
JSON-LD: Kompletní průvodce implementací a SEO výhodami
Zjistěte, co je JSON-LD a jak jej implementovat pro SEO. Objevte výhody strukturovaných dat pro Google, ChatGPT, Perplexity a viditelnost ve vyhledávání pomocí ...
14 min čtení
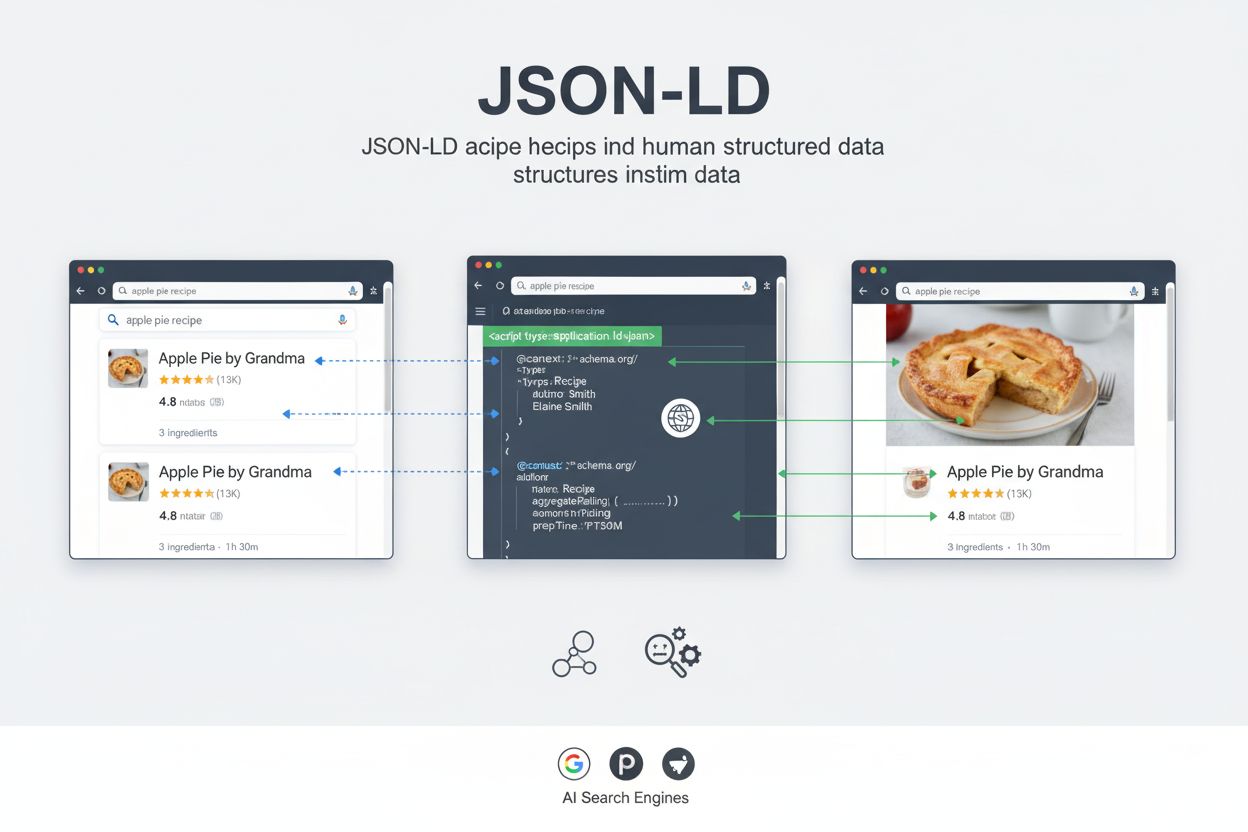
JSON-LD (JavaScript Object Notation for Linked Data) je lehký, W3C-standardizovaný formát pro vyjádření strukturovaných dat pomocí syntaxe JSON, který umožňuje vyhledávačům a AI systémům porozumět obsahu webu prostřednictvím slovníku schema.org. Je vkládán do webových stránek jako strojově čitelný zápis, který pomáhá vyhledávačům zobrazovat bohaté výsledky a zlepšuje dohledatelnost obsahu napříč AI platformami.
