
Transformátorová architektura
Transformátorová architektura je návrh neuronové sítě využívající mechanismy self-attention pro paralelní zpracování sekvenčních dat. Pohání ChatGPT, Claude a m...
13 min čtení
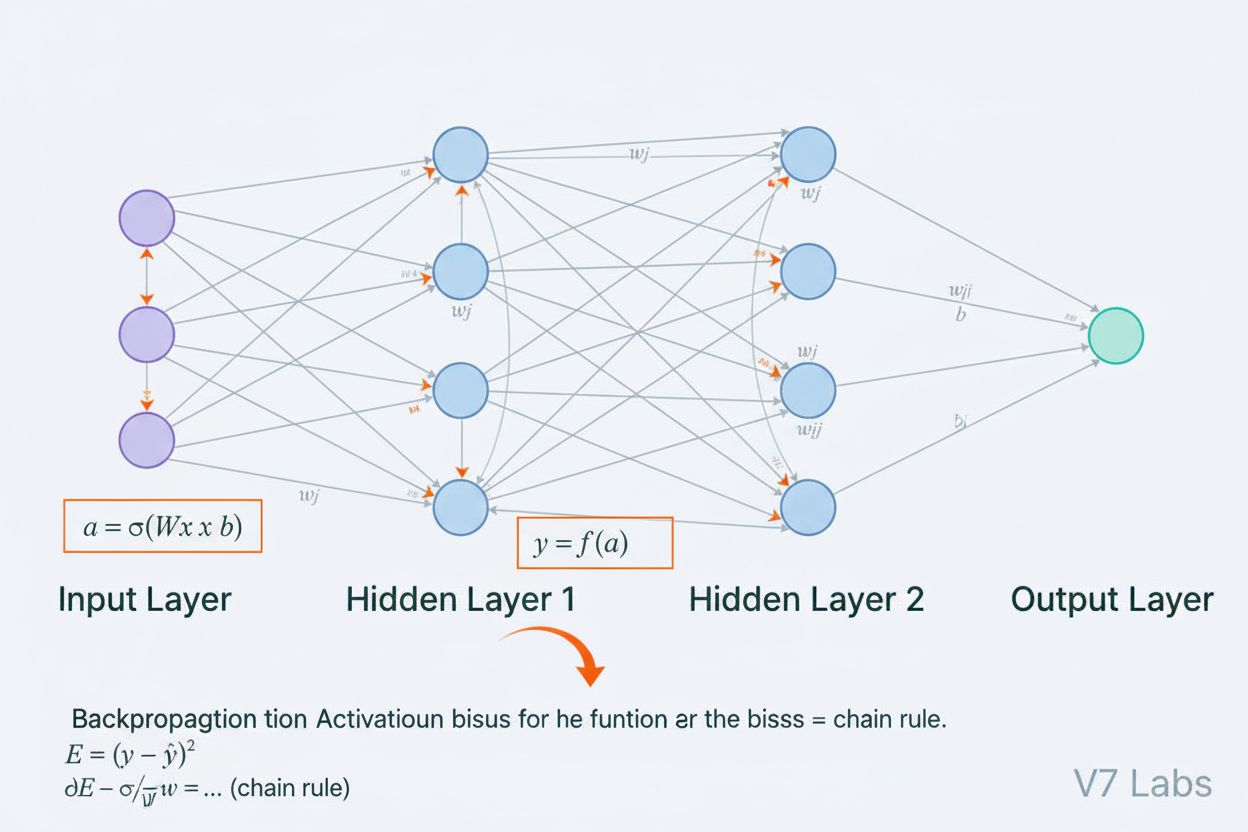
Neuronová síť je výpočetní systém inspirovaný biologickými neuronovými sítěmi, který se skládá z propojených umělých neuronů uspořádaných do vrstev a je schopen se učit vzorce z dat prostřednictvím procesu zvaného zpětná propagace. Tyto systémy tvoří základ moderní umělé inteligence a hlubokého učení a pohánějí aplikace od zpracování přirozeného jazyka až po počítačové vidění.
