
Pokrytí indexu AI
Zjistěte, co je pokrytí indexu AI a proč je důležité pro viditelnost vaší značky v ChatGPT, Google AI Overviews a Perplexity. Objevte technické faktory, osvědče...
7 min čtení

Pokrytí indexu označuje procento a stav stránek webu, které byly objeveny, procházeny a zahrnuty do indexu vyhledávače. Měří, které stránky se mohou zobrazit ve výsledcích vyhledávání, a identifikuje technické problémy bránící indexaci.
Pokrytí indexu označuje procento a stav stránek webu, které byly objeveny, procházeny a zahrnuty do indexu vyhledávače. Měří, které stránky se mohou zobrazit ve výsledcích vyhledávání, a identifikuje technické problémy bránící indexaci.
Pokrytí indexu je měřítkem toho, kolik stránek vašeho webu bylo objeveno, procházeno a zahrnuto do indexu vyhledávače. Udává procento stránek vašeho webu, které se mohou zobrazit ve výsledcích vyhledávání, a identifikuje stránky, na nichž se vyskytly technické problémy bránící indexaci. Ve své podstatě pokrytí indexu odpovídá na zásadní otázku: “Jak velkou část mého webu mohou vyhledávače skutečně najít a hodnotit?” Tento údaj je základní pro pochopení viditelnosti vašeho webu ve vyhledávačích a sleduje se pomocí nástrojů jako Google Search Console, která poskytuje detailní reporty o indexovaných stránkách, vyloučených stránkách a stránkách s chybami. Bez správného pokrytí indexu zůstává i nejlépe optimalizovaný obsah neviditelný jak pro vyhledávače, tak pro uživatele hledající vaše informace.
Pokrytí indexu není jen otázkou kvantity—jde o to, aby byly indexovány správné stránky. Web může mít tisíce stránek, ale pokud je mnoho z nich duplicitních, s nekvalitním obsahem nebo blokovaných souborem robots.txt, skutečné pokrytí indexu může být výrazně nižší, než by se čekalo. Tento rozdíl mezi celkovým počtem stránek a počtem indexovaných stránek je zásadní pro tvorbu efektivní SEO strategie. Organizace, které pravidelně sledují pokrytí indexu, mohou identifikovat a odstranit technické problémy dříve, než ovlivní organickou návštěvnost, což z pokrytí indexu dělá jeden z nejpraktičtějších technických SEO ukazatelů.
Koncept pokrytí indexu se objevil s tím, jak se vyhledávače vyvinuly z jednoduchých crawlerů v sofistikované systémy schopné zpracovávat miliony stránek denně. V počátcích SEO měli správci webů jen omezený přehled o tom, jak vyhledávače komunikují s jejich weby. Google Search Console, původně spuštěná jako Google Webmaster Tools v roce 2006, tuto transparentnost revolučně změnila tím, že nabídla přímou zpětnou vazbu o stavu procházení a indexace. Report pokrytí indexu (dříve označovaný jako “Stránky v indexu”) se stal hlavním nástrojem pro zjišťování, které stránky Google zaindexoval a proč byly jiné vyloučeny.
S rostoucí složitostí webů, dynamickým obsahem, parametry a duplicitními stránkami se problémy s pokrytím indexu staly běžnějšími. Výzkumy ukazují, že přibližně 40–60 % webů má významné problémy s pokrytím indexu, přičemž mnoho stránek zůstává neobjeveno nebo je záměrně vyloučeno z indexu. Nástup webů s intenzivním využitím JavaScriptu a jednostránkových aplikací (SPA) indexaci dále zkomplikoval, protože vyhledávače musí nejprve vykreslit obsah, aby mohly posoudit možnost indexace. Dnes je sledování pokrytí indexu považováno za nezbytné pro každou organizaci spoléhající na organickou návštěvnost, přičemž odborníci doporučují alespoň měsíční audity.
