Schema Markup
Schema markup je standardizovaný kód, který pomáhá vyhledávačům pochopit obsah. Zjistěte, jak strukturovaná data zlepšují SEO, umožňují bohaté výsledky a podpor...
8 min čtení
Strukturovaná data jsou organizované informace formátované pomocí standardizovaných schémat (jako JSON-LD, Microdata nebo RDFa), která pomáhají vyhledávačům a AI systémům porozumět obsahu stránek, umožňují bohaté výsledky a zlepšují viditelnost ve vyhledávání a odpovědích generovaných AI.
Strukturovaná data jsou organizované informace formátované pomocí standardizovaných schémat (jako JSON-LD, Microdata nebo RDFa), která pomáhají vyhledávačům a AI systémům porozumět obsahu stránek, umožňují bohaté výsledky a zlepšují viditelnost ve vyhledávání a odpovědích generovaných AI.
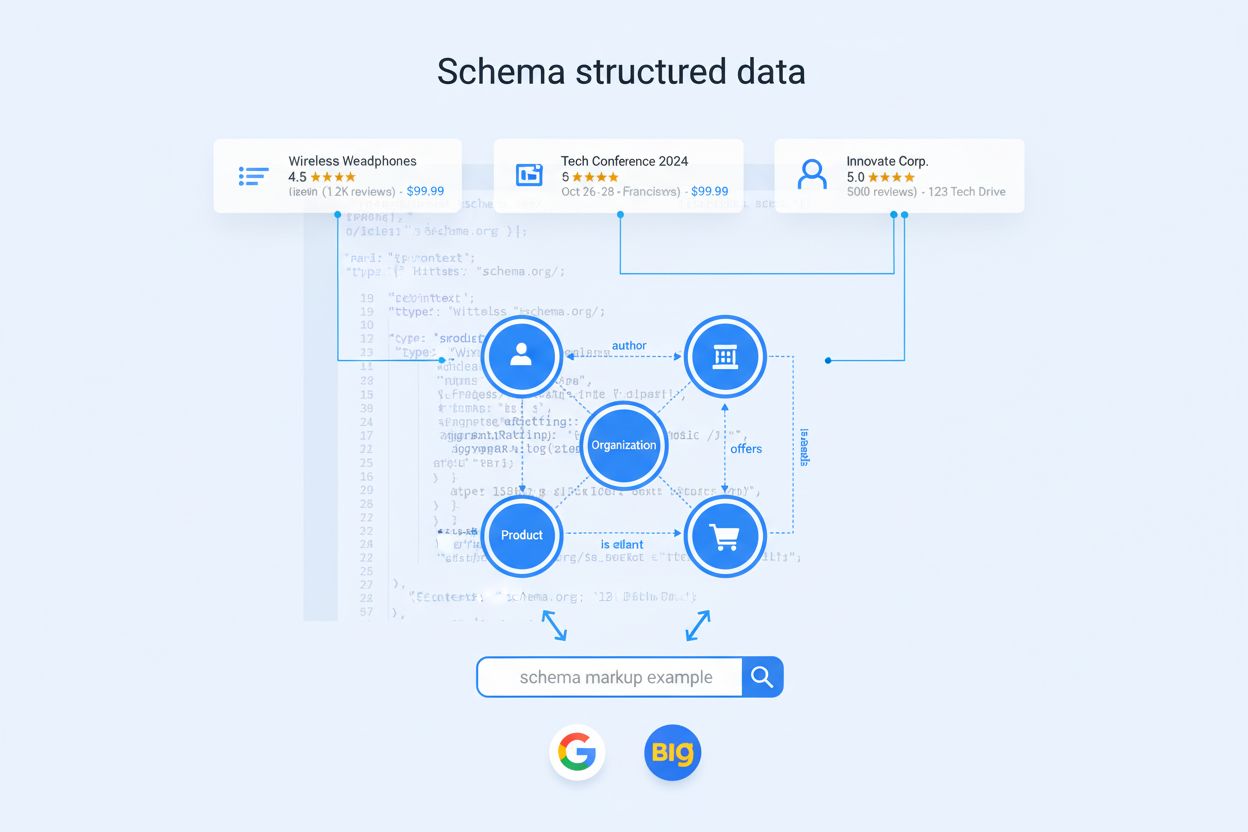
Strukturovaná data jsou standardizovaný formát pro organizaci a prezentaci informací na webových stránkách tak, aby jim vyhledávače a systémy umělé inteligence snadno porozuměly a dokázaly je zpracovat. Na rozdíl od běžného HTML obsahu, který lidé intuitivně čtou, využívají strukturovaná data předdefinovaná schémata a slovníky—nejčastěji ze Schema.org—k jasnému označení a kategorizaci prvků stránky. Toto značkování říká vyhledávačům přesně, jaké informace se na stránce nacházejí, ať už jde o ingredience a čas přípravy receptu, cenu a dostupnost produktu, autora a datum publikace článku nebo místo a informace o vstupenkách na událost. Implementací strukturovaných dat poskytují vlastníci webů vyhledávačům a AI systémům strojově čitelný překlad svého obsahu, což těmto systémům umožňuje chápat kontext, vztahy a význam bez nutnosti analyzovat a interpretovat syrový text. Tato jasnost je stále důležitější, protože se vyhledávání posouvá od prostého porovnávání klíčových slov k sémantickému porozumění a vyhledávače poháněné AI se stávají hlavním faktorem online viditelnosti.
