
Upřesnění dotazu
Upřesnění dotazu je iterativní proces optimalizace vyhledávacích dotazů pro lepší výsledky v AI vyhledávačích. Zjistěte, jak funguje v ChatGPT, Perplexity, Goog...
11 min čtení
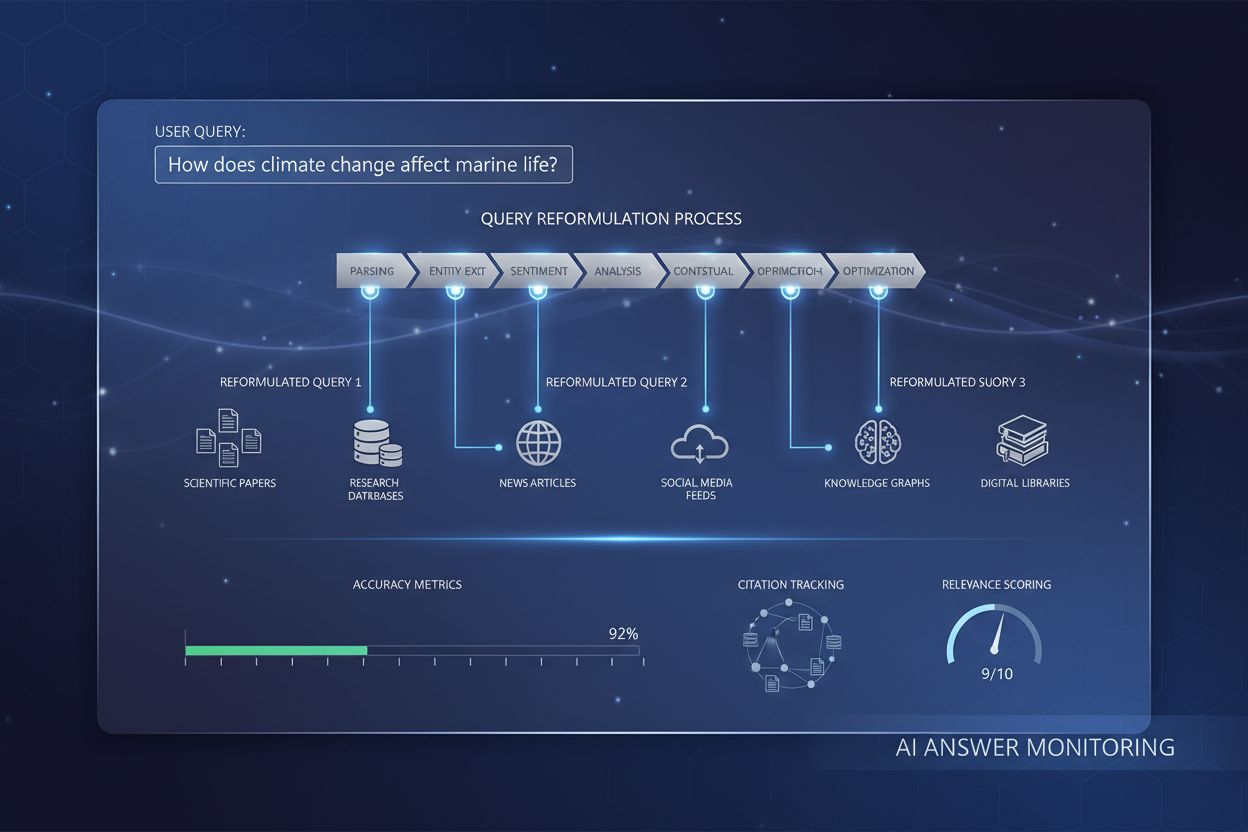
Reformulace dotazu je proces, při kterém systémy umělé inteligence interpretují, restrukturalizují a vylepšují uživatelské dotazy za účelem zlepšení přesnosti a relevance vyhledávání informací. Převádí jednoduché nebo nejednoznačné uživatelské vstupy do podrobnějších, kontextově obohacených verzí, které odpovídají porozumění AI systému a umožňují přesnější a komplexnější odpovědi.
Reformulace dotazu je proces, při kterém systémy umělé inteligence interpretují, restrukturalizují a vylepšují uživatelské dotazy za účelem zlepšení přesnosti a relevance vyhledávání informací. Převádí jednoduché nebo nejednoznačné uživatelské vstupy do podrobnějších, kontextově obohacených verzí, které odpovídají porozumění AI systému a umožňují přesnější a komplexnější odpovědi.