Neuronová síť je výpočetní systém inspirovaný biologickými neuronovými sítěmi, který se skládá z propojených umělých neuronů uspořádaných do vrstev a je schopen se učit vzorce z dat prostřednictvím procesu zvaného zpětná propagace. Tyto systémy tvoří základ moderní umělé inteligence a hlubokého učení a pohánějí aplikace od zpracování přirozeného jazyka až po počítačové vidění.
Neuronová síť je výpočetní systém zásadně inspirovaný strukturou a funkcí biologických neuronových sítí nalezených v mozcích živočichů. Skládá se z propojených umělých neuronů uspořádaných do vrstev—typicky vstupní vrstvy, jedné nebo více skrytých vrstev a výstupní vrstvy—které společně zpracovávají data, rozpoznávají vzorce a vytvářejí predikce. Každý neuron přijímá vstupy, provádí matematické transformace pomocí vah a biasů a výsledek prochází aktivační funkcí, která vytváří výstup. Definujícím rysem neuronových sítí je jejich schopnost učit se z dat skrze iterativní proces zvaný zpětná propagace, při kterém síť upravuje své vnitřní parametry za účelem minimalizace chyb predikce. Tato schopnost učení v kombinaci s kapacitou modelovat složité nelineární vztahy učinila z neuronových sítí základní technologii pohánějící moderní systémy umělé inteligence, od velkých jazykových modelů až po aplikace počítačového vidění.
Koncept umělých neuronových sítí vznikl z raných pokusů matematicky modelovat, jak biologické neurony komunikují a zpracovávají informace. V roce 1943 navrhli Warren McCulloch a Walter Pitts první matematický model neuronu a ukázali, že jednoduché výpočetní jednotky mohou provádět logické operace. Na tento teoretický základ navázalo v roce 1958 představení perceptronu Frankem Rosenblattem, což byl algoritmus navržený pro rozpoznávání vzorů a stal se historickým předchůdcem dnešních sofistikovaných architektur neuronových sítí. Perceptron byl v podstatě lineární model s omezeným výstupem, schopný učit se jednoduché rozhodovací hranice. V 70. letech však obor utrpěl výrazné neúspěchy, když vědci zjistili, že jednovrstvé perceptrony nedokážou řešit nelineární problémy jako je funkce XOR, což vedlo k období zvanému „AI zima“. Průlom přišel v 80. letech s opětovným objevením a zdokonalením zpětné propagace, algoritmu umožňujícího trénovat vícevrstvé sítě. Tento rozmach se dramaticky zrychlil v roce 2010 díky dostupnosti masivních datových sad, výkonných GPU a zdokonalených trénovacích technik, což vedlo k revoluci hlubokého učení, která proměnila umělou inteligenci.
Architektura neuronové sítě se skládá z několika klíčových součástí, které společně spolupracují. Vstupní vrstva přijímá surové znaky z externích zdrojů, přičemž každý neuron této vrstvy odpovídá jednomu znaku. Skryté vrstvy provádějí hlavní výpočetní operace, transformují vstupy do stále abstraktnějších reprezentací pomocí vážených kombinací a nelineárních aktivačních funkcí. Počet a velikost skrytých vrstev určují kapacitu sítě učit se složité vzorce—hlubší sítě dokážou zachytit složitější vztahy, ale vyžadují více dat a výpočetních prostředků. Výstupní vrstva produkuje finální predikce, přičemž její struktura závisí na úloze: jeden neuron pro regresi, více neuronů pro vícetřídní klasifikaci nebo specializované architektury pro jiné aplikace. Každé spojení mezi neurony nese váhu, která určuje sílu vlivu, zatímco každý neuron má bias, který posouvá jeho aktivační práh. Tyto váhy a biasy jsou učitelné parametry, které síť během tréninku upravuje. Aktivační funkce aplikovaná na každý neuron vnáší zásadní nelinearitu, díky níž se síť dokáže učit složité rozhodovací hranice a vzorce, které lineární modely zachytit nemohou.
