Strukturovaná data
Strukturovaná data jsou standardizované značkování, které pomáhá vyhledávačům porozumět obsahu webových stránek. Zjistěte, jak JSON-LD, schema.org a microdata z...
9 min čtení

Schema markup speciálně navržený tak, aby AI systémy dokázaly přesně porozumět obsahu a správně ho citovat. Strukturovaná data využívají standardizované formáty jako JSON-LD k poskytnutí explicitního kontextu o obsahu stránky, což umožňuje velkým jazykovým modelům spolehlivěji zpracovávat informace a citovat zdroje s větší jistotou.
Schema markup speciálně navržený tak, aby AI systémy dokázaly přesně porozumět obsahu a správně ho citovat. Strukturovaná data využívají standardizované formáty jako JSON-LD k poskytnutí explicitního kontextu o obsahu stránky, což umožňuje velkým jazykovým modelům spolehlivěji zpracovávat informace a citovat zdroje s větší jistotou.
Strukturovaná data pro AI označují organizované, strojově čitelné informace formátované podle standardizovaných schémat, která umožňují systémům umělé inteligence přesně porozumět, interpretovat a využívat obsah. Na rozdíl od nestrukturovaného textu, který vyžaduje složité zpracování přirozeného jazyka k rozpoznání významu, poskytují strukturovaná data explicitní kontext o tom, co informace představují. Tato jasnost je zásadní, protože AI systémy—zejména velké jazykové modely a vyhledávače—zpracovávají denně miliardy datových bodů. Když je obsah strukturován pomocí standardů jako schema.org, JSON-LD nebo microdata, AI okamžitě rozpozná entity, vztahy a atributy bez nejasností. Tento strukturovaný přístup přináší o 300 % vyšší přesnost v porozumění AI ve srovnání s nestrukturovanými alternativami. Pro organizace, které chtějí být viditelné v AI Overviews a dalších AI-generovaných výsledcích, se strukturovaná data stala nepostradatelnou infrastrukturou. Přetvářejí syrový obsah na inteligenci, kterou AI systémy mohou s jistotou citovat, odkazovat a začleňovat do svých odpovědí, což zásadně mění, jak digitální obsah dosahuje objevitelnosti v AI světě.

AI systémy zpracovávají strukturovaná data pomocí sofistikovaného procesu, který přeměňuje označený obsah na využitelnou inteligenci. Když AI narazí na správně formátovaná strukturovaná data, může okamžitě extrahovat klíčové informace bez výpočetní náročnosti potřebné pro interpretaci přirozeného jazyka. Technický mechanismus zahrnuje tyto základní kroky:
Tento proces umožňuje AI dosáhnout o 30 % vyšší viditelnosti v AI Overviews u správně strukturovaného obsahu. Strukturovaný přístup minimalizuje riziko halucinací tím, že ukotvuje odpovědi AI v explicitních, ověřitelných datech místo pravděpodobnostního generování textu. Organizace, které implementují komplexní strategie strukturovaných dat, zaznamenávají měřitelná zlepšení v tom, jak AI systémy objevují, chápou a propagují jejich obsah napříč platformami i aplikacemi.
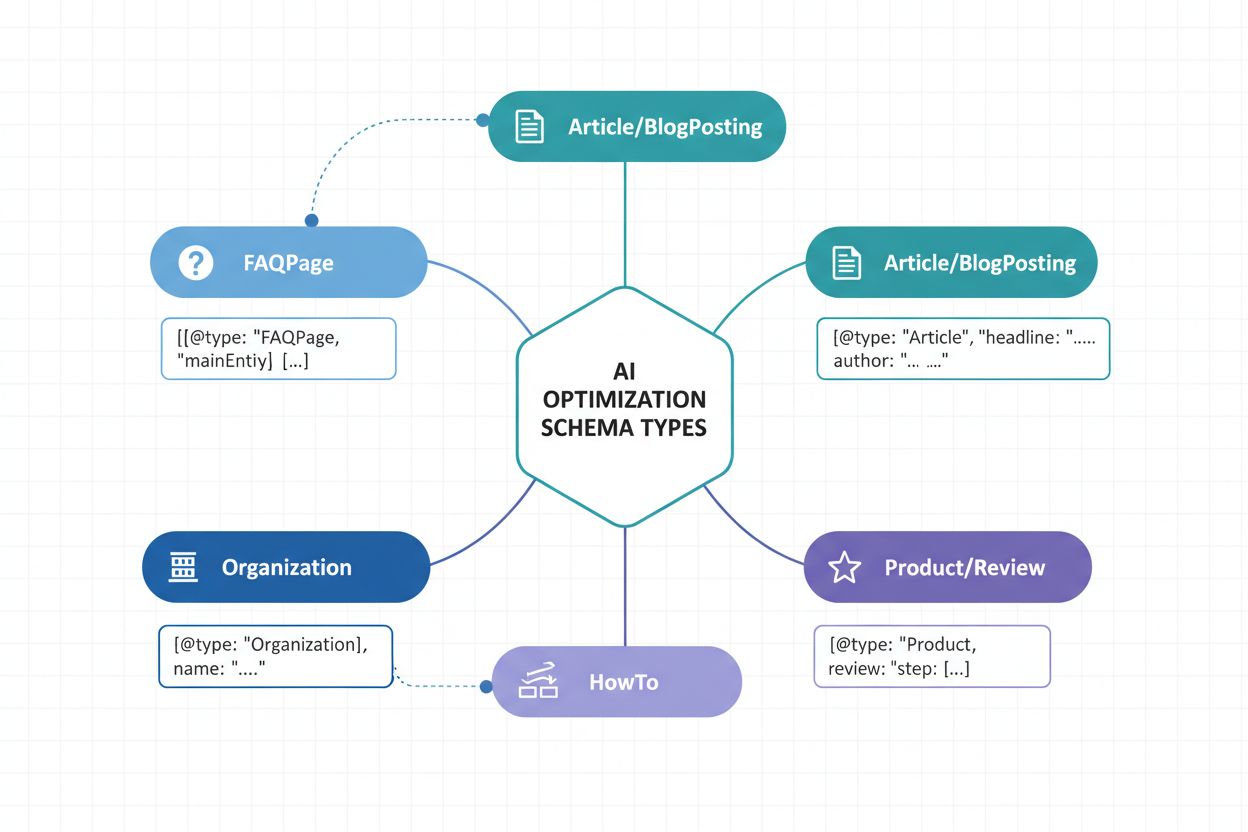
