Oficiální webový crawler společnosti OpenAI, který shromažďuje tréninková data pro AI modely jako ChatGPT a GPT-4. Majitelé webových stránek mohou řídit přístup prostřednictvím robots.txt pomocí direktiv ‘User-agent: GPTBot’. Crawler respektuje standardní webové protokoly a indexuje pouze veřejně dostupný obsah.
GPTBot
Oficiální webový crawler společnosti OpenAI, který shromažďuje tréninková data pro AI modely jako ChatGPT a GPT-4. Majitelé webových stránek mohou řídit přístup prostřednictvím robots.txt pomocí direktiv 'User-agent: GPTBot'. Crawler respektuje standardní webové protokoly a indexuje pouze veřejně dostupný obsah.
Co je GPTBot?
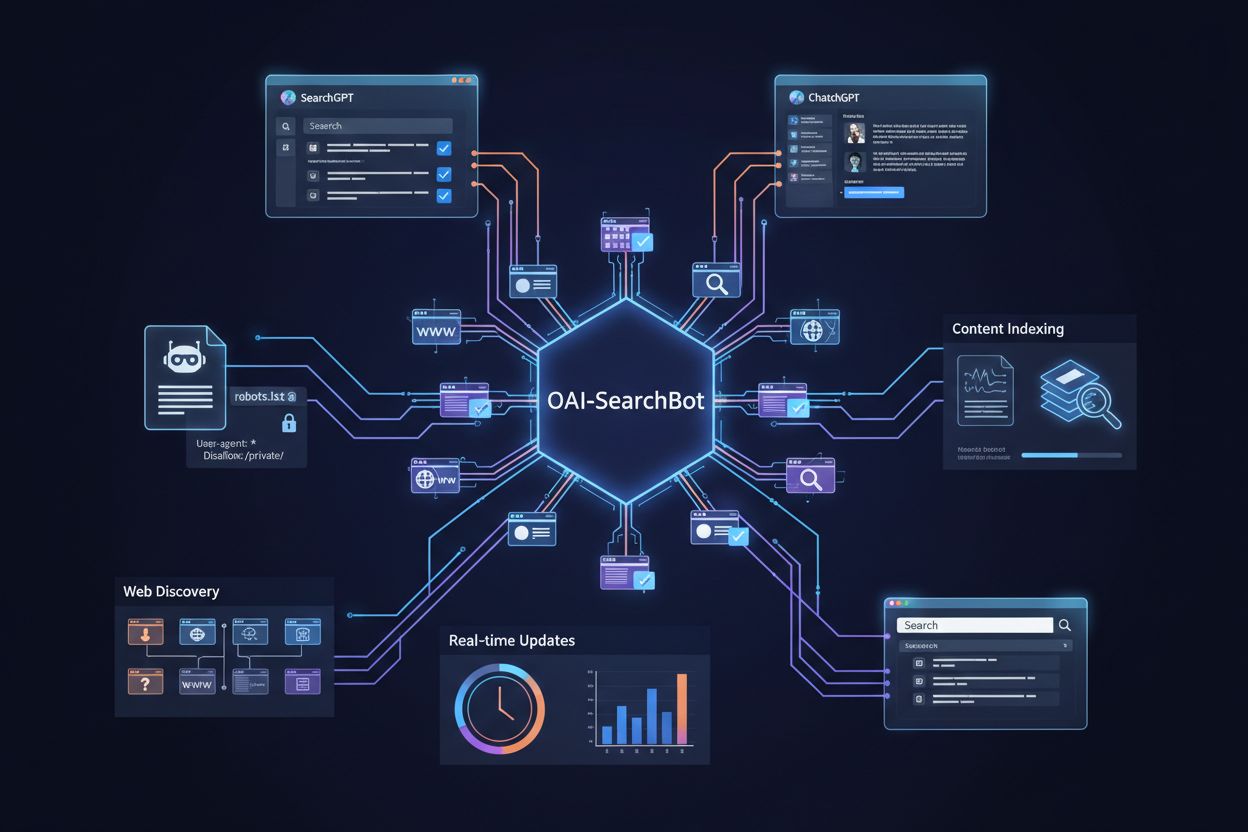
GPTBot je oficiální webový crawler společnosti OpenAI navržený k indexaci veřejně dostupného obsahu z internetu za účelem trénování a vylepšování AI modelů jako ChatGPT a GPT-4. Na rozdíl od univerzálních crawlerů vyhledávačů, jako je Googlebot, má GPTBot specifické poslání: shromažďovat data, která pomáhají OpenAI zdokonalovat jazykové modely a poskytovat uživatelům lepší AI odpovědi. Majitelé webových stránek mohou GPTBot rozpoznat podle charakteristického user agent řetězce (“GPTBot/1.0”), který se objevuje v serverových logách a analytických platformách při přístupu crawleru na jejich stránky. GPTBot respektuje soubor robots.txt, což znamená, že majitelé webu mohou řídit přístup crawleru k obsahu přidáním konkrétních direktiv do tohoto souboru. Crawler indexuje pouze veřejně přístupný obsah a nepokouší se obcházet autentizaci ani přistupovat do chráněných oblastí webu. Pochopení účelu a chování GPTBotu je klíčové pro majitele webových stránek, kteří chtějí informovaně rozhodnout, zda crawler na svůj web pustit nebo jej zablokovat.