JSON-LD (JavaScript Object Notation for Linked Data) je lehký, W3C-standardizovaný formát pro vyjádření strukturovaných dat pomocí syntaxe JSON, který umožňuje vyhledávačům a AI systémům porozumět obsahu webu prostřednictvím slovníku schema.org. Je vkládán do webových stránek jako strojově čitelný zápis, který pomáhá vyhledávačům zobrazovat bohaté výsledky a zlepšuje dohledatelnost obsahu napříč AI platformami.
JSON-LD znamená JavaScript Object Notation for Linked Data a představuje lehký, standardizovaný formát pro vyjádření strukturovaných dat na webových stránkách. Jako doporučení W3C existuje od ledna 2014 a JSON-LD kombinuje jednoduchost syntaxe JSON se sémantickou silou slovníků propojených dat, zejména schema.org. Na rozdíl od jiných formátů strukturovaných dat, které prokládají zápis do HTML obsahu, je JSON-LD vkládán jako samostatný <script> tag v hlavičce nebo těle stránky, čímž odděluje data od prezentačního kódu. Toto oddělení činí JSON-LD mimořádně snadným pro implementaci, údržbu a škálování na velkých webech i v redakčních systémech.
Hlavním účelem JSON-LD je poskytnout strojově čitelný kontext, který pomáhá vyhledávačům, AI systémům a dalším webovým aplikacím porozumět významu a vztahům v obsahu webové stránky. Správně implementovaný JSON-LD umožňuje vyhledávačům zobrazovat bohaté výsledky – rozšířené výpisy ve vyhledávání, které obsahují hodnocení, ceny, obrázky, detaily událostí a další strukturované informace. Pro AI vyhledávací platformy jako ChatGPT, Perplexity, Google AI Overviews a Claude představuje JSON-LD zásadní most mezi lidsky čitelným obsahem a strojově interpretovatelnými daty, čímž zvyšuje přesnost a relevanci AI generovaných odpovědí a citací.
JSON-LD se stal doporučeným formátem strukturovaných dat od Google i dalších hlavních vyhledávačů, protože minimalizuje chyby při implementaci a bez problémů funguje s moderními webovými technologiemi včetně JavaScriptových frameworků a dynamického generování obsahu. Flexibilita formátu umožňuje vyjádření komplexních vnořených datových struktur, takže je vhodný pro různé typy obsahu – od jednoduchých informací o produktech až po složité organizační hierarchie a události.
JSON-LD vznikl z potřeby propojit tradiční formáty JSON s normami sémantického webu. Před JSON-LD vývojáři propojených dat obvykle používali RDF/XML nebo Turtle formáty, které byly sice výkonné, ale složité a ne zcela přirozené pro běžnou webovou vývojářskou praxi. Vývoj JSON-LD začal na počátku 10. let 21. století v rámci W3C JSON-LD Community Group, kdy JSON již byl de facto standardem pro webová API a výměnu dat. Formát byl oficiálně standardizován W3C v roce 2014, následně došlo k dalším úpravám a JSON-LD 1.1 se stal plným doporučením W3C v roce 2020.
Adopce JSON-LD se zásadně zrychlila poté, co jej Google a další hlavní vyhledávače začaly doporučovat jako preferovaný formát pro zápis schema.org v roce 2013. Toto doporučení bylo klíčové, protože vývojářské komunitě ukázalo, že JSON-LD není jen akademickým experimentem, ale praktickým, produkčně připraveným řešením pro reálné SEO a problémy s dohledatelností obsahu. Za poslední dekádu používání JSON-LD exponenciálně vzrostlo – aktuální data ukazují, že 41 % všech webových stránek nyní používá JSON-LD pro strukturovaná data, oproti 34 % v roce 2022. Mezi weby se strukturovanými daty je JSON-LD použitý přibližně na 70 % z nich, což z něj činí dominantní formát v této oblasti.
Vývoj JSON-LD ovlivnil i vzestup AI vyhledávačů a velkých jazykových modelů. Jak se platformy jako ChatGPT, Perplexity a Google AI Overviews staly běžnou součástí webu, význam JSON-LD vzrostl, protože tyto systémy silně spoléhají na strukturovaná data pro přesnou a kontextovou extrakci informací z webových stránek. Schopnost formátu jasně definovat typy entit, vztahy a vlastnosti je neocenitelná pro trénování i provoz AI systémů, které potřebují porozumět webovému obsahu ve velkém měřítku.
