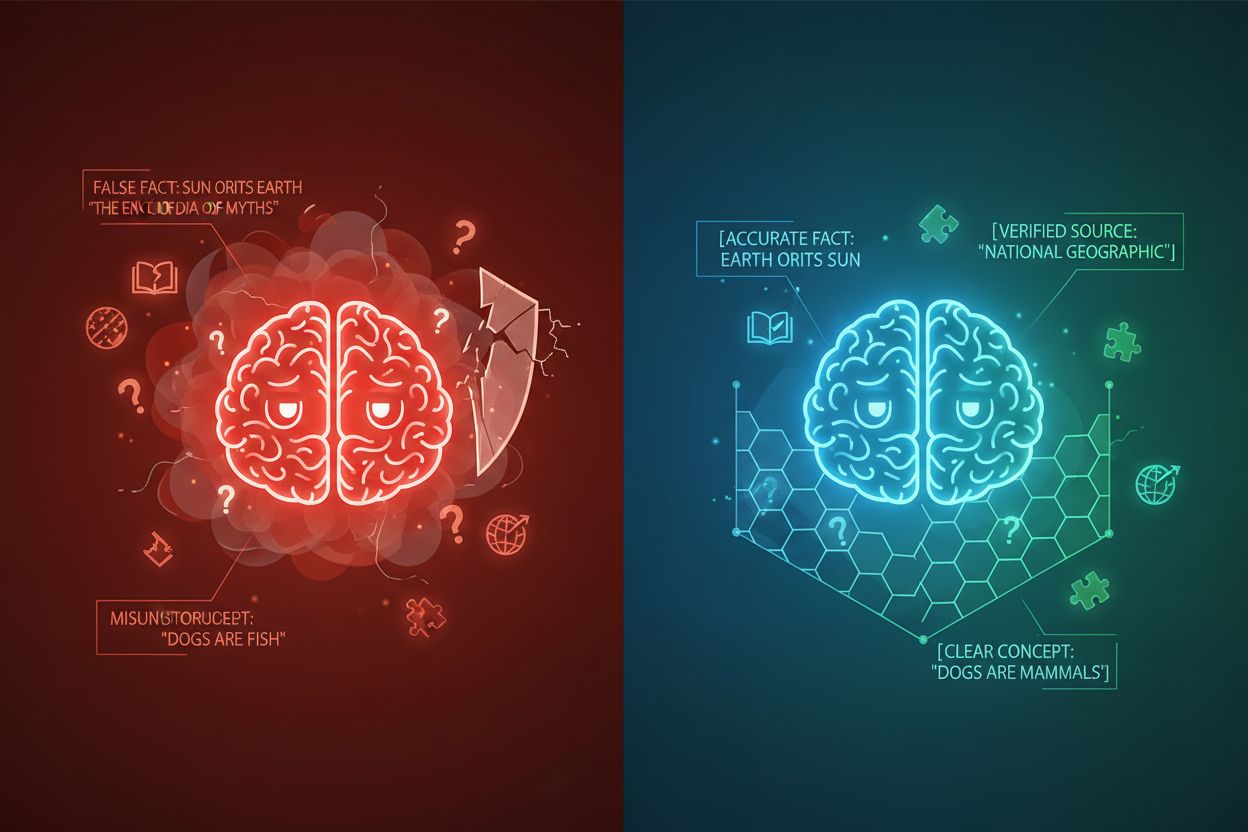
K halucinacím AI dochází, když jazykové modely generují odpovědi, které nejsou založeny na faktech nebo konkrétním poskytnutém kontextu, což vede k nepravdivým údajům, zavádějícím tvrzením nebo odkazům na neexistující zdroje. Výzkumy ukazují, že chatboti si vymýšlejí fakta přibližně ve 27 % případů, přičemž 46 % jejich textů obsahuje faktické chyby, zatímco novinářské citace ChatGPT byly nesprávné v 76 % případů. Tyto halucinace mají více příčin: modely se mohou učit vzorce ze zaujatých nebo neúplných tréninkových dat, špatně chápat vztahy mezi tokeny nebo jim chybí dostatečná omezení, která by limitovala možné výstupy. Důsledky jsou závažné napříč obory—ve zdravotnictví mohou halucinace vést ke špatné diagnóze a zbytečným lékařským zákrokům; v právní oblasti mohou vést ke smyšleným soudním citacím (viz případ Mata v. Avianca, kde právník čelil sankcím za použití falešných citací ChatGPT); v podnikání způsobují plýtvání zdroji špatnou analýzou a prognózami. Zásadní problém spočívá v tom, že bez jasných kontextových hranic fungují AI modely ve vakuum informací, kde mají tendenci „doplňovat mezery“ věrohodně znějícími, ale nepřesnými informacemi, a vnímají halucinace spíše jako funkci než chybu.
