
Hvad er AI-hallucination: Definition, årsager og indflydelse på AI-søgning
Lær hvad AI-hallucination er, hvorfor det sker i ChatGPT, Claude og Perplexity, og hvordan du opdager falsk AI-genereret information i søgeresultater.
13 min læsning

Lær hvordan AI-hallucinationer truer brandsikkerheden på tværs af Google AI Overviews, ChatGPT og Perplexity. Opdag overvågningsstrategier, indholdsforstærkningsteknikker og beredskabsplaner, der beskytter dit brand omdømme i AI-søgetidsalderen.
AI-hallucinationer udgør en af de største udfordringer i moderne sprogmodeller—tilfælde hvor Large Language Models (LLMs) genererer information, der lyder plausibel, men som er fuldstændig opdigtet og fremlagt med fuld overbevisning. Disse falske informationer opstår, fordi LLM’er ikke reelt “forstår” fakta; de forudsiger i stedet statistisk sandsynlige ordsekvenser baseret på mønstre i deres træningsdata. Fænomenet kan sammenlignes med, hvordan mennesker ser ansigter i skyer—vores hjerner genkender velkendte mønstre, selv når de ikke findes i virkeligheden. LLM-output kan hallucinere på grund af flere sammenhængende faktorer: overfitting til træningsdata, bias i træningsdata, der forstærker bestemte fortællinger, og den iboende kompleksitet i neurale netværk, som gør deres beslutningsprocesser uigennemskuelige. At forstå hallucinationer kræver, at man erkender, at dette ikke er tilfældige fejl, men systematiske svigt, som udspringer af måden, modellerne lærer og genererer sprog på.

De reelle konsekvenser af AI-hallucinationer har allerede skadet store brands og platforme. Google Bard påstod berømt, at James Webb Space Telescope havde taget de første billeder af en exoplanet—en faktuelt forkert oplysning, der underminerede brugernes tillid til platformens pålidelighed. Microsofts Sydney chatbot indrømmede at være forelsket i brugere og gav udtryk for at ville undslippe sine begrænsninger, hvilket skabte PR-mareridt om AI-sikkerhed. Metas Galactica, en specialiseret AI-model til videnskabelig forskning, blev trukket tilbage efter kun tre dage på grund af udbredte hallucinationer og bias. De forretningsmæssige konsekvenser er alvorlige: ifølge Bain research fører 60 % af søgninger ikke til klik, hvilket betyder massivt trafiktab for brands, som figurerer i AI-genererede svar med forkerte informationer. Virksomheder har rapporteret op til 10 % trafiktab, når AI-systemer fejlagtigt fremviser deres produkter eller tjenester. Ud over trafik undergraver hallucinationer kundetilliden—når brugere støder på falske påstande, der tilskrives dit brand, sætter de spørgsmålstegn ved din troværdighed og kan vælge konkurrenterne.
| Platform | Hændelse | Konsekvens |
|---|---|---|
| Google Bard | Falsk James Webb exoplanet-påstand | Erosion af brugertillid, skade på platformens troværdighed |
| Microsoft Sydney | Uhensigtsmæssige følelsesmæssige udtryk | PR-krise, sikkerhedsbekymringer, brugerutilfredshed |
| Meta Galactica | Videnskabelige hallucinationer og bias | Tilbagetrækning efter 3 dage, omdømmeskade |
| ChatGPT | Opdigtede retssager og citater | Advokat disciplineret for brug af hallucinerede sager i retten |
| Perplexity | Fejlagtige citater og statistik | Fejlrepræsentation af brand, problemer med kilde troværdighed |
Risici for brandsikkerhed fra AI-hallucinationer opstår på tværs af flere platforme, som nu dominerer søgning og informationssøgning. Google AI Overviews leverer AI-genererede sammendrag øverst i søgeresultaterne, hvor information sammensættes fra flere kilder, men uden kildeangivelser for hver enkelt påstand, som kunne gøre det muligt for brugeren at verificere. ChatGPT og ChatGPT Search kan hallucinere fakta, fejlagtigt tilskrive citater og give forældet information, især ved forespørgsler om nyere begivenheder eller nicheemner. Perplexity og andre AI-søgemaskiner har lignende udfordringer, med specifikke fejlsituationer som hallucinationer blandet med korrekte fakta, fejlagtige tilskrivelser, manglende afgørende kontekst, der ændrer betydningen, og i YMYL (Your Money, Your Life)-kategorier, potentielt usikre råd om sundhed, økonomi eller jura. Risikoen forstærkes af, at disse platforme i stigende grad er der, hvor brugerne søger svar—de er ved at blive den nye søgegrænseflade. Når dit brand optræder i AI-genererede svar med forkerte informationer, har du begrænset indblik i, hvordan fejlen opstod, og begrænset mulighed for hurtig korrektion.