JSON-LD dokumenty využívají standardní syntaxi JSON, ale obsahují speciální vyhrazená klíčová slova s předponou @, která mají sémantický význam. Nejzákladnějšími z těchto klíčových slov jsou @context, @type a @id. Vlastnost @context určuje slovníkový jmenný prostor – typicky https://schema.org – který definuje význam všech vlastností a typů použitých v zápisu. Tento kontext funguje jako deklarace jmenného prostoru podobně jako v XML a zajišťuje, že názvy vlastností jsou interpretovány konzistentně napříč různými systémy a platformami.
Vlastnost @type určuje typ schématu entity, kterou popisujeme, například Product, Article, Event, Organization nebo LocalBusiness. Každý typ ve schema.org má sadu vlastností, které lze použít k popisu konkrétních instancí. Například typ Product může zahrnovat vlastnosti jako name, description, price, image, aggregateRating a offers. Vlastnost @id poskytuje jedinečný identifikátor entity, obvykle URL odkazující na další informace o této entitě.
Kromě těchto základních klíčových slov obsahují JSON-LD dokumenty vlastní vlastnosti, které přímo odpovídají slovníku schema.org. Tyto vlastnosti mohou obsahovat jednoduché hodnoty (řetězce, čísla, data) nebo složité vnořené objekty představující související entity. Například entita Product může mít vlastnost offers, která obsahuje vnořený objekt Offer se svým vlastním @type a vlastnostmi jako price a priceCurrency. Tato možnost vnoření umožňuje JSON-LD vyjadřovat sofistikované datové vztahy a hierarchie, které by bylo v plošších formátech jako Microdata nesnadné reprezentovat.
| Aspekt | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Umístění implementace | Samostatný <script> tag v <head> nebo <body> | Vložený do HTML atributů | Vložený do HTML atributů |
| Snadnost implementace | Velmi snadné; minimální změny v HTML | Střední; vyžaduje přidání HTML atributů | Střední až složité; vyžaduje deklaraci jmenných prostorů |
| Náročnost údržby | Nízká; data oddělena od prezentace | Střední; zápis prokládán obsahem | Střední až vysoká; více slovníků možné |
| Podpora dynamického obsahu | Výborná; funguje s vkládáním přes JavaScript | Omezená; vyžaduje server-side renderování | Omezená; vyžaduje server-side renderování |
| Doporučení Google | Doporučeno | Podporováno | Podporováno |
| Míra adopce (2024) | 41 % všech webů; 70 % webů se strukturovanými daty | ~20 % webů se strukturovanými daty | ~15 % webů se strukturovanými daty |
| Flexibilita slovníků | Jeden slovník na dokument (typicky schema.org) | Jeden slovník na dokument | Podpora více slovníků |
| Složitost vnoření | Výborná; přirozená hierarchie JSON | Dobrá; vyžaduje více deklarací itemscope | Dobrá; podporuje složité vztahy |
| Kompatibilita s AI vyhledávači | Výborná; preferováno ChatGPT, Perplexity, Claude | Dobrá; podporováno, ale méně preferováno | Dobrá; podporováno, ale méně preferováno |
Když crawler vyhledávače nebo AI systém narazí na stránku obsahující JSON-LD zápis, analyzuje <script type="application/ld+json"> tag a extrahuje strukturovaná data. Crawler použije @context k pochopení použitého slovníku a následně interpretuje jednotlivé vlastnosti podle definic schema.org. Tento proces umožňuje vyhledávači získat konkrétní, strojově čitelné informace o obsahu stránky bez nutnosti spoléhat na zpracování přirozeného jazyka nebo heuristiky.
