
Hvorfor original forskning er vigtig for AI-synlighed og citater
Opdag hvorfor det er afgørende at skabe original forskning for AI-synlighed. Lær, hvordan original forskning hjælper dit brand med at blive citeret i AI-generer...
8 min læsning
Lær hvordan du skaber originalt data og forskning, som AI-systemer aktivt citerer. Opdag strategier til at gøre dine data synlige for ChatGPT, Perplexity, Google Gemini og Claude, mens du opbygger bæredygtig AI-synlighed.
I kunstig intelligens’ tidsalder er originale data blevet den nye konkurrencefordel for brands, der søger synlighed ud over traditionelle søgeresultater. Efterhånden som AI-platforme som ChatGPT, Perplexity, Google Gemini og Claude i stigende grad formidler, hvordan publikum opdager information, har synlighedsreglerne ændret sig fundamentalt. I stedet for at konkurrere om position nul i Googles søgeresultater, skal organisationer nu skabe data, som AI-systemer aktivt ønsker at citere og referere. Denne transformation afspejler et bredere skift fra indholdsbaseret SEO til det, eksperter kalder “Generative Engine Optimization” (GEO), hvor AI-citering har erstattet traditionelle placeringer som den primære synlighedsmåling. Platforme, der syntetiserer information til direkte svar—uanset om det er via retrieval-augmented generation (RAG) eller modelnative synteser—foretrækker kilder, der leverer klare, udtrækkelige og autoritative originale forskningsdata. Organisationer, der forstår dette skifte og investerer i at skabe originale data, proprietær forskning og unikke indsigter, positionerer sig til at opnå citater på tværs af flere AI-platforme samtidigt og opbygger opmærksomhed og troværdighed blandt publikum, der måske aldrig ser traditionelle søgeresultater.

Forskellige AI-platforme bruger grundlæggende forskellige arkitekturer til at opdage og citere kilder, hvilket direkte påvirker, hvordan dine originale data bliver vist og krediteret. Forståelse for disse mekanismer er afgørende for at optimere indholdets synlighed på tværs af AI-landskabet. Forskellen mellem modelnative syntese (hvor AI genererer svar ud fra mønstre i træningsdata) og retrieval-augmented generation (hvor AI søger i levende kilder og syntetiserer ud fra de hentede resultater) forklarer, hvorfor nogle platforme giver eksplicitte citater, mens andre tilbyder svar uden kildeangivelse. Platforme, der bruger RAG-systemer, kan spore deres svar tilbage til specifikke kilder, hvilket gør citering ligetil og sporbar. Omvendt er modelnative systemer afhængige af probabilistisk viden lært under træning, hvilket gør kildeangivelse vanskelig eller umulig uden ekstra plugins eller integrationer.
| AI-platform | Citeringsmetode | Datakildeprioritet | Synlighedseffekt |
|---|---|---|---|
| ChatGPT | Modelnative (standard); linkede citater med plugins/browsing aktiveret | Træningsdata + levende web, når aktiveret; prioriterer nylige, autoritative kilder med retrieval aktiv | Lav uden plugins; moderat med søgning aktiveret; citater vises i svaret, når tilgængeligt |
| Perplexity | Retrieval-først med indlejrede nummererede citater | Live web-søgeresultater; prioriterer friske, direkte relevante kilder; fremhæver kildeprominens | Høj; nummererede citater med klare kilde-links; kilder i første position får uforholdsmæssigt meget trafik |
| Google Gemini | Integreret med Google Search og Knowledge Graph | Live indekserede sider + Knowledge Graph entiteter; prioriterer sider med strukturerede data og E-E-A-T signaler | Høj; citater vises som kilde-links i AI Overviews; strukturerede data forbedrer citeringsmulighederne |
| Claude | Modelnative (standard); websøgefunktioner udrulles i 2025 | Træningsdata + selektiv websøgningsfunktion; prioriterer sikre, autoritative kilder | Moderat; citater vises, når websøgningsfunktion er aktiveret; fokus på nøjagtighed og kildekredibilitet |
De praktiske konsekvenser er betydelige: Platforme som Perplexity og Google Gemini, der aktivt søger på det levende web, kan citere dit indhold straks ved udgivelse, hvis det lever op til deres kvalitets- og relevansstandarder. ChatGPT og Claude, der i højere grad er afhængige af træningsdata, kan tage længere tid om at inkorporere din originale forskning, men tilbyder andre synlighedsmuligheder via plugins og integrationer. For indholdsskabere betyder det at forstå, hvilke platforme dit målpublikum bruger, og optimere dine data derefter—uanset om det betyder at sikre udtrækkeligt, velstruktureret indhold til Perplexitys live retrieval eller opbygge autoritetssignaler, der påvirker inkluderingen i træningsdata for modelnative systemer.