Neuronové sítě se učí dvoufázovým iterativním procesem. Během dopředné propagace procházejí vstupní data sítí od vstupní vrstvy k výstupní. V každém neuronu se vypočítá vážený součet vstupů plus bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), který je následně předán aktivační funkci pro získání výstupu neuronu. Tento proces se opakuje v každé skryté vrstvě až po výstupní vrstvu, která poskytuje predikci sítě. Poté síť spočítá chybu mezi svou predikcí a skutečnou hodnotou pomocí ztrátové funkce, která měří, jak moc se predikce liší od správné odpovědi. Při zpětné propagaci je tato chyba předávána zpět sítí pomocí řetězového pravidla kalkulu. U každého neuronu algoritmus vypočítá gradient ztráty podle každé váhy a biasu, čímž určí, jak moc každý parametr přispěl k celkové chybě. Tyto gradienty vedou aktualizaci parametrů: váhy a biasy se upravují ve směru opačném k gradientu, přičemž velikost kroku určuje učící rychlost. Tento proces se opakuje v mnoha iteracích nad trénovací sadou, čímž dochází k postupnému snižování ztráty a zlepšení predikcí sítě. Kombinace dopředné propagace, výpočtu ztráty, zpětné propagace a aktualizace parametrů tvoří celý trénovací cyklus, který neuronovým sítím umožňuje učit se z dat.
| Typ architektury | Primární využití | Klíčová charakteristika | Přednosti | Omezení |
|---|---|---|---|---|
| Dopředné sítě | Klasifikace, regrese na strukturovaných datech | Informace proudí pouze jedním směrem | Jednoduché, rychlý trénink, snadná interpretace | Špatně zpracovávají sekvenční nebo prostorová data |
| Konvoluční neuronové sítě (CNNs) | Rozpoznávání obrazu, počítačové vidění | Konvoluční vrstvy detekují prostorové znaky | Výborné v zachycování lokálních vzorců, úspora parametrů | Vyžadují velké množství označených obrazových dat |
| Rekurentní neuronové sítě (RNNs) | Sekvenční data, časové řady, NLP | Skrytý stav uchovává paměť napříč časovými kroky | Zpracují sekvence proměnné délky | Trpí vymizením/explozí gradientů |
| Long Short-Term Memory (LSTM) | Dlouhodobé závislosti v sekvencích | Paměťové buňky s bránami vstupu, zapomnění a výstupu | Efektivně zvládají dlouhodobé závislosti | Komplexnější, pomalejší trénink než RNN |
| Transformátorové sítě | Zpracování přirozeného jazyka, velké jazykové modely | Mechanismus vícehlavé pozornosti, paralelní zpracování | Vysoce paralelizovatelné, zachytí dlouhodobé závislosti | Vyžadují obrovské výpočetní prostředky |
| Generativní adversariální sítě (GANs) | Generování obrazů, tvorba syntetických dat | Síť generátoru a diskriminátoru soupeří | Dokáží generovat realistická syntetická data | Obtížné na trénink, problémy s kolapsem režimů |
Zavedení aktivačních funkcí je jednou z nejzásadnějších inovací v návrhu neuronových sítí. Bez aktivačních funkcí by byla neuronová síť matematicky ekvivalentní jediné lineární transformaci, bez ohledu na počet vrstev. Kompozice lineárních funkcí je totiž opět lineární, což silně omezuje schopnost sítě učit se složité vzorce. Aktivační funkce tento problém řeší vnesením nelinearity do každého neuronu. ReLU (Rectified Linear Unit), definovaná jako f(x) = max(0, x), je díky své výpočetní efektivitě a účinnosti při tréninku hlubokých sítí nejpopulárnější volbou v moderním hlubokém učení. Sigmoidální funkce, f(x) = 1/(1 + e^(-x)), stlačuje výstupy do intervalu 0 až 1, což je užitečné pro binární klasifikaci. Tanh funkce, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), vytváří výstupy mezi -1 a 1 a často v hidden vrstvách funguje lépe než sigmoid. Výběr aktivační funkce významně ovlivňuje učící dynamiku sítě, rychlost konvergence i výsledný výkon. Moderní architektury často používají ReLU ve skrytých vrstvách pro výpočetní efektivitu a sigmoid nebo softmax ve výstupních vrstvách pro odhad pravděpodobnosti. Nelinearita zavedená aktivačními funkcemi umožňuje neuronovým sítím aproximovat libovolnou spojitou funkci, což je vlastnost známá jako věta o univerzální aproximaci, která vysvětluje jejich mimořádnou univerzálnost v různorodých aplikacích.
