Definice tabulky: Organizovaná data v řádcích a sloupcích
Tabulka je základní datová struktura, která organizuje informace do dvourozměrné mřížky tvořené vodorovnými řádky a svislými sloupci. V nejjednodušší podobě představuje tabulka soubor souvisejících dat uspořádaných strukturovaně, kde každý průsečík řádku a sloupce obsahuje jednu datovou položku nebo buňku. Tabulky slouží jako základ relačních databází, tabulkových procesorů, datových skladů a prakticky všech systémů, které vyžadují organizované ukládání a vyhledávání informací. Síla tabulek spočívá v jejich schopnosti umožnit rychlé vizuální procházení, logické porovnávání dat napříč více dimenzemi a programový přístup ke specifickým informacím prostřednictvím standardizovaných dotazovacích jazyků. Ať už jsou používané v obchodní analytice, vědeckém výzkumu nebo AI monitorovacích platformách, tabulky poskytují univerzálně srozumitelný formát pro prezentaci strukturovaných dat, který snadno interpretují lidé i stroje.
Historický kontext a vývoj organizace tabulkových dat
Koncept organizace informací do řádků a sloupců předchází modernímu počítačovému zpracování o staletí. Starověké civilizace používaly tabulkové formáty k zaznamenávání zásob, finančních transakcí a astronomických pozorování. Formalizace struktur tabulek v informatice však přišla s rozvojem relační databázové teorie Edgarem F. Coddem v roce 1970, která revolučně změnila způsob ukládání a dotazování na data. Relační model stanovil, že data by měla být organizována do tabulek s jasně definovanými vztahy, což zásadně proměnilo principy návrhu databází. V 80. a 90. letech rozšířily použití tabulek aplikace jako Lotus 1-2-3 a Microsoft Excel, čímž zpřístupnily tabulkovou organizaci dat i netechnickým uživatelům. Dnes přibližně 97 % organizací používá tabulkové aplikace pro správu a analýzu dat, což dokládá trvalý význam tabulkové organizace dat. Vývoj pokračuje s moderními kolonárními databázemi, NoSQL systémy a data lake řešeními, které zpochybňují tradiční přístupy orientované na řádky, ale stále zachovávají základní tabulkovou strukturu pro organizaci informací.
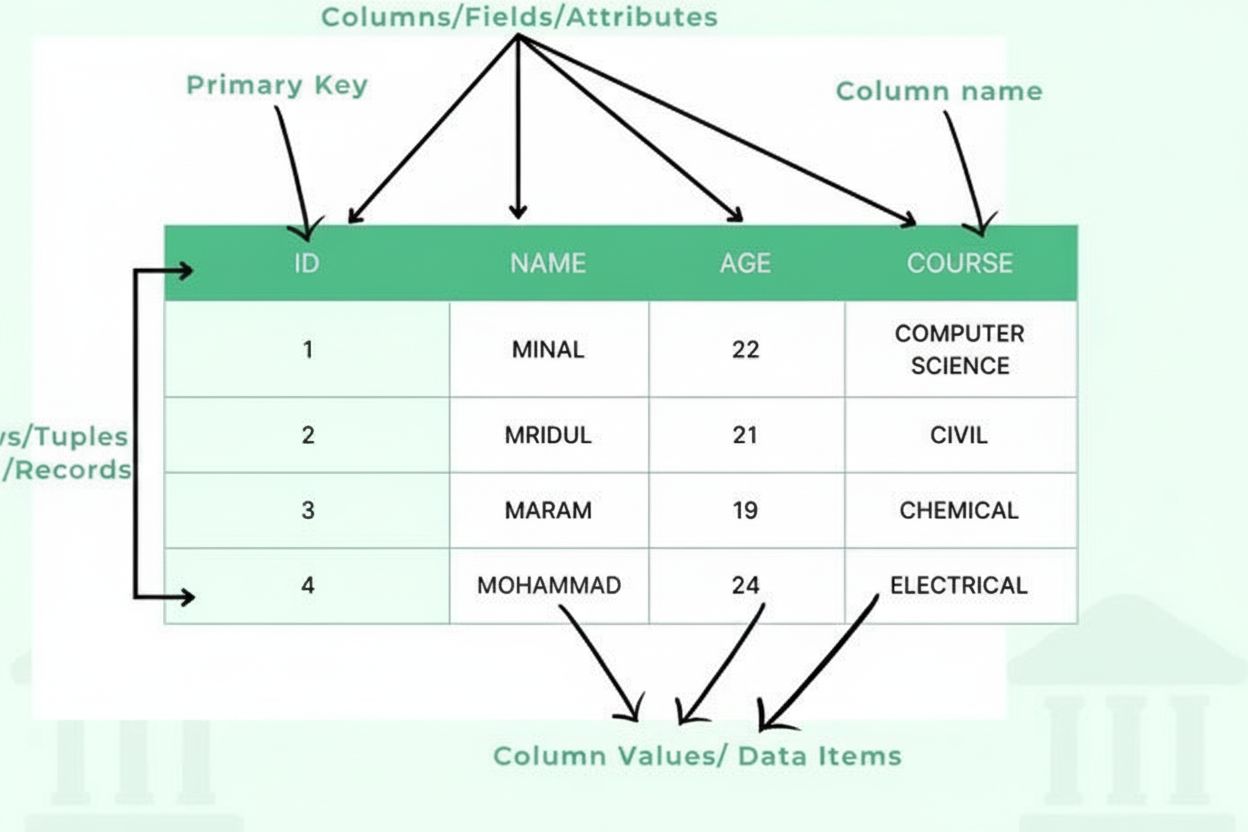
Základní komponenty a struktura tabulek
Tabulka se skládá z několika klíčových strukturálních komponent, které společně vytvářejí organizovaný rámec dat. Sloupce (nazývané také pole nebo atributy) vedou svisle a představují kategorie informací, například „Jméno zákazníka“, „E-mailová adresa“ nebo „Datum nákupu“. Každý sloupec má definovaný datový typ, který určuje, jaký druh informací může obsahovat—celá čísla, textové řetězce, data, desetinná čísla nebo složitější struktury. Řádky (nazývané také záznamy nebo tuples) vedou vodorovně a představují jednotlivé položky nebo entity, přičemž každý řádek obsahuje jeden úplný záznam. Průsečík řádku a sloupce vytváří buňku nebo datovou položku, která obsahuje jednu konkrétní informaci. Hlavičky sloupců identifikují každý sloupec a nacházejí