Reformulace dotazu je proces transformace, rozšíření nebo přeformulování původního uživatelského dotazu tak, aby lépe odpovídal schopnostem podkladového systému pro vyhledávání informací a skutečnému záměru uživatele. V kontextu umělé inteligence a zpracování přirozeného jazyka (NLP) reformulace dotazu překonává zásadní propast mezi tím, jak uživatelé přirozeně vyjadřují své potřeby, a tím, jak AI systémy tyto požadavky interpretují a zpracovávají. Tato technika je klíčová v moderních AI systémech, protože uživatelé často formulují dotazy nepřesně, používají doménovou terminologii nekonzistentně, nebo opomíjejí kontextové informace, které by zvýšily přesnost vyhledávání. Reformulace dotazu působí na průsečíku vyhledávání informací, sémantického porozumění a strojového učení a umožňuje systémům generovat relevantnější výsledky reinterpretací dotazů různými pohledy – ať už rozšiřováním o synonyma, kontextovým obohacením nebo strukturální reorganizací. Inteligentní reformulací dotazů mohou AI systémy dramaticky zvýšit kvalitu odpovědí, snížit nejednoznačnost a zajistit, že nalezené informace přesněji odpovídají záměru uživatele.
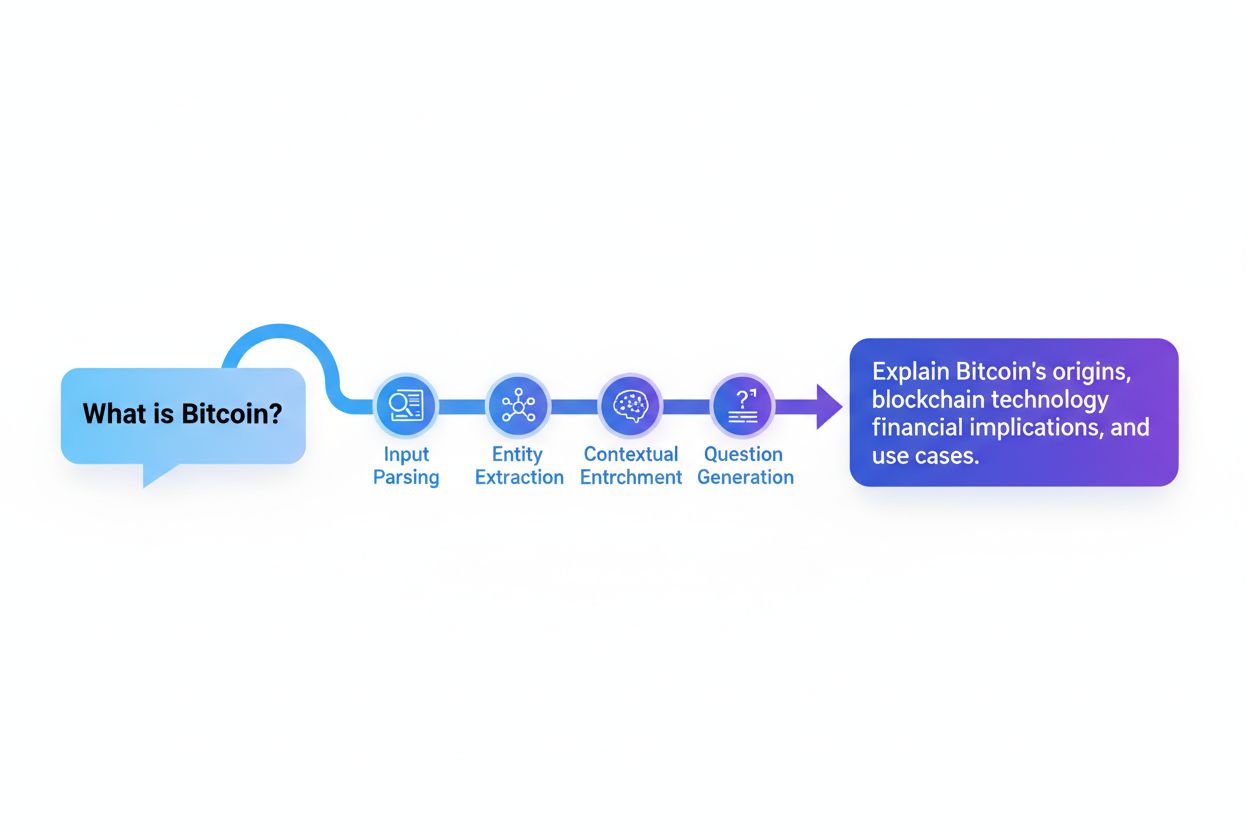
Systémy pro reformulaci dotazů obvykle fungují prostřednictvím pěti vzájemně propojených komponent, které společně převádějí surový uživatelský vstup na optimalizované vyhledávací dotazy. Parsování vstupu rozkládá původní dotaz na jeho jednotlivé části, identifikuje klíčová slova, fráze a strukturální prvky. Extrakce entit rozpozná pojmenované entity (osoby, místa, organizace, produkty) a doménově specifické koncepty, které nesou sémantickou váhu. Analýza sentimentu zachovává emocionální tón nebo hodnotící postoj původního dotazu, aby reformulované verze odrážely původní uživatelskou perspektivu. Kontextová analýza začleňuje historii relace, informace z uživatelského profilu a doménové znalosti k obohacení dotazu o implicitní význam. Generování otázek převádí oznamovací věty nebo fragmenty na dobře strukturované otázky, které systémy pro vyhledávání účinněji zpracují.
| Komponenta | Účel | Příklad |
|---|---|---|
| Parsování vstupu | Tokenizuje a segmentuje dotaz na smysluplné jednotky | “nejlepší Python knihovny” → [“nejlepší”, “Python”, “knihovny”] |