Koncept strukturovaných dat pro webový obsah vznikl z potřeby standardizovat způsob, jakým jsou informace prezentovány napříč internetem. V roce 2011 spojily síly Google, Bing, Yahoo! a Yandex a vytvořily Schema.org, společný slovníkový projekt, který měl poskytovat společný jazyk pro značkování webového obsahu. Tato iniciativa řešila zásadní problém: vyhledávače musely vynakládat obrovské výpočetní zdroje na to, aby pochopily, o čem stránky skutečně jsou, přičemž často docházelo k omylům nebo opomenutí důležitých detailů. Původní slovník Schema.org obsahoval 297 typů obsahu, od té doby se však rozrostl na více než 811 tříd a tisíce vlastností, což odráží rostoucí komplexnost webového obsahu i zvyšující se sofistikovanost vyhledávacích algoritmů. Zavedení JSON-LD (JavaScript Object Notation for Linked Data) jako doporučeného formátu v roce 2014 implementaci výrazně zjednodušilo a umožnilo vývojářům přidávat strukturovaná data bez nutnosti jejich vkládání přímo do HTML obsahu. Podle dat z roku 2024 si RDFa drží 66% zastoupení na webech, JSON-LD dosahuje 41% adopce (meziročně +7 %) a implementace Open Graph činí 64 % (+5 % meziročně). Tento vývoj odráží uznání odvětví, že strukturovaná data už nejsou volitelností, ale nezbytností pro konkurenceschopnou viditelnost v tradičním i nově vznikajícím AI poháněném vyhledávání.
Strukturovaná data lze implementovat třemi hlavními formáty, z nichž každý má své výhody a specifické využití. JSON-LD (JavaScript Object Notation for Linked Data) je doporučovaným formátem Googlu a stal se průmyslovým standardem, protože odděluje značkování od HTML obsahu, což usnadňuje správu a minimalizuje chybovost. JSON-LD lze umístit do sekce <head> nebo <body> HTML stránky a může být dynamicky vkládán pomocí JavaScriptu, což je zvláště užitečné pro redakční systémy, které neumožňují přímé úpravy HTML. Microdata je otevřená HTML specifikace, která vkládá strukturovaná data do HTML obsahu pomocí atributů značek, obvykle v <body> elementu. RDFa (Resource Description Framework in Attributes) je rozšíření HTML5, které přidává atributy HTML značek odpovídající uživatelsky viditelnému obsahu a často se používá jak v <head>, tak <body>. Přestože všechny tři formáty Google akceptuje, JSON-LD se stal preferovanou volbou, protože je nejsnadněji implementovatelný a udržitelný ve velkém měřítku, zejména pro rozsáhlé weby s komplexní strukturou obsahu. Výběr formátu obvykle závisí na technickém nastavení webu, možnostech CMS a vývojářských zdrojích, ale základní princip zůstává stejný: poskytovat explicitní, strojově čitelný kontext o vašem obsahu.