Jak GPTBot funguje
GPTBot systematicky prochází webové stránky, analyzuje jejich obsah a odesílá data zpět na servery OpenAI pro zpracování a trénink modelů. Nejprve ověří soubor robots.txt na webu, aby zjistil, které stránky může navštívit, a respektuje direktivy majitelů stránek před jakoukoli indexací. Po identifikaci pomocí svého user agent řetězce stáhne a zpracuje obsah stránky, extrahuje text, metadata a strukturální informace, které přispívají do tréninkových datasetů. Crawler může způsobit značnou zátěž šířky pásma—některé weby hlásí více než 30 TB měsíčního provozu crawlerů napříč všemi boty, ačkoli konkrétní dopad GPTBotu závisí na velikosti a relevanci obsahu webu.
Název crawleru
Účel
Respektuje robots.txt
Dopad na SEO
Využití dat
GPTBot
Trénink AI modelů
Ano
Nepřímý (viditelnost v AI)
Tréninkové datasety
Googlebot
Indexace vyhledávání
Ano
Přímý (pozice v SERPu)
Výsledky vyhledávání
Bingbot
Indexace vyhledávání
Ano
Přímý (pozice v SERPu)
Výsledky vyhledávání
ClaudeBot
Trénink AI modelů
Ano
Nepřímý (viditelnost v AI)
Tréninkové datasety
Majitelé webových stránek mohou sledovat aktivitu GPTBotu v serverových logách hledáním specifického user agent řetězce, což jim umožňuje sledovat frekvenci procházení a případný dopad na výkon. Chování crawleru je navrženo tak, aby bylo šetrné k serverovým zdrojům, ale weby s vysokou návštěvností mohou i tak zaznamenat zvýšenou spotřebu šířky pásma při paralelním běhu více AI crawlerů.
Proč majitelé webů blokují GPTBot
Mnoho majitelů webů blokuje GPTBot z obav z využívání obsahu bez kompenzace, protože OpenAI používá procházený obsah k tréninku komerčních AI modelů, aniž by poskytovala přímý užitek či odměnu tvůrcům obsahu. Významná je také zátěž serveru, zejména pro menší weby nebo ty s omezenou šířkou pásma, protože AI crawleři mohou spotřebovat značné množství zdrojů—některé weby hlásí přes 30 TB měsíčně napříč všemi boty a GPTBot k tomu významně přispívá. Rizika vystavení dat a bezpečnostní hrozby trápí tvůrce obsahu, kteří se obávají, že jejich proprietární informace, obchodní tajemství či citlivá data mohou být nechtěně zařazena do trénovacích datasetů AI, což může ohrozit konkurenční výhody či porušit důvěrnost. Právní prostředí kolem AI trénovacích dat zůstává nejisté, s nevyřešenými otázkami ohledně souladu s GDPR, povinností podle CCPA a porušení autorských práv, což vytváří rizika pro OpenAI i weby, které umožní neomezené procházení. Statistiky ukazují, že přibližně 3,5 % webů aktivně blokuje GPTBot a více než 30 hlavních médií ze 100 největších webů crawler blokuje, včetně The New York Times, CNN, Associated Press a Reuters—což naznačuje, že významní tvůrci obsahu vnímají rizika jako zásadní. Kombinace těchto faktorů činí z blokování GPTBot stále běžnější praxi mezi vydavateli, mediálními společnostmi a weby s velkým objemem obsahu, které chtějí chránit své duševní vlastnictví a udržet kontrolu nad využitím svého obsahu.