| Typ halucinace | Frekvence | Dopad | Příklad |
|---|---|---|---|
| Faktické nepřesnosti | 27–46 % | Šíření dezinformací | Falešné vlastnosti produktu |
| Smyšlené zdroje | 76 % (citace) | Ztráta důvěryhodnosti | Neexistující citace |
| Nepochopené koncepty | Různě | Nesprávná analýza | Špatné právní precedentní |
| Zaujaté vzorce | Průběžně | Diskriminační výstupy | Stereotypní odpovědi |
Účinnost kontextového uzávorkování spočívá v pěti základních principech:
Používání ohraničovačů: Používejte konzistentní, jednoznačné značky (XML tagy jako <context>, markdown nadpisy nebo speciální znaky) k jasnému oddělení informačních bloků a zabraňte tak modelu v záměně hranic mezi různými zdroji dat nebo typy instrukcí.
Správa kontextového okna: Strategicky rozdělujte tokeny mezi systémové instrukce, uživatelské vstupy a získané znalosti, abyste zajistili, že nejrelevantnější informace obsadí omezenou pozornost modelu, zatímco méně důležité detaily jsou filtrovány nebo získávány podle potřeby.
Hierarchie informací: Stanovte jasné priority různých typů informací, aby model poznal, které údaje jsou autoritativní zdroje a které pouze doplňkový kontext, a zabránilo se tak stejnému vážení primárních a sekundárních informací.
Definice hranic: Explicitně stanovte, jaké informace má model zohlednit a jaké ignorovat, čímž vytvoříte pevné mantinely a zabráníte extrapolaci mimo poskytnutá data nebo domněnkám o neuvedených informacích.
Značky rozsahu: Používejte strukturální prvky k vymezení rozsahu instrukcí, příkladů a dat, aby bylo jasné, zda se pokyny vztahují globálně, na konkrétní sekce nebo jen na určité typy dotazů.
Implementace kontextového uzávorkování vyžaduje pečlivé promyšlení struktury a prezentace informací pro AI modely. Strukturované formátování vstupů pomocí JSON nebo XML schémat poskytuje explicitní definice polí, které řídí chování modelu—například uzavření uživatelských dotazů do tagů <user_query> a očekávaných výstupů do <expected_output> vytváří jednoznačné hranice. Systémové prompty by měly být rozděleny do samostatných sekcí pomocí markdown nadpisů nebo XML tagů: <background_information>, <instructions>, <tool_guidance>, a <output_description> slouží specifickému účelu a pomáhají modelu pochopit hierarchii informací. Few-shot příklady by měly obsahovat uzávorkovaný kontext, který ukazuje přesně, jak má model strukturovat odpovědi, s jasnými ohraničovači kolem vstupů a výstupů. Definice nástrojů těží z explicitních popisů parametrů a omezení použití, což zabraňuje modelu v nesprávném použití nástrojů nebo jejich aplikaci mimo určený rozsah. Retrieval-Augmented Generation (RAG) systémy mohou implementovat kontextové uzávorkování uzavřením získaných dokumentů do zdrojových značek (<source>název_dokumentu</source>) a použitím skóre ukotvení pro ověření, že generované odpovědi zůstávají v hranicích získaných informací. Například funkce kontextových hranic v CustomGPT zajišťuje, že model je školen výhradně na nahraných datech a odpovědi nikdy nepřekročí poskytnutou znalostní bázi—praktická implementace kontextového uzávorkování na architektonické úrovni.
I když má kontextové uzávorkování podobnosti s příbuznými technikami, zaujímá v rámci AI inženýrství specifické místo. Základní prompt engineering se zaměřuje hlavně na tvorbu efektivních instrukcí a příkladů, ale postrádá systematičnost správy všech kontextových prvků, kterou kontextové uzávorkování přináší. Kontextové inženýrství, širší disciplína, zahrnuje kontextové uzávorkování jako jednu z mnoha součástí—patří sem optimalizace promptů, návrh nástrojů, správa paměti a dynamické získávání kontextu, což z něj činí nadmnožinu oproti úžeji zaměřenému přístupu kontextového uzávorkování. Jednoduché následování instrukcí spoléhá na schopnost modelu chápat přirozeně formulované pokyny bez explicitních strukturálních hranic, což často selhává, když jsou instrukce složité nebo když model čelí nejasným situacím. Ochranné mechanismy a validační systémy působí na úrovni výstupu a kontrolují odpovědi až po jejich vygenerování, zatímco kontextové uzávorkování funguje na vstupní úrovni a předchází halucinacím ještě před jejich vznikem. Klíčový rozdíl spočívá v tom, že kontextové uzávorkování je preventivní a strukturální—formuje informační prostředí, ve kterém model operuje—namísto korektivního či reaktivního přístupu, a proto je efektivnější a spolehlivější pro udržení přesnosti v produkčních systémech.
