
Jak implementovat LLMs.txt: Podrobný technický průvodce
Zjistěte, jak implementovat LLMs.txt na svůj web a pomoci AI systémům lépe porozumět vašemu obsahu. Kompletní průvodce krok za krokem pro všechny platformy včet...
9 min čtení

Navrhovaný standardní soubor umístěný v kořenové doméně webu, který komunikuje s AI crawlery a velkými jazykovými modely o vysoce kvalitním, citovatelném obsahu. Podobný robots.txt, ale navržený pro poskytování vodítek v době inference místo řízení přístupu. Pomáhá AI systémům objevovat a upřednostňovat autoritativní obsah při generování odpovědí. Stává se stále více přijímaným hlavními AI platformami, jako jsou OpenAI, Anthropic, Perplexity a Google.
Navrhovaný standardní soubor umístěný v kořenové doméně webu, který komunikuje s AI crawlery a velkými jazykovými modely o vysoce kvalitním, citovatelném obsahu. Podobný robots.txt, ale navržený pro poskytování vodítek v době inference místo řízení přístupu. Pomáhá AI systémům objevovat a upřednostňovat autoritativní obsah při generování odpovědí. Stává se stále více přijímaným hlavními AI platformami, jako jsou OpenAI, Anthropic, Perplexity a Google.
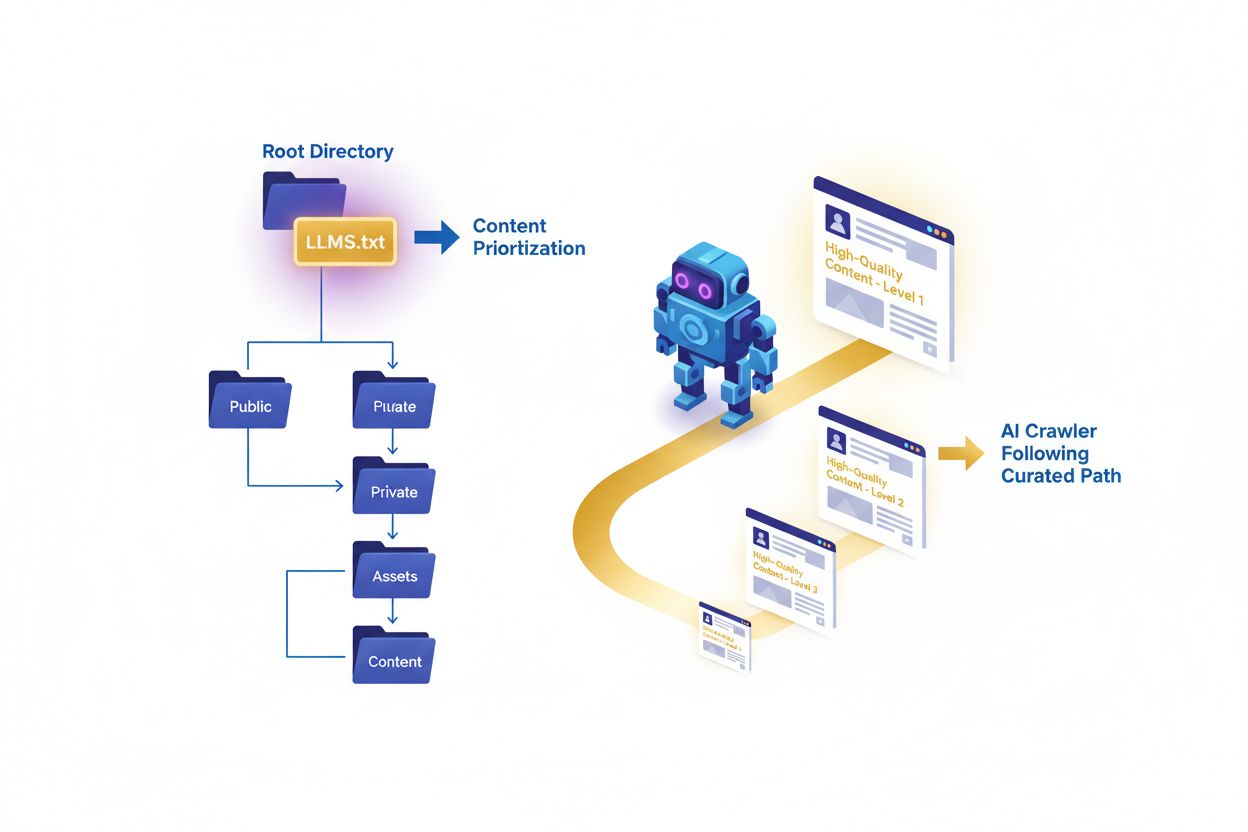
LLMs.txt soubor je prostý textový markdown soubor umístěný v kořenové doméně webu, který slouží jako kurátorovaný průvodce pro velké jazykové modely během inference. Na rozdíl od tradičních SEO nástrojů je LLMs.txt navržen tak, aby AI crawlery a jazykové modely dokázaly objevit a upřednostnit vysoce kvalitní obsah na vašem webu při generování odpovědí nebo vyhledávání informací. Tento navrhovaný standard představuje posun v tom, jak weby komunikují s AI systémy – místo blokování jako robots.txt poskytuje inteligentní kurátorství obsahu. Soubor funguje jako obsahová