Proč majitelé webů povolují GPTBot
Majitelé webů, kteří GPTBot povolují, si uvědomují strategický význam viditelnosti v ChatGPT, protože platforma obsluhuje přibližně 800 milionů uživatelů týdně, kteří pravidelně interagují s AI odpověďmi, v nichž může být jejich obsah citován či shrnut. Když GPTBot projde web, zvyšuje se pravděpodobnost, že obsah bude v ChatGPT citován, shrnut nebo zmíněn, což přináší reprezentaci značky v AI rozhraních a oslovuje uživatele, kteří se stále více obracejí na AI místo tradičních vyhledávačů. Výzkumy ukazují, že AI vyhledávací provoz konvertuje 23x lépe než tradiční organická návštěvnost—uživatelé, kteří nacházejí obsah skrze AI shrnutí a doporučení, mají výrazně vyšší míru zapojení a konverze než běžní návštěvníci z vyhledávačů. Povolení GPTBotu je také formou přípravy na budoucnost, protože AI vyhledávání a objevování obsahu se stává dominantním způsobem, jak lidé nacházejí informace online, a včasná adopce strategie viditelnosti v AI je konkurenční výhodou. Majitelé webů, kteří vsadí na GPTBot, mohou těžit také z Generative Engine Optimization (GEO)—nově vznikající disciplíny zaměřené na optimalizaci obsahu pro AI systémy místo tradičních vyhledávacích algoritmů, což může dlouhodobě výrazně zvýšit návštěvnost. Povolením GPTBotu se progresivní vydavatelé a firmy staví do pozice, kdy mohou získat návštěvnost z rychle rostoucího segmentu uživatelů, kteří se při hledání informací a rozhodování spoléhají na AI nástroje.
Jak zablokovat GPTBot
Blokování GPTBotu je jednoduché a spočívá pouze v úpravě souboru robots.txt na vašem webu (v kořenové složce), který řídí přístup crawlerů na celou doménu. Nejjednodušší je kompletní blokace všech crawlerů OpenAI:
User-agent: GPTBot
Disallow: /
Pokud chcete zablokovat GPTBot pouze v konkrétních adresářích a jinde jej povolit, použijte cílené direktivy:
Kromě úprav robots.txt mohou majitelé webů použít alternativní metody blokace, například blokaci IP adres přes firewall, Web Application Firewall (WAF) filtrování podle user agentu nebo omezení rychlosti, které omezí spotřebu šířky pásma crawlerem. Pro maximální kontrolu některé weby kombinují více přístupů—robots.txt jako hlavní mechanismus a IP blokaci jako doplňkovou ochranu proti crawlerům, které robots.txt ignorují. Po implementaci jakékoli blokace ověřte její účinnost kontrolou serverových logů na výskyt user agent řetězce GPTBot, abyste se ujistili, že crawler už na váš obsah nepřistupuje.
Odvětví, která by měla zvážit blokaci
Některá odvětví čelí zvláštním rizikům spojeným s neomezeným přístupem AI crawlerů a měla by pečlivě zvážit, zda blokace GPTBotu odpovídá jejich obchodním zájmům a strategiím ochrany obsahu:
Vydavatelství & média (noviny, časopisy, tiskové agentury) – Originální žurnalistika je významnou investicí a konkurenční výhodou; média jako The New York Times, Associated Press a Reuters blokují GPTBot pro ochranu exkluzivního obsahu
E-commerce platformy (Amazon, maloobchodní weby) – Popisy produktů, cenové strategie a zákaznické recenze jsou proprietárními obchodními daty, která by mohla konkurence využít při tréninku AI
Platformy s uživatelsky generovaným obsahem (sociální sítě, fóra, recenzní weby) – Obsah vytvářený uživateli může být využit bez souhlasu či odměny, což vyvolává etické i právní otázky
Weby s autoritativními daty (výzkumné instituce, akademické databáze, specializované znalostní portály) – Proprietární výzkum, datasety a odborné znalosti mají vysokou komerční hodnotu a měly by zůstat pod kontrolou tvůrců
Právní a finanční služby – Citlivé klientské informace, právní strategie a finanční poradenství vyžadují přísnou důvěrnost a nelze je vystavit AI datasetům
Zdravotnictví a lékařský obsah – Údaje o pacientech, zdravotní záznamy a klinické informace musí splňovat HIPAA a další předpisy zakazující neautorizované využití dat
Tato odvětví by měla implementovat blokovací strategie pro udržení konkurenčních výhod, ochranu proprietárních informací a zajištění souladu s předpisy o ochraně dat.