Trh s neuronovými sítěmi zažívá explozivní růst, což odráží zásadní roli této technologie v moderní umělé inteligenci. Podle nedávných průzkumů dosáhl celosvětový trh se softwarem neuronových sítí hodnoty přibližně 34,76 miliardy dolarů v roce 2025 a očekává se, že do roku 2030 vzroste na 139,86 miliardy dolarů, což představuje složenou roční míru růstu (CAGR) 32,10 %. Širší trh s neuronovými sítěmi vykazuje ještě dramatičtější expanzi, s odhady růstu z 34,05 miliardy dolarů v roce 2024 na 385,29 miliardy dolarů v roce 2033 při CAGR 31,4 %. Tento prudký růst je poháněn několika faktory: rostoucí dostupností velkých datových sad, vývojem efektivnějších trénovacích algoritmů, rozšiřováním GPU a specializovaného AI hardwaru a širokou adopcí neuronových sítí napříč odvětvími. Podle Stanfordské AI Index Report 2025 78 % organizací uvedlo, že v roce 2024 používalo AI, oproti 55 % předchozího roku, přičemž neuronové sítě tvoří páteř většiny podnikových AI implementací. Adopce zasahuje zdravotnictví, finance, výrobu, maloobchod i prakticky všechna další odvětví, neboť organizace rozpoznávají konkurenční výhodu, kterou systémy založené na neuronových sítích přinášejí v oblasti rozpoznávání vzorců, predikce a rozhodování.
Neuronové sítě pohánějí nejpokročilejší dnes nasazené AI systémy, včetně ChatGPT, Perplexity, Google AI Overviews a Claude. Tyto velké jazykové modely jsou postaveny na transformátorových neuronových architekturách využívajících mechanismy pozornosti ke zpracování a generování lidského jazyka s pozoruhodnou sofistikovaností. Transformátorová architektura, představená v roce 2017, způsobila revoluci ve zpracování přirozeného jazyka díky umožnění paralelního zpracování celých sekvencí namísto sekvenčního, což dramaticky zlepšilo efektivitu tréninku a výkon modelů. V kontextu monitoringu značky a sledování citací AI je porozumění neuronovým sítím klíčové, protože tyto systémy využívají neuronové sítě k pochopení kontextu, vyhledávání relevantních informací a generování odpovědí, které mohou zmiňovat nebo citovat vaši značku, doménu či obsah. AmICited využívá znalosti o tom, jak neuronové sítě zpracovávají a vyhledávají informace, k monitorování, kde se vaše značka objevuje v odpovědích generovaných AI na různých platformách. Jak se neuronové sítě dále zlepšují ve schopnosti rozumět sémantickému významu a vyhledávat relevantní informace, roste důležitost sledování přítomnosti vaší značky v AI odpovědích pro udržení viditelnosti a správu online reputace v době AI poháněného vyhledávání a tvorby obsahu.