Kontextové uzávorkování přináší měřitelné výsledky v různých oblastech. Chatboti zákaznické podpory využívají kontextové hranice, aby omezili odpovědi na schválené znalostní báze společnosti a zabránili agentům ve vymýšlení vlastností produktů nebo neoprávněných závazků. Systémy pro analýzu právních dokumentů uzavírají relevantní judikaturu, zákony a precedenty, takže AI odkazuje pouze na ověřené zdroje a nevymýšlí si právní citace. Medicínské AI systémy implementují striktní kontextové hranice kolem klinických doporučení, údajů o pacientech a schválených léčebných protokolů, čímž předcházejí nebezpečným halucinacím ohrožujícím pacienty. Platformy pro generování obsahu využívají kontextové uzávorkování k prosazení brandových pravidel, tónu a faktických omezení, aby generovaný obsah odpovídal standardům organizace. Analytické a výzkumné nástroje uzavírají primární zdroje, datasety a ověřené informace, což AI umožňuje syntetizovat poznatky při zachování jasného odkazování a zabránění vymýšlení falešných statistik či studií. AmICited.com tento princip ilustruje tím, že monitoruje, jak AI systémy citují a zmiňují značky napříč GPT, Perplexity a Google AI Overviews—prakticky sleduje, zda AI modely dodržují vhodné kontextové hranice při diskusi o konkrétních firmách nebo produktech a pomáhá organizacím zjistit, zda AI halucinuje o jejich značce nebo informace podává přesně.
Úspěšná implementace kontextového uzávorkování vyžaduje dodržování ověřených postupů:
Začněte s minimálním kontextem: Vyjděte z nejmenší možné sady informací potřebných pro přesné odpovědi a rozšiřujte ji jen tehdy, když testy odhalí mezery, čímž zabráníte „znečištění“ kontextu a zachováte soustředění modelu.
Používejte konzistentní vzorce ohraničovačů: Zaveďte a udržujte jednotné konvence ohraničovačů napříč celým systémem, což usnadní modelu rozpoznání hranic a sníží zmatek z nejednotného formátování.
Testujte a validujte hranice: Systematicky ověřujte, zda model respektuje stanovené hranice tím, že se jej pokusíte přimět k jejich překročení, a identifikujte a uzavřete případné mezery ještě před nasazením.
Sledujte posun v chápání kontextu: Průběžně sledujte, zda odpovědi modelu zůstávají v zamýšlených mezích i v průběhu času, protože chování modelu se může měnit s různými vzory vstupů nebo vývojem znalostní báze.
Implementujte zpětnovazební smyčky: Vytvořte mechanismy, které umožňují uživatelům nebo lidským recenzentům označovat případy, kdy model překročil své hranice, a využijte tuto zpětnou vazbu k vylepšení definic kontextu a zlepšení budoucího výkonu.
Verzujte definice kontextu: Přistupujte k hranicím kontextu jako ke kódu, udržujte historii verzí a dokumentujte změny, což vám umožní návrat k předchozím definicím v případě zhoršení výsledků.
Několik platforem má schopnosti kontextového uzávorkování přímo ve svých jádrech. CustomGPT.ai implementuje kontextové hranice prostřednictvím funkce „context boundary“, která funguje jako ochranná zeď a zajišťuje, že AI používá pouze data poskytnutá uživatelem a nikdy nesahá do obecné znalosti ani si nevymýšlí informace—tento přístup se osvědčil například v organizacích typu MIT, kde je vyžadována naprostá přesnost v poskytování znalostí. Claude od Anthropic klade důraz na principy kontextového inženýrství, poskytuje detailní dokumentaci ke struktuře promptů, správě kontextových oken a implementaci ochranných mantinelů, které drží odpovědi v definovaných hranicích. AWS Bedrock Guardrails nabízí automatizované kontrolní mechanismy, které ověřují generovaný obsah vůči matematickým a logickým pravidlům, přičemž skóre ukotvení indikuje, zda odpovědi zůstávají v rámci zdrojového materiálu (pro finance jsou vyžadována skóre nad 0,85). Shelf.io poskytuje RAG řešení s možnostmi správy kontextu, což organizacím umožňuje využívat retrieval-augmented generation a zároveň striktně vymezovat, jaké informace může model používat a na které odkazovat. AmICited.com hraje doplňkovou roli tím, že monitoruje, jak AI systémy citují a zmiňují vaši značku napříč různými AI platformami, a pomáhá vám zjistit, zda AI modely dodržují vhodné kontextové hranice při diskusi o vaší organizaci nebo zůstávají v rámci přesných, ověřených informací o vaší značce—poskytuje tak přehled, zda kontextové uzávorkování skutečně funguje v praxi.