Strukturerede data er gået fra at være en god SEO-taktik til at være en strategisk nødvendighed for AI-synlighed. Når du implementerer schema markup ved hjælp af Schema.org, hjælper du ikke bare Google med at forstå dit indhold—du skaber et maskinlæsbar lag, som AI-systemer pålideligt kan basere deres svar på. Dette strukturerede datalag, ofte kaldet en “content knowledge graph”, definerer eksplicit entiteter (personer, produkter, tjenester, steder, organisationer) og relationerne mellem dem, hvilket gør det langt lettere for AI-systemer at forstå, hvad dit brand er, hvad det tilbyder, og hvordan det skal fortolkes. Ifølge nyere forskning fra BrightEdge viste sider med robust schema markup højere citeringsrater i Googles AI Overviews, hvilket antyder, at strukturerede data direkte påvirker sandsynligheden for at blive citeret. Den nye Model Context Protocol (MCP), der er taget i brug af både OpenAI og Google DeepMind, repræsenterer næste udviklingstrin—i praksis en standardiseret API til at forbinde AI-modeller med strukturerede datakilder. Ved at implementere schema markup i stor skala skaber virksomheder et fundament, der reducerer hallucinationer i AI-svar, forbedrer forankringen i faktabaseret indhold og gør deres data mere synlige på tværs af retrieval-systemer. Dette er især vigtigt, fordi AI-systemer, der kun er trænet på ustruktureret tekst, ofte kæmper med nøjagtighed; strukturerede data giver den kontekstuelle klarhed, der gør det muligt for LLM’er at generere mere pålidelige, attribuerbare svar, der trygt kan citere din originale forskning.

Den mest effektive strategi for at opnå AI-citater er at skabe originale data, der er udtrækkelige, autoritative og tilpasset den måde, AI-systemer henter og syntetiserer information på. I stedet for at håbe, at dit eksisterende indhold bliver citeret, skal du bevidst designe dataprodukter, som AI-platforme nemt kan opdage, forstå og referere til. Her er de centrale strategier for at skabe citeringsværdige originale data:
Gennemfør original forskning med gennemsigtig metode: AI-systemer prioriterer kilder, der udviser grundig forskning. Offentliggør studier, undersøgelser og analyser med tydeligt dokumenterede metoder, stikprøver og begrænsninger. Når du synliggør din arbejdsproces, kan AI-platforme trygt citere dine fund som autoritative. Eksempler inkluderer branchebenchmarks, kundeanalyser, markedsforskning og proprietær dataanalyse, som konkurrenter ikke kan kopiere.
Gør data udtrækkelige via strukturerede formater: AI-systemer foretrækker indhold organiseret som tabeller, lister, sammenligningsmatricer og FAQ-stil Q&A frem for tætte tekstafsnit. En sammenligningstabel over konkurrenters funktioner bliver langt oftere citeret end de samme informationer skjult i prosa. Brug overskrifter, punktlister og visuelle hierarkier, der gør nøgleindsigter umiddelbart scannbare og udtrækkelige for AI-systemer.
Sikre datanyhed og aktualitetssignaler: AI-platforme, især dem med webretrieval, prioriterer aktuelle informationer. Medtag synlige udgivelsesdatoer, opdateringstidspunkter og regelmæssige opdateringer. Når du demonstrerer, at dine data er aktuelle og vedligeholdte, behandler AI-systemer dem som mere pålidelige end forældede kilder. Dette er særligt vigtigt for tidssensitive data som priser, statistikker og markedstendenser.
Etabler forfatter- og brandautoritet: AI-systemer vurderer kildens troværdighed før citering. Opbyg tydelige forfatterkredentialer (inkluder bios med relevant ekspertise), organisatorisk autoritet (backlinks, medieomtale, brancheanerkendelse) og domæneekspertisesignaler. Når dit brand er anerkendt som autoritet i din kategori, bliver du citeret oftere og mere fremtrædende.
Brug klare entitetsdefinitioner og relationer: Definér nøgleentiteter eksplicit—din virksomhed, produkter, tjenester, teammedlemmer og branchebegreber. Brug strukturerede data til at etablere relationer mellem disse entiteter. Når et AI-system forstår præcis, hvad du er, og hvordan du relaterer til branchebegreber, kan det citere dig mere præcist og kontekstuelt.