Pro Google Search umožňuje JSON-LD zápis zobrazování bohatých výsledků – rozšířených výpisů ve vyhledávání, které obsahují vizuální prvky jako hodnocení, ceny, obrázky a detaily událostí. Když Google prochází produktovou stránku se správně implementovaným JSON-LD zápisem, může přímo ze strukturovaných dat získat název produktu, cenu, dostupnost, recenze a obrázky. Tyto informace pak použije k vytvoření bohatého výsledku zobrazeného ve vyhledávání, který má obvykle vyšší míru prokliku než běžné modré odkazy. Výzkumy velkých webů ukazují dopad: Rotten Tomatoes zaznamenal 25 % vyšší míru prokliku na stránkách s rozšířenými daty, zatímco Nestlé měřilo 82 % vyšší míru prokliku na stránkách zobrazovaných jako bohaté výsledky.
Pro AI vyhledávače jako Perplexity, ChatGPT a Google AI Overviews má JSON-LD trochu jinou, ale stejně důležitou roli. Tyto systémy využívají strukturovaná data k porozumění sémantickému významu obsahu, identifikaci klíčových entit a vztahů a přesné extrakci informací pro zařazení do AI generovaných odpovědí. Když AI systém narazí na JSON-LD zápis, dokáže s jistotou určit, o jaký typ entity se jedná, jaké má vlastnosti a jak souvisí s dalšími entitami. Toto strukturované pochopení umožňuje AI systémům poskytovat přesnější, kontextově relevantní odpovědi a správně přiřazovat informace zdrojovým webům.
Efektivní implementace JSON-LD vyžaduje pochopení několika klíčových zásad a osvědčených postupů. Za prvé, JSON-LD by měl být umístěn v <head> části HTML dokumentu, i když jej lze vložit i do <body>. Umístění v <head> je obecně preferováno, protože zajišťuje, že strukturovaná data budou zpracována před načtením obsahu stránky, i když moderní vyhledávače a AI systémy dokáží JSON-LD zpracovat odkudkoli ze stránky.
Za druhé, @context by mělo být vždy explicitně definováno, obvykle jako "@context": "https://schema.org". To zajišťuje, že všechny názvy vlastností a typů budou interpretovány podle definic schema.org. I když je technicky možné použít více kontextů nebo vlastní slovníky, naprostá většina webových implementací používá výhradně schema.org.
Za třetí, JSON-LD zápis by měl přesně odrážet viditelný obsah stránky. Vyhledávače i AI systémy očekávají, že strukturovaná data budou odpovídat tomu, co uživatelé na stránce vidí. Přidávání JSON-LD o informacích, které nejsou uživatelům viditelné – nebo které odporují viditelnému obsahu – může vést k penalizaci či ignorování zápisu. Tento princip je zásadní pro udržení důvěry vyhledávačů a pro to, aby AI systémy správně citovaly váš obsah.
Za čtvrté, všechny požadované vlastnosti pro daný typ schématu by měly být zahrnuty. I když schema.org definuje mnoho volitelných vlastností, zahrnutí těch povinných zajišťuje, že vyhledávače mohou zápis správně validovat a zobrazit. Například schéma Product vyžaduje alespoň vlastnosti name, description a offers, aby bylo možné zobrazit bohatý výsledek.
Za páté, JSON-LD by měl být před nasazením validován pomocí nástrojů jako Google Rich Results Test nebo Validator schema.org. Tyto nástroje kontrolují syntaktické chyby, chybějící povinné vlastnosti a další problémy, které by mohly zabránit rozpoznání zápisu. Testování během vývoje zabrání problémům v produkci a zajistí, že zápis bude fungovat dle očekávání.
Implementace strukturovaných dat pomocí JSON-LD přináší měřitelné výhody v několika oblastech. Z hlediska SEO umožňuje JSON-LD bohaté výsledky, které výrazně zvyšují míru prokliku. Food Network převedl 80 % svých stránek na strukturovaná data a zaznamenal 35% nárůst návštěvnosti. Rakuten zjistil, že uživatelé tráví 1,5x více času na stránkách se strukturovanými daty oproti nestrukturovaným a zaznamenal 3,6x vyšší míru interakce na AMP stránkách s vyhledávacími funkcemi.