Souvislost mezi pokrytím indexu a crawl budgetem je stále důležitější s růstem webů. Crawl budget znamená počet stránek, které Googlebot projde na vašem webu během určitého časového období. Velké weby se špatnou architekturou nebo nadměrným množstvím duplicitního obsahu mohou plýtvat crawl budgetem na málo hodnotné stránky, zatímco důležitý obsah zůstává neobjeven. Studie ukazují, že více než 78 % podniků používá nějaký nástroj pro monitoring obsahu, aby sledovaly svou viditelnost ve vyhledávačích a AI platformách, přičemž pokrytí indexu je základním kamenem každé strategie viditelnosti.
| Pojem | Definice | Primární řízení | Používané nástroje | Dopad na hodnocení |
|---|---|---|---|---|
| Pokrytí indexu | Procento stránek indexovaných vyhledávači | Meta tagy, robots.txt, kvalita obsahu | Google Search Console, Bing Webmaster Tools | Přímý—jen indexované stránky mohou být hodnoceny |
| Procházení (Crawlability) | Schopnost robotů přistupovat a procházet stránky | robots.txt, struktura webu, interní odkazy | Screaming Frog, ZentroAudit, serverové logy | Nepřímý—stránky musí být procházené, aby byly indexované |
| Indexovatelnost (Indexability) | Schopnost procházených stránek být přidány do indexu | Noindex direktivy, kanonické tagy, obsah | Google Search Console, Nástroj pro kontrolu URL | Přímý—určuje, zda se stránky zobrazí ve výsledcích |
| Crawl budget | Počet stránek, které Googlebot projde v čase | Autorita webu, kvalita stránek, chyby procházení | Google Search Console, serverové logy | Nepřímý—ovlivňuje, které stránky budou procházeny |
| Duplicitní obsah | Více stránek s totožným nebo podobným obsahem | Kanonické tagy, 301 přesměrování, noindex | SEO auditní nástroje, manuální kontrola | Negativní—oslabuje potenciál pro hodnocení |
Pokrytí indexu probíhá ve třech fázích: objevení, procházení a indexace. Ve fázi objevení vyhledávače nacházejí URL různými způsoby včetně XML sitemapy, interních odkazů, externích zpětných odkazů a přímých odeslání přes Google Search Console. Po objevení jsou URL zařazeny do fronty procházení, kde Googlebot stránku načte a analyzuje její obsah. Nakonec při indexaci Google zpracuje obsah stránky, posoudí jeho relevanci a kvalitu a rozhodne, zda ji zahrne do vyhledávacího indexu.
Report pokrytí indexu v Google Search Console rozděluje stránky do čtyř hlavních stavů: Platné (indexované stránky), Platné s upozorněními (indexované, ale s problémy), Vyloučené (záměrně neindexované) a Chyba (stránky, které nelze indexovat). Každý stav obsahuje konkrétní typy problémů, které poskytují detailní pohled na to, proč jsou stránky indexovány či ne. Například stránky mohou být vyloučeny kvůli noindex meta tagu, blokaci souborem robots.txt, duplicitě bez správných kanonických tagů nebo vracením HTTP kódů 4xx či 5xx.
Porozumět technickým principům pokrytí indexu znamená znát několik klíčových prvků. Soubor robots.txt je textový soubor v kořenovém adresáři webu, který instruuje roboty vyhledávačů, které složky a soubory mohou či nemohou navštěvovat. Chybná konfigurace robots.txt patří mezi nejčastější příčiny problémů s pokrytím indexu—nechtěné blokování důležitých složek znemožní Googlu jejich objevení. Meta tag robots v hlavičce HTML stránky poskytuje stránkově specifické instrukce pomocí direktiv jako index, noindex, follow, nofollow. Kanonický tag (rel=“canonical”) říká vyhledávačům, která verze stránky je preferovaná v případě duplicit, čímž zabraňuje přebytku indexovaných stránek a sjednocuje signály pro hodnocení.
Pro firmy závislé na organické návštěvnosti má pokrytí indexu přímý dopad na příjmy a viditelnost. Pokud důležité stránky nejsou indexované, nemohou se zobrazit ve vyhledávání, což znamená, že je potenciální zákazníci přes Google nenajdou. E-shopy s nízkým pokrytím indexu mohou mít produktové stránky uvízlé ve stavu “Zjištěno – zatím neindexováno”, což vede ke ztrátě prodejů. Content marketingové platformy s tisíci články potřebují robustní pokrytí indexu, aby jejich obsah dosáhl k publiku. SaaS společnosti se spoléhají na indexovanou dokumentaci a blogové příspěvky pro získání organických leadů.