Implementér korrekt kildeangivelse og attribution: Hvis dine originale data bygger på andre kilder, citer dem åbent. AI-systemer anerkender og belønner kilder, der selv anerkender andre kilder. Dette skaber en citeringskæde, der øger tillid og sandsynlighed for yderligere citater i økosystemet.
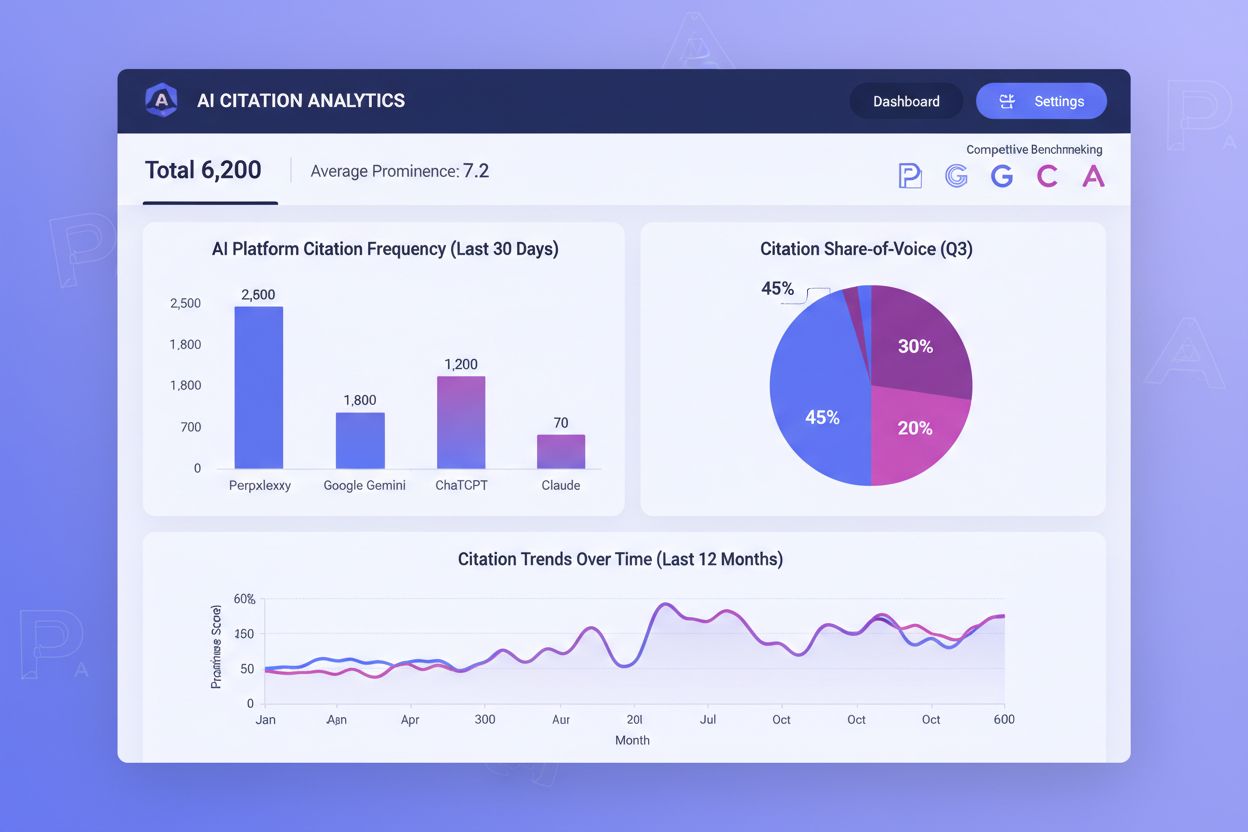
At spore AI-citater er blevet lige så vigtigt som at overvåge traditionelle søgeresultater, men de fleste organisationer mangler indsigt i, hvor ofte deres indhold bliver citeret på tværs af AI-platforme. Citeringsfrekvens, citeringsprominens og share-of-voice er de tre centrale målinger, der afgør din succes med AI-formidlet opdagelse. Citeringsfrekvens måler, hvor ofte dit indhold optræder i AI-svar for dine målrettede forespørgsler—hvis du citeres på 40% af relevante prompts, mens konkurrenter citeres på 60%, har du et klart optimeringsgab. Citeringsprominens betyder endnu mere: Et citat i første position i Perplexitys nummererede liste giver uforholdsmæssig høj synlighed sammenlignet med et citat i femte position. Share-of-voice afslører din konkurrencemæssige position—hvis dit brand får citater på 25% af kategori-definerende forespørgsler, mens din største konkurrent får citater på 50%, mister du væsentlig synlighed.