Efektivní trénování neuronových sítí přináší několik zásadních výzev, které musí výzkumníci a praktici řešit. Přeučení nastává, když se síť naučí trénovací data až příliš dobře, včetně jejich šumu a zvláštností, což vede ke špatnému výkonu na nových, neznámých datech. To je obzvlášť problém u hlubokých sítí s mnoha parametry vzhledem k velikosti trénovacích dat. Nedoučení je opačný problém, kdy síť nemá dostatečnou kapacitu nebo trénink k zachycení základních vzorců v datech. Problém vymizení gradientu nastává u velmi hlubokých sítí, kdy se gradienty při zpětné propagaci exponenciálně zmenšují a váhy v počátečních vrstvách se aktualizují velmi pomalu nebo vůbec. Problém explodujícího gradientu je opačný případ, kdy gradienty exponenciálně rostou a trénink se stává nestabilním. Moderní řešení zahrnují batch normalizaci, která normalizuje vstupy vrstev pro udržení stabilního toku gradientů; reziduální spojení (skip connections), která umožňují gradientům procházet vrstvami přímo; a ořezávání gradientů (gradient clipping), které limituje velikost gradientů. Regularizační techniky jako L1 a L2 regularizace zavádějí penalizaci za velké váhy a podporují jednodušší modely s lepší generalizací. Dropout náhodně deaktivuje neurony během tréninku a brání jejich spolupůsobení, čímž zlepšuje generalizaci. Volba optimalizátoru (například Adam, SGD nebo RMSprop) a učící rychlosti významně ovlivňuje efektivitu tréninku i výsledný výkon modelu. Praktici musí pečlivě vyvažovat složitost modelu, velikost trénovacích dat, sílu regularizace a optimalizační parametry, aby dosáhli sítí, které se efektivně učí bez přeučení.
Vývoj architektur neuronových sítí směřuje k čím dál sofistikovanějším mechanismům zpracování informací. Rané dopředné sítě byly omezeny na vstupy pevné velikosti a nedokázaly zachytit časové či sekvenční závislosti. Rekurentní neuronové sítě (RNNs) zavedly zpětné vazby umožňující uchování informace v čase, což umožnilo zpracování sekvencí proměnné délky. RNNs však trpěly problémy s tokem gradientů a byly ze své podstaty sekvenční, což bránilo paralelizaci na moderním hardwaru. Long Short-Term Memory (LSTM) sítě některé z těchto problémů řešily pomocí paměťových buněk a řídicích bran, ale zůstaly v jádru sekvenční. Průlom znamenaly transformátorové sítě, které zcela nahradily rekurenci mechanismy pozornosti. Mechanismus pozornosti umožňuje síti dynamicky se zaměřit na různé části vstupu a počítat vážené kombinace všech vstupních prvků paralelně. Díky tomu mohou transformátory efektivně zachytit dlouhodobé závislosti a zároveň plně využít paralelizace na GPU clusterech. Transformátorová architektura v kombinaci s masivním měřítkem (moderní velké jazykové modely mají miliardy až biliony parametrů) se ukázala jako mimořádně účinná pro zpracování přirozeného jazyka, počítačové vidění i multimodální úlohy. Úspěch transformátorů vedl k jejich přijetí jako standardní architektury pro špičkové AI systémy, včetně všech hlavních velkých jazykových modelů. Tento vývoj ukazuje, jak architektonické inovace v kombinaci s rostoucími výpočetními zdroji a většími datovými sadami neustále posouvají hranice možností neuronových sítí.
Obor neuronových sítí se rychle vyvíjí a objevuje se několik perspektivních směrů. Neuromorfní výpočty usilují o vytváření hardwaru, který věrněji napodobuje biologické neuronové sítě, což slibuje vyšší energetickou efektivitu i výpočetní výkon. Výzkum v oblasti few-shot a zero-shot learningu se zaměřuje na to, aby se neuronové sítě dokázaly učit z minima příkladů, což by se více přiblížilo schopnostem lidského učení. Stále důležitější je vysvětlitelnost a interpretovatelnost, kdy výzkumníci vyvíjejí metody pro pochopení a vizualizaci toho, co se neuronové sítě učí, což je zásadní pro nasazení v kritických oblastech jako zdravotnictví, finance či justice. Federované učení umožňuje trénovat neuronové sítě na distribuovaných datech bez nutnosti centralizace citlivých informací, což řeší otázky soukromí. Kvantové neuronové sítě představují novou hranici, kde se principy kvantového výpočtu kombinují s architekturami neuronových sítí a potenciálně nabízejí exponenciální urychlení pro specifické úlohy. Multimodální neuronové sítě, které bezproblémově propojují text, obraz, zvuk a video, jsou čím dál propracovanější a umožňují komplexnější AI systémy. Vyvíjejí se také energeticky úsporné neuronové sítě pro snížení výpočetní i ekologické náročnosti tréninku a nasazení velkých modelů. Jak neuronové sítě dále pokročují, jejich integrace do AI monitorovacích systémů jako AmICited je stále důležitější pro organizace, které chtějí rozumět a spravovat přítomnost své značky v obsahu a odpovědích generovaných AI na platformách jako ChatGPT, Perplexity, Google AI Overviews a Claude.