Praktické dopady přesahují tradiční vyhledávání. S nástupem generativních AI platforem jako ChatGPT, Perplexity a Google AI Overviews se pokrytí indexu stalo důležité i pro viditelnost v AI. Tyto systémy často využívají indexovaný webový obsah jako trénovací data a zdroje citací. Pokud vaše stránky nejsou správně indexovány Googlem, je menší pravděpodobnost, že budou zahrnuty do AI trénovacích datasetů nebo citovány v odpovědích generovaných AI. Vzniká tak kumulativní problém s viditelností: špatné pokrytí indexu ovlivňuje tradiční pozice ve vyhledávačích i viditelnost v AI obsahu.
Organizace, které pokrytí indexu aktivně sledují, zaznamenávají měřitelné zlepšení organické návštěvnosti. Typickým scénářem je zjištění, že 30–40 % odeslaných URL je vyloučeno kvůli noindex tagům, duplicitnímu obsahu nebo chybám procházení. Po odstranění problémů—odstranění zbytečných noindex tagů, implementaci správné kanonizace a opravě chyb procházení—se počet indexovaných stránek často zvýší o 20–50 %, což přímo souvisí s lepší organickou viditelností. Cena nečinnosti je značná: každý měsíc, kdy stránka není indexována, je měsícem ztracené potenciální návštěvnosti a konverzí.
Google Search Console zůstává hlavním nástrojem pro sledování pokrytí indexu a poskytuje nejautoritativnější data o rozhodnutích Google ohledně indexace. Report pokrytí indexu zobrazuje indexované stránky, stránky s varováními, vyloučené stránky a stránky s chybami s detailním rozpisem typů problémů. Google také nabízí Nástroj pro kontrolu URL, který umožňuje zkontrolovat stav indexace jednotlivých stránek a požádat o indexaci nového nebo aktualizovaného obsahu. Tento nástroj je neocenitelný při řešení konkrétních stránek a pochopení, proč Google stránku nezaindexoval.
Bing Webmaster Tools nabízí podobnou funkcionalitu prostřednictvím Index Exploreru a odesílání URL. Přestože podíl Bingu na trhu je menší než u Google, stále je důležitý pro oslovování uživatelů, kteří preferují jeho vyhledávání. Data o pokrytí indexu v Bingu se někdy liší od Google a odhalují problémy specifické pro crawling nebo indexační algoritmy Bingu. Organizace spravující velké weby by měly sledovat obě platformy pro zajištění komplexního pokrytí.
Pro AI monitoring a viditelnost značky platformy jako AmICited sledují, jak se vaše značka a doména zobrazují v ChatGPT, Perplexity, Google AI Overviews a Claude. Tyto platformy propojují tradiční pokrytí indexu s AI viditelností a pomáhají organizacím chápat, jak se jejich indexovaný obsah promítá do zmínek v AI odpovědích. Tato integrace je klíčová pro moderní SEO strategii, protože viditelnost v AI systémech stále více ovlivňuje povědomí o značce a návštěvnost.
Třetí strany, například SEO auditní nástroje Ahrefs, SEMrush a Screaming Frog, poskytují další pohledy na pokrytí indexu tím, že web samy procházejí a porovnávají svá zjištění s reporty Google. Rozdíly mezi vaším crawl reportem a daty Google mohou odhalit problémy jako renderování JavaScriptu, serverové chyby nebo omezený crawl budget. Tyto nástroje také identifikují tzv. sirotčí stránky (bez interních odkazů), které často mají problém s indexací.
Zlepšení pokrytí indexu vyžaduje systematický přístup k technickým i strategickým otázkám. Nejprve proveďte audit současného stavu pomocí reportu pokrytí indexu v Google Search Console. Identifikujte hlavní typy problémů ovlivňujících váš web—zda jde o noindex tagy, blokaci robots.txt, duplicitní obsah nebo chyby procházení. Určete priority podle dopadu: stránky, které by měly být indexovány, ale nejsou, mají přednost před stránkami, které jsou správně vyloučené.