Implementace správných typů schema je základem strategie viditelnosti v AI. Různé typy obsahu vyžadují specifický strukturovaný markup, aby AI systémům sdělily svou povahu a hodnotu. Zde jsou zásadní typy schema pro maximalizaci rozpoznání AI:
Article Schema – Označuje zpravodajské články, blogy a dlouhé texty s titulkem, autorem, datem publikace a hlavním textem. Klíčové pro AI systémy identifikující autoritativní zdroje a určující důvěryhodnost publikace.
Organization Schema – Definuje identitu firmy včetně názvu, loga, kontaktních údajů a sociálních profilů. Umožňuje AI správně rozpoznat a přiřadit obsah organizace napříč různými kontexty.
Product Schema – Strukturuje informace o produktech včetně názvu, popisu, ceny, dostupnosti a recenzí. Nezbytné pro viditelnost v AI asistentkách pro nakupování a doporučovacích systémech.
LocalBusiness Schema – Označuje lokaci firmy, otevírací dobu, kontaktní údaje a služby. Klíčové pro lokální AI dotazy a lokalizované AI Overviews, které stále více dominují výsledkům vyhledávání.
BreadcrumbList Schema – Definuje hierarchii navigace webu a pomáhá AI pochopit strukturu obsahu a vztahy mezi stránkami v rámci vaší informační architektury.
FAQPage Schema – Strukturuje často kladené dotazy a odpovědi, což umožňuje AI přímo extrahovat a citovat konkrétní Q&A obsah ve svých odpovědích.
NewsArticle a BlogPosting Schemas – Specializované typy článků, které signalizují kategorii obsahu AI systémům, zlepšují přesnost kategorizace a relevanci.
Event Schema – Označuje údaje o událostech včetně data, místa, popisu a registračních informací, nezbytné pro AI objevování událostí a integraci do kalendářů.
Aktuálně používá schema.org markup 45 milionů domén, což představuje 12,4 % všech domén globálně. Organizace, které implementují více typů schema současně, zaznamenávají kumulativní přínos ve viditelnosti, protože AI systémy získávají bohatší kontext jejich obsahového ekosystému.
Úspěšná implementace strukturovaných dat vyžaduje strategické plánování a technickou preciznost. Organizace by měly dodržovat tyto zavedené postupy pro maximalizaci viditelnosti v AI a zajištění přesnosti dat:
Zde je praktický příklad JSON-LD pro článek:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Strukturovaná data pro AI: Průvodce strategickou implementací",
"author": {
"@type": "Person",
"name": "Autor obsahu"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Celý text článku zde...",
"publisher": {
"@type": "Organization",
"name": "Vaše organizace",
"logo": "https://example.com/logo.png"
}
}
Správná implementace přináší 35% zlepšení CTR díky rozšířeným výsledkům v tradičním vyhledávání a další výhody s tím, jak se AI Overviews stávají hlavními kanály objevování. Organizace, které sledují výkon svých strukturovaných dat pomocí řešení jako AmICited.com, získávají konkurenční výhodu tím, že identifikují, které typy obsahu a implementace schema přinášejí nejvyšší viditelnost v AI.