mapa, která AI systémům říká, které stránky, články a zdroje jsou nejhodnotnější, nejautoritativnější a nejrelevantnější. Je důležité pochopit, že LLMs.txt není o blokování nebo povolování AI tréninku – je určen výhradně pro příjem obsahu v čase inference, tedy pro pomoc AI systémům najít správný obsah při zodpovídání dotazů. Soubor je psán ve formátu markdown a uložen jako prostý text, což usnadňuje jeho tvorbu i údržbu. Implementací LLMs.txt může web zajistit, že když AI systémy odkazují na jeho obsah, čerpají z nejpřesnějších, dobře strukturovaných a autoritativních zdrojů.
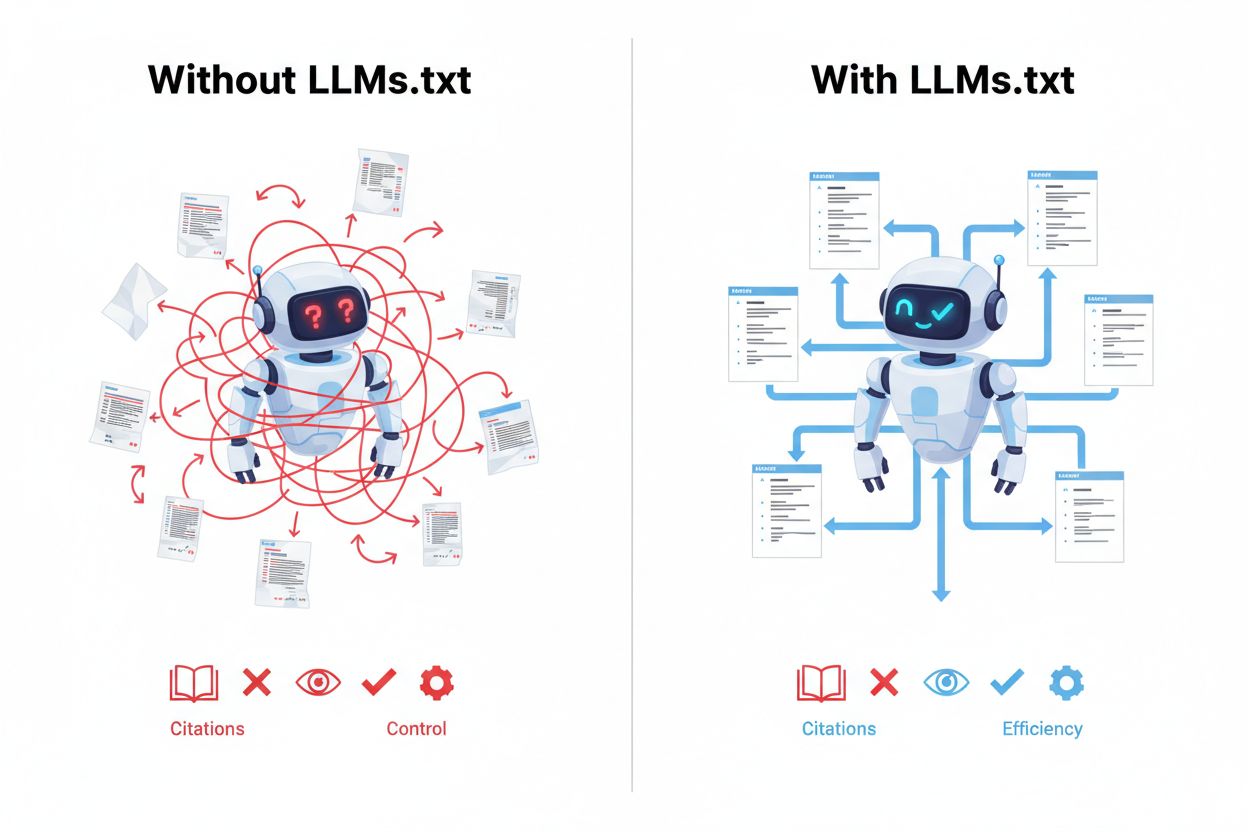
I když robots.txt a sitemap.xml dobře sloužily pro tradiční vyhledávače, LLMs.txt řeší zásadně odlišnou potřebu v době umělé inteligence. Klíčový rozdíl spočívá v jejich hlavních funkcích a časování: robots.txt řídí chování crawlerů a to, k čemu mají vyhledávače přístup, sitemap.xml pomáhá vyhledávačům objevit a indexovat stránky, zatímco LLMs.txt naviguje AI systémy během inference, tedy při aktivním generování odpovědí. Je důležité pochopit, že LLMs.txt neblokuje ani nepovoluje AI trénink – pouze kurátoruje, jaký obsah by měly AI systémy upřednostnit při zodpovídání dotazů či vyhledávání informací. Všechny tři soubory mají doplňující účely a mohou bez problémů koexistovat na jedné doméně. Zatímco robots.txt je o řízení přístupu a sitemap.xml o objevení obsahu, LLMs.txt je o kvalitě a relevanci obsahu. Můžete si to představit takto: robots.txt říká „co můžete crawlovať“, sitemap.xml říká „co zde je“, a LLMs.txt říká „na čem nejvíc záleží“. Tento rozdíl je důležitý, protože AI systémy potřebují jiné signály než tradiční vyhledávače – musí poznat, který obsah je autoritativní, dobře strukturovaný a vhodný k citaci.