se v horní části tabulky, kde poskytují kontext pro data pod nimi. Primární klíče jsou speciální sloupce, které jednoznačně identifikují každý řádek a zajišťují, že neexistují duplicitní záznamy. Cizí klíče vytvářejí vztahy mezi tabulkami tím, že odkazují na primární klíče v jiných tabulkách. Tato hierarchická organizace umožňuje databázím udržovat integritu dat, předcházet redundanci a podporovat složité dotazy, které získávají informace na základě více kritérií.
Porovnání metod organizace tabulek
| Aspekt | Tabulky orientované na řádky | Tabulky orientované na sloupce | Hybridní přístupy |
|---|
| Způsob ukládání | Data ukládána a zpřístupňována podle celých záznamů | Data ukládána a zpřístupňována podle jednotlivých sloupců | Kombinuje výhody obou přístupů |
| Výkon dotazů | Optimalizováno pro transakční dotazy získávající celé záznamy | Optimalizováno pro analytické dotazy na konkrétní sloupce | Vyvážený výkon pro smíšené zátěže |
| Použití | OLTP (Online Transaction Processing), obchodní operace | OLAP (Online Analytical Processing), datové sklady | Analýza v reálném čase, operační inteligence |
| Příklady databází | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Efektivita komprese | Nižší komprese kvůli různorodosti dat | Vyšší komprese pro podobné hodnoty ve sloupci | Optimalizovaná komprese pro specifické vzory |
| Výkon zápisu | Rychlé zápisy celých záznamů | Pomalejší zápisy vyžadující úpravy sloupců | Vyvážený výkon zápisu |
| Škálovatelnost | Dobře škáluje s objemem transakcí | Dobře škáluje s objemem dat a složitostí dotazů | Škáluje v obou dimenzích |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technická implementace a architektura databází
V relačních databázových systémech (RDBMS) jsou tabulky implementovány jako strukturované kolekce řádků, kde každý řádek odpovídá předem definovanému schématu. Schéma definuje strukturu tabulky, stanovuje názvy sloupců, datové typy, omezení a vztahy. Při vkládání dat do tabulky systém správy databáze ověřuje, že každá hodnota odpovídá typu sloupce a splňuje všechna definovaná omezení. Například sloupec definovaný jako INTEGER odmítne textové hodnoty a sloupec označený jako NOT NULL odmítne prázdné položky. Indexy jsou vytvářeny na často dotazovaných sloupcích pro urychlení vyhledávání dat; fungují jako organizované odkazy, které umožňují databázi najít konkrétní řádky bez procházení celé tabulky. Normalizace je koncepce návrhu, která organizuje tabulky tak, aby minimalizovala redundanci a zlepšila integritu dat rozčleněním informací do vzájemně propojených tabulek prostřednictvím klíčů. Moderní databáze podporují transakce, které zajišťují, že více operací nad tabulkami buď všechny uspějí, nebo všechny selžou, čímž zachovávají konzistenci i při selhání systému. Optimalizátor dotazů v databázových enginech analyzuje SQL dotazy a určuje nejefektivnější způsob přístupu k datům v tabulkách s ohledem na dostupné indexy a statistiky tabulek.