Obě metody—strukturovaná data i llms.txt—slouží k objevitelnosti v AI, ale fungují zásadně odlišně. Strukturovaná data využívají standardizovaná schémata (schema.org, JSON-LD) vložená do HTML, aby označila konkrétní prvky obsahu explicitním sémantickým významem. Tento přístup je přímo součástí webových stránek, což umožňuje okamžitý přístup informací jak vyhledávačům, tak AI systémům při procházení obsahu. Strukturovaná data umožňují detailní označení jednotlivých článků, produktů, událostí a organizací, což AI dovoluje pochopit přesné vztahy a atributy.
llms.txt je naopak textový soubor umístěný v kořenovém adresáři webu obsahující instrukce a pokyny pro velké jazykové modely. Funguje jako manifest, který komunikuje preference ohledně toho, jak by AI systémy měly s vaším obsahem pracovat a jak jej citovat. llms.txt poskytuje obecné pokyny ohledně práv k obsahu a preferencí ohledně citací, ale postrádá sémantickou přesnost strukturovaných dat. Strukturovaná data odpovídají na otázku „co je tento obsah?“ explicitními strojově čitelnými odpověďmi, zatímco llms.txt odpovídá „jak by měl být tento obsah použit?“ formou doporučení.
Nejúčinnější strategie kombinuje oba přístupy: strukturovaná data zajišťují, že AI systémy váš obsah přesně pochopí a mohou ho citovat, zatímco llms.txt stanovuje jasná pravidla použití a požadavky na atribuci. Organizace implementující obojí mají o 36 % vyšší pravděpodobnost objevení v AI-generovaných souhrnech oproti těm, které nepoužívají ani jeden přístup. Strukturovaná data tvoří základ pro pochopení AI, zatímco llms.txt poskytuje rámec pro správnou atribuci a soulad s pravidly použití.
Měření efektivity strukturovaných dat vyžaduje sledování specifických metrik, které ukazují, jak AI systémy objevují, chápou a citují váš obsah. Organizace by měly sledovat tyto klíčové ukazatele výkonu:
AmICited.com nabízí specializované sledování výkonu AI citací a umožňuje organizacím zjistit, jak se jejich investice do strukturovaných dat promítají do skutečné AI viditelnosti a atribuce. Platforma ukazuje, který obsah získává AI citace, které dotazy spouštějí váš obsah a jaká je vaše frekvence citací ve srovnání s konkurencí. Tento datově řízený přístup proměňuje implementaci strukturovaných dat z teoretického doporučení na měřitelný obchodní přínos.
Organizace implementující komplexní strategie strukturovaných dat uvádějí, že 93 % dotazů zodpovězených AI proběhne bez kliknutí, což činí viditelnost citací stále důležitější pro generování návštěvnosti. Měření výkonu citací zajišťuje, že vaše investice do strukturovaných dat přinášejí kvantifikovatelné výsledky díky zvýšené AI objevitelnosti a atribuci značky.
Úspěšná implementace strukturovaných dat probíhá v jednotlivých fázích, které postupně budují schopnosti a zároveň přinášejí měřitelné hodnoty v každém kroku. Organizace by měly plánovat implementační časovou osu následovně:
Fáze 1: Základy (měsíce 1-2)
Fáze 2: Rozšíření (měsíce 3-4)
Fáze 3: Optimalizace (měsíce 5-6)
Fáze 4: Strategická integrace (měsíce 7+)
Tato časová osa umožňuje organizacím dosáhnout významného zlepšení AI viditelnosti během 2-3 měsíců a současně budovat komplexní, podnikové infrastrukturu strukturovaných dat. Průkopníci, kteří implementují tuto roadmapu, získávají konkurenční výhodu se vzestupem AI Overviews jako hlavního kanálu pro objevování obsahu.
Strukturovaná data se vyvinula z volitelného SEO vylepšení na zásadní strategickou infrastrukturu v digitálním světě řízeném AI. S tím, jak AI systémy stále více zprostředkovávají, jak lidé objevují informace, čelí organizace bez komplexního schema markupu systematické nevýhodě ve viditelnosti. Tato změna odráží zásadní proměnu toku informací: tradiční vyhledávání vyžadovalo, aby uživatelé klikali na weby, ale AI Overviews odpovídají přímo, takže citace obsahu je novou konkurenční arénou.