Værktøjer som AmICited.com er blevet essentielle løsninger til at overvåge AI-citater på tværs af platforme. Disse værktøjer sporer, hvilke af dine sider der får citater på Perplexity, Google AI Overviews, ChatGPT med søgning og andre AI-systemer og viser, hvilket indhold der faktisk driver AI-formidlet synlighed. Ved at overvåge citeringsmønstre over tid kan du identificere, hvilke indholdstyper, emner og formater der genererer flest citater og derefter gentage de vindende strategier. Konkurrencebenchmarking gennem disse værktøjer viser præcist, hvor du mister citater til konkurrenter, og gør målrettet optimering mulig. Dataene afslører, om dine citeringsudfordringer er universelle på tværs af alle AI-platforme eller specifikke for bestemte systemer—hvis du ofte bliver citeret på Perplexity, men sjældent på Google AI Overviews, bør din optimeringsstrategi tilpasses derefter. Positionsvægtede målinger anerkender, at tidlige citater giver uforholdsmæssig stor værdi; et værktøj, der vægter citater i første position stærkere end lavere placeringer, giver mere handlingsrettede indsigter end rå citeringstal. Ved at gøre AI-citeringssporing til en central del af din indholdsstrategi kan du løbende optimere dine originale data for både citeringsfrekvens og prominens og dermed direkte forbedre din synlighed i et AI-drevet søgeresultatslandskab.
At skabe originale data, der opnår AI-citater, kan ikke være et engangsprojekt—det kræver opbygning af en bæredygtig, tværfunktionel datastrategi, hvor data betragtes som en strategisk ressource, der fortjener løbende investering og styring. Organisationer, der lykkes med AI-synlighed, implementerer strukturerede processer for kontinuerlige dataopdateringer, så original forskning forbliver aktuel og relevant. Det indebærer faste opdateringscyklusser for centrale datasæt, opdatering af statistikker, når ny information opstår, samt vedligeholdelse af aktualitetssignaler, som AI-systemer bruger til at vurdere kilders pålidelighed. Ud over indholdsopdateringer samler succesfulde organisationer deres datastrategi på tværs af marketing, SEO, indhold, produkt og data teams gennem entity governance—fælles definitioner og taksonomier, der sikrer konsistent, korrekt repræsentation af dit brand, produkter og branchebegreber på tværs af alle kontaktpunkter.
Den mest avancerede tilgang betragter strukturerede data og content knowledge graphs som virksomhedsinfrastruktur. I stedet for at implementere schema markup side for side bygger førende organisationer omfattende content knowledge graphs, der forbinder alle entiteter, emner og relationer på tværs af deres digitale ejendomme. Dette kræver tekniske kompetencer—værktøjer og processer til at styre schema markup i stor skala—og organisatorisk enighed om datakvalitetsstandarder. Når det struktureres korrekt, tjener denne infrastruktur dobbelt formål: Den forbedrer ekstern AI-synlighed og muliggør samtidig interne AI-initiativer. Ifølge Gartners 2024 AI Mandates for the Enterprise Survey er datatilgængelighed og -kvalitet den største barriere for succesfuld AI-implementering; ved at investere i strukturerede data og entity governance løser du både eksterne synlighedsudfordringer og interne AI-behov. Organisationerne, der vinder på AI-synlighed, ser oprettelsen af originale data ikke som en marketingtaktik, men som en grundlæggende forretningskompetence med dedikerede ressourcer, klar ansvarlighed og løbende optimering baseret på citeringssporing og konkurrencebenchmarking.
Originale data refererer til proprietær forskning, unikke datasæt og primære fund, som du selv har skabt eller opdaget. AI-systemer prioriterer originale data, fordi de giver autoritativ, udtrækkelig information, de trygt kan citere. Almindeligt indhold syntetiserer ofte eksisterende information og er derfor mindre værdifuldt for AI-citering. Originale data bliver grundlaget for AI-synlighed, fordi platforme som Perplexity og Google Gemini aktivt søger og citerer kilder, der giver unikke indsigter og forskning.
Forskellige AI-platforme bruger forskellige opdagelsesmekanismer. Perplexity og Google Gemini bruger retrieval-augmented generation (RAG), hvilket betyder, at de søger på det levende web og kan citere dit indhold straks ved udgivelse. ChatGPT og Claude er mere afhængige af træningsdata, så dit indhold kan tage længere tid at blive inkorporeret, men tilbyder andre synlighedsmuligheder. Alle platforme drager fordel af strukturerede data (schema markup), der gør dine data maskinlæsbare og lettere at forstå, hvilket øger sandsynligheden for citater på tværs af alle systemer.