| Aspekt | JSON-LD | Microdata | RDFa | Open Graph |
|---|---|---|---|---|
| Způsob implementace | Oddělený <script> tag | HTML atributy značek | HTML atributy značek | Meta tagy v <head> |
| Umístění | Head nebo body | Element body | Head nebo body | Pouze head |
| Doporučení Google | ✓ Preferováno | Podporováno | Podporováno | Ne pro vyhledávání |
| Dynamické vkládání | ✓ Ano | Ne | Ne | Ne |
| Snadnost údržby | ✓ Vysoká | Střední | Střední | Vysoká |
| Adopce 2024 | 41 % (+7 % YoY) | Součástí RDFa | 66 % (+3 % YoY) | 64 % (+5 % YoY) |
| Hlavní využití | Vyhledávače & AI | Vyhledávače | Vyhledávače | Sociální sítě |
| Kompatibilita s CMS | ✓ Výborná | Dobrá | Dobrá | Výborná |
| Odolnost vůči chybám | ✓ Vysoká | Střední | Střední | Vysoká |
| Podpora bohatých výsledků | ✓ Plná | Plná | Plná | Omezená |
Vyhledávače využívají sofistikované procesy procházení a indexování, aby z webových stránek extrahovaly a využívaly strukturovaná data. Když Googlebot nebo jiný crawler navštíví stránku, analyzuje jak viditelný HTML obsah, tak vložené značkování strukturovaných dat. Crawler identifikuje typ schématu (například Recipe, Product nebo Article) a extrahuje relevantní vlastnosti definované ve značkování. Tyto informace jsou následně zpracovány v systémech porozumění Googlu, které využívají strukturovaná data k tvorbě knowledge graphů—propojených databází entit a jejich vztahů. Například pokud stránka s receptem obsahuje JSON-LD značkování ingrediencí, doby přípravy a nutričních údajů, Google tyto prvky okamžitě pochopí bez nutnosti analyzovat textový obsah stránky. Toto explicitní označení šetří výpočetní zdroje a umožňuje Google zobrazovat bohaté výsledky—vylepšené výpisy ve vyhledávání s dodatečnými informacemi jako hvězdičkové hodnocení, doba vaření nebo ceny produktů přímo ve výsledcích. Tento proces je ještě důležitější u AI poháněných vyhledávačů jako Google AI Overviews a třetích stran jako Perplexity a ChatGPT, které se na strukturovaná data spoléhají pro pochopení kontextu a rozhodování o zahrnutí zdroje do generovaných odpovědí. Výzkumy ukazují, že přes 72 % webů na první stránce Googlu používá schema markup a weby implementující strukturovaná data dosahují o 25–82 % vyšší míry prokliků v bohatých výsledcích oproti standardním výpisům.
Strukturovaná data přímo umožňují bohaté výsledky—vylepšené výpisy ve vyhledávání, které zobrazují další informace nad rámec standardního titulku, URL a meta popisu. Při správné implementaci mohou strukturovaná data spustit různé funkce bohatých výsledků, včetně karet s recepty obsahujících čas vaření a hodnocení, úryvků produktů zobrazujících ceny a dostupnost, výpisů událostí s daty a místy konání a sekcí FAQ s přímými odpověďmi. Tyto bohaté výsledky se obvykle zobrazují nad běžnými textovými výsledky ve výsledcích vyhledávání (SERP), často v podobě karuselů nebo zvýrazněných pozic. Případové studie dokazují reálný dopad: Rotten Tomatoes přidalo strukturovaná data na 100 000 unikátních stránek a zaznamenalo o 25 % vyšší míru prokliků na stránkách s strukturovanými daty oproti stránkám bez nich. Food Network převedl 80 % svých stránek pro využití vyhledávacích funkcí a zaznamenal 35% nárůst návštěvnosti. Nestlé zjistilo, že stránky zobrazované jako bohaté výsledky mají o 82 % vyšší míru prokliků než stránky bez těchto výsledků. Zlepšení vyplývá z lepší vizuální výraznosti, poskytnutí relevantních informací předem a lepší použitelnosti na mobilech oproti standardním výpisům. Je však důležité poznamenat, že Google nezaručuje bohaté výsledky u všech implementací strukturovaných dat—vyhledávač musí vyhodnotit, že značkování je platné, přesné a relevantní k dotazu, než zvýrazněné výsledky zobrazí.
Vzestup vyhledávačů poháněných AI zásadně změnil důležitost strukturovaných dat v digitální strategii viditelnosti. Platformy jako ChatGPT, Perplexity, Google AI Overviews a Claude se spoléhají na strukturovaná data k pochopení kontextu obsahu a rozhodování, které zdroje ocitovat ve svých generovaných odpovědích. Na rozdíl od tradičního vyhledávání založeného na klíčových slovech upřednostňují AI systémy sémantické porozumění a důvěryhodnost zdrojů, díky čemuž jsou jasná, dobře organizovaná strukturovaná data klíčovým signálem. Výzkumy ukazují, že LLM modely zapojené do vyhledávání, jako Google Gemini, používají výsledky vyhledávání pro zakotvení odpovědí, což znamená, že strukturovaná data, která ovlivňují pořadí na Google a Bingu, mohou nepřímo ovlivnit viditelnost v AI vyhledávacích nástrojích. Porovnáním výsledků napříč platformami pro stejný dotaz studie odhalují výrazný překryv mezi bohatými výsledky Google a zdroji citovanými AI vyhledávači—což naznačuje, že optimalizace strukturovaných dat pro tradiční vyhledávání prospívá i AI viditelnosti. Navíc strukturovaná data pomáhají AI systémům budovat knowledge graphy propojující entity a vztahy napříč vaším webem i širším internetem. Tato sémantická organizace je zásadní, aby AI systémy správně pochopily význam a kontext vašeho obsahu, což je zvlášť důležité, jak se AI vyhledávání přesouvá od porovnávání klíčových slov k záměru a kontextově řízeným odpovědím. Organizace, které implementují strukturovaná data napříč svými weby, v podstatě připravují svou viditelnost na současné i budoucí paradigmy vyhledávání.