| Extrakce entit | Rozpoznává pojmenované entity a doménové koncepty | “Apple’s latest iPhone” → Entita: Apple (firma), iPhone (produkt) |
| Analýza sentimentu | Zachovává hodnotící tón a uživatelskou perspektivu | “strašný zákaznický servis” → Negativní sentiment zůstává i v reformulaci |
| Kontextová analýza | Zahrnuje historii relace a doménové znalosti | Předchozí dotaz na “machine learning” ovlivňuje aktuální dotaz “neuronové sítě” |
| Generování otázek | Převádí fragmenty na strukturované otázky | “Python debugging” → “Jak mohu ladit kód v Pythonu?” |
Proces reformulace dotazu následuje systematickou šestikrokovou metodologii, která postupně zvyšuje kvalitu a relevanci dotazu:
Parsování a normalizace vstupu
Extrakce entit a konceptů
Zachování sentimentu a záměru
Kontextové obohacení
Rozšíření dotazu a generování synonym
Optimalizace a vyhodnocení
Reformulace dotazu využívá rozmanité techniky od tradičních lexikálních přístupů až po nejmodernější neuronové metody. Rozšiřování na bázi synonym využívá zavedené zdroje jako WordNet, embeddingy slov jako Word2Vec a GloVe a kontextové modely jako BERT k nalezení sémanticky podobných pojmů. Relaxace dotazu postupně uvolňuje omezení dotazu za účelem zvýšení záchytu v případě nedostatečných výsledků – například odstraněním vzácných výrazů nebo rozšířením časových rozsahů. Integrace uživatelské zpětné vazby a kontextu relace umožňuje systémům učit se z interakcí uživatelů a zpřesňovat reformulace podle toho, které výsledky uživatelé považují za relevantní. Transformační přepisovače jako T5 (Text-to-Text Transfer Transformer) a modely GPT generují zcela nové formulace dotazů na základě velkých trénovacích datových sad párových dotazů. Hybridní přístupy kombinují více technik – například použití pravidlového rozšiřování synonym pro výrazy s vysokou důvěrou a neuronových modelů pro nejednoznačné fráze. Reálné implementace často využívají ansámblové metody, které generují více reformulací a řadí je pomocí naučených modelů relevance. Například e-commerce platformy mohou kombinovat doménové slovníky synonym s embeddingy BERT pro pokrytí jak standardizované produktové terminologie, tak hovorového uživatelského jazyka, zatímco medicínské vyhledávací systémy využijí specializované ontologie spolu s transformačními modely pro zajištění klinické přesnosti.