Druhým krokem je oprava špatné konfigurace robots.txt zkontrolujte tento soubor a ujistěte se, že neblokujete důležité složky. Častou chybou je blokování adresářů jako /admin/, /staging/ nebo /temp/, které mají být blokovány, ale zároveň nechtěně blokování veřejného obsahu typu /blog/, /products/ apod. Použijte tester robots.txt v Google Search Console a ověřte, že důležité stránky nejsou blokovány.
Třetím krokem je správná kanonizace duplicitního obsahu. Pokud máte více URL se stejným nebo velmi podobným obsahem (např. produktové stránky dostupné přes různé kategorie), implementujte samo-odkazující kanonické tagy na každé stránce nebo použijte 301 přesměrování ke sloučení na jednu verzi. Tím zabráníte nadměrné indexaci a sjednotíte signály pro hodnocení na preferované verzi.
Čtvrtým krokem je odstranění zbytečných noindex tagů ze stránek, které mají být indexovány. Proveďte audit webu na direktivy noindex, zejména na testovacích prostředích, která mohla být omylem nasazena do produkce. Pomocí Nástroje pro kontrolu URL ověřte, že důležité stránky nemají noindex tagy.
Pátým krokem je odeslání XML sitemap do Google Search Console obsahující pouze indexovatelné URL. Udržujte sitemapu čistou tím, že vyloučíte stránky s noindex tagy, přesměrováními nebo chybami 404. U velkých webů rozdělte sitemapy podle typů obsahu nebo sekcí pro lepší organizaci a detailnější reportování chyb.
Šestým krokem je oprava chyb procházení jako jsou nefunkční odkazy (404), chyby serveru (5xx) a řetězce přesměrování. V Google Search Console identifikujte postižené stránky a systematicky řešte každý problém. U důležitých stránek s chybou 404 buď obnovte obsah, nebo nastavte 301 přesměrování na relevantní alternativu.
Budoucnost pokrytí indexu se vyvíjí spolu se změnami ve vyhledávacích technologiích a rozvojem generativních AI systémů. S tím, jak Google stále zpřísňuje požadavky Core Web Vitals a standardy E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), bude pokrytí indexu čím dál více záviset na kvalitě obsahu a uživatelských metrikách. Stránky se špatnými Core Web Vitals nebo nekvalitním obsahem mohou mít problémy s indexací, i když jsou technicky procházené.
Nástup AI generovaných výsledků vyhledávání a odpovědních enginů mění význam pokrytí indexu. Tradiční pozice ve vyhledávačích závisí na indexovaných stránkách, ale AI systémy mohou citovat indexovaný obsah odlišně nebo upřednostňovat určité zdroje. Organizace tak budou muset sledovat nejen to, zda jsou jejich stránky indexovány Googlem, ale také zda jsou citovány a zmiňovány AI platformami. Tato požadovaná dvojí viditelnost znamená, že monitoring pokrytí indexu musí rozšířit záběr za hranice Google Search Console a zahrnout AI monitoringové platformy, které sledují zmínky značky napříč ChatGPT, Perplexity a dalšími generativními AI systémy.
Renderování JavaScriptu a dynamický obsah budou nadále komplikovat pokrytí indexu. S tím, jak stále více webů využívá JavaScriptové frameworky a jednostránkové aplikace, musí vyhledávače obsah nejprve vykreslit, aby mu porozuměly. Google sice zlepšil schopnosti vykreslování JavaScriptu, ale problémy stále přetrvávají. Budoucí osvědčené postupy proto budou klást důraz na server-side rendering nebo dynamické renderování, aby byl obsah okamžitě přístupný crawlerům bez nutnosti spouštění JavaScriptu.
Integrace strukturovaných dat a schema markup bude pro pokrytí indexu stále důležitější. Vyhledávače využívají strukturovaná data pro lepší pochopení obsahu a kontextu stránky, což může zlepšit rozhodování o indexaci. Organizace, které implementují komplexní schema markup pro své typy obsahu—články, produkty, události, FAQ—mohou dosáhnout lepšího pokrytí indexu a větší viditelnosti v rozšířených výsledcích.