Prompt engineering se zaměřuje především na tvorbu efektivních instrukcí a příkladů, zatímco kontextové uzávorkování je systematický přístup ke správě všech kontextových prvků pomocí explicitních ohraničovačů a hranic. Kontextové uzávorkování je strukturovanější a preventivní, funguje na úrovni vstupu a předchází halucinacím dříve, než nastanou, zatímco prompt engineering je širší a zahrnuje různé optimalizační techniky.
Kontextové uzávorkování předchází halucinacím tím, že stanovuje jasné informační hranice pomocí ohraničovačů jako jsou XML tagy nebo markdown nadpisy. Tím AI modelu přesně určuje, které informace má zohlednit a které má ignorovat, a zabraňuje mu tak ve vymýšlení detailů nebo domněnkách o neuvedených informacích. Omezením pozornosti modelu na definované hranice se snižuje pravděpodobnost generování nepravdivých údajů nebo smyšlených zdrojů.
Běžné ohraničovače zahrnují XML tagy (např.
Principy kontextového uzávorkování lze aplikovat na většinu moderních jazykových modelů, i když účinnost se liší. Modely lépe trénované na respektování instrukcí (jako Claude, GPT-4 a Gemini) mají tendenci hranice spolehlivěji dodržovat. Technika nejlépe funguje v kombinaci s modely podporujícími strukturované výstupy a trénovanými na rozmanitých, dobře formátovaných datech.
Začněte organizováním systémových promptů do samostatných sekcí pomocí jasných ohraničovačů. Strukturované vstupy a výstupy tvořte pomocí JSON nebo XML schémat. Používejte konzistentní vzorce ohraničovačů napříč celým systémem. Zařaďte few-shot příklady, které modelu přesně ukazují, jak respektovat hranice. Důkladně testujte, zda model stanovené hranice dodržuje, a průběžně monitorujte výkon, abyste zachytili posun v chápání kontextu.
Kontextové uzávorkování může mírně zvýšit spotřebu tokenů kvůli přidaným ohraničovačům a strukturálním značkám, to je však obvykle vyváženo vyšší přesností a omezením halucinací. Technika ve skutečnosti zvyšuje efektivitu tím, že zabraňuje plýtvání tokeny na smyšlené informace. V produkčních systémech jsou přínosy v přesnosti mnohem větší než minimální režijní náklady na tokeny.
Kontextové uzávorkování a RAG jsou doplňkové techniky. RAG získává relevantní informace z externích zdrojů, zatímco kontextové uzávorkování zajišťuje, že model zůstává v hranicích těchto získaných informací. Společně vytvářejí silný systém, kde model může čerpat z externích znalostí, ale je omezen pouze na odkazování ověřených, získaných zdrojů.
Některé platformy mají vestavěnou podporu: CustomGPT.ai nabízí funkce kontextových hranic, Claude od Anthropic poskytuje dokumentaci ke kontextovému inženýrství a podporu strukturovaných výstupů, AWS Bedrock Guardrails zahrnuje automatizované kontrolní mechanismy, Shelf.io nabízí RAG s řízením kontextu. AmICited.com monitoruje, jak AI systémy citují vaši značku, a pomáhá ověřovat, že kontextové uzávorkování funguje efektivně.
Kontextové uzávorkování zajišťuje, že AI systémy poskytují přesné informace o vaší značce. Využijte AmICited ke sledování, jak AI modely citují a odkazují na váš obsah napříč GPT, Perplexity a Google AI Overviews.
Zjistěte, co jsou kontextová okna v jazykových modelech AI, jak fungují, jaký mají dopad na výkon modelu a proč jsou důležitá pro AI aplikace a monitoring....
Diskuze komunity o kontextových oknech AI a jejich dopadu na obsahový marketing. Porozumění tomu, jak limity kontextu ovlivňují zpracování vašeho obsahu AI....

Zjistěte, co je konverzační kontextové okno, jak ovlivňuje odpovědi AI a proč je důležité pro efektivní interakci s AI. Pochopte tokeny, omezení a praktické apl...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.