Efektivní implementace strukturovaných dat vyžaduje dodržování několika klíčových osvědčených postupů, které zajistí maximální přínos a vyhnou se případným penalizacím. Nejprve použijte nejkonkrétnější schéma, které odpovídá vašemu obsahu—například místo obecného “HowTo” použijte pro kuchařský návod konkrétní typ “Recipe”, protože konkrétnost pomáhá vyhledávačům a AI systémům správně kategorizovat a zobrazovat váš obsah. Zadruhé zajistěte přesnost a úplnost—označujte pouze informace, které jsou skutečně viditelné uživatelům na stránce, a poskytněte všechny povinné vlastnosti pro zvolené schéma; neúplné či nepřesné značkování může vyvolat varování nebo zabránit zobrazení bohatých výsledků. Zatřetí ověřujte implementaci pomocí nástroje Google Rich Results Test před nasazením i po něm, abyste identifikovali chyby a zajistili soulad s aktuálními požadavky. Začtvrté implementujte strukturovaná data konzistentně na všechny podobné stránky webu, nikoli pouze na vybrané; tím signalizujete vyhledávačům záměr a systematičnost značkování. Zapáté vyhněte se nadměrnému či nerelevantnímu značkování—používání schémat, která neodpovídají obsahu nebo označování skrytých informací, může vést k ručním penalizacím. Zašesté udržujte značkování aktuální podle vývoje požadavků schematu; Google pravidelně aktualizuje dokumentaci a může přidávat nové povinné či doporučené vlastnosti. Nakonec zohledněte strukturu obsahu—organizujte stránku pomocí jasné hierarchie nadpisů (H1, H2, H3), krátkých zaměřených odstavců a popisných podnadpisů, které signalizují témata, protože tato sémantická organizace pomáhá vyhledávačům i AI systémům chápat vztahy mezi pojmy na stránce.
Role strukturovaných dat v digitální viditelnosti se neustále vyvíjí s tím, jak se vyhledávací technologie zdokonalují a AI se stává ústředním bodem, jak uživatelé objevují informace. Google opakovaně zdůrazňuje význam strukturovaných dat ve své dokumentaci a doporučeních, přičemž John Mueller konkrétně uvádí, že “strukturovaná data pomáhají našim systémům lépe chápat, co je na stránce, což může pomoci zobrazit váš obsah v bohatých výsledcích a dalších speciálních funkcích vyhledávání.” S tím, jak bude přibývat AI poháněných vyhledávacích zážitků, bude strategický význam strukturovaných dat jen růst. Vyhledávače se vzdalují prostému porovnávání klíčových slov směrem k sémantickému porozumění, kde strukturovaná data fungují jako most mezi lidsky čitelným obsahem a strojově interpretovatelným významem. Rozšíření Schema.org ze 297 typů na více než 811 tříd odráží rostoucí potřebu zahrnout stále komplexnější a rozmanitější typy obsahu. Navíc s rozvojem knowledge graphů a vyhledávání založeného na entitách už strukturovaná data nejsou jen o bohatých výsledcích—jde o to, abyste svou značku, produkty a obsah etablovali jako autoritativní entity v širším webovém ekosystému. Organizace, které dnes investují do komplexní implementace strukturovaných dat, si zajišťují viditelnost napříč několika paradigmáty vyhledávání: tradiční Google Search, AI Overviews, AI vyhledávače třetích stran i budoucí inovace ve vyhledávání. Konvergence SEO a optimalizace pro AI vyhledávání znamená, že strukturovaná data se stala základním prvkem moderní digitální strategie, nikoli jen volitelným vylepšením.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Schema markup je standardizovaný kód, který pomáhá vyhledávačům pochopit obsah. Zjistěte, jak strukturovaná data zlepšují SEO, umožňují bohaté výsledky a podpor...

Zjistěte, co je to organizační schéma, jak funguje a proč je důležité pro SEO a viditelnost ve vyhledávání s využitím AI. Kompletní průvodce implementací strukt...
Produktové schéma je strukturované značkování dat, které pomáhá vyhledávačům a AI systémům porozumět detailům o produktech. Naučte se, jak jej implementovat pro...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.