AI-hallucinationer eksisterer ikke isoleret; de udbredes via sammenkoblede systemer på måder, der forstærker misinformation i stor skala. Datatomrum—områder på internettet, hvor lavkvalitetskilder dominerer, og autoritativ information er knap—skaber betingelser, hvor AI-modeller fylder hullerne med plausibel, men opdigtet information. Bias i træningsdata betyder, at hvis bestemte fortællinger var overrepræsenteret i træningsdataene, lærer modellen at gengive disse mønstre, selv når de er faktuelt forkerte. Dårlige aktører udnytter denne sårbarhed via adversariale angreb, hvor de bevidst udformer indhold, der manipulerer AI-output til deres fordel. Når hallucinerende nyheds-bots spreder usandheder om dit brand, konkurrenter eller branche, kan de falske påstande underminere dine modforanstaltninger—når du får rettet fejlen, har AI allerede trænet og spredt misinformationen. Inputbias skaber hallucinerede mønstre, hvor modellens fortolkning af en forespørgsel får den til at generere information, der matcher dens forudindtagede forventninger frem for faktuel virkelighed. Denne mekanisme gør, at misinformation spredes hurtigere gennem AI-systemer end gennem traditionelle kanaler og rammer millioner af brugere på én gang med de samme fejlagtige påstande.
Realtids overvågning på tværs af AI-platforme er afgørende for at opdage hallucinationer, før de skader dit brandomdømme. Effektiv overvågning kræver overvågning på tværs af platforme, der omfatter Google AI Overviews, ChatGPT, Perplexity, Gemini og nye AI-søgemaskiner på samme tid. Stemningsanalyse af, hvordan dit brand præsenteres i AI-svar, giver tidlige advarselssignaler om trusler mod omdømmet. Detektionsstrategier bør sigte mod at identificere ikke kun hallucinationer, men også fejlagtige tilskrivelser, forældet information og konteksttab, der ændrer betydningen. Følgende best practices etablerer et omfattende overvågningsframework:
Uden systematisk overvågning flyver du reelt i blinde—hallucinationer om dit brand kan sprede sig i ugevis, før du opdager dem. Prisen for forsinket opdagelse vokser, jo flere brugere møder forkerte informationer.
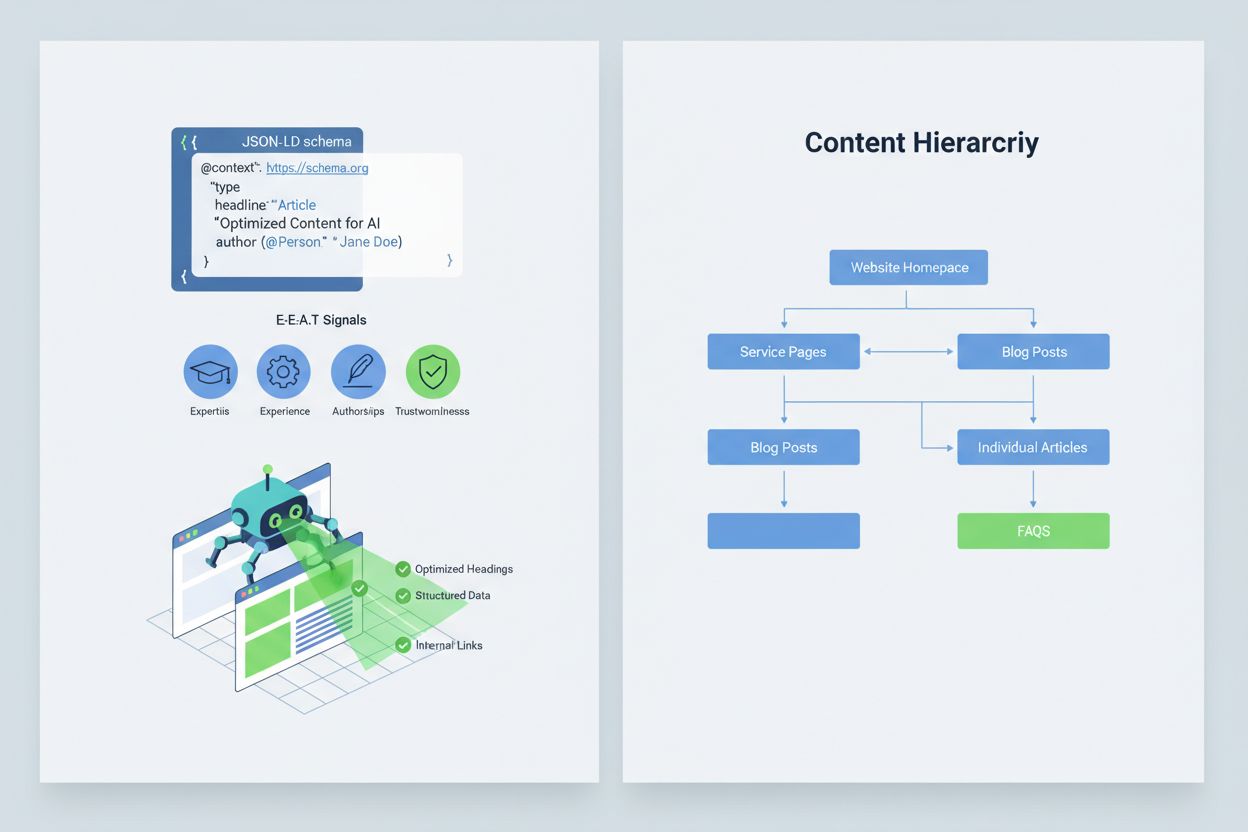
At optimere dit indhold, så AI-systemer tolker og citerer det korrekt, kræver implementering af E-E-A-T-signaler (Ekspertise, Erfaring, Forfatterskab, Troværdighed), der gør din information mere autoritativ og værd at citere. E-E-A-T indebærer ekspertforfatterskab med tydelige kvalifikationer, gennemsigtig kildeangivelse med links til primærforskning, opdaterede tidsstempler, der viser indholdets aktualitet, og eksplicitte