Reformulace dotazu přináší významná zlepšení v několika oblastech výkonu AI systémů a uživatelské zkušenosti:
Zlepšená přesnost vyhledávání: Reformulované dotazy přesněji vystihují záměr uživatele, což vede k vyhledání kvalitnějších dokumentů a relevantnějších AI odpovědí. Rozšířením dotazů o synonyma a příbuzné pojmy systémy najdou dokumenty, které mohou používat odlišnou terminologii než původní dotaz, čímž výrazně roste šance na nalezení skutečně relevantních informací.
Zvýšený záchyt a pokrytí: Rozšíření dotazu zvyšuje počet relevantních dokumentů prozkoumáním sémantických variant a souvisejících pojmů. To je obzvlášť cenné ve specializovaných oborech, kde se terminologie značně liší, a zajišťuje, že uživatelé nepřijdou o relevantní informace kvůli rozdílné slovní zásobě.
Snížení nejednoznačnosti a upřesnění: Reformulace rozptyluje vágní nebo nejednoznačné dotazy začleněním kontextu a generováním více interpretací. Umožňuje systémům zpracovat dotazy typu “apple” (ovoce vs. firma) vygenerováním kontextově specifických reformulací.
Lepší uživatelská zkušenost a spokojenost: Uživatelé dostanou relevantnější výsledky rychleji, což snižuje nutnost opakovaného zadávání dotazů. Méně neúspěšných vyhledávání a přesnější odpovědi hned napoprvé přímo zvyšují spokojenost a snižují kognitivní zátěž.
Škálovatelnost a efektivita: Reformulace umožňuje systémům obsluhovat různorodé uživatelské skupiny s rozdílnou slovní zásobou, úrovní znalostí a jazykovým zázemím. Jeden engine pro reformulaci může obsloužit uživatele napříč doménami i jazyky, což zlepšuje škálovatelnost systému bez nutnosti úměrně navyšovat infrastrukturu.
Průběžné zdokonalování a učení: Systémy pro reformulaci dotazů lze trénovat na uživatelských interakcích, čímž se jejich postupy reformulace neustále zlepšují na základě úspěšnosti předchozích výsledků. Vzniká tak pozitivní cyklus, kdy se výkon systému časem zvyšuje s narůstajícími uživatelskými daty.
Doménová adaptace a specializace: Reformulační techniky lze doladit pro specifické obory (medicína, právo, technika) trénováním na doménově specifických párech dotazů a začleněním doménových ontologií. Díky tomu zvládnou specializované systémy doménovou terminologii přesněji než obecné přístupy.
Odolnost vůči variacím dotazů: Systémy se stávají odolné vůči překlepům, gramatickým chybám i hovorovému jazyku tím, že převádějí dotazy do standardizovaných tvarů. To je zvláště cenné pro hlasové rozhraní a mobilní vyhledávání, kde je kvalita vstupu velmi různorodá.
Reformulace dotazu hraje zásadní roli v přesnosti a spolehlivosti AI odpovědí, a je proto klíčová pro platformy pro monitoring odpovědí AI, jako je AmICited.com. Pokud AI systémy reformulují dotazy před generováním odpovědí, kvalita těchto reformulací přímo ovlivňuje, zda AI získá vhodné zdrojové materiály a vytvoří přesné, správně citované odpovědi. Špatně reformulované dotazy mohou vést k vyhledání irelevantních dokumentů, což způsobí, že AI generuje odpovědi bez odpovídajícího podkladu nebo cituje nevhodné zdroje. V kontextu monitoringu AI a sledování citací je porozumění tomu, jak jsou dotazy reformulovány, zásadní pro ověření, že AI systémy skutečně odpovídají na původní otázku uživatele, nikoli na její zkreslenou interpretaci. AmICited.com sleduje, jak systémy AI reformulují dotazy, aby zajistil, že zdroje uvedené v AI odpovědích jsou opravdu relevantní k původnímu dotazu uživatele, nikoli pouze k špatně reformulovanému dotazu. Tato monitorovací schopnost je zvlášť důležitá, protože reformulace dotazu je pro koncového uživatele neviditelná – vidí pouze finální odpověď a citace, aniž by tušil, jak byl dotaz přetransformován. Analýzou vzorců reformulace mohou monitorovací platformy rozpoznat, kdy AI generuje odpovědi na základě reformulovaných dotazů, které se výrazně odchylují od záměru uživatele, a včas označit potenciální problémy s přesností. Dále porozumění reformulaci pomáhá platformám posoudit, zda AI systémy správně řeší nejednoznačné dotazy generováním více reformulací a syntetizací informací napříč nimi, nebo zda činí nepodložené domněnky o záměru uživatele.