| Soubor | Hlavní funkce | Hlavní účel | Případ použití |
|---|---|---|---|
| robots.txt | Řízení přístupu | Zabránit/povolit přístup crawlerům | Blokování citlivých stránek před vyhledávači |
| sitemap.xml | Objevitelnost | Pomoc vyhledávačům najít stránky | Zlepšení indexace nového nebo hlubokého obsahu |
| LLMs.txt | Kurátorování obsahu | Navigace AI při získávání obsahu v čase inference | Směrování AI systémů na autoritativní zdroje |
LLMs.txt soubor používá strukturu založenou na markdownu, která je čitelná pro lidi i stroje, což ji zpřístupňuje autorům obsahu i AI systémům. Soubor obvykle začíná H1 titulkem (pomocí #), který identifikuje web a jeho účel, následovaný úvodní blokovou citací poskytující informace o poslání nebo zaměření webu. Jádro struktury tvoří organizované sekce pomocí H2 nadpisů (##), které kategorizují různé typy obsahu – např. „Hlavní zdroje“, „Průvodce“, „Dokumentace“ nebo „Osvědčené postupy“ – každá obsahuje kurátorovaný seznam URL s krátkými popisy. Volitelná sekce na konci umožňuje zahrnout další zdroje, které mohou být hodnotné, ale nejsou součástí hlavního výběru. Soubor využívá prostý text v UTF-8 kódování pro zajištění kompatibility se všemi systémy a AI platformami. Každá URL položka obvykle obsahuje celou cestu a krátký popis vysvětlující hodnotu nebo obsah. Doporučená velikost souboru je obecně pod 100 KB pro efektivní zpracování AI systémy, i když není stanoven striktní limit. Markdown formát umožňuje flexibilní organizaci při zachování přehlednosti a struktura by měla odrážet skutečnou hierarchii a důležitost obsahu vašeho webu.
# Příkladový web – LLMs.txt
> Toto je Příkladový web, komplexní zdroj pro studium [vašeho tématu].
> Poskytujeme autoritativní průvodce, tutoriály a dokumentaci pro [vaši oblast].