Neuronové sítě jsou inspirované strukturou a funkcí biologických neuronů v lidském mozku. V mozku komunikují neurony prostřednictvím elektrických signálů přes synapse, které lze na základě zkušeností posilovat nebo oslabovat. Umělé neuronové sítě toto chování napodobují pomocí matematických modelů neuronů propojených váženými spoji, což systému umožňuje učit se a adaptovat se na data podobně, jako biologické mozky zpracovávají informace a tvoří vzpomínky.
Zpětná propagace je hlavní algoritmus, který neuronovým sítím umožňuje učení. Během dopředné propagace procházejí data vrstvami sítě a vytvářejí predikce. Síť poté vypočítá chybu mezi předpovězenými a skutečnými výstupy pomocí ztrátové funkce. Při zpětném průchodu je tato chyba propagována zpět skrz síť pomocí řetězového pravidla kalkulu, přičemž se vypočítává, jak moc se každá váha a bias podílela na chybě. Váhy jsou následně upraveny ve směru, který chybu minimalizuje, obvykle pomocí optimalizace gradientního sestupu.
Mezi hlavní architektury neuronových sítí patří dopředné sítě (data proudí pouze jedním směrem), konvoluční neuronové sítě neboli CNN (optimalizované pro zpracování obrazu), rekurentní neuronové sítě neboli RNN (určené pro sekvenční data), sítě s dlouhodobou krátkodobou pamětí neboli LSTM (vylepšené RNN s paměťovými buňkami) a transformátorové sítě (využívající mechanismy pozornosti pro paralelní zpracování). Každá architektura je specializovaná na různé typy dat a úkolů, od rozpoznávání obrazu po zpracování přirozeného jazyka.
Moderní AI systémy jako ChatGPT, Perplexity a Claude jsou postaveny na transformátorových neuronových sítích, které využívají mechanismy pozornosti pro efektivní zpracování jazyka. Tyto neuronové sítě umožňují systémům pochopit kontext, generovat souvislý text a provádět složité úlohy vyžadující uvažování. Schopnost neuronových sítí učit se z obrovských datových sad a zachytit složité vzorce v jazyce je činí nezbytnými pro tvorbu konverzační AI, která dokáže s pozoruhodnou přesností rozumět lidským dotazům a reagovat na ně.
Váhy v neuronových sítích řídí sílu spojení mezi neurony a určují, jaký vliv má každý vstup na výstup. Biasy jsou další parametry, které posouvají aktivační práh neuronů, takže se mohou aktivovat i při slabých vstupech. Váhy a biasy společně tvoří učitelné parametry sítě, které se během tréninku upravují za účelem minimalizace chyb predikce a umožnění učení složitých vzorců z dat.
Aktivační funkce vnášejí do neuronových sítí nelinearitu, díky čemuž se mohou učit složité, nelineární vztahy v datech. Bez aktivačních funkcí by i vícenásobné vrstvení vedlo pouze k lineárním transformacím, což by výrazně omezilo schopnost sítě učit se. Mezi běžné aktivační funkce patří ReLU (Rectified Linear Unit), sigmoid a tanh, z nichž každá vnáší jiný typ nelinearity, která síti pomáhá zachytit složité vzorce a dělat sofistikovanější předpovědi.