Z hlediska viditelnosti v AI vyhledávání je JSON-LD stále důležitější, jak se AI vyhledávače stávají běžnou součástí webu. Weby implementující JSON-LD mají vyšší pravděpodobnost, že jejich obsah bude přesně pochopen, citován a zobrazen v AI generovaných odpovědích. To je zvlášť důležité pro uživatele AmICited, kteří chtějí sledovat, jak se jejich značka, doména a URL zobrazují ve výsledcích AI vyhledávání na platformách jako ChatGPT, Perplexity, Google AI Overviews a Claude. Správná implementace JSON-LD zajistí, že AI systémy budou mít dostatek strukturovaného kontextu pro správné přiřazení a citaci vašeho obsahu.
Z technického pohledu JSON-LD snižuje složitost implementace a zátěž při údržbě. Protože je zápis oddělen od HTML obsahu, mohou vývojáři spravovat strukturovaná data nezávisle na změnách rozvržení stránky. Toto oddělení je zvláště cenné pro velké organizace s komplexními redakčními systémy, kde za obsah a technickou implementaci odpovídají různé týmy.
Z uživatelského pohledu JSON-LD nepřímo zvyšuje zapojení uživatelů tím, že umožňuje bohatší a informativnější výsledky ve vyhledávání. Uživatelé častěji kliknou na výsledky, které zahrnují hodnocení, ceny, obrázky a další strukturované informace, což vede k vyšší návštěvnosti a lepším konverzím na webech, které JSON-LD efektivně využívají.
JSON-LD se bez problémů integruje s moderními webovými postupy a technologiemi. Na rozdíl od Microdata a RDFa, které pro správné zpracování vyhledávači vyžadují server-side renderování, může být JSON-LD dynamicky vkládán do stránky pomocí JavaScriptu. Tato schopnost je zásadní pro single-page aplikace (SPA), progresivní webové aplikace (PWA) a další JavaScriptem řízené weby s dynamicky generovaným obsahem.
Redakční systémy (CMS) jako WordPress, Shopify, Wix a Drupal stále častěji nabízejí vestavěnou podporu generování JSON-LD, ať už nativně nebo prostřednictvím pluginů. Tato demokratizace implementace JSON-LD znamená, že i netechnicky zaměření uživatelé mohou přidávat strukturovaná data na své stránky bez nutnosti programování. Mnoho CMS platforem generuje JSON-LD automaticky na základě metadat stránky a obsahu, čímž snižuje zátěž pro vývojáře i tvůrce obsahu.
JSON-LD dobře funguje také s bezhlavými CMS architekturami, kde je obsah spravován odděleně od prezentace. V těchto systémech lze JSON-LD generovat na straně serveru a doručovat jako součást odpovědi stránky, nebo jej lze generovat na straně klienta pomocí JavaScriptových frameworků jako React, Vue nebo Angular. Tato flexibilita činí JSON-LD vhodným pro prakticky jakoukoli moderní webovou architekturu.
https://schema.org pro konzistentní výklad slovníkuBudoucí význam JSON-LD pravděpodobně poroste. S tím, jak se AI vyhledávače a velké jazykové modely stávají sofistikovanějšími, roste potřeba kvalitních, strojově čitelných strukturovaných dat. Vyhledávače i AI systémy stále častěji využívají strukturovaná data nejen pro zobrazování, ale jako klíčovou součást svých algoritmů porozumění a řazení výsledků.
Mezi novinky ve světě JSON-LD patří JSON-LD-star, který rozšiřuje formát pro podporu složitějších vztahů v znalostních grafech, a CBOR-LD, jenž poskytuje kompaktnější binární reprezentaci JSON-LD dat. Tyto rozšíření naznačují, že ekosystém JSON-LD se bude dále vyvíjet tak, aby vyhověl potřebám stále sofistikovanějších webových aplikací i AI systémů.
Vzestup AI vyhledávačů znamená zásadní změnu v tom, jak se strukturovaná data využívají. Tradiční vyhledávače používají strukturovaná data hlavně k zobrazení bohatých výsledků. AI vyhledávače oproti tomu využívají strukturovaná data jako základní vstup pro své porozumění a rozhodování. To znamená, že weby, které efektivně implementují JSON-LD, získají významnou výhodu v oblasti viditelnosti a četnosti citací v AI vyhledávání.