Nakonec se koncept pokrytí indexu rozšíří z úrovně stránek na úroveň entit a témat. Namísto pouhého sledování, zda jsou stránky indexovány, se bude monitoring zaměřovat na to, zda jsou vaše značka, produkty a témata správně reprezentovány v znalostních grafech vyhledávačů a trénovacích datech AI. To představuje zásadní posun od sledování indexace na úrovni stránky k viditelnosti na úrovni entity, což si vyžádá nové přístupy i strategie monitoringu.
+++
Procházení znamená, zda mohou roboti vyhledávačů přistupovat a procházet stránky vašeho webu, což je řízeno například robots.txt a strukturou webu. Indexovatelnost pak určuje, zda budou procházené stránky skutečně přidány do indexu vyhledávače, což ovlivňují meta tagy robots, kanonické tagy a kvalita obsahu. Stránka musí být procházená, aby mohla být indexována, ale samotné procházení nezaručuje indexaci.
Většině webů stačí kontrolovat pokrytí indexu jednou měsíčně, aby zachytily hlavní problémy. Pokud však zásadně měníte strukturu webu, často publikujete nový obsah nebo provádíte migrace, sledujte report týdně nebo jednou za dva týdny. Google sice posílá e-mailová upozornění na závažné problémy, ta ale bývají opožděná, proto je proaktivní monitoring zásadní pro udržení optimální viditelnosti.
Tento stav znamená, že Google našel URL (obvykle přes sitemapu nebo interní odkazy), ale zatím ji neprocházel. Může to být způsobeno limity crawl budgetu, kdy Google upřednostňuje jiné stránky vašeho webu. Pokud důležité stránky zůstávají v tomto stavu delší dobu, může to signalizovat problémy s crawl budgetem nebo nízkou autoritou webu, které je třeba řešit.
Ano, odeslání XML sitemap do Google Search Console pomáhá vyhledávačům objevit a upřednostnit vaše stránky k procházení a indexaci. Dobře spravovaná sitemap obsahující pouze indexovatelné URL může významně zlepšit pokrytí indexu tím, že nasměruje crawl budget Google na nejdůležitější obsah a zkrátí čas potřebný k objevení stránek.
Mezi běžné problémy patří stránky blokované souborem robots.txt, meta tagy noindex na důležitých stránkách, duplicitní obsah bez správné kanonizace, chyby serveru (5xx), řetězce přesměrování a nekvalitní (thin) obsah. Dále se v reportech často objevují chyby 404, soft 404 a stránky s požadavkem na autorizaci (chyby 401/403), které je třeba řešit pro lepší viditelnost.
Pokrytí indexu přímo ovlivňuje, zda se váš obsah objeví v odpovědích generovaných AI platformami jako ChatGPT, Perplexity a Google AI Overviews. Pokud vaše stránky nejsou správně indexovány Googlem, je menší pravděpodobnost, že budou zahrnuty do trénovacích dat nebo citovány AI systémy. Monitorování pokrytí indexu zajišťuje, že je obsah vaší značky dohledatelný a citovatelný jak v tradičním vyhledávání, tak v generativních AI platformách.
Crawl budget je počet stránek, které Googlebot projde na vašem webu během určitého časového období. Weby s neefektivním využitím crawl budgetu mohou mít mnoho stránek ve stavu 'Zjištěno – zatím neindexováno'. Optimalizací crawl budgetu opravením chyb procházení, odstraněním duplicitních URL a strategickým využitím robots.txt zajistíte, že Google se zaměří na indexaci vašeho nejhodnotnějšího obsahu.
Ne, ne všechny stránky by měly být indexovány. Stránky jako testovací prostředí, duplicitní varianty produktů, interní výsledky vyhledávání a archivy zásad ochrany osobních údajů je vhodnější z indexu vyloučit pomocí tagů noindex nebo robots.txt. Cílem je indexovat jen hodnotný, unikátní obsah, který odpovídá záměru uživatele a přispívá k celkovému SEO výkonu vašeho webu.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte, co je pokrytí indexu AI a proč je důležité pro viditelnost vaší značky v ChatGPT, Google AI Overviews a Perplexity. Objevte technické faktory, osvědče...