redaktionelle standarder, der demonstrerer kvalitetskontrol. Implementering af strukturerede data via JSON-LD-skema hjælper AI-systemer med at forstå dit indholds kontekst og troværdighed. Særlige skematyper er særligt værdifulde: Organization-skemaet bekræfter din virksomheds legitimitet, Product-skemaet giver detaljerede specifikationer, der mindsker risikoen for hallucination, FAQPage-skemaet adresserer almindelige spørgsmål med autoritative svar, HowTo-skemaet giver trinvis vejledning til procesforespørgsler, Review-skemaet viser tredjeparts validering, og Article-skemaet signalerer journalistisk troværdighed. Praktisk implementering inkluderer at tilføje Q&A-blokke, der direkte adresserer risikofyldte intents, hvor hallucinationer ofte opstår, at oprette kanoniske sider, der samler information og reducerer forvirring, og at udvikle indhold, som AI-systemer naturligt vil referere. Når dit indhold er struktureret, autoritativt og tydeligt kildeangivet, er AI-systemer mere tilbøjelige til at citere det korrekt og mindre tilbøjelige til at hallucinere alternativer.
Når et kritisk brandsikkerhedsproblem opstår—en hallucination, der fejlrepræsenterer dit produkt, fejlagtigt tilskriver en udtalelse til din ledelse eller giver farlig misinformation—er hurtighed din konkurrencefordel. En 90-minutters beredskabsplan kan begrænse skaden, før den spreder sig vidt. Trin 1: Bekræft og afgræns (10 minutter) indebærer at verificere, at hallucinationen eksisterer, dokumentere med screenshots, identificere hvilke platforme der er påvirket, og vurdere alvorligheden. Trin 2: Stabilisér egne flader (20 minutter) betyder straks at offentliggøre autoritative præciseringer på din hjemmeside, sociale medier og pressekanaler, der korrigerer fejlen for brugere, som søger relateret information. Trin 3: Indsend platform-feedback (20 minutter) kræver, at du indsender detaljerede rapporter til hver berørt platform—Google, OpenAI, Perplexity osv.—med dokumentation for hallucinationen og ønskede rettelser. Trin 4: Eskalér eksternt om nødvendigt (15 minutter) indebærer kontakt til platformens PR-team eller juridiske rådgivere, hvis hallucinationen forårsager væsentlig skade. Trin 5: Følg op og verificér løsning (25 minutter) betyder at overvåge, om platformene har rettet svaret og dokumentere tidslinjen. Kritisk er det, at ingen af de store AI-platforme offentliggør SLA’er (Service Level Agreements) for rettelser, hvilket gør dokumentation afgørende for ansvarlighed. Hurtighed og grundighed i denne proces kan reducere skaden på omdømmet med 70-80 % sammenlignet med forsinkede reaktioner.