Organizace, které implementují strukturovaná data strategicky, si zajišťují dlouhodobý úspěch napříč AI platformami a nově vznikajícími kanály objevování. Investice do této infrastruktury přináší benefity přesahující okamžitou AI viditelnost—strukturovaná data zlepšují interní správu obsahu, umožňují lepší personalizaci, podporují optimalizaci pro hlasové vyhledávání a vytvářejí datová aktiva cenná pro budoucí AI aplikace. Ti, kdo včas vybudují komplexní základy strukturovaných dat, získávají kumulativní výhody, protože AI systémy stále více upřednostňují dobře označený obsah.
Výhodu včasné adopce nelze podcenit. Jak více organizací uznává důležitost strukturovaných dat, stává se jejich implementace nutností pro viditelnost. Organizace, které dnes vybudují robustní infrastrukturu strukturovaných dat, budou dominovat AI-generovaným výsledkům, jakmile tyto kanály dospějí. Naopak organizace, které s implementací otálejí, budou mít čím dál tím větší problém dosáhnout viditelnosti, protože AI systémy se učí upřednostňovat komplexně označený obsah. Strukturovaná data nejsou jen technickou implementací, ale základním strategickým závazkem zůstat objevitelný a citovatelný v AI zprostředkovaném informačním ekosystému.
Strukturovaná data přímo neovlivňují pozice ve výsledcích Google, ale výrazně zlepšují vzhled výsledků díky rozšířeným výpisům (rich snippets), což zvyšuje míru prokliku až o 35 %. Pro AI systémy mají strukturovaná data přímější dopad na to, zda je váš obsah citován v AI generovaných odpovědích.
Ano, AI systémy zpracovávají strukturovaná data jak při tréninku, tak při dotazech v reálném čase. I když OpenAI neuvedl veřejná prohlášení, důkazy naznačují, že GPTBot a další AI crawleři zpracovávají JSON-LD markup. Microsoft oficiálně potvrdil, že AI systémy Bingu používají schema markup pro lepší pochopení obsahu.
JSON-LD je doporučený formát, protože odděluje schema od HTML obsahu a usnadňuje implementaci i údržbu ve velkém měřítku. Google výslovně doporučuje JSON-LD a je méně náchylný k chybám než Microdata nebo RDFa.
Rich snippets se mohou objevit během 1-4 týdnů po implementaci. Zlepšení CTR je často měřitelné do 2 týdnů. U AI citací očekávejte, že základy začnou působit za 4-8 týdnů, přičemž výhody budování autority se kumulují během 3-6 měsíců.
Nejprve dejte přednost schema markup—je ověřený a široce podporovaný. llms.txt je stále vznikající standard s omezeným přijetím AI crawlery. Pokud jste společnost zaměřená na vývojáře s rozsáhlou dokumentací, minimální úsilí na vytvoření llms.txt může být užitečné pro budoucnost.
Začněte s Organization schema na domovské stránce (s vlastnostmi sameAs), poté Article schema na klíčových obsahových stránkách. Dále by mělo následovat FAQPage schema—je nejpříměji využitelné pro AI extrakci. Poté přidejte HowTo schema do návodů a SoftwareApplication schema na produktové stránky.
Jen špatně implementovaný markup škodí výkonu. Pokyny Googlu jsou jasné: používejte relevantní typy schema odpovídající viditelnému obsahu, udržujte ceny a data aktuální a nemarkupujte obsah, který uživatelé nevidí. Vždy ověřte pomocí Google Rich Results Test před zveřejněním.
Strukturovaná data poskytují explicitní kontext, který pomáhá AI systémům pochopit, co informace představují—entity, vztahy, atributy. Tato jasnost umožňuje AI s jistotou extrahovat a citovat váš obsah. LLMs postavené na znalostních grafech dosahují o 300 % vyšší přesnosti oproti těm, které se spoléhají pouze na nestrukturovaná data.
Sledujte, jak AI systémy citují váš obsah napříč ChatGPT, Perplexity, Google AI Overviews a dalšími platformami. Získejte přehled o vaší přítomnosti v AI v reálném čase.
Strukturovaná data jsou standardizované značkování, které pomáhá vyhledávačům porozumět obsahu webových stránek. Zjistěte, jak JSON-LD, schema.org a microdata z...
Komunitní diskuze o tom, zda AI crawlery čtou strukturovaná data. Skutečné zkušenosti SEO profesionálů testujících dopad schema markup na viditelnost v ChatGPT,...
Zjistěte, jak AI crawlery zpracovávají strukturovaná data. Objevte, proč na implementaci JSON-LD záleží pro viditelnost v ChatGPT, Perplexity, Claude a Google A...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.