Monitoring a detekce
Majitelé webů by měli pravidelně sledovat serverové logy pro identifikaci aktivity GPTBotu a sledování vzorců procházení, což poskytuje přehled o tom, jak AI systémy k jejich obsahu přistupují a případně jej využívají. Identifikace GPTBotu je snadná—crawler se hlásí pomocí user agent řetězce “GPTBot/1.0” v HTTP požadavcích, což jej snadno odliší od ostatních crawlerů v serverových logách a analytických nástrojích. Většina moderních analytických nástrojů a SEO monitorovacích softwarů (včetně Google Analytics, Semrush, Ahrefs a specializovaných platforem pro sledování botů) automaticky kategorizuje a hlásí aktivitu GPTBotu, což majitelům webů umožňuje sledovat frekvenci procházení, spotřebu šířky pásma a navštívené stránky bez nutnosti ruční analýzy logů. Přímá kontrola serverových logů poskytuje detailní informace o požadavcích GPTBotu včetně časových značek, navštívených URL, odpovědních kódů a využití šířky pásma, což umožňuje detailní přehled o chování crawleru. Pravidelný monitoring je zásadní, protože chování crawlerů se může v čase měnit, mohou se objevit nové AI crawleři a účinnost blokování je třeba čas od času ověřovat, aby direktivy plnily svůj účel. Majitelé webů by si měli nastavit výchozí metriky pro běžný provoz crawlerů a zkoumat významné odchylky, které mohou znamenat zvýšenou aktivitu AI crawlerů nebo bezpečnostní problémy vyžadující zásah.
Bezpečnostní standardy OpenAI
OpenAI veřejně deklaruje závazek k odpovědnému vývoji AI a nakládání s daty, včetně jasného prohlášení, že GPTBot respektuje preference majitelů webů vyjádřené v souborech robots.txt a dalších technických direktivách. Společnost zdůrazňuje ochranu dat a odpovědné AI praktiky a uznává, že tvůrci obsahu mají legitimní zájem na kontrole využití svého díla a na odměně, i když aktuální přístup OpenAI neposkytuje přímou kompenzaci za procházený obsah. Ve své dokumentaci OpenAI potvrzuje, že GPTBot respektuje direktivy v robots.txt, což znamená, že firma zabudovala do infrastruktury crawleru mechanizmy pro dodržování těchto pravidel a očekává, že majitelé webů využijí standardní technické prostředky ke kontrole přístupu. Společnost také deklaruje ochotu jednat s vydavateli a tvůrci obsahu ohledně otázek využívání dat, byť formální licenční smlouvy či kompenzační mechanismy jsou zatím omezené. Politika OpenAI se vyvíjí v reakci na právní výzvy, regulační tlak a zpětnou vazbu od oboru, což naznačuje, že budoucí verze GPTBotu mohou obsahovat další ochrany, prvky transparentnosti nebo mechanismy kompenzace. Majitelé webů by měli sledovat oficiální komunikaci a aktualizace politiky OpenAI, aby byli informováni o změnách v přístupu společnosti k procházení obsahu a využívání dat.