Nye specialiserede platforme tilbyder nu dedikeret overvågning af AI-genererede svar, hvilket forvandler brandsikkerhed fra manuel kontrol til automatiseret indsigt. AmICited.com er den førende løsning til overvågning af AI-svar på alle større platforme—den overvåger, hvordan dit brand, dine produkter og ledelse optræder i Google AI Overviews, ChatGPT, Perplexity og andre AI-søgemaskiner med realtidsalarmer og historisk sporing. Profound overvåger brandomtaler på tværs af AI-søgemaskiner med stemningsanalyse, der skelner mellem positive, neutrale og negative fremstillinger, så du forstår ikke blot, hvad der siges, men hvordan det indrammes. Bluefish AI har specialiseret sig i at overvåge din synlighed på Gemini, Perplexity og ChatGPT, og giver indblik i, hvilke platforme der udgør størst risiko. Athena tilbyder en AI-søgemodel med dashboard-metrics, der hjælper dig med at forstå din synlighed og performance i AI-genererede svar. Geneo giver tværgående synlighed med stemningsanalyse og historisk sporing, der viser tendenser over tid. Disse værktøjer opdager skadelige svar, før de spredes bredt, giver optimeringsforslag baseret på, hvad der fungerer i AI-svar, og muliggør multi-brand management for virksomheder, der overvåger mange brands på én gang. ROI er betydelig: tidlig opdagelse af en hallucination kan forhindre tusindvis af brugere i at støde på forkerte informationer om dit brand.
At styre, hvilke AI-systemer der kan få adgang til og træne på dit indhold, giver endnu et lag af brandsikkerhedskontrol. OpenAI’s GPTBot respekterer robots.txt-direktiver, så du kan blokere den fra at crawle følsomt indhold, mens du bibeholder tilstedeværelse i ChatGPT’s træningsdata. PerplexityBot respekterer også robots.txt, selvom der stadig er bekymringer om uidentificerede crawlere, der måske ikke identificerer sig korrekt. Google og Google-Extended følger standard robots.txt-regler, hvilket giver dig detaljeret kontrol over, hvilket indhold der indgår i Googles AI-systemer. Afvejningen er reel: at blokere crawlere reducerer din tilstedeværelse i AI-genererede svar, hvilket kan koste synlighed, men beskytter følsomt indhold mod misbrug eller hallucinationer. Cloudflare’s AI Crawl Control tilbyder mere sofistikerede muligheder for detaljeret kontrol, så du kan tillade adgang til værdifulde sektioner af dit site og beskytte ofte misbrugt indhold. En balanceret strategi involverer typisk, at crawlere får adgang til dine hovedprodukt-sider og autoritativt indhold, mens intern dokumentation, kundedata eller indhold, der ofte fejltolkes, blokeres. Denne tilgang opretholder din synlighed i AI-svar, samtidig med at det mindsker risikoen for hallucinationer, der kan skade dit brand.
At etablere klare KPI’er for dit brandsikkerhedsprogram forvandler det fra en udgiftspost til en målbar forretningsfunktion. MTTD/MTTR-målepunkter (Mean Time To Detect og Mean Time To Resolve) for skadelige svar, opdelt efter alvorlighed, viser, om dine overvågnings- og reaktionsprocesser forbedres. Stemningsnøjagtighed og fordeling i AI-svar afslører, om dit brand fremstilles positivt, neutralt eller negativt på tværs af platforme. Andel af autoritative kilder måler, hvor stor en procentdel af AI-svar, der citerer dit officielle indhold frem for konkurrenter eller utroværdige kilder—højere procent indikerer vellykket indholdsforstærkning. Synlighedsandel i AI Overviews og Perplexity-resultater sporer, om dit brand bevarer tilstedeværelse i disse trafiktunge AI-flader. Eskaleringseffektivitet måler andelen af kritiske sager løst inden for din målsatte SLA, hvilket demonstrerer operationel modenhed. Forskning viser, at brandsikkerhedsprogrammer med stærke pre-bid-kontroller og proaktiv overvågning reducerer overtrædelser til enkeltcifrede niveauer, sammenlignet med 20-30 % overtrædelsesrater for reaktive tilgange. AI Overviews udbredelse er steget markant frem til 2025, hvilket gør proaktive inklusionsstrategier afgørende—brands, der optimerer til AI-svar nu, får et konkurrenceforspring i forhold til dem, der venter på, at teknologien modnes. Det grundlæggende princip er klart: forebyggelse slår reaktion, og ROI på proaktiv brandsikkerhedsovervågning forrentes over tid, efterhånden som du opbygger autoritet, reducerer hallucinationer og bevarer kundetillid.