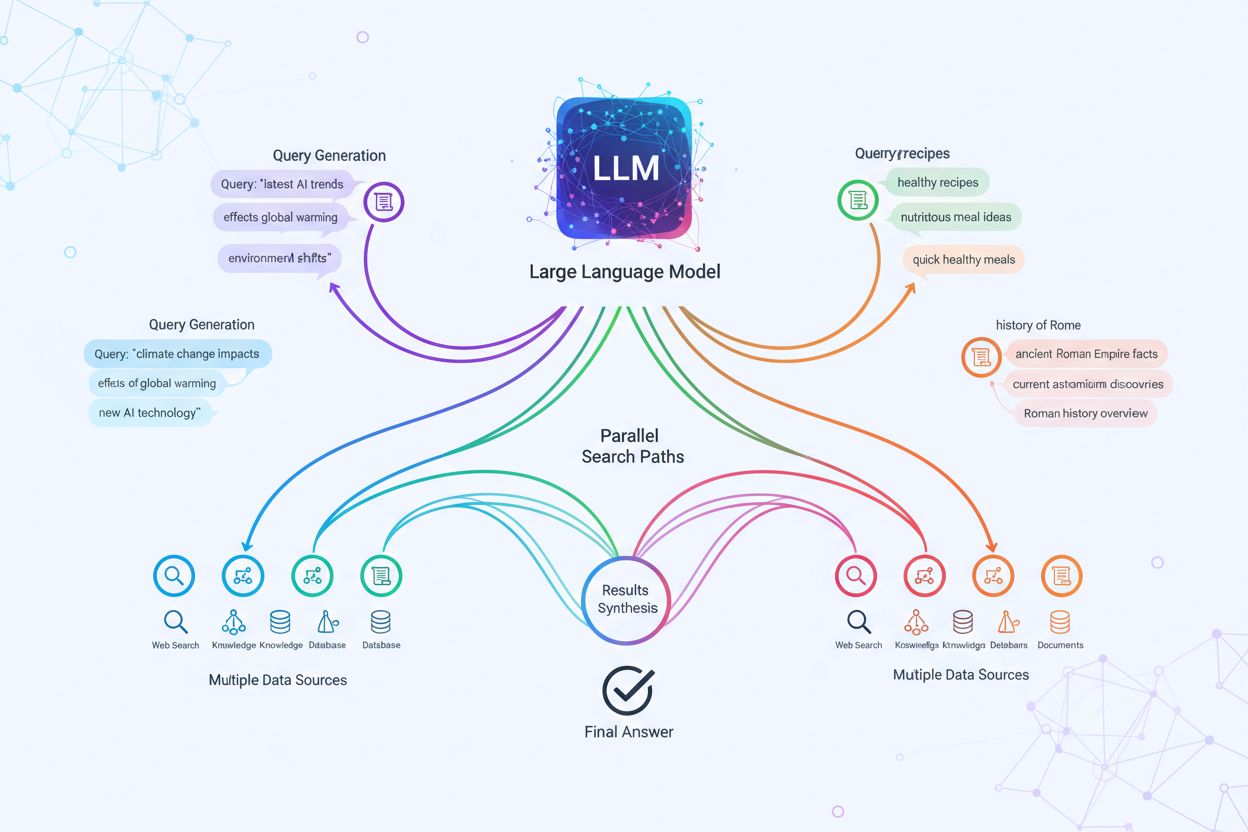
Reformulace dotazu se stala nepostradatelnou v řadě AI aplikací a odvětví. Ve zdravotnictví a medicínském výzkumu řeší složitost lékařské terminologie, kdy pacient hledá “infarkt” a odborná literatura používá “myokardiální infarkt” – reformulace překlenuje tuto slovní propast a umožňuje vyhledat klinicky správné informace. Systémy pro analýzu právních dokumentů využívají reformulaci, aby zvládly přesný a archaický jazyk právních textů i současné hledací výrazy, a zajistily, že právníci najdou relevantní precedenty bez ohledu na formulaci dotazu. Technická podpora reformuluje uživatelské dotazy, aby odpovídaly článkům znalostní báze – převádí hovorové popisy problémů (“můj počítač je pomalý”) na technické pojmy (“snížení výkonu systému”) a najde tak vhodné návody k řešení. E-commerce optimalizace vyhledávání využívá reformulaci dotazů při hledání produktů, kdy uživatel zadá “běžecké boty” a katalog obsahuje “sportovní obuv” nebo konkrétní značky – zákazník tak najde požadované zboží i přes rozdílnou terminologii. Konverzační AI a chatboti používají reformulaci k udržení kontextu v rámci vícekrokových dialogů, reformulují následné otázky tak, aby obsahovaly implicitní kontext předchozí konverzace. Systémy Retrieval-Augmented Generation (RAG) jsou na reformulaci dotazu silně závislé, protože právě ta zajišťuje, že získané kontextové dokumenty jsou opravdu relevantní k uživatelské otázce a přímo ovlivňují kvalitu generovaných odpovědí. Například RAG systém odpovídající na “Jak optimalizuji databázové dotazy?” může tento dotaz reformulovat na více variant, jako “ladění výkonu databázových dotazů”, “techniky optimalizace SQL” a “plány provádění dotazů”, aby získal komplexní kontext před vytvořením podrobné odpovědi.
Navzdory svým výhodám přináší reformulace dotazů několik zásadních výzev, které je třeba pečlivě řešit. Výpočetní složitost výrazně roste při generování a řazení více reformulací – každá reformulace vyžaduje zpracování a systémy musí vyvažovat přínos s požadavky na rychlost, zejména v reálném čase. Kvalita trénovacích dat přímo určuje účinnost reformulace; systémy trénované na nekvalitních nebo zaujatých datech budou tato zkreslení