Indexovatelnost je schopnost vyhledávačů zahrnout stránky do svého indexu. Zjistěte, jak crawlabilita, technické faktory a kvalita obsahu ovlivňují, zda se vaše...
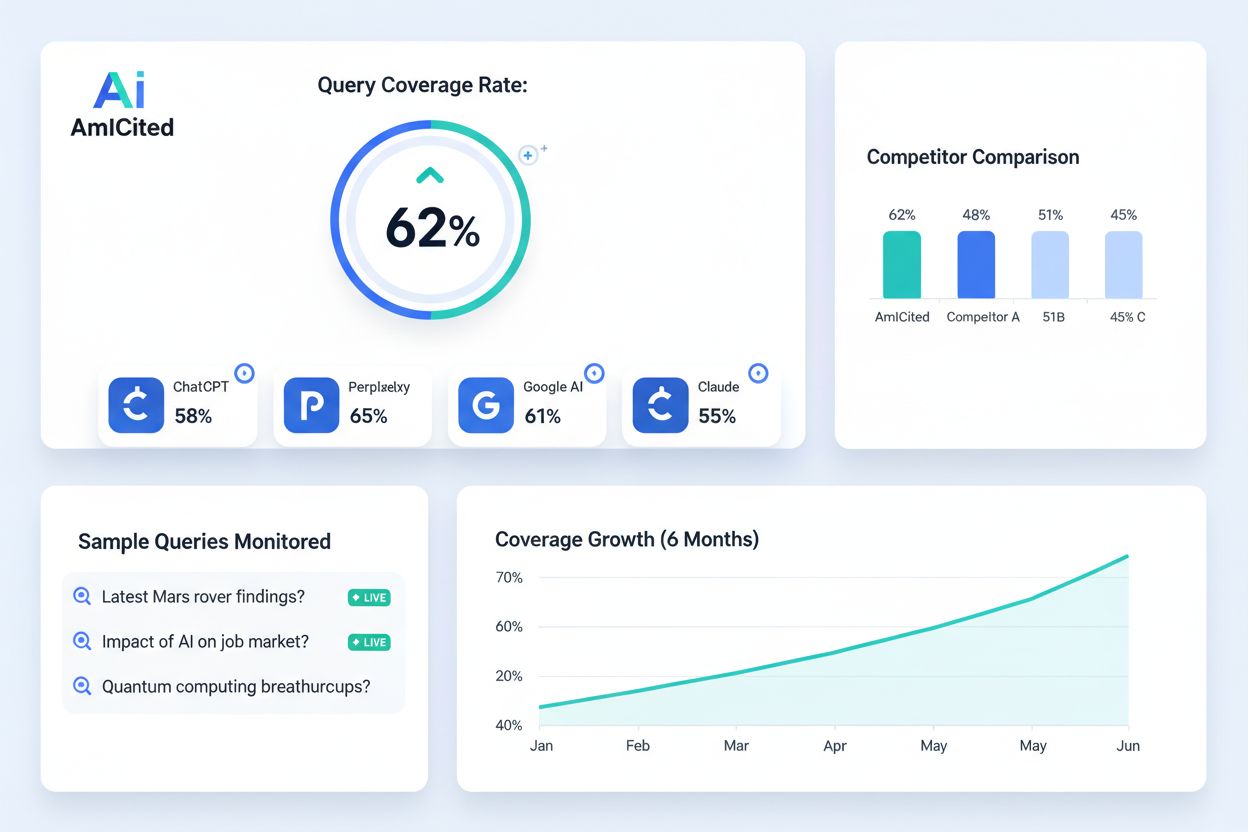
Zjistěte, co je Míra pokrytí dotazů, jak ji měřit a proč je klíčová pro viditelnost značky ve vyhledávání poháněném AI. Objevte benchmarky, optimalizační strate...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.