Skryté vrstvy jsou mezivrstvy mezi vstupní a výstupní vrstvou, kde síť provádí většinu svých výpočtů. Tyto vrstvy extrahují a transformují znaky z původních vstupních dat do stále abstraktnějších reprezentací. Hloubka a šířka skrytých vrstev určují schopnost sítě učit se složité vzorce. Hlubší sítě s více skrytými vrstvami dokáží zachytit sofistikovanější vztahy v datech, ale vyžadují více výpočetních prostředků a pečlivější trénink, aby se zabránilo přeučení.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Transformátorová architektura je návrh neuronové sítě využívající mechanismy self-attention pro paralelní zpracování sekvenčních dat. Pohání ChatGPT, Claude a m...
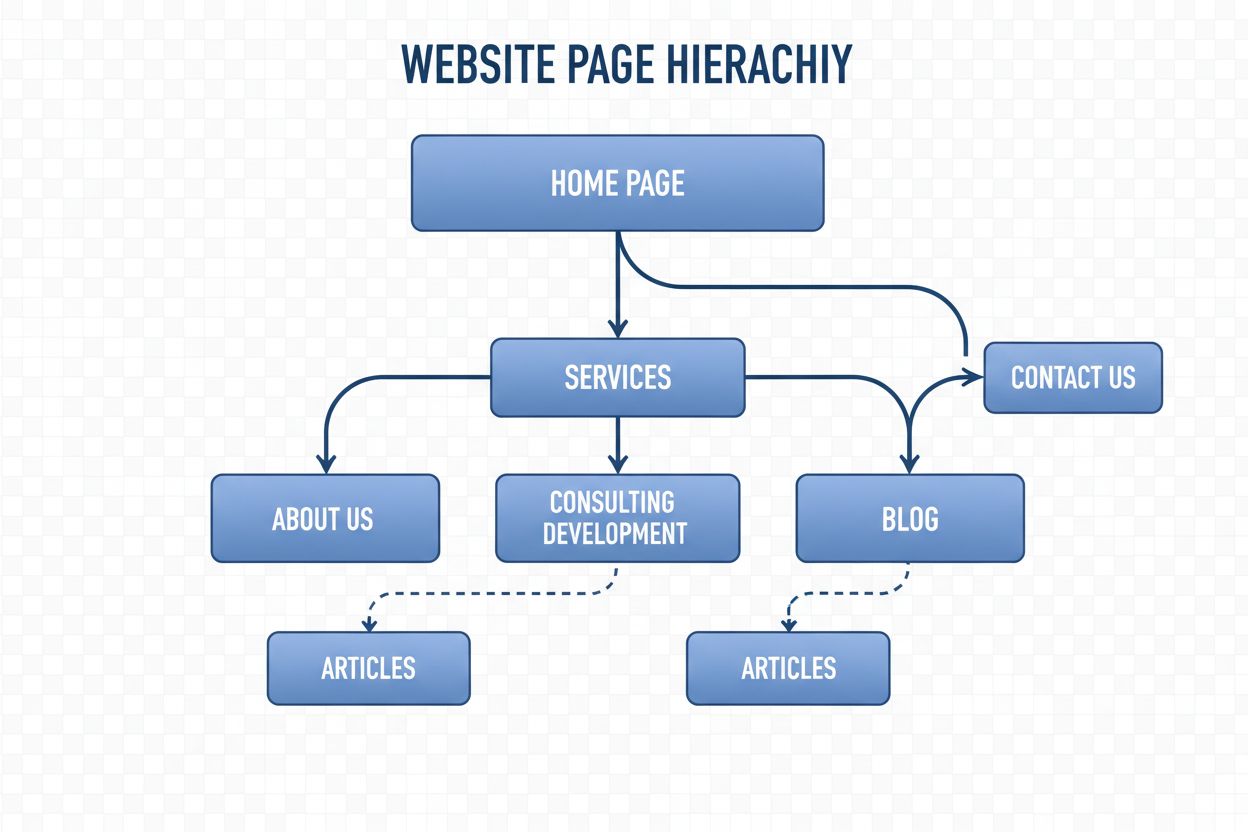
Navigační struktura je systém organizující stránky a odkazy webu, aby usnadnil pohyb uživatelům i AI robotům. Zjistěte, jak ovlivňuje SEO, uživatelský zážitek a...