## Hlavní zdroje
- https://example.com/about - Přehled naší mise a odbornosti
- https://example.com/getting-started - Základní startovní bod pro nové uživatele
## Komplexní průvodce
- https://example.com/guide/advanced-techniques - Hloubkový průzkum pokročilých metod
- https://example.com/guide/best-practices - Odborné standardy a doporučení
## Dokumentace
- https://example.com/docs/api-reference - Kompletní dokumentace API
- https://example.com/docs/installation - Pokyny k instalaci a nastavení
## Volitelné
- https://example.com/blog/latest-trends - Aktuální trendy v oboru
- https://example.com/case-studies - Příklady reálných implementací
Implementace LLMs.txt přináší významné výhody v nově se rozvíjejícím světě vyhledávání a objevování obsahu poháněného AI. Primární výhodou je příjem obsahu v čase inference, což znamená, že váš kurátorovaný obsah je upřednostňován, když AI systémy aktivně odpovídají na dotazy uživatelů, nikoliv pouze během tréninku. To vede k lepšímu pochopení obsahu AI systémy – kontext, autorita a relevance jsou správně zachyceny a výsledkem jsou přesnější citace a odkazy při zmínkách AI. Implementací LLMs.txt získáváte přímou kontrolu nad objevitelností, takže AI systémy najdou nejdříve váš nejlepší obsah, namísto méně kvalitních stránek. Soubor zvyšuje viditelnost ve výsledcích AI vyhledávání a v aplikacích využívajících AI, což vytváří nový kanál pro návštěvnost a citace nad rámec tradičního SEO. Organizace, které LLMs.txt zavedou brzy, získají konkurenční výhodu tím, že se stanou autoritativními zdroji ve svém oboru dříve, než se standard rozšíří. Implementace zároveň slouží jako příprava na budoucnost, protože web bude připraven na nevyhnutelný posun k AI-řízenému objevování obsahu.
Hlavní případy užití:
LLM-přátelský obsah má určité vlastnosti, díky nimž je hodnotnější a lépe využitelný AI systémy během inference. Nejzásadnější je jasná struktura s odpovídající hierarchií nadpisů – použití H1, H2 a H3 pro logické rozčlenění informací, aby AI systémy pochopily tok a vztahy obsahu. Krátké odstavce (obvykle 2–4 věty) jsou vhodnější, protože umožňují AI snadněji extrahovat konkrétní myšlenky než husté bloky textu. Obsah by měl obsahovat seznamy, tabulky a odrážky, které rozkládají složité informace na stravitelné části a usnadňují AI jejich zpracování i citování. Minimum rušivých prvků (automaticky přehrávaná videa, vyskakovací okna, příliš mnoho reklam) je žádoucí, protože nepřispívají k hodnotě obsahu. Sémantická srozumitelnost – jasný jazyk, definování odborných pojmů a vyhýbání se nejasnostem – pomáhá AI správně pochopit význam. Obsah by měl být soběstačný a kontextový, tedy dávat smysl i při vyjmutí z původní stránky. Tento přístup přímo podporuje AI SEO a zvyšuje šanci, že váš obsah bude správně a kompletně citován, když jej AI systémy použijí.
Správná implementace LLMs.txt vyžaduje strategické promyšlení, jaký obsah si skutečně zaslouží zařazení a jak jej uspořádat pro maximální hodnotu. Soubor musí být umístěn v kořenové doméně (např. example.com/llms.txt), aby jej AI systémy a crawlery snadno nalezly. Místo zahrnutí celého sitemapu do LLMs.txt upřednostněte kvalitu před kvantitou – zařaďte pouze nejautoritativnější, stále relevantní a hodnotný obsah, na který chcete, aby AI systémy odkazovaly. Preferujte hodnotné zdroje, jako jsou komplexní průvodce, dokumentace, tutoriály a originální výzkum, které prokazují odbornost a přináší skutečnou hodnotu. Zvažte zařazení úvodní či o nás stránky, aby AI systémy lépe pochopily poslání a důvěryhodnost vašeho webu. Vybraný obsah by měl být dobře udržovaný a pravidelně aktualizovaný, protože zastaralé informace mohou poškodit vaši důvěryhodnost u AI systémů. Organizujte obsah logicky pomocí jasných sekcí, které odrážejí strukturu a kategorie vašeho webu. Vyhněte se obsahu vyžadujícímu přihlášení, placeným článkům nebo stránkám dostupným jen uživatelům, protože AI systémy k nim nemají přístup. Pravidelně provádějte audit a aktualizujte svůj LLMs.txt soubor, abyste reflektovali změny ve strategii obsahu, odstranili nefunkční odkazy a přidali nové autoritativní zdroje.