dále šířit, a mohou tak dané problémy spíše zhoršovat než řešit. Riziko nadměrné reformulace nastává, když systém vygeneruje tolik variant dotazu, že ztratí původní záměr a nachází čím dál vzdálenější výsledky, které spíše matou než upřesňují. Doménová adaptace vyžaduje značné úsilí – modely trénované na obecných webových dotazech často v oborových doménách (medicína, právo) bez důkladného přeškolení selhávají. Vyvážení přesnosti a záchytu je základní kompromis: agresivní rozšíření dotazu zvyšuje záchyt, ale může snížit přesnost kvůli irelevantním výsledkům, zatímco konzervativní přístup zachová přesnost, ale přehlédne relevantní dokumenty. Riziko zavedení biasu hrozí, pokud reformulační systém převezme společenská zkreslení z trénovacích dat, a může tak zesílit diskriminaci ve výsledcích vyhledávání či AI odpovědích – například reformulace dotazů “zdravotní sestra” může neúměrně zobrazovat výsledky spojené s ženami, pokud data odrážejí historické genderové stereotypy.
Reformulace dotazů se rychle vyvíjí s rozvojem AI a příchodem nových technik. Pokroky v reformulaci založené na velkých jazykových modelech (LLM) umožňují stále sofistikovanější a kontextově citlivé transformace dotazů, protože tyto modely lépe rozumí nuancím uživatelského záměru a generují přirozené, sémanticky bohaté reformulace. Multimodální AI rozšíří reformulaci dotazů za hranice textu a umožní zpracování dotazů v podobě obrázků, zvuku či videa, kde vizuální dotazy budou přeformulovány do textu, který lze vyhledat. Personalizace a učení umožní reformulačním systémům přizpůsobit se preferencím, slovní zásobě i vzorcům hledání konkrétního uživatele a generovat personalizované reformulace odrážející jeho styl komunikace. Reformulace v reálném čase dovolí systémům dynamicky upravovat dotazy na základě průběžných výsledků vyhledávání a vytvářet zpětnovazební smyčky pro další vylepšení. Integrace znalostních grafů umožní využít strukturované znalosti o entitách a vztazích a generovat sémanticky přesné reformulace opřené o explicitní znalostní reprezentace. Nově vznikající standardy pro hodnocení a benchmarkování reformulace dotazů usnadní srovnání systémů a podpoří zvyšování kvality a konzistence napříč celým odvětvím.