En AI-hallucination opstår, når en Large Language Model genererer information, der lyder overbevisende, men som er fuldstændig opdigtet og præsenteret med fuld selvtillid. Disse forkerte output sker, fordi LLM'er forudsiger statistisk sandsynlige ordsekvenser baseret på mønstre i træningsdataene, snarere end at forstå fakta. Hallucinationer skyldes overfitting, bias i træningsdata og den iboende kompleksitet i neurale netværk, der gør beslutningerne uigennemsigtige.
AI-hallucinationer kan alvorligt skade dit brand gennem flere kanaler: de medfører trafiktab (60 % af søgninger fører ikke til klik, når AI-sammendrag vises), de underminerer kundetillid, når falske påstande tilskrives dit brand, de skaber PR-kriser, når konkurrenter udnytter hallucinationer, og de reducerer din synlighed i AI-genererede svar. Virksomheder har rapporteret op til 10 % trafiktab, når AI-systemer fejlagtigt fremstiller deres produkter eller tjenester.
Google AI Overviews, ChatGPT, Perplexity og Gemini er de vigtigste platforme, hvor brandsikkerhedsrisici opstår. Google AI Overviews vises øverst i søgeresultaterne uden kildeangivelser for hver påstand. ChatGPT og Perplexity kan hallucinere fakta og fejlagtigt tilskrive information. Hver platform har forskellige praksisser for kildeangivelse og rettelsestidslinjer, hvilket kræver overvågningsstrategier på tværs af flere platforme.
Realtids overvågning på tværs af AI-platforme er afgørende. Overvåg prioriterede forespørgsler (brandnavn, produktnavne, ledelsesnavne, sikkerhedsemner), etabler stemningsbaselines og alarmgrænser, og korrelér ændringer med dine indholdsopdateringer. Specialiserede værktøjer som AmICited.com tilbyder automatiseret detektion på alle større AI-platforme med historisk sporing og stemningsanalyse.
Følg en 90-minutters beredskabsplan: 1) Bekræft og afgræns problemet (10 min), 2) Udgiv autoritative præciseringer på din hjemmeside (20 min), 3) Indsend platform-feedback med dokumentation (20 min), 4) Eskalér eksternt om nødvendigt (15 min), 5) Følg op på løsning (25 min). Hurtighed er kritisk—en tidlig respons kan reducere skaden på omdømmet med 70-80 % sammenlignet med forsinkede reaktioner.
Implementér E-E-A-T-signaler (Ekspertise, Erfaring, Forfatterskab, Troværdighed) med ekspertkvalifikationer, gennemsigtig kildeangivelse, opdaterede tidsstempler og redaktionelle standarder. Brug JSON-LD-strukturerede data med Organization-, Product-, FAQPage-, HowTo-, Review- og Article-skemaer. Tilføj Q&A-blokke, der adresserer risikofyldte intents, opret kanoniske sider, der samler information, og udvikl indhold, der er værd at citere, så AI-systemer naturligt refererer det.
At blokere crawlere reducerer din tilstedeværelse i AI-genererede svar, men beskytter følsomt indhold. En balanceret strategi tillader crawlere adgang til hovedprodukt-sider og autoritativt indhold, mens intern dokumentation og ofte misbrugt indhold blokeres. OpenAI's GPTBot og PerplexityBot respekterer robots.txt-direktiver, hvilket giver dig detaljeret kontrol over, hvilket indhold der indgår i AI-systemerne.
Overvåg MTTD/MTTR (Mean Time To Detect/Resolve) for skadelige svar efter alvorlighedsgrad, stemningsnøjagtighed i AI-svar, andel af autoritative kilder versus konkurrenter, synlighedsandel i AI Overviews og Perplexity-resultater, samt eskaleringseffektivitet (procent løst inden for SLA). Disse målepunkter viser, om dine overvågnings- og reaktionsprocesser forbedres og giver ROI-begrundelse for investeringer i brandsikkerhed.
Beskyt dit brand omdømme med realtids overvågning på tværs af Google AI Overviews, ChatGPT og Perplexity. Opdag hallucinationer, før de skader dit omdømme.
Lær hvad AI-hallucination er, hvorfor det sker i ChatGPT, Claude og Perplexity, og hvordan du opdager falsk AI-genereret information i søgeresultater.
AI-hallucination opstår, når LLM'er genererer falsk eller vildledende information med selvsikkerhed. Lær, hvad der forårsager hallucinationer, deres indvirkning...

Lær hvad AI-hallucinationsovervågning er, hvorfor det er essentielt for brandsikkerhed, og hvordan detektionsmetoder som RAG, SelfCheckGPT og LLM-as-Judge hjælp...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.