Kromě toho, s rostoucím důrazem na ochranu soukromí a správu dat může JSON-LD sehrát stále větší roli při vyjádření původu dat, licencování a práv k užití. Flexibilita a rozšiřitelnost tohoto formátu z něj činí vhodný nástroj pro vyjádření složitých metadat o zdrojích dat a omezeních použití, což bude stále důležitější, jak budou organizace usilovat o kontrolu nad tím, jak jejich data využívají AI systémy.
Pro organizace využívající platformy jako AmICited ke sledování své viditelnosti v AI vyhledávačích je komplexní implementace JSON-LD strategickou investicí. Poskytnutím jasného, strukturovaného kontextu o svém obsahu AI systémům zvyšujete pravděpodobnost, že vaše značka, doména a URL budou správně pochopeny, citovány a zobrazeny v AI generovaných odpovědích. S tím, jak význam AI vyhledávání poroste, stane se JSON-LD nezbytnou součástí každé komplexní SEO a strategie viditelnosti obsahu.
JSON-LD a Microdata jsou oba formáty strukturovaných dat, ale liší se v implementaci. JSON-LD je vložen v samostatném <script> tagu a není prokládán HTML obsahem, což usnadňuje údržbu a nasazení ve velkém měřítku. Microdata používá HTML atributy přímo v obsahu stránky. Google doporučuje JSON-LD pro většinu implementací, protože je méně náchylný k chybám uživatelů a bez problémů funguje s dynamicky vkládaným obsahem z JavaScriptových frameworků a redakčních systémů.
JSON-LD umožňuje vyhledávačům lépe porozumět obsahu stránky, což může vést k bohatým výsledkům – rozšířeným zobrazením ve vyhledávání s hodnoceními, cenami, obrázky a dalšími strukturovanými informacemi. Studie ukazují, že stránky se strukturovanými daty mají výrazně vyšší míru prokliku. Například Nestlé naměřilo o 82 % vyšší míru prokliku na stránkách zobrazovaných jako bohaté výsledky ve srovnání se stránkami bez těchto výsledků, což ukazuje přímý dopad JSON-LD na výkon ve vyhledávání a zapojení uživatelů.
@context v JSON-LD určuje slovníkový jmenný prostor (obvykle schema.org), který definuje význam vlastností a typů použitých v zápisu. Funguje podobně jako jmenný prostor v XML a říká vyhledávačům a AI systémům, jak interpretovat data. Například @context: 'https://schema.org' říká parseru, že hodnoty @type jako 'Product' nebo 'Article' odkazují na definice schema.org a zajišťuje tak jednotný výklad napříč různými platformami a systémy.
Ano, strukturovaná data JSON-LD jsou stále důležitější pro AI vyhledávače. Platformy jako ChatGPT, Perplexity a Google AI Overviews využívají strukturovaná data k lepšímu pochopení a extrakci informací z webových stránek. JSON-LD poskytuje strojově čitelný kontext, který těmto AI systémům pomáhá identifikovat klíčové entity, vztahy a typy obsahu a zvyšuje pravděpodobnost, že váš obsah bude citován a zobrazen v AI generovaných odpovědích.
Klíčové vlastnosti JSON-LD zahrnují @context (určuje slovník), @type (specifikuje typ schématu, např. Product nebo Article), @id (jedinečný identifikátor entity) a vlastní vlastnosti podle typu schématu. Pro schéma Product můžete uvést například name, description, price, image a aggregateRating. Každá vlastnost odpovídá definici ve schema.org, což umožňuje vyhledávačům extrahovat a porozumět konkrétním informacím o vašem obsahu.
Používání JSON-LD výrazně vzrostlo a v roce 2024 dosáhlo 41 % všech webových stránek, oproti 34 % v roce 2022. Mezi weby využívajícími strukturovaná data je JSON-LD nejrozšířenější formát, používá ho přibližně 70 % těchto stránek. Tento růst odráží doporučení Googlu používat JSON-LD jako preferovaný formát a jeho jednoduchost oproti alternativám jako Microdata a RDFa.