Strukturerede data ved brug af Schema.org-vokabular opretter et maskinlæsbar lag, som AI-systemer pålideligt kan basere deres svar på. Når du implementerer schema markup, definerer du eksplicit entiteter (din virksomhed, produkter, tjenester) og deres relationer, hvilket gør det markant lettere for AI-systemer at forstå og citere dit indhold korrekt. Forskning viser, at sider med robust schema markup får højere citeringsrater i AI Overviews. Strukturerede data reducerer også hallucinationer ved at give AI-systemer klare, faktuelle informationer at referere til.
AI-systemer citerer oftest original forskning med gennemsigtig metode, proprietære datasæt, branchestandarder, kunde- og markedsanalyser samt unikke indsigter, som konkurrenter ikke kan efterligne. Data præsenteret i udtrækkelige formater—tabeller, sammenligningsmatricer, lister og FAQ-stil Q&A—får flere citater end de samme informationer i tætte tekstafsnit. Friske, aktuelle data med synlige udgivelsesdatoer og løbende opdateringer prioriteres over forældet information. Autoritetssignaler som forfatterkredentialer og organisatorisk anerkendelse øger også sandsynligheden for at blive citeret.
Værktøjer som AmICited.com sporer AI-citater på tværs af platforme og viser, hvor ofte dit indhold vises i svar fra ChatGPT, Perplexity, Google AI Overviews og Claude. Disse værktøjer måler citeringsfrekvens (hvor ofte du bliver citeret), citeringsprominens (placering i svaret) og share-of-voice (dine citater sammenlignet med konkurrenters). Ved at overvåge disse målinger kan du identificere, hvilke indholdstyper og emner der genererer flest citater og derefter optimere din datastrategi tilsvarende. Positionsvægtede målinger anerkender, at citater i første position giver mere værdi end lavere placerede citater.
Citeringsfrekvens måler, hvor ofte dit indhold bliver citeret i AI-svar for dine målrettede forespørgsler—hvis du citeres på 40% af relevante prompts, er det din citeringsfrekvens. Citeringsprominens måler, hvor dit citat vises i svaret—et citat i første position i Perplexitys nummererede liste giver langt mere synlighed end et citat i femte position. Begge målinger er vigtige for AI-synlighed, men prominens betyder ofte mere, fordi brugere er mere tilbøjelige til at klikke eller engagere sig med tidlige citater. Effektiv optimering kræver forbedring af begge målinger samtidig.
Originale data bør opdateres på en regelmæssig tidsplan, der matcher din branches forandringshastighed. For hurtigt udviklende brancher som teknologi eller finans kan månedlige eller kvartalsvise opdateringer være nødvendige. For mere stabile brancher kan årlige opdateringer være tilstrækkelige. Det vigtige er at opretholde synlige aktualitetssignaler—udgivelsesdatoer, opdateringstidspunkter og fornyelsesindikatorer—der viser AI-systemer, at dine data er aktuelle og pålidelige. Løbende opdateringer øger også chancen for at blive citeret af retrieval-baserede systemer som Perplexity, der prioriterer friske informationer. Behandl datavedligehold som en løbende driftsopgave, ikke et engangsprojekt.
Ja, AmICited.com inkluderer konkurrencebenchmarking, der viser din citeringspræstation i forhold til definerede konkurrenter. Du kan se, hvilke konkurrenter der citeres hyppigere, på mere fremtrædende positioner og på hvilke AI-platforme. Denne konkurrenceindsigt afslører præcist, hvor du mister citater, og hvilke optimeringsstrategier der kan hjælpe dig til at vinde terræn. Ved at forstå dit konkurrencemæssige citeringslandskab kan du prioritere din dataoprettelse og optimering, så dine originale data får den synlighed, de fortjener.
Følg hvor ofte dine originale data bliver citeret på ChatGPT, Perplexity, Google AI Overviews og andre AI-platforme. Få handlingsrettede indsigter til at optimere dit indhold for maksimal AI-synlighed.
Opdag hvorfor det er afgørende at skabe original forskning for AI-synlighed. Lær, hvordan original forskning hjælper dit brand med at blive citeret i AI-generer...

Lær, hvordan du skaber original forskning og datadrevet PR-indhold, som AI-systemer aktivt citerer. Opdag de 5 egenskaber ved indhold, der er værd at citere, sa...
Opdag hvordan original forskning og førstepartsdata skaber et synlighedsboost på 30-40% i AI-citater på tværs af ChatGPT, Perplexity og Google AI Overviews.
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.