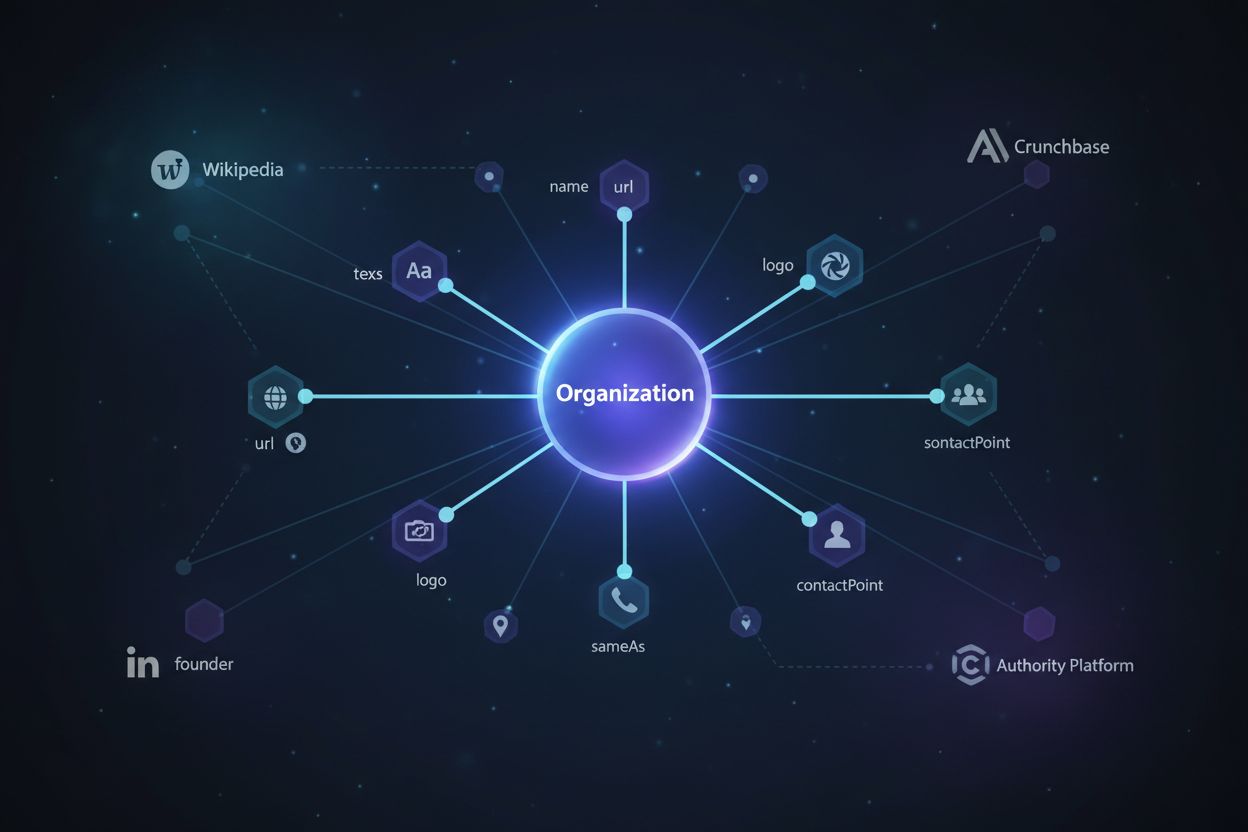
Zjistěte, jak schéma organizace pomáhá AI systémům rozpoznat a citovat vaši značku. Kompletní průvodce značkovým markupem pro viditelnost v LLM a citace v AI....
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.