GPTBot vs ostatní AI crawleři
OpenAI provozuje tři různé typy crawlerů pro různé účely: GPTBot (obecné procházení webu pro trénink modelů), ChatGPT-User (procházení odkazů sdílených uživateli ChatGPT) a ChatGPT-Plugins (přístup k obsahu přes plugin integrace)—každý s vlastním user agent řetězcem a vzorcem přístupu. Kromě crawlerů OpenAI existuje v AI ekosystému řada dalších crawlerů provozovaných konkurencí: Google-Extended (AI crawler Google pro trénink), CCBot (Commoncrawl), Perplexity (AI vyhledávač), Claude (AI model společnosti Anthropic) a nové crawleři dalších AI firem, každý s odlišným účelem a využitím dat. Majitelé webů stojí před strategickou volbou mezi selektivní blokací (zaměření na konkrétní crawlery jako GPTBot, zatímco ostatní povolí) a komplexní blokací (omezení všech AI crawlerů pro úplnou kontrolu nad využitím obsahu). Rozmnožení AI crawlerů znamená, že samotné blokování GPTBotu nemusí zcela ochránit obsah před AI tréninkem, protože jiné crawlery mohou i nadále přistupovat ke stejnému materiálu jinými způsoby. Někteří majitelé webů volí vícestupňové strategie, kdy blokují nejagresivnější nebo komerčně nejvýznamnější crawlery a zároveň povolují menší nebo výzkumně zaměřené crawlery. Pochopení rozdílů mezi jednotlivými crawlery pomáhá majitelům webů rozhodnout, které blokovat na základě konkrétních obav o využití dat, dopad na konkurenci a obchodní cíle.
Dopad na SEO a viditelnost vyhledávání
Vliv ChatGPT na vyhledávací chování mění způsob, jakým uživatelé objevují informace—800 milionů uživatelů týdně se stále více obrací k AI nástrojům místo tradičních vyhledávačů, což zásadně mění konkurenční prostředí pro viditelnost obsahu. AI generovaná shrnutí a zvýrazněné úryvky v odpovědích ChatGPT nyní slouží jako alternativní kanály objevování, takže obsah, který je dobře hodnocen v tradičních výsledcích vyhledávače, může být přehlížen, pokud není vybrán pro AI generované odpovědi. Generative Engine Optimization (GEO) se stala klíčovou disciplinou pro progresivní tvůrce obsahu, zaměřující se na strukturu, srozumitelnost a autoritu obsahu s cílem zvýšit šanci na zařazení do AI generovaných odpovědí a shrnutí. Dlouhodobé dopady na viditelnost jsou zásadní: weby, které GPTBot blokují, mohou ztratit příležitost objevit se v odpovědích ChatGPT, což může snížit návštěvnost z rychle rostoucího segmentu AI vyhledávání, zatímco ty, které přístup povolí, se strategicky staví do pozice pro AI řízené objevování. Výzkumy ukazují, že 86,5 % obsahu v top 20 výsledcích Google obsahuje částečně AI generované prvky, což dokládá, že AI integrace je v prostředí vyhledávání standardem, nikoliv okrajovou záležitostí. Konkurenční pozice je čím dál více závislá na viditelnosti jak v tradičních vyhledávačích, tak v AI systémech, což činí strategická rozhodnutí ohledně přístupu GPTBotu klíčová pro dlouhodobý SEO úspěch a růst organické návštěvnosti. Majitelé webů musí vyvážit ochranu obsahu s rizikem ztráty viditelnosti v AI systémech, které se stávají hlavním kanálem objevování pro miliony uživatelů po celém světě.
Často kladené otázky
Co je GPTBot a jak se liší od Googlebotu?
GPTBot je oficiální webový crawler OpenAI určený ke shromažďování tréninkových dat pro AI modely jako ChatGPT a GPT-4. Na rozdíl od Googlebotu, který indexuje obsah pro výsledky vyhledávače, GPTBot sbírá data specificky pro zlepšení jazykových modelů. Oba crawleři respektují direktivy robots.txt a přistupují pouze k veřejně dostupnému obsahu, ale jejich účel v digitálním ekosystému je zásadně odlišný.
Mám GPTBot na svém webu zablokovat?
Rozhodnutí závisí na vašich obchodních cílech a obsahové strategii. Blokujte GPTBot, pokud máte proprietární obsah, působíte v regulovaných odvětvích nebo máte obavy o duševní vlastnictví. Povolit GPTBot má smysl, pokud chcete být viditelní v ChatGPT (800 milionů uživatelů týdně), těžit z AI vyhledávacího provozu (konvertuje 23x lépe než organické), nebo chcete být připraveni na budoucnost, kde bude AI vyhledávání dominantní.
Jak zablokuji GPTBot pomocí robots.txt?