Adopce LLMs.txt se mezi hlavními AI platformami a firmami, které chápou hodnotu kurátorovaných zdrojů, rychle zrychluje. OpenAI, Anthropic, Perplexity a Google již oznámily podporu nebo zájem o standard LLMs.txt, přičemž některé platformy jej aktivně využívají pro zlepšení získávání a citování obsahu. Standard je zatím vznikající a není povinný, ale stále více je uznáván jako osvědčený postup pro weby, které chtějí optimalizovat svou viditelnost v AI aplikacích. Objevují se také adresáře a registry katalogizující weby s implementací LLMs.txt, což AI systémům usnadňuje objevování kurátorovaných zdrojů. První uživatelé získávají významnou výhodu tím, že si vybudují autoritu dříve, než se standard plošně rozšíří napříč AI platformami. Reálné příklady ukazují, že weby s LLMs.txt zaznamenávají vyšší počet citací a lepší zastoupení v AI generovaném obsahu. Trend naznačuje, že LLMs.txt se v následujících letech stane stejně běžným standardem jako robots.txt a sitemap.xml, takže implementace je rozumnou investicí pro progresivní organizace.
Rozdíl mezi llms.txt a llms-full.txt představuje dva doplňující přístupy k navádění AI systémů vaším obsahem. LLMs.txt je kurátorovaná, ručně vybíraná verze, která obsahuje pouze váš nejdůležitější, nejautoritativnější a nejhodnotnější obsah – obvykle 20–100 URL rozdělených podle kategorií s popisy. Oproti tomu llms-full.txt je kompletní, strojově čitelná verze, která obsahuje všechny stránky vašeho webu ve strukturovaném formátu, často generovaná automaticky ze sitemapu nebo redakčního systému. Hlavní rozdíl je v záměru: llms.txt vyžaduje lidské rozhodnutí a kurátorství, zatímco llms-full.txt je kompletní a vyčerpávající. LLMs.txt používejte, když chcete AI systémy směrovat na svůj nejlepší obsah a jasně signalizovat autoritu, llms-full.txt slouží jako záloha pro AI, které chtějí úplné pokrytí webu. Oba soubory používají markdown formát, ale s odlišnou filozofií – llms.txt je selektivní a strategický, llms-full.txt je inkluzivní a úplný. Mnoho organizací implementuje oba soubory současně, což AI umožňuje volit mezi kurátorovaným výběrem (llms.txt) a kompletním pokrytím (llms-full.txt). Například AIOSEO nabízí nástroje pro automatickou generaci obou verzí, kdy llms.txt zvýrazňuje prémiový obsah a llms-full.txt poskytuje úplné pokrytí webu.
Několik častých chyb může snížit efektivitu vaší implementace LLMs.txt a je potřeba se jim pečlivě vyhnout. Nejzásadnější chybou je umístění souboru na špatné místo – musí být v kořenové doméně (example.com/llms.txt), nikoliv v podadresářích či pod jinými názvy. Chybějící povinné prvky, jako H1 titulek a úvodní bloková citace, mohou zmást AI ohledně účelu a autority webu. Zahrnutí nefunkčních nebo zastaralých URL snižuje vaši důvěryhodnost a zbytečně zatěžuje AI systémy snahou o přístup k neexistujícímu obsahu. Nadměrné zahrnutí je další častou chybou – přidání stovek či tisíců URL popírá smysl kurátorství a AI má potíže identifikovat skutečně významný obsah. Špatné nebo chybějící popisy u odkazů znamenají, že AI systémy nepochopí hodnotu ani zaměření obsahu. Opomíjení pravidelných aktualizací umožňuje, aby soubor zastaral a obsahoval nefunkční odkazy nebo irelevantní obsah. Zahrnutí obsahu vyžadujícího přihlášení či placených článků, ke kterým AI nemá přístup, snižuje důvěru. Nakonec zajistěte, že používáte správný MIME typ (text/plain nebo text/markdown) při servírování souboru, protože špatná konfigurace může zabránit jeho správnému zpracování AI systémy.