Reformulace dotazu je širší proces transformace dotazu za účelem zlepšení vyhledávání, zatímco rozšíření dotazu je konkrétní technika v rámci reformulace, která přidává synonyma a související pojmy. Rozšíření dotazu se zaměřuje na rozšíření rozsahu vyhledávání, zatímco reformulace zahrnuje více technik, včetně parsování, extrakce entit, analýzy sentimentu a kontextového obohacení, aby se zásadně zlepšila kvalita dotazu.
Reformulace dotazu pomáhá AI systémům lépe pochopit záměr uživatele tím, že objasňuje nejednoznačné pojmy, přidává kontext a generuje více interpretací původního dotazu. To vede k vyhledání relevantnějších zdrojových dokumentů, což umožňuje AI generovat přesnější, lépe podložené odpovědi se správnými citacemi.
Ano, reformulace dotazu může fungovat jako bezpečnostní vrstva standardizací a sanitizací uživatelských vstupů předtím, než se dostanou do hlavního AI systému. Specializovaný agent pro reformulaci dokáže detekovat a neutralizovat potenciálně škodlivé vstupy, filtrovat podezřelé vzory a převádět dotazy do bezpečných, standardizovaných formátů, které snižují zranitelnost vůči útokům typu prompt injection.
V systémech Retrieval-Augmented Generation (RAG) je reformulace dotazu zásadní pro zajištění toho, že získané kontextové dokumenty jsou skutečně relevantní k otázce uživatele. Reformulací dotazů do více variant mohou RAG systémy získat komplexnější a rozmanitější kontext, což přímo zlepšuje kvalitu a přesnost generovaných odpovědí.
Implementace obvykle zahrnuje výběr vhodných technik pro váš případ použití: použijte rozšiřování na bázi synonym s BERT nebo Word2Vec pro sémantickou podobnost, aplikujte transformační modely jako T5 nebo GPT pro neuronovou reformulaci, začleňte doménově specifické ontologie pro specializované obory a implementujte zpětnovazební smyčky pro průběžné zlepšování reformulací na základě interakcí uživatelů a metrik úspěšnosti vyhledávání.
Výpočetní náklady se liší podle techniky: jednoduché rozšiřování pomocí synonym je nenáročné, zatímco reformulace založená na transformerech vyžaduje značné GPU zdroje. Optimalizovat náklady lze použitím menších specializovaných modelů pro reformulaci a větších modelů pouze pro generování finální odpovědi. Mnoho systémů využívá cache a dávkové zpracování pro rozložení výpočetních nákladů mezi více dotazy.
Reformulace dotazu přímo ovlivňuje přesnost citací, protože reformulovaný dotaz určuje, které dokumenty jsou získány a citovány. Pokud se reformulace výrazně odchýlí od původního záměru uživatele, může AI citovat zdroje relevantní k reformulovanému dotazu, nikoliv k původní otázce. Platformy pro monitoring AI, jako je AmICited, sledují tyto transformace, aby zajistily, že citace jsou skutečně relevantní k tomu, na co se uživatelé skutečně ptali.
Ano, reformulace dotazu může zesilovat stávající zkreslení, pokud trénovací data odrážejí společenské předsudky. Například reformulace některých dotazů může neúměrně zobrazovat výsledky spojené s konkrétními demografickými skupinami. Zmírnění tohoto rizika vyžaduje pečlivou přípravu datových sad, mechanismy detekce zkreslení, rozmanité trénovací příklady a průběžné sledování výstupů reformulace z hlediska férovosti a reprezentativnosti.
Reformulace dotazu ovlivňuje, jak systémy AI rozumí a citují váš obsah. AmICited sleduje tyto transformace, aby vaše značka byla správně uvedena v AI generovaných odpovědích.
Upřesnění dotazu je iterativní proces optimalizace vyhledávacích dotazů pro lepší výsledky v AI vyhledávačích. Zjistěte, jak funguje v ChatGPT, Perplexity, Goog...
Objevte, jak moderní AI systémy jako Google AI Mode a ChatGPT rozkládají jeden dotaz na více vyhledávání. Poznejte mechanismy rozvětvení dotazů, dopady na vidit...
Zjistěte více o vzorech AI dotazů – opakujících se strukturách a formulacích, které uživatelé používají při pokládání otázek AI asistentům. Objevte, jak tyto vz...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.