Přidejte tyto řádky do svého robots.txt souboru pro blokaci GPTBot na celém webu: User-agent: GPTBot / Disallow: /. Pro blokaci konkrétních adresářů nahraďte lomítko cestou k adresáři. Pro zablokování všech crawlerů OpenAI přidejte samostatné položky User-agent pro GPTBot, ChatGPT-User a ChatGPT-Plugins. Změny se projeví ihned a lze je snadno vrátit zpět.
Jaký je dopad GPTBotu na můj server a šířku pásma?
Dopad GPTBotu závisí na velikosti vašeho webu a relevanci obsahu. I když je dopad jednotlivého crawleru většinou zvládnutelný, více AI crawlerů najednou může spotřebovávat značnou šířku pásma—některé weby hlásí přes 30 TB crawler provozu měsíčně napříč všemi boty. Sledujte své serverové logy, abyste mohli sledovat aktivitu GPTBotu, a zvažte omezení rychlosti nebo blokaci IP, pokud spotřeba šířky pásma začne být problémem.
Mohu GPTBot zablokovat jen na některých stránkách?
Ano, můžete použít cílené direktivy v robots.txt k blokaci GPTBotu v konkrétních adresářích nebo na stránkách, zatímco ostatní ponecháte přístupné. Například můžete zakázat přístup do adresářů /private/ a /admin/ a zároveň povolit zbytek webu. Tento selektivní přístup vám umožní chránit citlivý obsah a přitom zachovat viditelnost veřejných stránek v AI systémech.
Jak poznám, že GPTBot navštěvuje můj web?
Zkontrolujte své serverové logy a hledejte user agent řetězec 'GPTBot/1.0' v HTTP požadavcích. Většina analytických platforem (Google Analytics, Semrush, Ahrefs) automaticky kategorizuje a hlásí aktivitu GPTBotu. Můžete také využít SEO nástroje, které sledují aktivitu AI crawlerů. Pravidelné sledování vám pomůže pochopit frekvenci procházení a případné dopady na výkon.
Jaké jsou právní důsledky blokace nebo povolení GPTBotu?
Právní prostředí se stále vyvíjí. Povolení GPTBotu vyvolává otázky ohledně souladu s GDPR, povinnostmi podle CCPA a porušení autorských práv, ačkoli OpenAI tvrdí, že respektuje direktivy robots.txt. Blokace GPTBotu je právně přímočará, ale může omezit vaši viditelnost v AI systémech. Pokud působíte v regulovaných odvětvích nebo zpracováváte citlivá data, konzultujte postup s právníkem.
Jak povolení GPTBotu ovlivní můj SEO a viditelnost vyhledávání?
Povolení GPTBotu přímo neovlivňuje tradiční hodnocení v Google, ale zvyšuje vaši viditelnost v odpovědích ChatGPT a dalších AI vyhledávačích. S 800 miliony uživatelů ChatGPT a AI vyhledávacím provozem, který konvertuje 23x lépe než organický, vám povolení GPTBotu zajistí dlouhodobou viditelnost v AI systémech. Blokace GPTBotu může snížit šanci být zahrnut v AI generovaných odpovědích a tím omezit návštěvnost z nejrychleji rostoucího segmentu vyhledávání.
Sledujte svou značku ve výsledcích AI vyhledávání
Zjistěte, jak se vaše značka zobrazuje v ChatGPT, Perplexity, Google AI a dalších AI platformách. Získejte okamžité přehledy o citacích a viditelnosti v AI s AmICited.
Co je GPTBot a Měli Byste Ho Povolit? Kompletní Průvodce pro Majitele Webů
Zjistěte, co je GPTBot, jak funguje a zda byste měli povolit nebo zablokovat webového crawlera OpenAI. Pochopte dopad na viditelnost vaší značky ve vyhledávání ...
GPTBot vs OAI-SearchBot: Porozumění různým crawlerům OpenAI
Poznejte hlavní rozdíly mezi crawlery GPTBot a OAI-SearchBot. Zjistěte jejich účel, chování při procházení a jak je spravovat pro optimální viditelnost vašeho o...
Zjistěte, co je OAI-SearchBot, jak funguje a jak optimalizovat svůj web pro specializovaný vyhledávací crawler od OpenAI využívaný SearchGPT a ChatGPT.
6 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.