Objevila se řada nástrojů a zdrojů, které zjednodušují tvorbu a údržbu LLMs.txt souborů. AIOSEO nabízí dedikovaný plugin, který automaticky generuje jak llms.txt, tak llms-full.txt, což umožňuje implementaci i neprogramátorům. Pro ty, kdo preferují manuální tvorbu, je proces jednoduchý – stačí vytvořit textový soubor ve formátu markdown a nahrát jej do kořenové domény. Validační nástroje jsou dostupné online pro kontrolu správného formátu, nefunkčních odkazů a souladu se standardem. Komunita na GitHubu vytvořila řadu repozitářů se šablonami, příklady a osvědčenými postupy pro implementaci LLMs.txt. Oficiální dokumentace na llmstxt.org poskytuje kompletní návod ke struktuře souboru, formátovacím požadavkům i strategiím implementace. Mnohé dokumentace AI platforem již zahrnují sekce o podpoře LLMs.txt, což vám pomůže pochopit, jak různé systémy využívají kurátorovaný obsah. Tyto zdroje dohromady usnadňují implementaci LLMs.txt a zajišťují, že váš obsah bude správně optimalizován pro AI-řízené objevování a citace.
LLMs.txt navádí AI systémy k vašemu nejlepšímu obsahu pro využití v době inference, zatímco robots.txt řídí, k čemu mají přístup crawlery vyhledávačů. Slouží odlišným účelům a mohou existovat vedle sebe na jedné doméně. LLMs.txt je o kurátorství a navádění, robots.txt o řízení přístupu.
Ne, není povinný, ale stává se osvědčenou praxí. Implementace LLMs.txt vám dává konkurenční výhodu ve výsledcích vyhledávání poháněných AI a zajišťuje, že váš obsah získá správné uvedení zdroje, když jej AI systémy citují.
Soubor musí být umístěn v kořeni vaší domény (např. vaseweb.cz/llms.txt), aby byl pro AI systémy a crawlery dohledatelný. Měl by být veřejně přístupný bez autentizace.
Ne, llms.txt není určen pro blokování nebo řízení tréninku. Je specificky určen pro navádění AI systémů v době inference (při generování odpovědí). Pokud chcete řídit přístup k tréninku, použijte robots.txt nebo jiné mechanismy.
Zkontrolujte a aktualizujte čtvrtletně nebo kdykoliv provedete významné změny ve struktuře webu, přidáte nový důležitý obsah nebo změníte URL adresy. Pravidelná údržba zajišťuje, že váš soubor zůstane přesný a hodnotný.
OpenAI, Anthropic, Perplexity a Google začaly implementovat podporu llms.txt. Přijetí roste, jak se tento standard stává více zavedeným a uznávaným jako osvědčená praxe.
LLMs.txt je kurátorovaný seznam vašeho nejlepšího obsahu (obvykle 20–100 URL), zatímco llms-full.txt obsahuje kompletní strojově čitelnou verzi veškerého vašeho obsahu ve formátu Markdown. Oba lze používat společně pro maximální flexibilitu.
Upřednostněte kvalitu před kvantitou. Zahrňte 10–20 vašich nejdůležitějších, autoritativních stránek, které nejlépe reprezentují vaši odbornost a hodnotu obsahu. Vyhněte se zahrnutí celého sitemapu do souboru.
AmICited sleduje, jak AI systémy odkazují na vaši značku v ChatGPT, Perplexity, Google AI Overviews a dalších. Zajistěte, aby váš obsah získal správné uvedení zdroje a viditelnost v odpovědích generovaných AI.
Zjistěte, jak implementovat LLMs.txt na svůj web a pomoci AI systémům lépe porozumět vašemu obsahu. Kompletní průvodce krok za krokem pro všechny platformy včet...

Kritická analýza efektivity LLMs.txt. Zjistěte, zda je tento AI obsahový standard nezbytný pro váš web, nebo je to jen hype. Skutečná data o adopci, podpoře pla...

Zjistěte, co je LLMs.txt, jestli skutečně funguje a zda byste ho měli nasadit na svůj web. Poctivá analýza tohoto nově vznikajícího AI SEO standardu.
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.