Prezentace a vizualizace dat v tabulkách
Tabulky slouží jako hlavní mechanismus pro prezentaci strukturovaných dat uživatelům v digitální i tištěné podobě. V aplikacích business intelligence a analytiky zobrazují tabulky agregované metriky, výkonnostní indikátory a detailní záznamy transakcí, které umožňují rozhodovatelům rychle porozumět složitým datovým sadám. Výzkumy ukazují, že 83 % obchodních profesionálů spoléhá na datové tabulky jako na hlavní nástroj pro analýzu informací, protože tabulky umožňují přesné porovnání hodnot a rozpoznání vzorců. HTML tabulky na webových stránkách využívají sémantické značky <table>, <tr> (řádek tabulky), <td> (datová buňka) a <th> (hlavička tabulky) pro strukturování dat jak pro vizuální zobrazení, tak pro programovou interpretaci. Tabulkové procesory jako Microsoft Excel, Google Sheets a LibreOffice Calc rozšiřují základní funkčnost tabulek o vzorce, podmíněné formátování a kontingenční tabulky, které uživatelům umožňují provádět výpočty a dynamicky reorganizovat data. Nejlepší postupy vizualizace dat doporučují používat tabulky tam, kde jsou důležitější přesné hodnoty než vizuální vzory, při porovnávání více atributů jednotlivých záznamů či při potřebě vyhledávání nebo výpočtů. W3C Web Accessibility Initiative zdůrazňuje, že správně strukturované tabulky s jasnými hlavičkami a vhodným značkováním jsou zásadní pro zpřístupnění dat uživatelům se zdravotním postižením, zejména těm, kteří používají čtečky obrazovky.
Tabulky v AI monitoringu a sledování obsahu
V kontextu AI monitorovacích platforem jako AmICited hrají tabulky zásadní roli v organizaci a prezentaci dat o tom, jak se obsah zobrazuje v různých AI systémech. Monitorovací tabulky sledují metriky jako frekvence citací, data výskytu, zdroje AI platforem (ChatGPT, Perplexity, Google AI Overviews, Claude) a kontextové informace o tom, jak jsou domény a URL adresy odkazovány. Tyto tabulky umožňují organizacím pochopit svou viditelnost značky v AI generovaných odpovědích a identifikovat trendy v tom, jak různé AI systémy citují nebo odkazují jejich obsah. Strukturovaná povaha monitorovacích tabulek umožňuje filtrování, třídění a agregaci citačních dat, což umožňuje odpovídat na otázky typu „Které naše URL se objevují nejčastěji v odpovědích Perplexity?“ nebo „Jak se změnila naše míra citací za poslední měsíc?“. Datové tabulky v monitorovacích systémech také usnadňují porovnávání napříč více dimenzemi—porovnání citačních vzorců mezi různými AI platformami, analýzu růstu citací v čase nebo identifikaci typů obsahu, které získávají nejvíce AI referencí. Možnost exportovat monitorovací data z tabulek do reportů, dashboardů a dalších analytických nástrojů činí tabulky nepostradatelnými pro organizace, které chtějí porozumět a optimalizovat svou přítomnost v AI generovaném obsahu.