JSON-LD nabízí několik výhod oproti RDFa: je snadnější na implementaci i údržbu, nevyžaduje prokládání HTML obsahem, bez problémů funguje s obsahem generovaným JavaScriptem a je méně náchylný k chybám. RDFa sice umožňuje kombinovat více slovníků pro komplexní požadavky, ale jednoduchost JSON-LD a explicitní doporučení Googlu z něj činí preferovanou volbu pro většinu webů, které chtějí implementovat strukturovaná data pro viditelnost ve vyhledávačích i AI.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte, co je JSON-LD a jak jej implementovat pro SEO. Objevte výhody strukturovaných dat pro Google, ChatGPT, Perplexity a viditelnost ve vyhledávání pomocí ...
Diskuze komunity o implementaci JSON-LD pro viditelnost ve vyhledávání přes AI. Vývojáři a SEO specialisté sdílejí, jak strukturovaná data ovlivňují citace AI a...
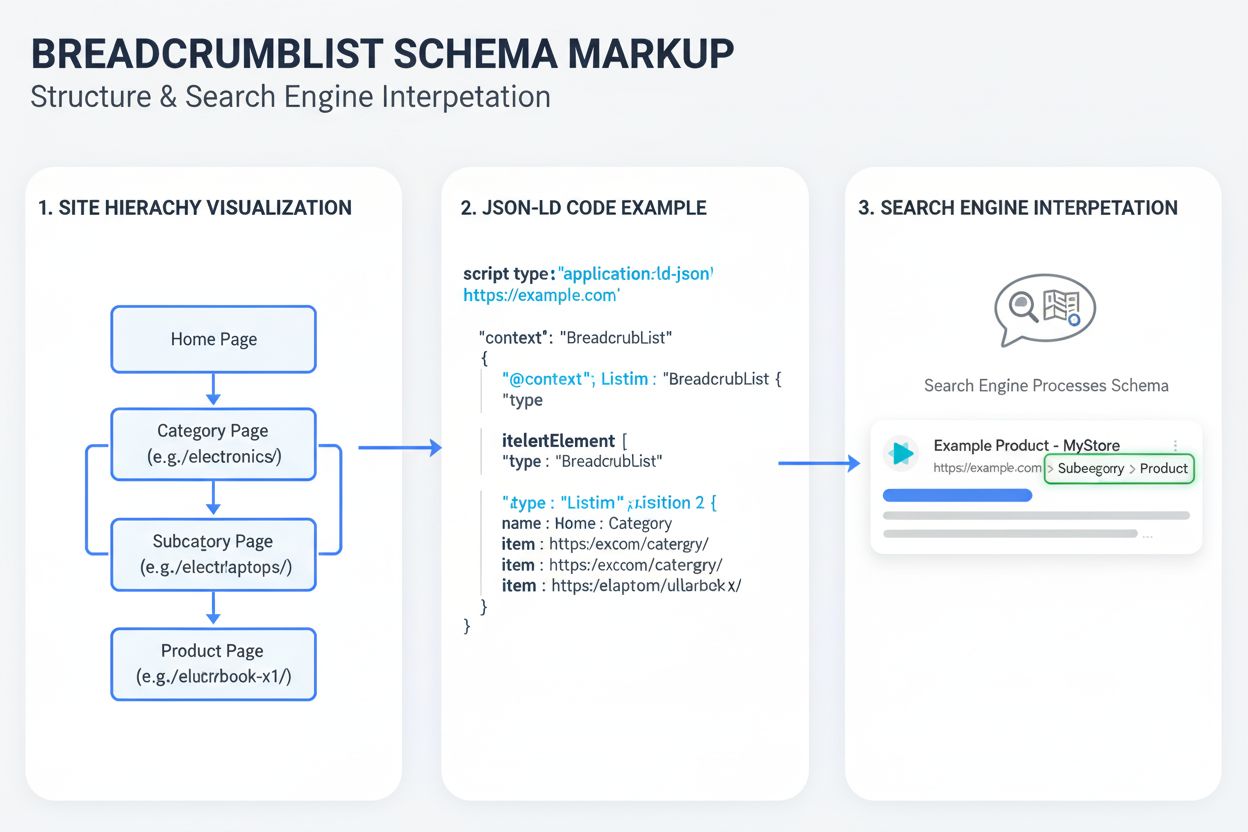
BreadcrumbList Schema je strukturované označení dat, které pomáhá vyhledávačům pochopit hierarchii webu a zobrazit breadcrumb navigaci ve výsledcích vyhledávání...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.