Nejlepší postupy pro návrh a organizaci tabulek
Efektivní návrh tabulek vyžaduje pečlivé zvážení struktury, pojmenování a principů organizace dat. Pojmenování sloupců by mělo používat jasné, popisné identifikátory, které přesně vystihují obsah dat, a vyhýbat se zkratkám, které by mohly uživatele či vývojáře mást. Volba datových typů je klíčová—správné typy brání zadávání neplatných dat a umožňují řádné třídění a porovnávání. Definice primárního klíče zajišťuje, že každý řádek lze jednoznačně identifikovat, což je zásadní pro integritu dat a vytváření vztahů s dalšími tabulkami. Normalizace snižuje datovou redundanci tím, že informace organizuje do souvisejících tabulek místo ukládání duplicit napříč více místy. Strategie indexování by měla vyvažovat rychlost dotazů s nároky na údržbu indexů při úpravách dat. Dokumentace struktury tabulky, včetně definic sloupců, datových typů, omezení a vztahů, je důležitá pro dlouhodobou udržitelnost. Kontrola přístupu by měla být nastavena tak, aby byla citlivá data v tabulkách chráněna před neoprávněným přístupem. Optimalizace výkonu zahrnuje sledování doby provádění dotazů a úpravu struktury tabulek, indexů nebo samotných dotazů ke zvýšení efektivity. Zálohování a obnova musí být nastaveny k ochraně tabulkových dat před ztrátou či poškozením.
Klíčové aspekty organizace a správy tabulek
- Strukturální komponenty: Tabulky se skládají ze sloupců (polí), řádků (záznamů), hlaviček, datových položek (buněk), datových typů, primárních a cizích klíčů, které společně vytvářejí organizovanou datovou strukturu
- Integrita dat: Omezení, validační pravidla a vztahy mezi klíči zajišťují přesnost dat a předcházejí nekonzistencím či duplicitám
- Efektivita dotazů: Správné indexování, normalizace a optimalizace dotazů umožňují rychlé získávání specifických informací z velkých tabulek
- Přístupnost: Sémantické HTML značkování, jasné hlavičky a správná struktura zpřístupňují tabulky uživatelům se zdravotním postižením i asistenční technologií
- Škálovatelnost: Dobře navržené tabulky zvládají rostoucí objem dat díky vhodnému indexování, dělení (partitioning) a optimalizaci databáze
- Správa vztahů: Cizí klíče propojují tabulky, což umožňuje složité dotazy kombinující informace z více zdrojů
- Vynucování datových typů: Definované datové typy zajišťují, že v každém sloupci jsou uloženy pouze platné informace, což zabraňuje chybám a umožňuje správné třídění
- Dokumentace a údržba: Jasná dokumentace struktury tabulek a pravidelná údržba zajišťují dlouhodobou použitelnost a výkon
Vývoj a budoucnost organizace dat na bázi tabulek
Budoucnost organizace dat na bázi tabulek se vyvíjí tak, aby splnila stále složitější požadavky na data, přičemž zachovává základní principy, díky nimž jsou tabulky efektivní. Kolonární formáty ukládání jako Apache Parquet a ORC se stávají standardem v prostředí big data, optimalizují tabulky pro analytické úlohy a zároveň zachovávají tabulkovou strukturu. Polostrukturovaná data ve formátech JSON a XML jsou stále častěji ukládána do sloupců tabulek, což umožňuje tabulkám pojmout jak strukturovaná, tak flexibilní data. Integrace strojového učení umožňuje databázím automaticky optimalizovat struktury tabulek a provádění dotazů na základě vzorců používání. Platformy pro analýzu v reálném čase rozšiřují tabulky o podporu streamovaných dat a průběžných aktualizací, čímž překračují tradiční dávkové operace s tabulkami. Cloudové databáze přepracovávají implementaci tabulek tak, aby využívaly distribuované výpočty a umožnily škálování tabulek napříč více servery i geografickými oblastmi. Rámce pro správu dat kladou větší důraz na metadata tabulek, sledování původu a metriky kvality pro zajištění spolehlivosti dat. Nástup AI poháněných datových platforem přináší nové příležitosti, jak mohou tabulky sloužit jako strukturované zdroje pro trénink modelů strojového učení, zároveň však vyvolává otázky, jak tabulky navrhovat pro poskytování kvalitních tréninkových dat. Jak organizace dále generují exponenciálně více dat, tabulky zůstávají základní strukturou pro organizaci, dotazování a analýzu informací, přičemž inovace směřují k lepšímu výkonu, škálovatelnosti a integraci s moderními datovými technologiemi.